
We live in the age of big data. It is difficult to give an exact definition of big data. However, as a good rule of thumb, if the dataset can't fit in memory or disk on a single system, it can be called big data. Big data is used in areas such as healthcare, biology, bioinformatics, and education. Big data has fundamentally changed data analytics. Home computers were sufficient to analyze small and medium-sized data. But big data has changed the game. Home computers failed to analyze big data because big data didn't fit in memory. Cloud platforms such as AWS, Google Cloud, and Azure have been developed to analyze big data. Now we can easily analyze big data using cloud computing.
BigQuery is a fully-managed, serverless data warehouse that allows you to manage and analyze your data with built-in features like machine learning, geospatial analysis, and business intelligence. You can query terabytes in seconds and petabytes in minutes with BigQuery.
- The Google Cloud console
- The bq command-line tool
- The BigQuery REST API
- An external tool such as a Jupyter notebook or business intelligence platform
Dataproc allows you to manage Spark and Hadoop services that let you take advantage of open-source data tools for batch processing, querying, streaming, and machine learning.
Dataproc automation enables you to create clusters quickly, manage them easily, and save money by turning clusters off when you don't need them. You can focus on your jobs and data with less time and money spent on administration.
- Low cost
- Super fast
- Integrated - You can use Dataproc with other Google Cloud Platform services, such as BigQuery, Cloud Storage, Cloud Bigtable, Cloud Logging, and Cloud Monitoring.
- Managed - You can easily interact with clusters and Spark or Hadoop jobs through the Google Cloud console, the Cloud SDK, or the Dataproc REST API.
- Simple and familiar
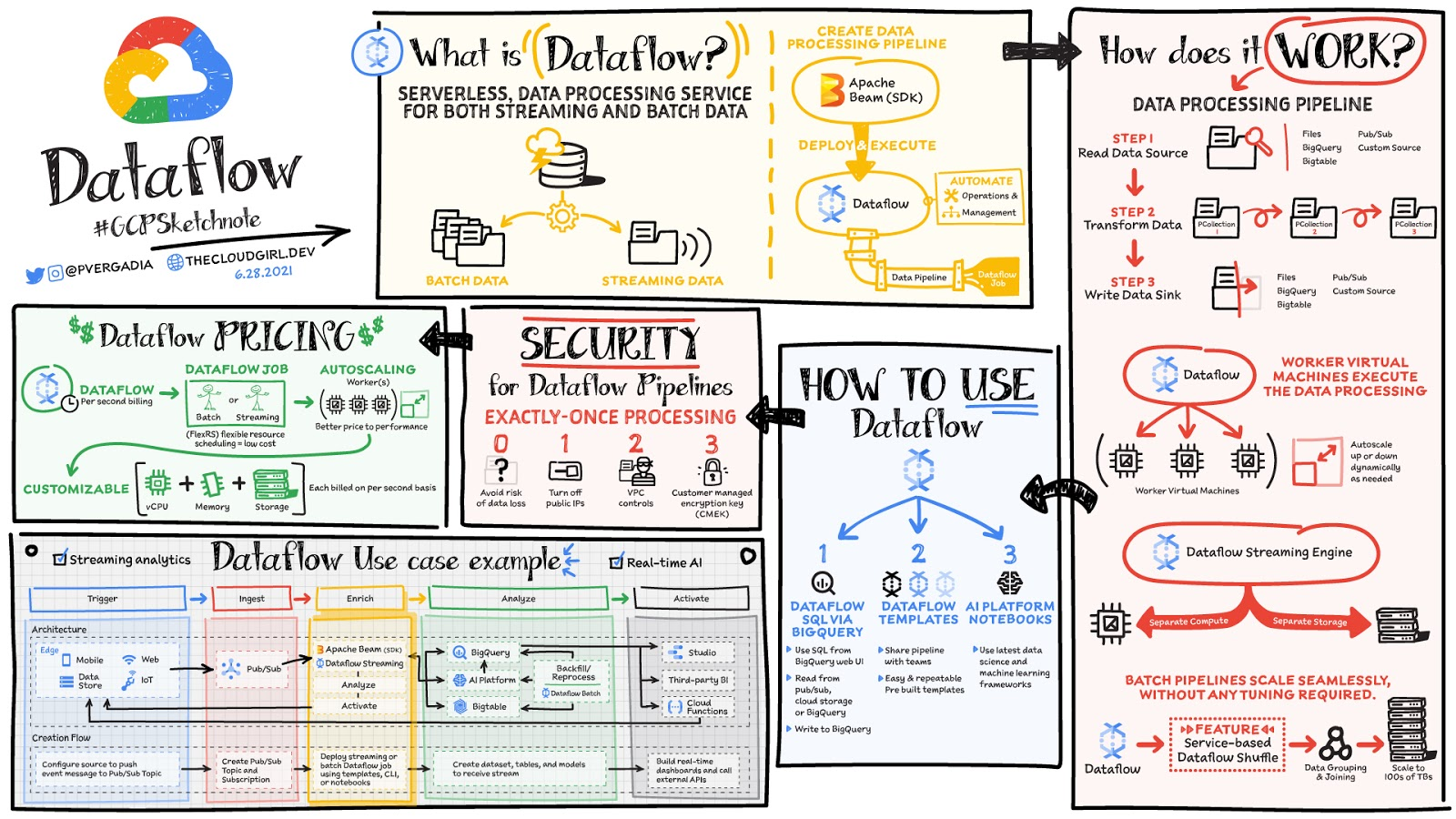
Dataflow is a data processing engine that can handle both batch and streaming data pipelines. It is a fully managed service for executing data processing pipelines written using Apache Beam. Apache Beam is an open source tool to define data pipelines. It runs the data pipeline using Dataflow.
Dataflow is similar to Spark that both technologies can process big data in parallel and can handle almost any kind of data or file. But in terms of underlying technologies, they are different. The main difference is the serverless nature of Dataflow. Using Dataflow, we don't need to set up any cluster. We just submit jobs to Dataflow, and the data pipeline will run automatically on the cloud. We just submit jobs to Dataflow, and the data pipeline will run automatically on the cloud.
Unlike with Cloud Dataproc, you don’t need to spin up a cluster to perform data processing. Instead, you simply submit the code and it will get executed and autoscaled to as many machines as needed to accomplish the task effectively.
Cloud SQL is a fully-managed database service that makes it easy to set up, maintain, manage, and administer your relational PostgreSQL and MySQL databases in the cloud.
Cloud Composer is a fully managed workflow orchestration service, enabling you to create, schedule, monitor, and manage workflows that span across clouds and on-premises data centers.
A DAG (Directed Acyclic Graph) is the core concept of Airflow, collecting Tasks together, organized with dependencies and relationships to say how they should run.
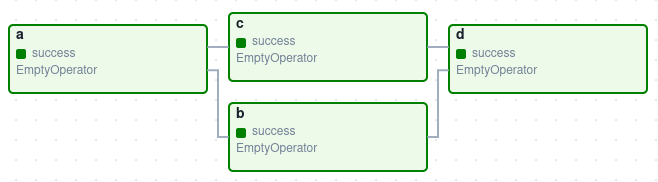
A Task is a unit of work within a DAG. Graphically, it’s a node in the DAG. Note that DAGs are nothing without Tasks to run.

Pub/Sub is a messaging system that receives messages from multiple systems and distribute them to multiple systems. Pub/Sub is used for streaming analytics and data integration pipelines to ingest and distribute data. Pub/Sub helps you create systems of event producers and consumers, called publishers and subscribers. Publishers communicate with subscribers asynchronously by broadcasting events, rather than by synchronous remote procedure calls. The following diagram illustrates how a message passes from a publisher to a subscriber.

Let's take a look at the main components of Pub/Sub?
The publisher is an entry point of Pub/Sub that uses the publisher to control incoming messages.
The topic is a central point of Pub/Sub. Pub/Sub stores messages in its internal storage. You can think of topics as the sets of messages that stores in Pub/Sub. Note that Pub/Sub messages are similar, with rows or records in the tables.
Each topic can have one or many subscriptions. Subscriptions are entities that have an interest in receiving messages from the topic. For example, for one topic that has two subscriptions, the two subscriptions will get identical messages from the topic.
A subscriber is different from a subscription. Each subscription can have one or many subscribers. The idea of having multiple subscribers in a subscription is to split the loads. For example, for one subscription that has two subscribers, the two subscribers will get partial messages from the subscription.
Vertex AI is a machine learning platform that allows you to manage all of Google’s cloud services in one place to deploy and maintain AI models. You can build, deploy, and scale machine learning (ML) models faster, with fully managed ML tools for any use case with this platform.
Vertex AI Pipeline is a tool for orchestrating ML workflows that uses Kubeflow Pipeline under the hood. Similar to the relationship between Airflow and Cloud Composer or Hadoop and DataProc, to understand Vertex AI Pipeline, we need to be familiar with Kubeflow Pipelines.
Data Studio is a fully managed tool on the cloud. This means that you can literally start developing your report, visualizing charts, sharing the report, and more without leaving your browser.
Looker Studio is a free, self-service business intelligence platform that lets users build and consume data visualizations, dashboards, and reports. With Looker Studio, you can connect to your data, create visualizations, and share your insights with others.
✨ Preparing for Google Cloud Machine Learning Engineer Professional Certificate
✨ Production Machine Learning Systems
✨ Google Cloud Big Data and Machine Learning Fundamentals
✨ MLOps (Machine Learning Operations) Fundamentals
✨ ML Pipelines on Google Cloud
✨ How to prepare for the GCP Professional Machine Learning Engineer exam
✨ A Comprehensive Study Guide for the Google Professional Machine Learning Engineer Certification