
Official implementation of Inf-DiT: Upsampling Any-Resolution Image with Memory-Efficient Diffusion Transformer

- 2024.07.01: Inf-DiT has been accepted by ECCV2024!
- 2024.05.20: This code and model weight is released.
- 2024.05.08: This repo is released.
- Code release
- Model weight release
- Complete the explanation for the inference code and hyperparameter
- Demo
- Comfyui
Diffusion models have shown remarkable performance in image generation in recent years. However, due to a quadratic increase in memory during generating ultra-high-resolution images (e.g. 4096 × 4096), the resolution of generated images is often limited to 1024×1024. In this work, we propose a unidirectional block attention mechanism that can adaptively adjust the memory overhead during the inference process and handle global dependencies. Building on this module, we adopt the DiT structure for upsampling and develop an infinite super-resolution model capable of upsampling images of various shapes and resolutions. Comprehensive experiments show that our model achieves excellent performance in generating ultra-high-resolution images. Compared to commonly used UNet structures, our model can save more than 5× memory when generating 4096 × 4096 images.
Model weights can be downloaded from here
- Download the model weights and put them in the 'ckpt'.
bash generate_sr_big_cli.shand input the low resolution image path.- You can change the "inference_type"(line 27 in generate_sr_big_cli.sh) to "ar"(parallel size=1), "ar2"(parallel size = block_batch(line 28)) or "full"(generate the entire image in one forward).
Hyperparameter explanation:
--input-type: choose between cli and txt(each line is a low resolution image path).--inference_type: choose between "ar"(parallel size=1), "ar2"(parallel size = block_batch(line 28)) or "full"(generate the entire image in one forward).--block_batch: block parallel size, one forward will generate block_batch*block_batch blocks. The current version requires that the image(after upsample) side length is divisible by block_batch * 128.--image-size: not used.--out-dir: output directory.--infer_sr_scale: the scale of the super-resolution, the current version only supports 2 and 4.
As this is a large-scale pre-trained model that has undergone multiple restarts and data adjustments during training, we cannot guarantee that the training results can be reproduced, it is only for reference implementation.
- Prepare the dataset. We use webdataset to organize data. Only one key "jpg" is needed in webdataset. You can replace WDS_DIR in the train_text2image_sr_big_clip.sh with webdataset path.
- train_text2image_sr_big_clip.sh and scripts/ds_config_zero_clip.json contain the main hyperparameters, among which ds_config_zero_clip.json are parameters related to DeepSpeed.
- Run train_text2image_sr_big_clip.sh with slurm or other distributed training tools.


Caption: A digital painting of a young goddess with flower and fruit adornments evoking symbolic metaphors.
Resolution:

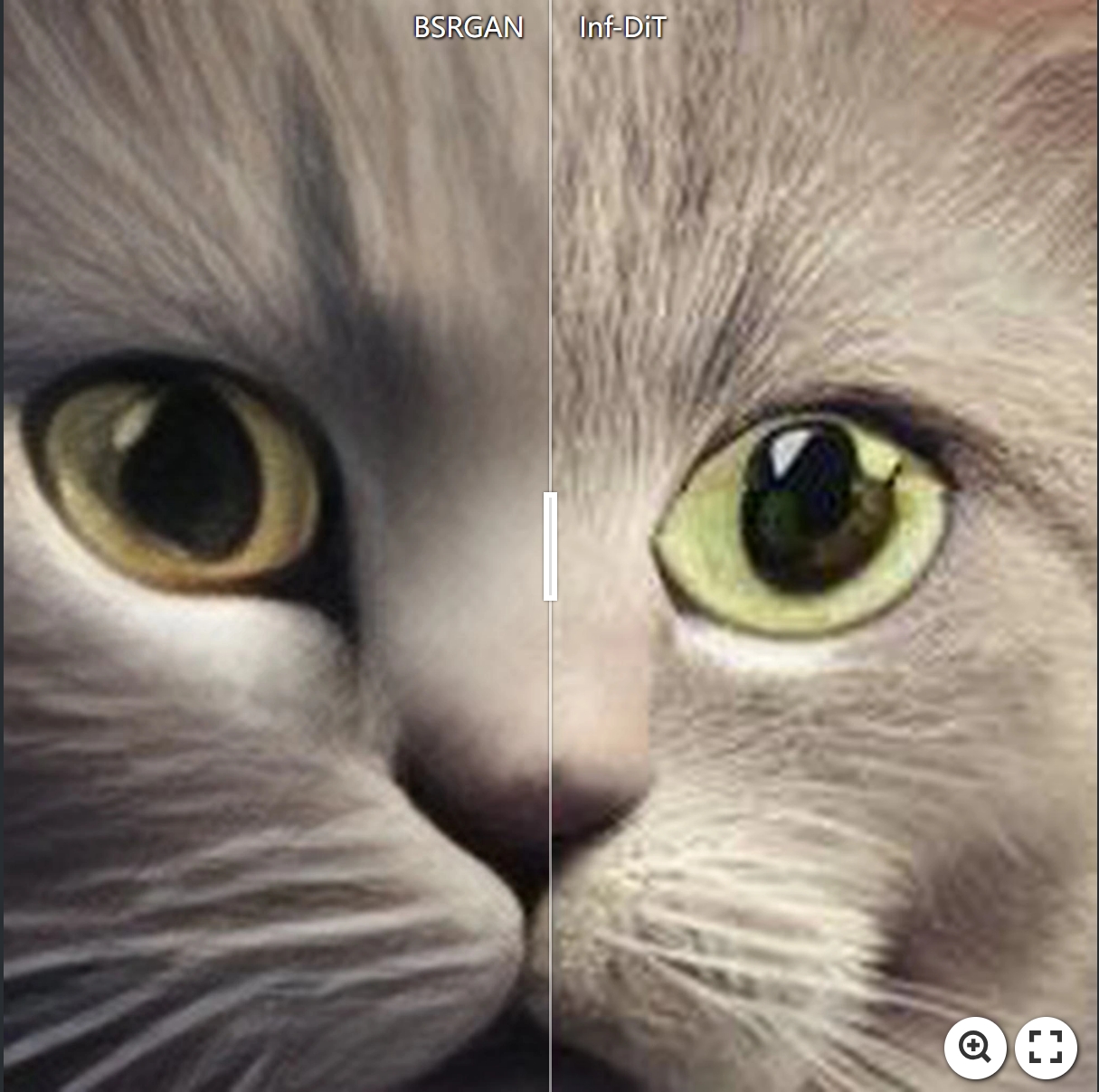
Caption: The image depicts a concept art of Schrodinger's cat in a box with an abstract background of waves and particles in a dynamic composition.
Resolution:

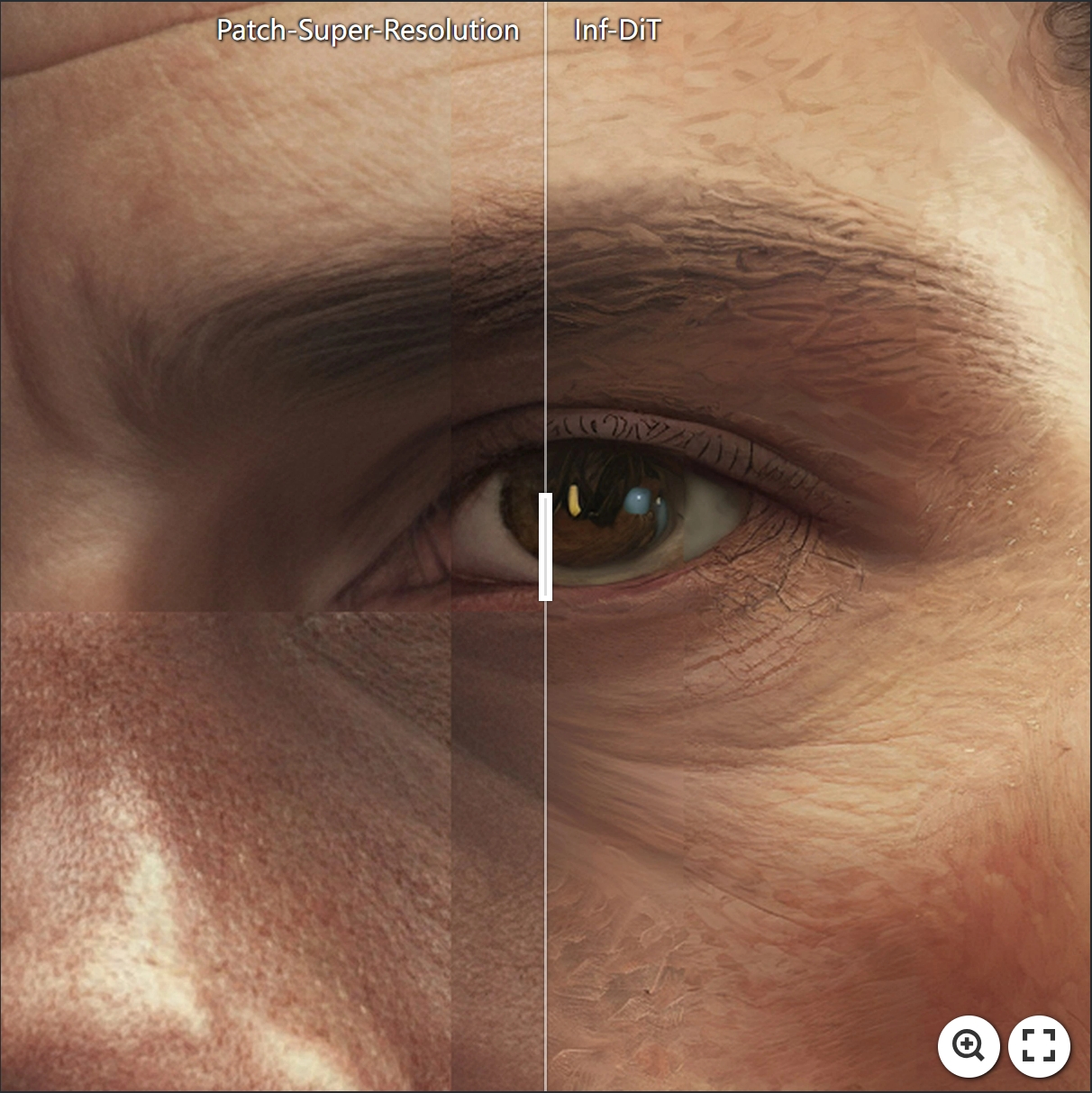
Caption: A portrait of a character in a scenic environment.
Resolution:

Resolution:

Resolution:
Please cite us if our work is useful for your research.
@misc{yang2024infdit,
title={Inf-DiT: Upsampling Any-Resolution Image with Memory-Efficient Diffusion Transformer},
author={Zhuoyi Yang and Heyang Jiang and Wenyi Hong and Jiayan Teng and Wendi Zheng and Yuxiao Dong and Ming Ding and Jie Tang},
year={2024},
eprint={2405.04312},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
If you have any comments or questions, feel free to contact zhuoyiyang2000@gmail.com or jianghy0581@gmail.com.