Improved AnimateAnyone implementation that allows you to use the opse image sequence and reference image to generate stylized video.
The current goal of this project is to achieve desired pose2video result with 1+FPS on GPUs that are equal to or better than RTX 3080!🚀
Test2Show-ChunLi.mp4
- Please check example workflows for usage. You can use Test Inputs to generate the exactly same results that I showed here. (I got Chun-Li image from civitai)
- Support different sampler & scheduler:
- DDIM
- 24 frames pose image sequences,
steps=20,context_frames=24; Takes 835.67 seconds to generate on a RTX3080 GPUDDIM_context_frame_24.mp4
- 24 frames pose image sequences,
steps=20,context_frames=12; Takes 425.65 seconds to generate on a RTX3080 GPU
DDIM_context_frame_12.mp4
- 24 frames pose image sequences,
- DPM++ 2M Karras
- 24 frames pose image sequences,
steps=20,context_frames=12; Takes 407.48 seconds to generate on a RTX3080 GPUDPM++_2M_Karras_context_frame_12.mp4
- 24 frames pose image sequences,
- LCM
- 24 frames pose image sequences,
steps=20,context_frames=24; Takes 606.56 seconds to generate on a RTX3080 GPULCM_context_frame_24.mp4
- Note:
Pre-trained LCM Lora for SD1.5 does not working well here, since model is retrained for quite a long time steps from SD1.5 checkpoint, however retain a new lcm lora is feasible
- 24 frames pose image sequences,
- Euler
- 24 frames pose image sequences,
steps=20,context_frames=12; Takes 450.66 seconds to generate on a RTX3080 GPUEuler_context_frame_12.mp4
- 24 frames pose image sequences,
- Euler Ancestral
- LMS
- PNDM
- DDIM
- Support add Lora
- I did this for insert lcm lora
- Support quite long pose image sequences
- Tested on my RTX3080 GPU, can handle 120+ frames pose image sequences with
context_frames=24 - As long as system can fit all the pose image sequences inside a single tensor without GPU memory leak, then the main parameters will determine the GPU usage is
context_frames, which does not correlate to the length of pose image sequences.
- Tested on my RTX3080 GPU, can handle 120+ frames pose image sequences with
- Current implementation is adopted from Moore-AnimateAnyone,
- I tried to break it down into as many modules as possible, so the workflow in ComfyUI would closely resemble the original pipeline from AnimateAnyone paper:
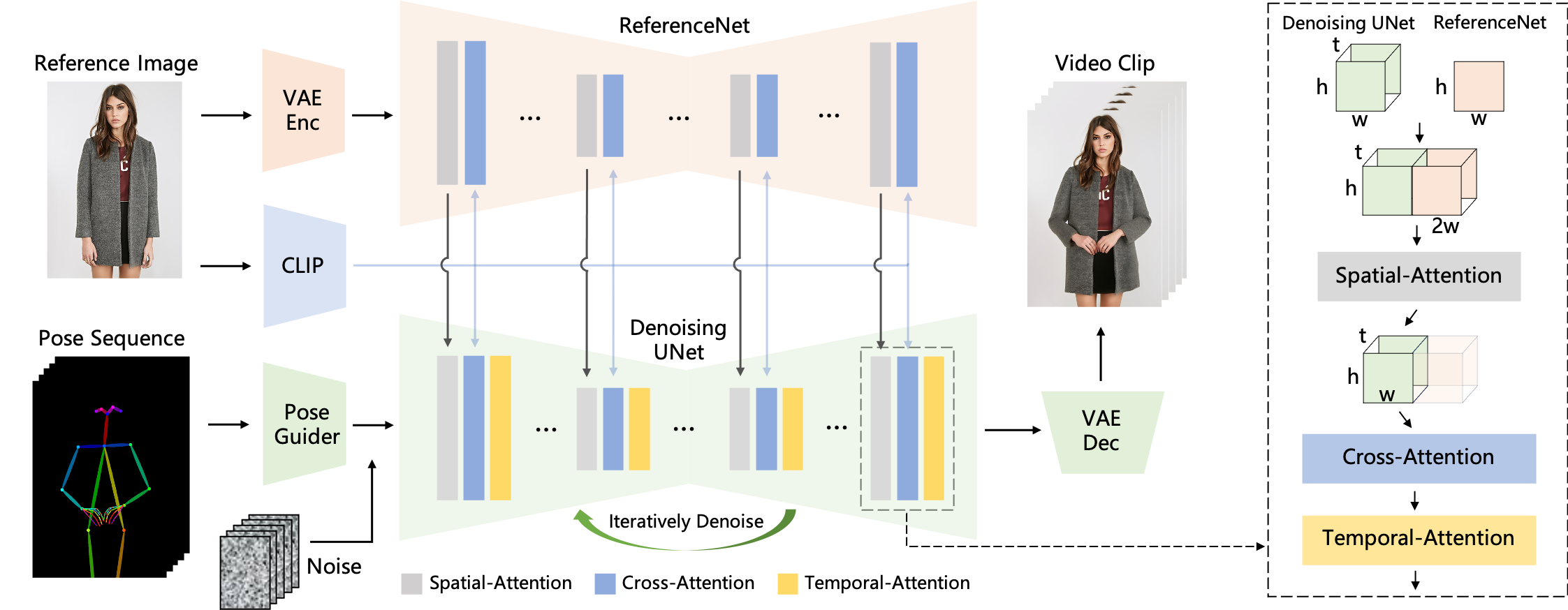
- I tried to break it down into as many modules as possible, so the workflow in ComfyUI would closely resemble the original pipeline from AnimateAnyone paper:

- Implement the compoents (Residual CFG) proposed in StreamDiffusion (Estimated speed up: 2X)
- Result:
Generated result is not good enough when using DDIM Scheduler togather with RCFG, even though it speed up the generating process by about 4X.
In StreamDiffusion, RCFG works with LCM, could also be the case here, so keep it in another branch for now.
- Result:
- Incorporate the implementation & Pre-trained Models from Open-AnimateAnyone & AnimateAnyone once they released
- Convert Model using stable-fast (Estimated speed up: 2X)
- Train a LCM Lora for denoise unet (Estimated speed up: 5X)
- Training a new Model using better dataset to improve results quality (Optional, we'll see if there is any need for me to do it ;)
- Continuous research, always moving towards something better & faster🚀
- Clone this repo into the
Your ComfyUI root directory\ComfyUI\custom_nodes\and install dependent Python packages:cd Your_ComfyUI_root_directory\ComfyUI\custom_nodes\ git clone https://github.com/MrForExample/ComfyUI-AnimateAnyone-Evolved.git pip install -r requirements.txt # If you got error regards diffusers then run: pip install --force-reinstall diffusers>=0.26.1
- Download pre-trained models:
- stable-diffusion-v1-5_unet
- Moore-AnimateAnyone Pre-trained Models
- Above models need to be put under folder pretrained_weights as follow:
./pretrained_weights/ |-- denoising_unet.pth |-- motion_module.pth |-- pose_guider.pth |-- reference_unet.pth `-- stable-diffusion-v1-5 |-- feature_extractor | `-- preprocessor_config.json |-- model_index.json |-- unet | |-- config.json | `-- diffusion_pytorch_model.bin `-- v1-inference.yaml- Download clip image encoder (e.g. sd-image-variations-diffusers ) and put it under
Your_ComfyUI_root_directory\ComfyUI\models\clip_vision - Download vae (e.g. sd-vae-ft-mse) and put it under
Your_ComfyUI_root_directory\ComfyUI\models\vae