Detection of Alcohol induced intoxication through voice using Neural Networks
Alcohol Language Corpus is a curation of audio samples from 162 speakers. Audio samples are first recorded when speaker is sober. Then the speakers are given a chosen amount of alcohol to reach a particular intoxication state, and audio samples are recorded again.
Audio samples are split into 8 seconds each. Below is the plot of a raw signal

These raw audio signals are converted into Mel filters using librosa. Below is how it looks:

Below are the architectures tried. All the files are under networks folder.
| Networks | Log Loss | UAR(Unweighted Average Recall) |
|---|---|---|
| Convolutional Neural Networks(convnet) | 0.89 | 66.28 |
| LSTM(lstm) | 1.59 | 58.12 |
| Conv LSTMs(crnn) | 1.17 | 62.27 |
| One class Neural Networks(ocnn) | 1.81 | 55 |
| Conv Auto Encoders(cae) | 0.92 | 65.53 |
-
Download and run the requirements.txt to install all the dependencies.
pip install -r requirements.txt -
Create a config file of your own
-
Install OpenSmile and set environment variable
OPENSMILE_CONFIG_DIRto point to the config directory of OpenSmile installation.
Run data_processor.py to generate data required for training the model. It reads the raw audio samples, splits into n seconds and generates Mel filters, also called as Filter Banks (fbank paramater in config file. Other available audio features are mfcc & gaf)
python3 data_processor.py --config_file <config_filepath>
Using main.py one can train all the architectures mentioned in the above section.
python3 main.py --config_file <config_filepath> --network convnet
One can use our model for inference. The best model is being saved under best_model folder
python3 main.py --config_file --test_net True <config_filepath> --network convnet --datapath <data filepath>
Remember to generate mel filters from raw audio data and use the generated .npy file for datapath parameter
- Work on frequency variance in voice
- Recurrence plots
- Extract features using Praat and Opensmile
- Normalise audio sample based on average amplitude
- Conditional Variational AutoEncoder
- Convolutional One class Neural Network
-
As training progresses, test and valid log losses increase. The confidence with which the network miss predicts increase. The below graph depicts this behaviour
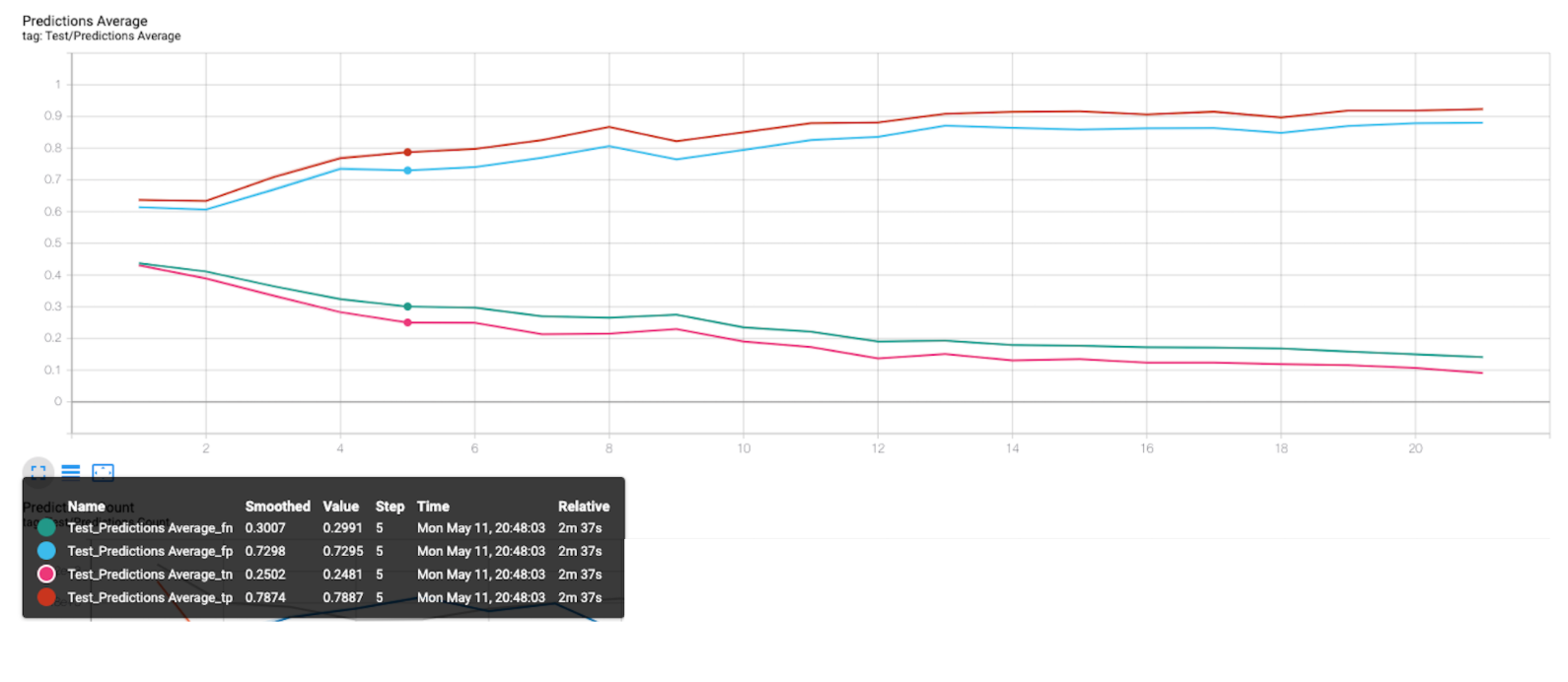
-
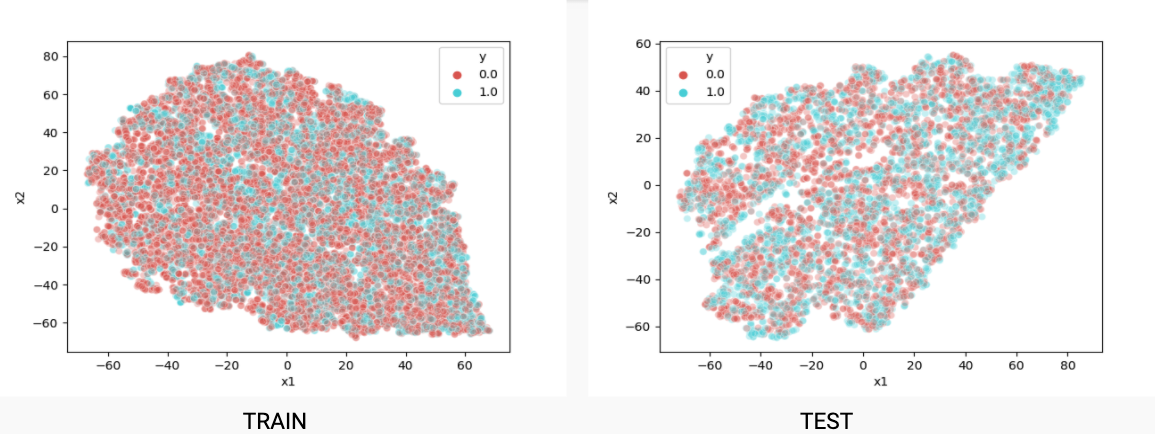
Mel filters or MFCC are not the best representation for this use case as these representations fail to capture variance in the amplitudes rather just try to mimic human voice.


Our team would like to thank Professor Emmanuel O. Agu for guiding the team throughout. I would like to thank team members Pratik, Arjun and Mitesh for all their contributions.