WOS_Crawler是一个Web of Science核心集合爬虫。
- 支持爬取任意合法高级检索式的检索结果(题录信息)
- 支持爬取给定期刊列表爬取期刊上的全部文章(题录信息)
- 支持选择目标文献类型,如Article、Proceeding paper等
- 支持多种爬取结果的保存格式,如Plain text、Bibtex、HTML等,推荐使用Plain text,解析速度最快
- 支持将爬取结果解析、导入数据库(目前支持Plain text、Bibtex、XML格式解析、导入),解析数据项除了基本的文献信息外(标题、摘要、关键词、被引量等),还包括作者机构、基金、分类、参考文献等信息
程序主要依赖:Scrapy、BeautifulSoup、PyQt5、SQLAlchemy、bibtexparser、qt5reactor、networkX
具体爬取逻辑和使用方法可以查看我的CSDN博客
-
将工程中的
main.py文件第33行的crawl_by_gui()取消注释,执行程序启动图形界面(或者你也可以通过
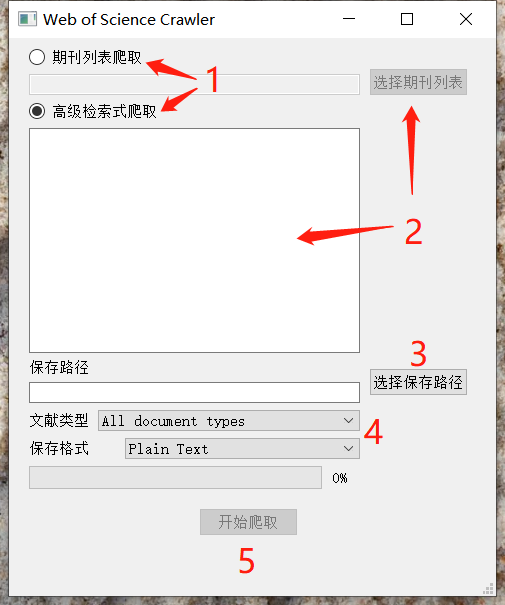
from wos_crawler.main import crawl_by_gui()来在你的程序中使用)首先选择是根据期刊列表还是高级检索式进行爬取,然后选择期刊列表或者输入高级检索式。选择好保存路径、导出文件类型、保存格式后,点击开始爬取即可。爬取进度会在进度条显示。
在爬取的同时会进行结果的解析和数据库导入,默认的数据库使用的是SQLite (支持保存到MySQL等关系型数据库),保存于目标路径的
result.db文件中
-
将工程中的
main.py文件第25-26行(按期刊列表)或第29-30行(按高级检索式)取消注释,传递合法的参数进去,执行程序即可。爬取进度会在终端显示。(或者你也可以通过
from wos_crawler.main import crawl_by_query, crawl_by_journal来在你的程序中使用)
- 因为Web of Science本身的限制,单个检索式如果结果数大于10万的话,大于10万的部分无法导出(即使手工也不行),此时可以通过年份划分来减少结果数,分批导出
- 导入数据库后,查询得到的结果条数可能会与网页结果数有偏差,我在定位目标批次后使用浏览器手动导出的方式证实了是WoS的问题(手动导出结果不足500条)。1万条结果会缺少5条左右
- 注重爬取道德,如有必要请设置合理的下载延迟。本程序可以视为是没有购买Web of Science API的一种替代解决方案,如果有更专业的需要请订阅WWS API
- 本程序虽不能通过WWS API获取数据,但是支持解析WWS API获得的XML文件
- 程序BUG在所难免,请在评论留言或提交ISSUE
输出格式为包含全部字段及参考文献的纯文本/Bibtex/HTML/Tab分隔文本文件,默认保存于output文件夹。
- 如果使用的是期刊列表进行爬取,则输出文件存放的方式为每个期刊一个独立文件夹
- 如果使用的是高级检索式进行爬取,则输出文件的存放文件夹命名为爬虫启动的时间
- 导出格式为
bibtex时,如果文献中存在{与}的不正确使用(不配对),则会存在截断问题,由于依赖了bibtexparser,目前我也没有很好的办法修复 - 少部分参考文献的格式极不规范,解析可能存在错误,该部分参考文献多为缺少具体信息的无效参考文献,对分析工作影响较小
- 集成各类常见的文献计量网络分析功能,如关键词、作者、机构共现分析等