- General info
- Project 1: Fraud detection using Autoencoder
- Project 1B: Fraud detection using XGBoost
- Project 2: Time serie anomaly detection
This repository goal is to learn how to detect anomalies within different types of data such as transactions from a bank account or time series with the usage of unsupervised learning, novelty detection and data clustering.
In this project we will classify transactions from a bank account as fraudulent or normal.
The dataset used is from Vesta Corporation (on kaggle) through the competition: IEEE-CIS Fraud Detection
The dataset is quite heavy, you might experience issues with your RAM.
Since the dataset is composed of 96.5% normal transactions and of only 3.5% fraudulent ones we are going to make an Anomaly Detection algorithm based on Novelty Detection (we train only on normal transactions).
For that we need an autoencoder which is an unsupervised Artificial Neural Network that attempts to encode the data by compressing it into the lower dimensions (bottleneck layer or code) and then decoding the data to reconstruct the original input.
Autoencoder Architecture

Then we compute the reconstruction error between the prediction and the original data with a Mean Squared Logarithmic Error.
And finally we set a threshold error between normal and fraudulent transactions, normal transactions should be smaller and fraudulents bigger than the threshold.
The results are 81.11% of True positive and 60.71% of True negative.
Which mean frauds will be detected 60.71% of the time and normal transactions misclassified 18.89% of the time
Depending on the situation using autoencoders is not always the best solution, here we can improve the results by using decision trees, in fact decision trees are better in supervised problems where we know the key features to classify from.
Exemple of Decision Tree
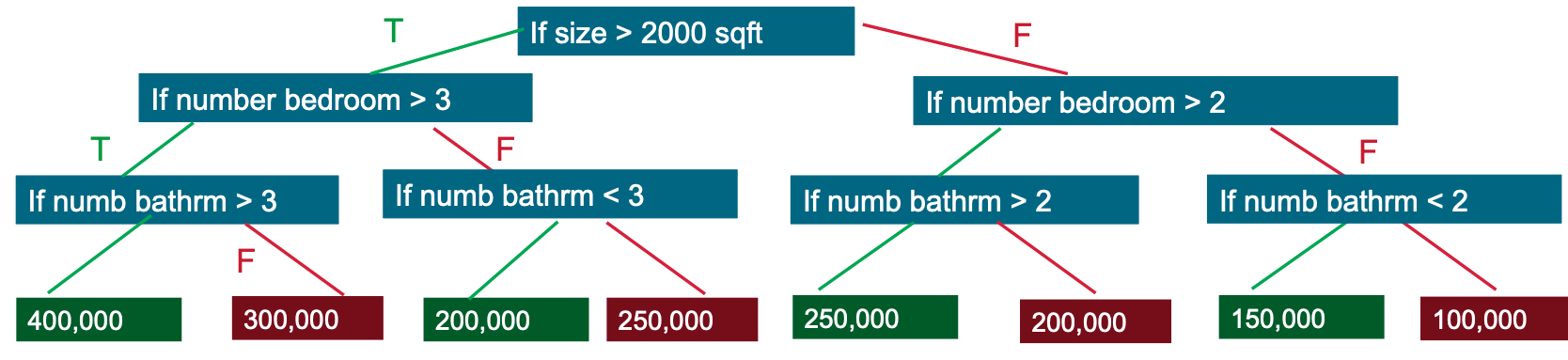
Here we will study in particular XGBoost which is a Gradient Boosting Decision Tree.
A Gradient Boosting Decision Tree (GBDT) is a decision tree ensemble learning algorithm similar to random forest, for classification and regression. Ensemble learning algorithms combine multiple machine learning algorithms to obtain a better model.
GBDTs iteratively train an ensemble of shallow decision trees, with each iteration using the error residuals of the previous model to fit the next model.
Gradient Boosting

With this model we obtain 96.93% of True positive and 89.31% of True Negative which is way better than the autoencoder.
For this project we'll apply the same idea as the first project: we make an autoencoder in order to compute a reconstruction error and we determine a threshold in order to detect anomalies in the time serie.
The difference in this project is that we have a new dimension which is time.
We'll train the algorithm on all data before January 2020, then we'll test it on data after this date.
(assuming there is no anomaly before January 2020)


We can see that the loss goes up as the Bitcoin's price rise, everything past 2021 is an anomaly because events and market manipulation exist and thus the price change in a random way.