Insurance Claims demo for Seldon Core v2
This is a demo that showcases streaming-based dataflow nature of Seldon Core v2. It implements the workflow of processing insurance claims, and shows how SCv2 can be used as a generic dataflow processing engine, beyond just model inference.
Description
The demo builds a simple workflow of processing car insurance claims. Input is given in a CSV file (downloaded from Kaggle), and each input record represents a single claim to be processed. Here is how it looks like:
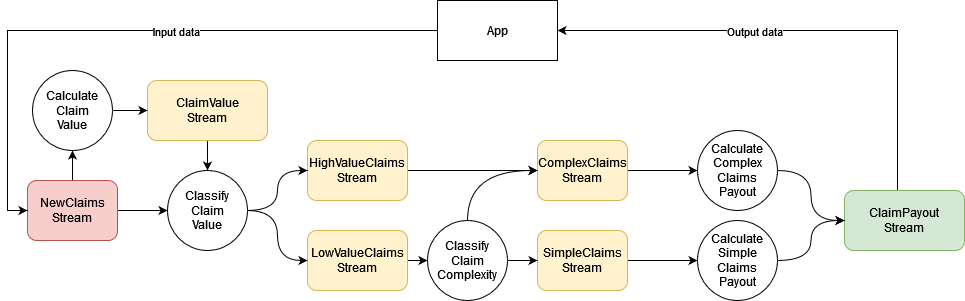
First stage of the demo implements the pipeline itself - each claim goes through a series of classification steps that determine if this is a simple or a complex case. Payout amount is determined according to this complexity.
Second stage collects a dataset of claim complexity data - we collect input-label pairs, where input is the entire claim and the binary label is the complexity. A simple classification model is then trained on this dataset with SKlearn.
Third and final stage is the deployment of a new pipeline where the entire classification process is replaced with the trained model, while payout part is reused.
The pipeline was originally described in this paper and implemented in the accompanying repo.
Structure
Walkthrough is presented as a notebook, so you probably want to start there. But make sure to go through the steps in the next section first! All models can be found in the models folder, and pipelines live in the pipelines folder.
How to run
First off, you need to have Seldon Core v2 running, please follow these docs to install it. Remember to add Seldon CLI to your PATH variable.
Starting SCv2
This demo uses models defined locally. To allow SCv2 to see location of these models, we need to set a corresponding environment variable and pass it to the SCv2 start script. This assumes you are in the root of SCv2 repo.
This demo is highly sensitive to the version of MLServer used (for boring technical reasons). It was most recently tested with 1.2.3, so we fix this version before starting SCv2.
export LOCAL_MODEL_FOLDER=/path/to/a/model/folder
export MLSERVER_IMG=seldonio/mlserver:1.2.3
make LOCAL_MODEL_FOLDER="${LOCAL_MODEL_FOLDER}" MLSERVER_IMG="${MLSERVER_IMG}" deploy-local
The path above is the path to the folder where all the models are defined. In our case this is the models folder of this repo. So the actual path might look something like this.
export LOCAL_MODEL_FOLDER=/home/usename/insurance-claims-scv2-demo/models
Demo requirements
This demo is built as a Jupyter notebook and uses a few Python packages that are all listed in the corresponding file. You can install them any way you like. Here is an example using virtual environments, from the root of this repo:
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
Running the demo
With all the prerequisites out of the way, feel free to open and run the main notebook.
SCv2 features
This demo showcases a number of interesting features of SCv2. In no particular order:
- Loading of locally defined models
- Joins
- Triggers
- Trigger joins
- Model reuse across pipelines
- Inspect command of Seldon CLI
- Using Triton and MLServer models in the same pipeline
In addition, it provides examples of building GRPC inference requests for SCv2 with Python code, using custom Python code as a Triton model, and uploading a SKlearn pipeline to MLServer.