This repo contains the official implementation of the AISTATS 2024 paper Generating and Imputing Tabular Data via Diffusion and Flow-based XGBoost Models. To make it easily accessible, we release our code through a Python library and an R package. See also our blog post for more information.
2023-12-15 update:
-
There is a new option to use an XGBoost data iterator (now used by default); this allows memory-efficient scaling to massive-scale datasets without requiring data duplication! With this new feature, we were able to train a ForestFlow on the massive Higgs boson dataset (21 features, 11M data points) in around 1.5 hours. See the memory section below for more details on how to use it.
-
You can now use your pre-trained ForestDiffusionModel to classify data using zero-shot classification! This option is only available when label_y is provided. There is evidence that generative models make better classifiers. See the zero-shot classification section below for more details on how to use it.
-
We did a few bug fixes in script_generation, script_imputation, and the R code. We also have a new metric based on classifiers trying to distinguish real from fake data.
2023-11-23 update: ForestFlow is now part of the wonderful TorchCFM (Conditional Flow Matching) library. This library is the most extensive library that exists on flow-matching! 😻 It now contains an in-depth notebook showing how to manually implement the ForestFlow method step by step. If you want to understand or even build upon our method 🙌, I highly recommend checking it out!
2023-11-02 update: You can now get Feature Importance! See the feature importance notebook for more info.
You can install the R package in R using:
install.packages("devtools") # do once if not already installed
devtools::install_github("SamsungSAILMontreal/ForestDiffusion/R-Package/ForestDiffusion")
Please see the documentation and a vignette with examples for guidance. The source code for the R package is in the R-package folder. The rest of the README is specific to the Python library.
Note that the R package may be updated for bug fixes but will not be updated with new features (such as the data iterator for scaling to large datasets in a memory-efficient matter). We highly recommend using the Python library for large data or experimental use.
The code for the Python library is in the Python-Package folder. To install the latest stable version on Python, run in bash :
pip install ForestDiffusion
Install the required packages:
pip install ForestDiffusion
pip install -r requirements.txt
Then run script_generation and script_imputation to replicate the analyses:
export out_path='/home/mila/j/jolicoea/where_to_store_results.txt'
# Generation with no missing data
myargs=" --methods oracle GaussianCopula TVAE CTABGAN CTGAN stasy TabDDPM forest_diffusion --diffusion_type flow --out_path ${out_path}"
python script_generation.py ${myargs}
myargs=" --methods forest_diffusion --diffusion_type vp --out_path ${out_path}"
python script_generation.py ${myargs}
# Generation with missing data
myargs=" --methods oracle GaussianCopula TVAE CTABGAN CTGAN stasy TabDDPM --add_missing_data True --imputation_method MissForest --out_path ${out_path}"
python script_generation.py ${myargs}
myargs=" --methods forest_diffusion --diffusion_type flow --add_missing_data True --imputation_method none --out_path ${out_path}"
python script_generation.py ${myargs}
myargs=" --methods forest_diffusion --diffusion_type vp --add_missing_data True --imputation_method none --out_path ${out_path}"
python script_generation.py ${myargs}
# Imputation with missing data
myargs=" --methods oracle KNN miceforest ice softimpute OT GAIN forest_diffusion --diffusion_type vp --out_path ${out_path}"
python script_imputation.py ${myargs}
As always, note that from the code refactoring and cleaning, the randomness will be different, so expect to get slightly different numbers than the exact ones from the paper.
We also provide the code for the complete replication of the LaTex tables and plots. This makes it easy to try your own method or add a dataset and obtain a new results table and plots. The output files with all the results and the R scripts to make the tables from the output files are in the Results folder. The R code could be cleaner, but adding your own method or datasets should be relatively straightforward. Once the tables are done, you can then make the plots using this notebook.
Install the pip package (as shown above).
Your dataset must be in numpy format. If you have a pandas dataset, you can convert using dataset_numpy = dataset.to_numpy(). The dataset can contain missing values.
Note: It is recommended use your own computer instead of Google Colab, because Google Colab only has two weak CPU cores. Using your own modern computer/laptop will be much faster (e.g., a laptop with a 16 cores i7-1270P CPU will be at least 8x faster than Google Colab, which has two cores).
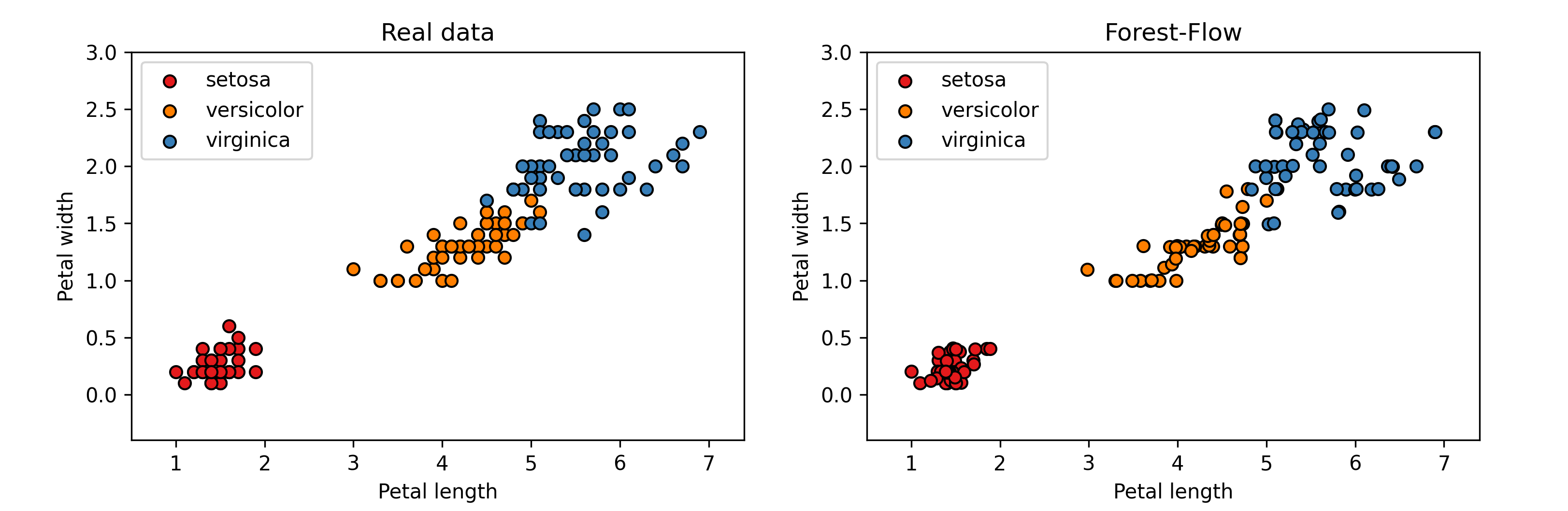
Examples to generate new samples with the Iris dataset:
from ForestDiffusion import ForestDiffusionModel
# Iris: numpy dataset with 4 variables (all numerical) and 1 outcome (categorical)
from sklearn.datasets import load_iris
import numpy as np
my_data = load_iris()
X, y = my_data['data'], my_data['target']
Xy = np.concatenate((X, np.expand_dims(y, axis=1)), axis=1)
# Classification problem (outcome is categorical)
forest_model = ForestDiffusionModel(X, label_y=y, n_t=50, duplicate_K=100, bin_indexes=[], cat_indexes=[], int_indexes=[], diffusion_type='flow', n_jobs=-1)
Xy_fake = forest_model.generate(batch_size=X.shape[0]) # last variable will be the label_y
# Regression problem (outcome is continuous)
Xy = np.concatenate((X, np.expand_dims(y, axis=1)), axis=1)
forest_model = ForestDiffusionModel(Xy, n_t=50, duplicate_K=100, bin_indexes=[], cat_indexes=[4], int_indexes=[], diffusion_type='flow', n_jobs=-1)
Xy_fake = forest_model.generate(batch_size=X.shape[0])
Examples to impute your dataset:
nimp = 5 # number of imputations needed
Xy = np.concatenate((X, np.expand_dims(y, axis=1)), axis=1)
forest_model = ForestDiffusionModel(Xy, n_t=50, duplicate_K=100, bin_indexes=[], cat_indexes=[4], int_indexes=[0], diffusion_type='vp', n_jobs=-1)
Xy_fake = forest_model.impute(k=nimp) # regular (fast)
Xy_fake = forest_model.impute(repaint=True, r=10, j=5, k=nimp) # REPAINT (slow, but better)
You can pass any XGBoost parameters that you want to be modified from the default values:
forest_model = ForestDiffusionModel(Xy, n_t=50, duplicate_K=100, bin_indexes=[], cat_indexes=[4], int_indexes=[0], diffusion_type='vp', n_jobs=-1,
max_bin=128, subsample=0.1, gamma=3, min_child_weight=2)
We list the important hyperparameters below, their default values, and how to tune them:
duplicate_K = 100 # number of noise per sample (or the number of times the rows of the dataset are duplicated when n_batch=0); should be as high as possible; higher values increase the memory demand when n_batch=0
n_batch = 1 # If > 0 use the data iterator with the specified number of batches and duplicate_K epochs
n_jobs = -1 # number of cpus/processes used for the parallel loop (-1 means all cpus; using a small number like n_jobs=4 will reduce training speed, but reduce memory load)
label_y = None # provide the outcome variable if it is categorical for improved performance by training separate models per class; cannot contain missing values
bin_indexes = [] # vector that indicates which column is binary
cat_indexes = [] # vector that indicates which column is categorical (>=3 categories)
int_indexes = [] # vector that indicates which column is an integer (ordinal variables such as the number of cats in a box)
n_t = 50 # number of noise levels (and sampling steps); increase for higher performance, but slows down training and sampling
diffusion_type = 'flow' # type of process (flow = ODE, vp = SDE); vp generally has slightly worse performance, but it is the only method that can be used for imputation
seed = 666 # random seed value
max_depth = 7 # max depth of the tree; recommended to leave at default
n_estimators = 100 # number of trees per XGBoost model; recommended to leave at default
gpu_hist = False # to use GPUs to train the XGBoost models (a single XGBoost model trains faster on GPUs, but its faster to train the n_t models in parallel over CPUs)
remove_miss=False, # If True, we remove the missing values, this allow us to make use of 'p_in_one=True'
p_in_one=True, # When possible (when there are no missing values), will train the XGBoost using one model for all predictors for more training/generation speed
Regarding the imputation with REPAINT, there are two important hyperparameters:
r = 10 # number of repaints, 5 or 10 is good
j = 5 # jump size; should be around 10% of n_t
You can now use your pre-trained ForestFlow or ForestDiffusion model for zero-shot classification. We provide below a small example:
from ForestDiffusion import ForestDiffusionModel
# Iris: numpy dataset with 4 variables (all numerical) and 1 outcome (categorical)
from sklearn.datasets import load_iris
import numpy as np
my_data = load_iris()
X, y = my_data['data'], my_data['target']
Xy = np.concatenate((X, np.expand_dims(y, axis=1)), axis=1)
# Classification problem (outcome is categorical)
forest_model = ForestDiffusionModel(X, label_y=y, n_t=50, duplicate_K=100, bin_indexes=[], cat_indexes=[], int_indexes=[], diffusion_type='flow', n_jobs=-1)
Xy_fake = forest_model.generate(batch_size=X.shape[0]) # last variable will be the label_y
y_pred = forest_model.predict(X, n_t=10, n_z=10) # return the predicted classes of the data provided (larger n_t and n_z increases precision)
y_probs = forest_model.predict_proba(X, n_t=10, n_z=10) # return the predicted class probabilities of the data provided (larger n_t and n_z increases precision)
Starting from version v1.0.5 of the Python library, the best way to reduce memory is to change the n_batch hyperparameter. In the original method (when n_batch=0), the rows of the dataset are duplicated duplicate_K times. With n_batch > 1, the data is not duplicated. Instead, we go through the dataset in n_batch iterations. So if we have 100K observations and n_batch=2, it does 2 iterations of 50K observations to go through the dataset once (i.e., one epoch). Since we want to associate multiple noises per data sample, we run the data iterator for duplicate_K epochs. This new method is equivalent to the old duplication method but is much more memory efficient. It is recommended to use n_batch=1 for small data and to increase it enough so that you do not have memory problems for large data (e.g., n_batch=11 with a 11M dataset to use 1M data points per iteration).
Our method trains p*n_t models in parallel using CPUs, where p is the number of variables and n_t is the number of noise levels. Furthermore, when n_batch=0, we make the dataset much bigger by duplicating the rows many times (100 times is the default). You may encounter out-of-memory problems in case of large datasets when n_batch=0 or if you have too many CPUs and use n_jobs=-1.
You can set n_jobs (the number of CPU cores used to parallelize the training of the models) to a reasonable value to prevent out-of-memory errors. Let's say you have 16 CPU cores. Then n_jobs=16 (or n_jobs=-1, i.e., using all cores) means training 16 models at a time using one core per model. It might be better to use a smaller value like n_jobs=8 to train 8 models at a time using 2 cores per model. The higher n_jobs is (or when n_jobs=1), the more memory-demanding it will be, which increases the risks of having out-of-memory errors.
We provide below some hyperparameters that can be changed to reduce the memory load:
n_batch # best way to reduce memory (from v1.0.5) along with reducing n_jobs; increase it to reduce the memory demand
n_jobs = -1 # number of cpus/processes used for the parallel loop (-1 means all cpus; using a small number like n_jobs=4 reduces the memory demand, but it will reduce training speed)
duplicate_K = 100 # lowering this value will reduce memory demand when n_batch=0
For maximum training speed, use all CPUs (n_jobs = -1) and the data iterator with 1 iteration per epoch (n_batch = 1). Furthermore, from the ablation, we found that vp-diffusion requires many noise levels to work well, but flow-matching works well even with as little as 10 noise levels; thus, you can reduce training time by using flow (diffusion_type = 'flow') with a small number of noise levels (n_t=10-20). Finally, duplicate_K corresponds to the number of epochs when (n_batch > 0) or the number of duplicated rows when (n_batch = 0); for small datasets, a large value is preferred, but for large datasets (N > 10K) with flow, a smaller value may be enough for good performance (duplicate_K=10) while reducing the training time.
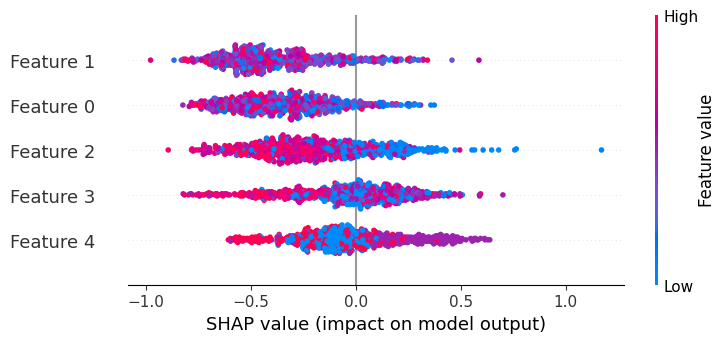
I made a simple example code showing how to extract the XGBoost models and either get i) the feature importance of each model or ii) the average feature importance from all models (simpler): Feature Importance Notebook.
If you find the code useful, please consider citing
@misc{jolicoeurmartineau2023generating,
title={Generating and Imputing Tabular Data via Diffusion and Flow-based Gradient-Boosted Trees},
author={Alexia Jolicoeur-Martineau and Kilian Fatras and Tal Kachman},
year={2023},
eprint={2309.09968},
archivePrefix={arXiv},
primaryClass={cs.LG}
}