- Linux Distribution OS (Ubuntu 20.04)
- Flex Package
- Bison Package
- LLVM Package (version 3.9)
- CLang Package (version 3.9)
- Visual Studio Code
-
First of all you must run this compiler in a Linux Distribution OS
-
The compiler won't output anything if there's some type of error and no flags passed
-
The compiler will work same way if is passed a unknown flag
-
You must ensure that you have the following folder's structure:
...
tests
outputs
-
Where:
- test folder contains a bunch of uc programs you can run
- outputs folder contains the result of your compilation
-
Define the variable
RUNNING_FILE_NAME, inmakefile, with only the name of the source file you want to compile, (make sure it has .uc format) -
Write
makein terminal to compile -
Optional: Write
make clearin terminal to clear your workspace (it deletes auxiliar and unnecessary files, all files present in outputs folder and the executable file)
-l: Prints tokens and eventual error messages in stdout-t: Prints the abstract syntax tree if there's no errors, otherwise only prints lexical and syntax errors-e1: Prints lexical error messages-e2: Prints syntax error messages +-e1-e3: Prints semantic error messages +-e2
This project was subdivided in 4 different and dependent steps, which means each step depends on previous step.
Our big goal was to program a compiler for a sub-language of C, named UC.
So we had to program all analyzers (using Lex, Yacc and C language) and code generator using. Fortunately LLVM makes our job easier and optimises the code for us, so we don't have to care about it.
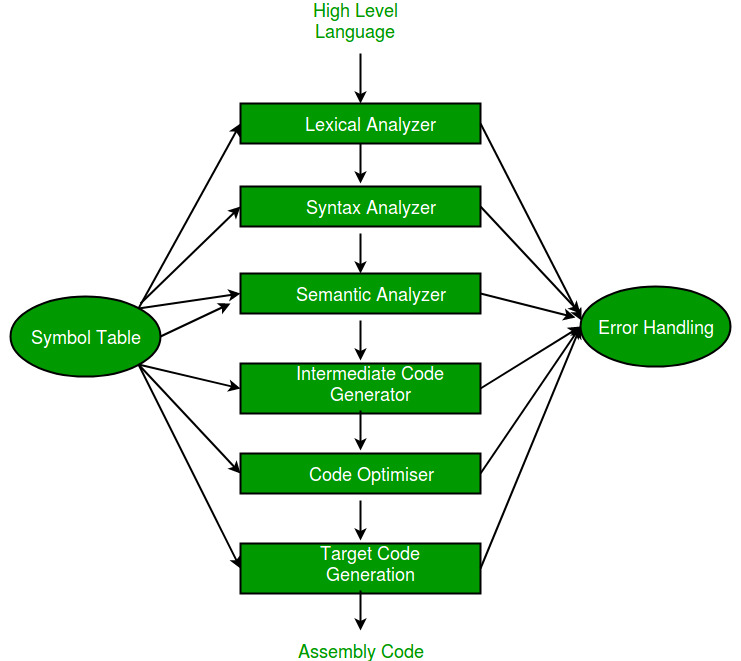
NOTE: I'll just do a superficial approach to what we've done. If you are interested in get some more explanations, you might consult the report available here [PT-PT Version].
In this step, using Flex, we only make sure that all symbols present in source code read belong to the UC language.
Since UC is a sub-language of C, all symbols existing in C, also exist in UC, unless some symbols like [, ], *, #, :, ?, !, ", among others. Knowing this, we can already conclude that concepts like pointers, arrays, strings or includes are not considered in our language.
NOTE: Do not forget that those symbols shall not exist in current code, however, they can be implemented inside characters, which means this can be possible:
char a= '#', b= '[';
char c= '"';
Now, we already know we're working with all symbols of our language, but we don't know if they are in the right order.
So, taking advantage of Yacc, we take care of our language grammar, in EBNF notation, so we can define what order symbols must have and then, we build the AST (abstract syntax tree, which structure is shown and explained in the report).
In this tree we'll save basically all the information about source code structure, including function definitions, function declarations, variable declarations, statements, expressions, etc.
Once we've the AST is built, we use it to guarantee if the given code "makes sense", so we have to verify a bunch of situations like:
- data types match to each other
- a function or variable is already defined or declarated
- the number and type of arguments passed in a function call correspond to the declarated ones
- a given operator can be applied to a certain type of data
- the void type was incorrectly used
- among others (you can check it all here on chapter 4.3)
If everything works fine and no errors are detected, we must start noting the AST with the corresponding data types and creating new data structures (linked lists) named symbol tables. There's one mandatory global symbol table containing all declarated functions and variables (global) and there's a undefined number of function tables, depending on the number of functions defined. Each function table contains its parameters, its declared variables and its return.
And finnaly we have, theoretically, a code free of errors so, getting the data we need from the noted AST and all symbol tables, we start translating that data into LLVM language so then LLVM can take that code, optimize it and turn it into machine code to execute in CPU.
And then, voilá, we have our code is working fine, just doing what we pretend it to do. 🙏
Licenciatura em Engenharia Informática - Universidade de Coimbra
COMPILADORES - 2020/2021
Coimbra, 21 de dezembro de 2020
🎓 Eduardo Filipe Ferreira Cruz - 🎓 Rodrigo Fernando Henriques Sobral
Have a look at the license file for details