By Paras Jain, Ajay Jain, Tianjun Zhang, Pieter Abbeel, Joseph E. Gonzalez and Ion Stoica (website)
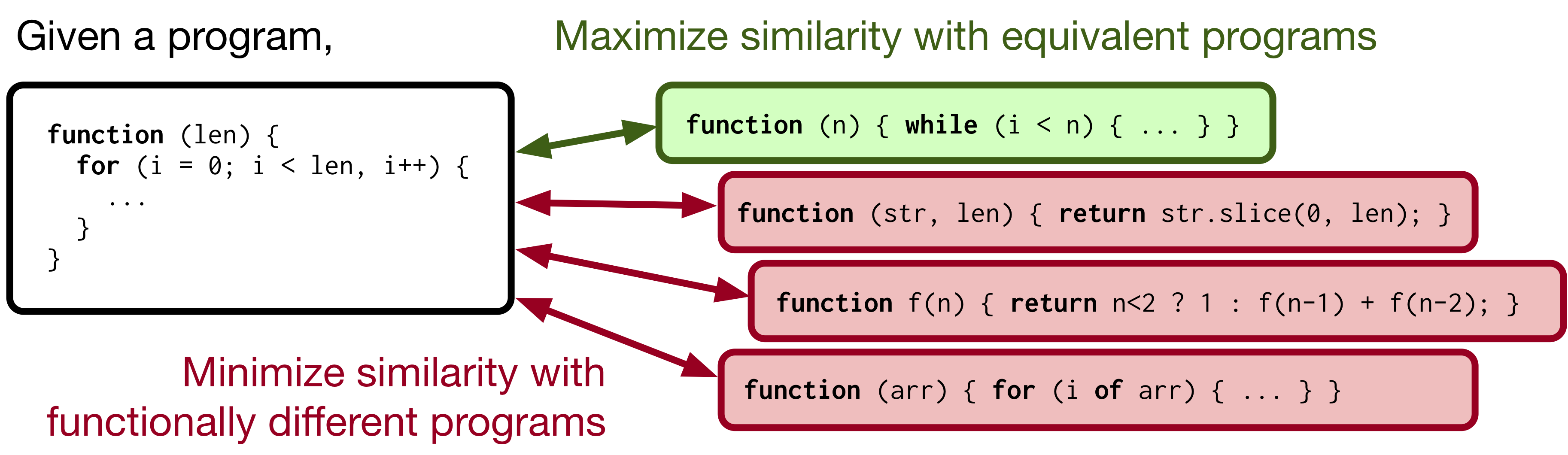
Machine-aided programming tools such as type predictors and code summarizers are increasingly learning-based. However, most code representation learning approaches rely on supervised learning with task-specific annotated datasets. We propose Contrastive Code Representation Learning (ContraCode), a self-supervised algorithm for learning task-agnostic semantic representations of programs via contrastive learning.
Our approach uses no human-provided labels, relying only on the raw text of programs. In particular, we design an unsupervised pretext task by generating textually divergent copies of source functions via automated source-to-source compiler transforms that preserve semantics. We train a neural model to identify variants of an anchor program within a large batch of negatives. To solve this task, the network must extract program features representing the functionality, not form, of the program. This is the first application of instance discrimination to code representation learning to our knowledge. We pre-train ContraCode over 1.8m unannotated JavaScript methods mined from GitHub. ContraCode pre-training improves code summarization accuracy by 7.9% over supervised approaches and 4.8% over BERT pre-training. Moreover, our approach is agnostic to model architecture; for a type prediction task, contrastive pre-training consistently improves the accuracy of existing baselines.
This repository contains code to augment JavaScript programs with code transformations, pre-train LSTM and Transformer models with ContraCode, and to finetune the models on downstream tasks.
Dependencies: Python 3.7, NodeJS, NPM
$ npm install
$ pip install -e "."
$ python scripts/download_data.pyDownload the data subfolder from this Google Drive link and place at the root of the repository. This folder contains training and evaluation data, vocabularies and model checkpoints.
Pretrain Bidirectional LSTM with ContraCode (10001 should be an available port, change if the port is in use):
python representjs/pretrain_distributed.py pretrain_lstm2l_hidden \
--num_epochs=200 --batch_size=512 --lr=1e-4 --num_workers=4 \
--subword_regularization_alpha 0.1 --program_mode contrastive --label_mode contrastive --save_every 5000 \
--train_filepath=data/codesearchnet_javascript/javascript_augmented.pickle.gz \
--spm_filepath=data/codesearchnet_javascript/csnjs_8k_9995p_unigram_url.model \
--min_alternatives 2 --dist_url tcp://localhost:10001 --rank 0 \
--encoder_type lstm --lstm_project_mode hidden --n_encoder_layers 2
Pretrain Transformer with ContraCode:
python representjs/pretrain_distributed.py pretrain_transformer \
--num_epochs=200 --batch_size=96 --lr=1e-4 --num_workers=6 \
--subword_regularization_alpha 0.1 --program_mode contrastive --label_mode contrastive --save_every 5000 \
--train_filepath=/dev/shm/codesearchnet_javascript/javascript_augmented.pickle.gz \
--spm_filepath=/dev/shm/codesearchnet_javascript/csnjs_8k_9995p_unigram_url.model \
--min_alternatives 1 --dist_url tcp://localhost:10001 --rank 0
Pretrain Transformer with hybrid MLM + ContraCode objective:
python representjs/pretrain_distributed.py pretrain_transformer_hybrid \
--num_epochs=200 --batch_size=96 --lr=4e-4 --num_workers=8 \
--subword_regularization_alpha 0. --program_mode contrastive --loss_mode hybrid --save_every 5000 \
--train_filepath=data/codesearchnet_javascript/javascript_augmented.pickle.gz \
--spm_filepath=data/codesearchnet_javascript/csnjs_8k_9995p_unigram_url.model \
--min_alternatives 1 --dist_url "tcp://localhost:10001" --rank 0
Commands to reproduce key type prediction results are provided below. In you are using pretraining checkpoints from the released checkpoints in the Google Drive, these commands should work without modification. However, if you pretrained the model from scratch, you will need to update the --resume_path argument.
Checkpoint paths if you pre-trained a model from scratch:
data/ft/ckpt_lstm_ft_types.pthbecomesdata/runs/types_contracode/ckpt_best.pthdata/pretrain/ckpt_transformer_ft_types.pthbecomesdata/runs/types_contracode_transformer/ckpt_best.pthdata/ft/ckpt_transformer_hybrid_ft_types.pthbecomesdata/runs/types_hybrid_transformer/ckpt_best.pthdata/ft/ckpt_transformer_ft_names.pthbecomesdata/runs/names_ft/ckpt_best.pth
Evaluate our finetuned Bidirectional LSTM (Table 2, DeepTyper with ContraCode pre-training):
python representjs/type_prediction.py eval --eval_filepath data/types/test_projects_gold_filtered.json --type_vocab_filepath data/types/target_wl --spm_filepath data/codesearchnet_javascript/csnjs_8k_9995p_unigram_url.model --num_workers 4 --batch_size 1 --max_seq_len -1 --no_output_attention True --encoder_type lstm --n_encoder_layers 2 --resume_path data/ft/ckpt_lstm_ft_types.pth
Finetune Bidirectional LSTM pretrained with ContraCode:
python representjs/type_prediction.py train --run_name types_contracode --train_filepath data/types/train_nounk.txt --eval_filepath data/types/valid_nounk.txt --type_vocab_filepath data/types/target_wl --spm_filepath data/codesearchnet_javascript/csnjs_8k_9995p_unigram_url.model --num_workers 4 --batch_size 16 --max_seq_len 2048 --max_eval_seq_len 2048 --lr 1e-3 --no_output_attention True --encoder_type lstm --n_encoder_layers 2 --warmup_steps 10000 --pretrain_resume_path data/pretrain/ckpt_lstm_pretrain_20k.pth --pretrain_resume_encoder_name encoder_q
Evaluate our finetuned Transformer (Table 2, Transformer with ContraCode pre-training):
python representjs/type_prediction.py eval --eval_filepath data/types/test_projects_gold_filtered.json --type_vocab_filepath data/types/target_wl --spm_filepath data/codesearchnet_javascript/csnjs_8k_9995p_unigram_url.model --num_workers 4 --batch_size 1 --max_seq_len -1 --resume_path data/pretrain/ckpt_transformer_ft_types.pth
Finetune Transformer pretrained with ContraCode:
python representjs/type_prediction.py train --run_name types_contracode_transformer --train_filepath data/types/train_nounk.txt --eval_filepath data/types/valid_nounk.txt --type_vocab_filepath data/types/target_wl --spm_filepath data/codesearchnet_javascript/csnjs_8k_9995p_unigram_url.model --num_workers 4 --batch_size 16 --max_seq_len 2048 --max_eval_seq_len 2048 --pretrain_resume_path data/pretrain/ckpt_transformer_pretrain_240k.pth --pretrain_resume_encoder_name encoder_q --lr 1e-4
Evaluate our finetuned hybrid Transformer (Table 2, Transformer (RoBERTa MLM pre-training) with ContraCode pre-training):
python representjs/type_prediction.py eval --eval_filepath data/types/test_projects_gold_filtered.json --type_vocab_filepath data/types/target_wl --spm_filepath data/codesearchnet_javascript/csnjs_8k_9995p_unigram_url.model --num_workers 4 --batch_size 1 --max_seq_len -1 --resume_path data/ft/ckpt_transformer_hybrid_ft_types.pth
Finetune Transformer after hybrid pretraining:
python representjs/type_prediction.py train --run_name types_hybrid_transformer --train_filepath data/types/train_nounk.txt --eval_filepath data/types/valid_nounk.txt --type_vocab_filepath data/types/target_wl --spm_filepath data/codesearchnet_javascript/csnjs_8k_9995p_unigram_url.model --num_workers 4 --batch_size 16 --max_seq_len 2048 --max_eval_seq_len 2048 --pretrain_resume_path data/pretrain/ckpt_transformer_hybrid_pretrain_240k.pth --pretrain_resume_encoder_name encoder_q --lr 1e-4
Evaluate (Table 3, Transformer + ContraCode + augmentation):
python representjs/main.py test --batch_size 64 --num_workers 8 --n_decoder_layers 4 \
--checkpoint_file data/ft/ckpt_transformer_ft_names.pth \
--test_filepath data/codesearchnet_javascript/javascript_test_0.jsonl.gz \
--spm_filepath data/codesearchnet_javascript/csnjs_8k_9995p_unigram_url.model
Finetune:
python representjs/main.py train --run_name names_ft \
--program_mode identity --label_mode identifier --n_decoder_layers=4 --subword_regularization_alpha 0 \
--num_epochs 100 --save_every 5 --batch_size 32 --num_workers 4 --lr 1e-4 \
--train_filepath data/codesearchnet_javascript/javascript_train_supervised.jsonl.gz \
--eval_filepath data/codesearchnet_javascript/javascript_valid_0.jsonl.gz \
--resume_path data/pretrain/ckpt_transformer_pretrain_20k.pth
If you find this code or our paper relevant to your work, please cite our arXiv paper:
@article{jain2020contrastive,
title={Contrastive Code Representation Learning},
author={Paras Jain and Ajay Jain and Tianjun Zhang
and Pieter Abbeel and Joseph E. Gonzalez and Ion Stoica},
year={2020},
journal={arXiv preprint}
}