
Porting of the code for "Intro - The Math of Intelligence" by Siraj Raval on Youtube to make it runnable on FloydHub.
This is the code for this video on Youtube by Siraj Raval. The dataset represents distance cycled vs calories burned. We'll create the line of best fit (linear regression) via gradient descent to predict the mapping. yes, I left out talking about the learning rate in the video, we're not ready to talk about that yet.
Here are some helpful links:
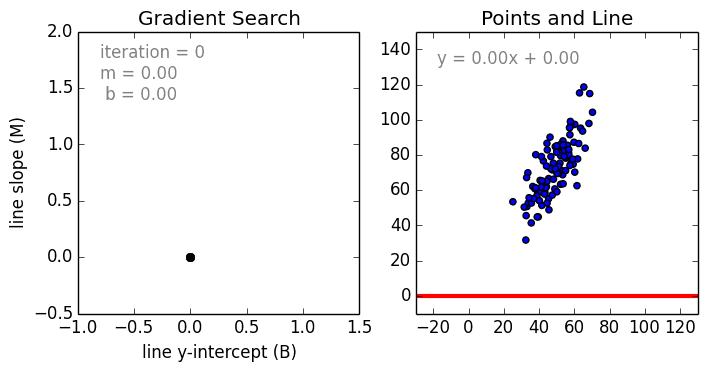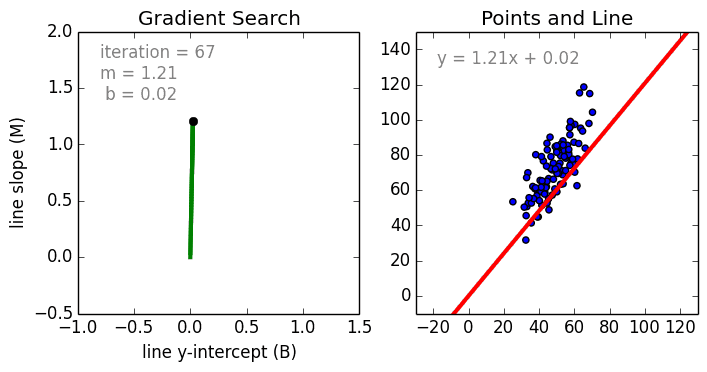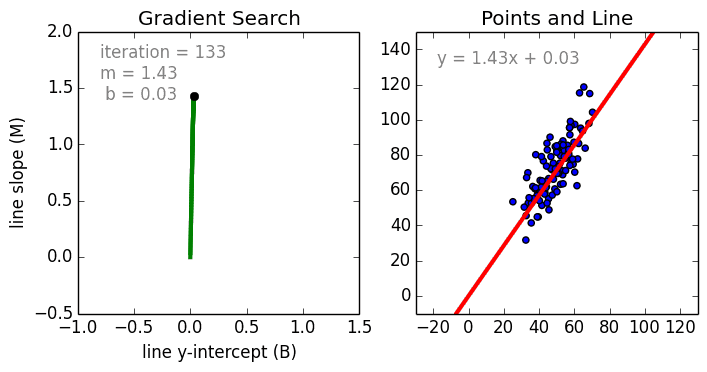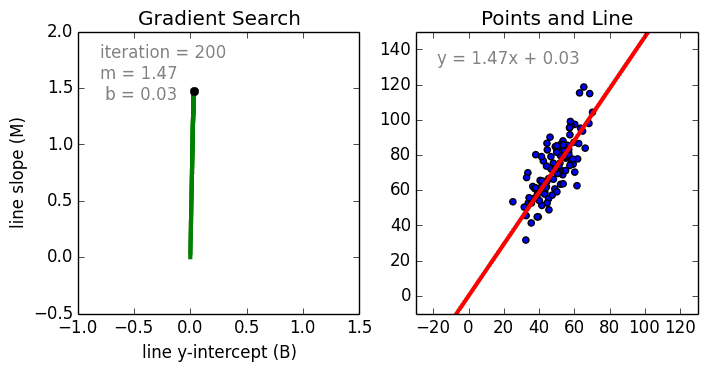
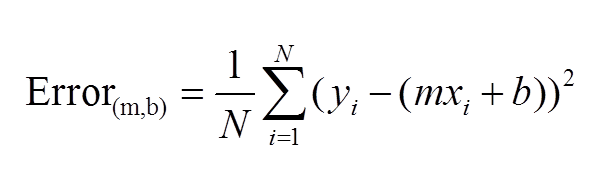
https://spin.atomicobject.com/wp-content/uploads/linear_regression_error1.png
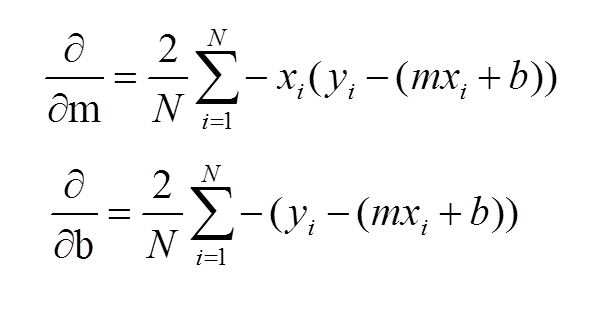
https://spin.atomicobject.com/wp-content/uploads/linear_regression_gradient1.png
Here's the commands to launch the demo on FloydHub.
$ pip install -U floyd-cli
$ floyd login
# Follow the instructions on your CLIClone from FloydHub:
$ cd /path/to/your-project-dir
$ floyd clone llSourcell/projects/Intro_to_the_Math_of_intelligence/1Clone from Github:
$ git clone https://github.com/floydhub/Intro_to_the_Math_of_intelligence
$ cd Intro_to_the_Math_of_intelligenceCreate a project on FloydHub and then sync the cloned repository with your new project
$ floyd init Intro_to_the_Math_of_intelligenceThe --data flag specifies that the version 1 of the distance-vs-calories dataset should be available at the /datasets directory. Note: If you want to mount/create a dataset look at the docs and our last blog post.
The --env flag specifies the environment that this project should run on, which is a Tensorflow 1.1.0 + Keras 2.0.6 backend environment with Python 3.5. Even if this is a basic tutorial that can run on every FloydHub environments, we suggest you to always specify an environment, this minimize all the reproducibility issue.
floyd run \
--env tensorflow-1.0 \
--data llSourcell/datasets/distance-vs-calories/1:dataset \
"python demo.py"You can follow along the progress by using the logs command or looking at the logs Panel inside the Overview Tab of your web dashboard's Job. This is the output of the demo:
...
################################################################################
2017-11-07 03:11:37,795 INFO - Run Output:
2017-11-07 03:11:37,992 INFO - Starting gradient descent at b = 0, m = 0, error = 5565.107834483211
2017-11-07 03:11:37,992 INFO - Running...
2017-11-07 03:11:38,124 INFO - After 1000 iterations b = 0.08893651993741346, m = 1.4777440851894448,
error = 112.61481011613473
2017-11-07 03:11:38,185 INFO -
################################################################################
...-
The Output of your Job is returned only if it saved inside the
/outputfolder, see our docs for a more detailed explanation. -
A keypoint of your experiments and a data science best pratice is to have a clean separation of the code from the data that it uses. This will allow you to structure the experiments/Jobs in a more elegant way and optimize the code you need to upload on FloydHub and speed up the experiment cycle iterations.
-
If you need any help check our documentation and forum.
This week's coding challenge is to implement gradient descent to find the line of best fit that predicts the relationship between 2 variables of your choice from a FloydHub or kaggle dataset. Bonus points for detailed documentation. Good luck!
We encourage you to try this alone and then check the winner of the coding challenge(wizard of the week) in the next Lesson.
Credits for this code go to mattnedrich. I've merely created a wrapper to get people started.