A demo project on batch data-parallel processing using Apache Beam and Python
 Rajeshwari Rudravaram 💻 |
 Sri Sudheera Chitipolu 💻 |
 Pooja Gundu 💻 |
 Raju Nooka 💻 |
 Sai Rohith Gorla 💻 |
 Rohith Reddy Avisakula 💻 |
- Apache Beam is a unified model for defining both batch and streaming data-parallel processing pipelines, as well as a set of language-specific SDKs for constructing pipelines and Runners for executing them on distributed processing backends, including Apache Flink, Apache Spark, Google Cloud Dataflow and Hazelcast Jet.
- Data process can either be for Analytic purpose or ETL(Extract, Transform and Load). Also, it doesn't rely on anyone of the execution engine and data agnostic, programming agnostic.
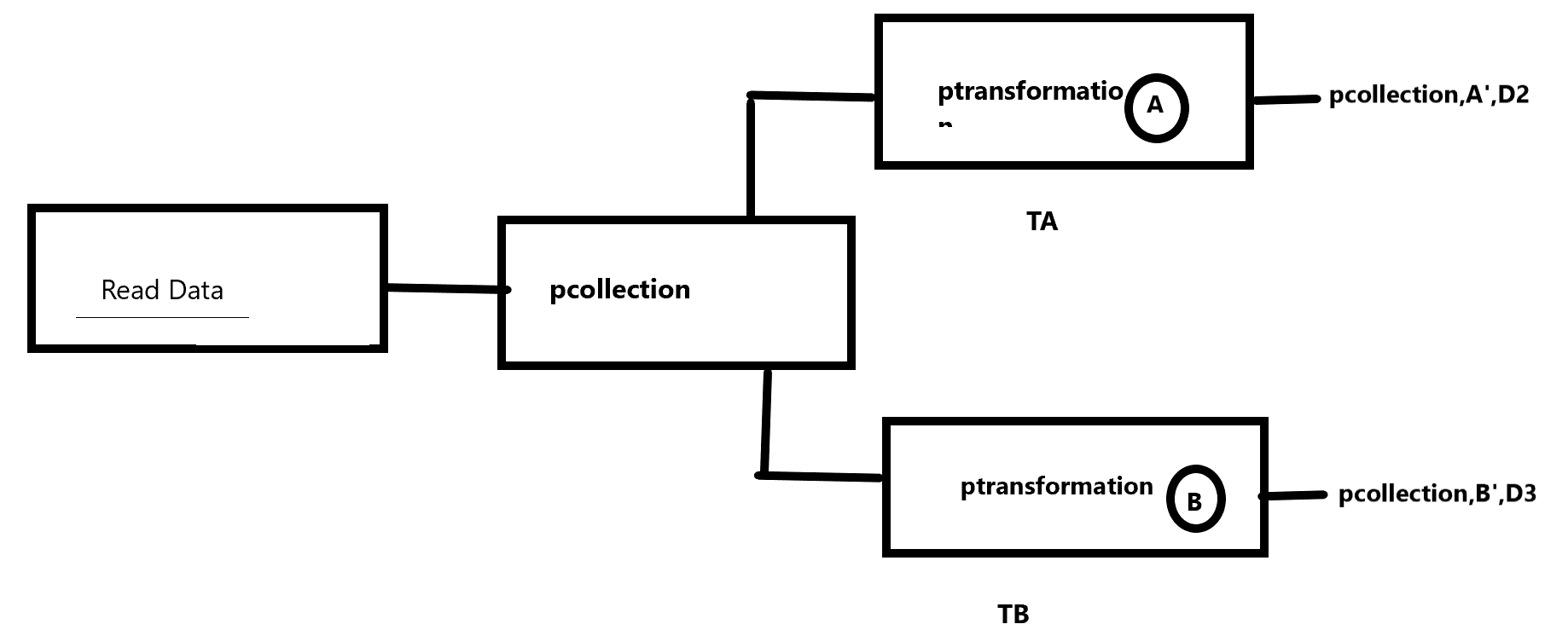
- Apache Beam provides a simple, powerful programming model for building both batch and streaming parallel data processing pipelines.
- Batch pipeline : The type of pipeline used to process the data in batches.
- Streaming data pipelines : These pipelines handles millions of events at scale in real time.
- Apache Beam SDK(Software Development Kit) for python provides access to the Apache Beam capabilities using Python Programming Language.
- Using Apache Beam SDK one can build a program that defines the pipeline.
- PCollection: represents a collection of data, which could be bounded or unbounded in size.
- PTransform: represents a computation that transforms input PCollections into output PCollections.
- Pipeline: manages a directed acyclic graph of PTransforms and PCollections that is ready for execution.
- PipelineRunner: specifies where and how the pipeline should execute.
- Colab is a Python development environment that runs in the browser using Google Cloud.
- Raju Nooka - GroupByKey Transformation
- Sri Sudheera Chitipolu - Groupby Transformation
- Rohith Reddy Avisakula- GroupIntoBatches
- Pooja Gundu - I will be working on word count of a dataset.
- Sai Rohith Gorla - BatchMatches
- Rajeshwari Rudravaram - Minimal Word Count of a Dataset.
Sri Sudheera Chitipolu  Demo link
Demo link
- Apache Beam python GroupBy Transformation on netflix_titles.csv
- Sri Sudheera's Google Colab Notebook on GroupBy Transformation
- Demonstration Video: Sri Sudheera's GroupBy Transformation on Apache Beam Python
- My Personal Repo on apache beam python with README file-https://github.com/sudheera96/abeam_python_Groupby
- Apache Beam
- Python
- Google Colab
- Kaggle for data set
- Open firefox or safari browser
- Type Google Colab
- Click on first link that is Google Colab
- Sign in with google account
- Click on notebook after appearing the window with recent
Note: Google Colab works similar to jupyter notebook
- After writing and execution of code,save file in local or Github
- Give the command to install apache beam
!pip install --quiet -U apache-beamProgram
.png) Output
Output
.png)
Rajeshwari Rudravaram  Demo Link
Demo Link
- Minimal word count is an implementation of word count for a given dataset.
- I will be creating a simple data processing pipeline that reads a text file and counts the number of occurrences of every word in that dataset.
- I have worked on "Minimal Word Count" for the file 'key_benifits.csv' of Shopify app store.
- The dataset, I have choosen is Kaggle. Here is the link Shopify app store
- I have choosen the Google colaboratory to run the code.
- Reading data from text file
- Specifying 'inline' transforms
- Counting a PCollection
- Writing data to text file
- Apache Beam python Minimal Word Count Transformation on Key_benifits.csv
- Rajeshwari Rudravaram's Google colab notebook on Minimal word count
- Output of the Minimal Word Count
- Video link on Demonstration of "Minimal Word Count"
- Apache Beam
- Python
- Google Colab
python --versionpip --version- Note:- Python must be greater than 3.6.0
python -m pip install apache-beampip install apache-beam[gcp,aws,test,docs]-
Installation of Apache Beam on Colab notebook and upload the input file to notebook

-
Importing required libraries and run the following commands

-
To check the list of files on your notebook

-
command to add the result to output file





Pooja Gundu  Demo link
Demo link
- I have worked on "Word Count" for the file 'superbowl-ads.csv' This file contains data about all advertisements shown during the Super Bowl(most watched US Program) across the years from 1967 to 2020.
- The dataset, I have choosen is Kaggle. Here is the link superbowl-ads.csv
- I have choosen the Google colaboratory to run the code.
- Pooja's Google Colab Notebook on wordcount Transformation
- Demonstration Video: link
- My Personal Repo on apache beam python with README file - https://github.com/GUNDUPOOJA/apache_beam_python-wordcount
- Apache beam
- Google Colab
- Google drive account
- Python
- Create a google colab account and open a new notebook, rename it as you required.
- First, install the apache-beam using the below command
!pip install --quiet -U apache-beam

- Also, install all the dependencies(executive engines)required using the command
!pip install apache-beam[gcp,aws,test,docs]

-
Program that performs the word count operation

-
output of the program

-
The command that lists all the files

! ls

-
First upload your .csv file to your google drive account. The email used should be same for both google drive and google Colab accounts.
-
Import the .csv file run the below commands otherwise you will get file not found error because it is not imported into google colab.


# Code to read csv file into colaboratory:
!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
# Autheticate E-Mail ID
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
- To get the id of the file, right-click on the file in google drive account, select share link option, then copy the link.
- Remove the part that contains https://
- keep only the id part.
# Get File from Drive using file-ID
# Get the file
downloaded = drive.CreateFile({'id':'1b73yN7MjGytqSP5wimYAQmtByOvGGe8Y'}) # replace the id with id of file you want to access
downloaded.GetContentFile('superbowl-ads.csv')
- Command to add the result to a output file
!cat output.txt-00000-of-00001 # output file

Raju Nooka  Demo link
Demo link
- I have worked on "GroupByKey" for the file 'vgsales.csv' This dataset contains a list of video games with sales greater than 100,000 copies.
- The dataset, I have choosen is Kaggle. Here is the link vgsales.csv
- I have choosen the Google colaboratory to run the code.
- My Google Colab Notebook on GroupByKey Transformation
- Demonstration Video: Video link for GroubByKey
- My Personal Repo on apache beam python with README file - https://github.com/nrajubn/apache-beam-python-GroupByKey
- Python
- Apache beam
- Google Colab
- First, install apache-beam using the below command.
!pip install --quiet -U apache-beam

- Install the other dependencies
!pip install apache-beam[gcp,aws,test,docs]

-
Program that performs the GroupByKey operation

-
output of the program

-
The command that lists all the files

! ls

- First upload your .csv file to your google drive account.
- The email used should be same for both google drive and google Colab accounts.
- Import the .csv file run into google colab.


# Code to read csv file into colaboratory:
!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
# Autheticate E-Mail ID
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
- To get the id of the file, right-click on the file in google drive account, select share link option, then copy the link.
- Remove the part that contains https://
- keep only the id part.
# Get File from Drive using file-ID
# Get the file
downloaded = drive.CreateFile({'id':'1b73yN7MjGytqSP5wimYAQmtByOvGGe8Y'}) # replace the id with id of file you want to access
downloaded.GetContentFile('superbowl-ads.csv')
- Command to add the result to a output file
!cat output.txt-00000-of-00001 # output file

Rohith Avisakula  Demo link
Demo link
- I have worked on GroupIntoBatches for dataset gas_retail.csv
- My Google Colab Notebook on GroupIntoBatches
- Demonstration Video link
- My personal repo link
- Python
- Apache beam
- Google Colaboratory
- Install apache beam using the below command.
pip install apache-beam
- Next install the dependencies required using below command.
!pip install apache-beam[gcp,aws,test,docs]
- The command that lists all the files.
! ls
- First sign in to google drive account and google colab with same credentials and upload .csv file to google drive account.
- Import .csv file into google colab.
# Code to read csv file into colaboratory:
!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
# Autheticate E-Mail ID
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
# Get File from Drive using file-ID
# Get the file
downloaded = drive.CreateFile({'id':'1b73yN7MjGytqSP5wimYAQmtByOvGGe8Y'}) # replace the id with id of file you want to access
downloaded.GetContentF
- Command for result
! cat results.txt-00000-of-00001
- For installation of apache beam.

- For installing required dependencies and libraries.

- Program for GroupIntoBatches.

- For importing file into colobaratory.

- For display of list of files.

- For output of the file.

Sai Rohith Gorla Demo link
Demo link
- I have worked on BatchElements for dataset games.csv
- My Google Colab Notebook on GroupIntoBatches
- Demonstration Video link
- My personal repo link
- Python
- Apache beam
- Google Colab
- First, install apache-beam using the below command.
!pip install --quiet -U apache-beam
- Install the other dependencies
!pip install apache-beam[gcp,aws,test,docs]
-
Program that performs the BatchElements operation

-
output of the program

-
The command that lists all the files

! ls

- First upload your .csv file to your google drive account.
- The email used should be same for both google drive and google Colab accounts.
- Import the .csv file run into google colab.

# Code to read csv file into colaboratory:
!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
# Autheticate E-Mail ID
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
- To get the id of the file, right-click on the file in google drive account, select share link option, then copy the link.
- Remove the part that contains https://
- keep only the id part.
# Get File from Drive using file-ID
# Get the file
downloaded = drive.CreateFile({'id':'1b73yN7MjGytqSP5wimYAQmtByOvGGe8Y'}) # replace the id with id of file you want to access
downloaded.GetContentFile('superbowl-ads.csv')
- Command to add the result to a output file
!cat output.txt-00000-of-00001 # output file
