Summarize all low-cost replication methods for Chatgpt countiously. It is believed that with the improvement of data and model fine-tuning techniques, small models suitable for various segmented fields will continue to emerge and have better performance.
Welcome everyone to provide pull requests, and I will also regularly track the latest developments in this repository!
What's New!
- Edit Structure 2023/4/25
- Add three new Motimodal models 2023/4/25
- Add Attachments 2023/4/25
- Initial construction 2022/3/27
- Chat with Open Large Language Model
- What’s Alpaca
- Models fine-tuned for application
- Alpaca-LoRA: Low-Rank LLaMA Instruct-Tuning
- LLM-Adapters
- Wombat 🐻❄️: from RLHF to RRHF, Aligning Human Preferences in a 'Right' Way
- Dolly
- Code Alpaca: An Instruction-following LLaMA Model trained on code generation instructions
- Evolving Alpaca: An Empirical Study on Instruction Tuning for Large Language Models (Alpaca-CoT)
- ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge
- Instruction Tuning with GPT-4
- DoctorGLM
- ChatGenTitle:使用百万arXiv论文信息在LLaMA模型上进行微调的论文题目生成模型
- Models fine-tuned for different languages
- 骆驼(Luotuo): Chinese-alpaca-lora
- KoAlpaca: Korean Alpaca Model based on Stanford Alpaca
- Chinese-Vicuna: A Chinese Instruction-following LLaMA-based Model —— 一个中文低资源的llama+lora方案
- Chinese LLaMA & Alpaca 大模型
- Japanese-Alpaca-LoRA
- Baize
- Chinese-ChatLLaMA
- Guanaco: A Multilingual Instruction-Following Language Model Based on LLaMA 7B
- Models finetuned for Chat
- Models fintuned for Multi-Modal Tasks
- Some Large Language Models Projects
- Some Resources for Instruction Fine-tuning.
- Attachment
- Contributors
In this website, you can try out many language models mentioned in this repository to conveniently compare their performance and choose the most suitable model for you!
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality. [Blog post] [GitHub]
- Koala: A Dialogue Model for Academic Research. [Blog post] [GitHub]
- This demo server. [GitHub]
- Vicuna: a chat assistant fine-tuned from LLaMA on user-shared conversations. This one is expected to perform best according to our evaluation.
- Koala: a chatbot fine-tuned from LLaMA on user-shared conversations and open-source datasets. This one performs similarly to Vicuna.
- ChatGLM: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型
- Alpaca: a model fine-tuned from LLaMA on 52K instruction-following demonstrations.
- LLaMA: open and efficient foundation language models
Contains: Dataset,Data Genrating Code, Finetune Code, Web Demo, Benchmark
Alpaca project aims to build and share an instruction-following LLaMA model.
- Github Page: https://github.com/tatsu-lab/stanford_alpaca
- Blog Post: https://crfm.stanford.edu/2023/03/13/alpaca.html
- Web Demo: https://crfm.stanford.edu/alpaca/
The repo contains:
- The 52K data used for fine-tuning the model.
- The code for generating the data.
- The code for fine-tuning the model.
![]()
The current Alpaca model is fine-tuned from a 7B LLaMA model [1] on 52K instruction-following data generated by the techniques in the Self-Instruct [2] paper, with some modifications that we discuss in the next section. In a preliminary human evaluation, we found that the Alpaca 7B model behaves similarly to the text-davinci-003 model on the Self-Instruct instruction-following evaluation suite [2].
[1]: LLaMA: Open and Efficient Foundation Language Models. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. https://arxiv.org/abs/2302.13971v1
[2]: Self-Instruct: Aligning Language Model with Self Generated Instructions. Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, Hannaneh Hajishirzi. https://arxiv.org/abs/2212.10560
Some applications:
-
Cleaned Alpaca Dataset:https://github.com/gururise/AlpacaDataCleaned
- This repository hosts a cleaned and curated version of a dataset used to train the Alpaca LLM (Large Language Model). The original dataset had several issues that are addressed in this cleaned version.
-
Serge - LLaMa made easy 🦙: https://github.com/nsarrazin/serge
- A chat interface based on
llama.cppfor running Alpaca models. Entirely self-hosted, no API keys needed. Fits on 4GB of RAM and runs on the CPU.
- A chat interface based on
-
Run LLaMA (and Stanford-Alpaca) inference on Apple Silicon GPUs: https://github.com/jankais3r/LLaMA_MPS
-
Alpaca Chinese Finetune Dataset: https://github.com/carbonz0/alpaca-chinese-dataset
-
🐫 self-hosted, Simple LLaMA/alpaca API & CLI written in go: go-skynet/llama-cli
A series of fine-tuned models derived from the Alpaca model. Some of them have publicly available weights, are fine-tuned for specific domains, and have better performance. These types of models are still being continuously developed.
Contains: Dataset, Data Genrating Code, Finetune Code, Model Weight, LoRA
- Github Page: https://github.com/tloen/alpaca-lora
- Discord Community: here
- Model: here
This repository contains code for reproducing the Stanford Alpaca results using low-rank adaptation (LoRA). Alpaca-LoRA provide an Instruct model of similar quality to text-davinci-003 that can run on a Raspberry Pi (for research), and the code is easily extended to the 13b, 30b, and 65b models.
In addition to the training code, which runs within five hours on a single RTX 4090, Alpaca-LoRA publish a script for downloading and inference on the foundation model and LoRA, as well as the resulting LoRA weights themselves. To fine-tune cheaply and efficiently, Alpaca-LoRA use Hugging Face's PEFT as well as Tim Dettmers' bitsandbytes.
Without hyperparameter tuning, the LoRA model produces outputs comparable to the Stanford Alpaca model.
Some applications:
- Alpaca-LoRA as a Chatbot Service: https://github.com/deep-diver/Alpaca-LoRA-Serve
Contains: Dataset, Finetune Code
- Github Page: https://github.com/tloen/alpaca-lora
- DataSet and Benchmark: https://github.com/AGI-Edgerunners/LLM-Adapters/tree/main/dataset
- Paper: https://arxiv.org/abs/2304.01933
LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models
LLM-Adapters is an easy-to-use framework that integrates various adapters into LLMs and can execute adapter-based PEFT methods of LLMs for different tasks. LLM-Adapter is an extension of HuggingFace's PEFT library, many thanks for their amazing work! Please find our paper at this link: https://arxiv.org/abs/2304.01933.
The framework includes state-of-the-art open-access LLMs: LLaMa, OPT, BLOOM, and GPT-J, as well as widely used adapters such as Bottleneck adapters, Parallel adapters, and LoRA.

Contains: Model Weight, Data Genrating Code,Dataset, Finetune Code, Web Demo

Wombats are adorable little creatures native to Australia. The first three pictures are generated from Stable Diffusion.
This is the repository for RRHF (Rank Response to align Human Feedback) and open-sourced language models Wombat. RRHF helps align large language models with human perference easier.
- Github Page:https://github.com/GanjinZero/RRHF
- Model: https://huggingface.co/GanjinZero/wombat-7b-delta
- Paper: https://github.com/GanjinZero/RRHF/blob/main/assets/rrhf.pdf
Reinforcement Learning from Human Feedback (RLHF) enables the alignment of large language models with human preference, improving the quality of interactions between humans and language models. Recent practice of RLHF uses PPO to enable the large language model optimization of such alignment. However, implementing PPO is non-trivial (where the training procedure requires interactive between policy, behavior policy, reward, value model) and it is also tedious to tuning many hyper-parameters. Our motivation is to simplify the alignment between language models with human preference, and our proposed paradigm RRHF (Rank Response from Human Feedback) can achieve such alignment as easily as conventional fine-tuning. It is simpler than PPO from the aspects of coding, model counts, and hyperparameters.

Contains: Dataset, Model Weight, Finetune Code, Manual Annotation
- Github Page: https://github.com/databrickslabs/dolly/tree/master
- Model: https://huggingface.co/databricks/dolly-v2-12b
- Dataset: https://github.com/databrickslabs/dolly/tree/master/data
Databricks’ Dolly is an instruction-following large language model trained on the Databricks machine learning platform that is licensed for commercial use. Based on pythia-12b, Dolly is trained on ~15k instruction/response fine tuning records databricks-dolly-15k generated by Databricks employees in capability domains from the InstructGPT paper, including brainstorming, classification, closed QA, generation, information extraction, open QA and summarization. dolly-v2-12b is not a state-of-the-art model, but does exhibit surprisingly high quality instruction following behavior not characteristic of the foundation model on which it is based.
+-----------------------------------+--------------+------------+--------------+-------------+-----------------+----------+----------+----------+
| model | openbookqa | arc_easy | winogrande | hellaswag | arc_challenge | piqa | boolq | gmean |
+-----------------------------------+--------------+------------+--------------+-------------+-----------------+----------+----------+----------|
| EleutherAI/pythia-2.8b | 0.348 | 0.585859 | 0.589582 | 0.591217 | 0.323379 | 0.73395 | 0.638226 | 0.523431 |
| EleutherAI/pythia-6.9b | 0.368 | 0.604798 | 0.608524 | 0.631548 | 0.343857 | 0.761153 | 0.6263 | 0.543567 |
| databricks/dolly-v2-2-8b | 0.384 | 0.611532 | 0.589582 | 0.650767 | 0.370307 | 0.742655 | 0.575535 | 0.544886 |
| EleutherAI/pythia-12b | 0.364 | 0.627104 | 0.636148 | 0.668094 | 0.346416 | 0.760065 | 0.673394 | 0.559676 |
| EleutherAI/gpt-j-6B | 0.382 | 0.621633 | 0.651144 | 0.662617 | 0.363481 | 0.761153 | 0.655963 | 0.565936 |
| databricks/dolly-v2-12b | 0.408 | 0.63931 | 0.616417 | 0.707927 | 0.388225 | 0.757889 | 0.568196 | 0.56781 |
| databricks/dolly-v2-6-9b | 0.392 | 0.633838 | 0.607735 | 0.686517 | 0.406997 | 0.750816 | 0.644037 | 0.573487 |
| databricks/dolly-v1-6b | 0.41 | 0.62963 | 0.643252 | 0.676758 | 0.384812 | 0.773667 | 0.687768 | 0.583431 |
| EleutherAI/gpt-neox-20b | 0.402 | 0.683923 | 0.656669 | 0.7142 | 0.408703 | 0.784004 | 0.695413 | 0.602236 |
+-----------------------------------+--------------+------------+--------------+-------------+-----------------+----------+----------+----------+
Contains: Dataset, Data Genrating Code, Finetune Code, Web Demo
This is the repo for the Code Alpaca project, which aims to build and share an instruction-following LLaMA model for code generation. This repo is fully based on Stanford Alpaca ,and only changes the data used for training. Training approach is the same.
- Github Page: https://github.com/sahil280114/codealpaca
- Web Demo: https://code-alpaca-demo.vercel.app/
Contains: Dataset, Data Genrating Code, Finetune Code, LoRA
This is the repository for the Evolving Alpaca project, which aims to extensively collect instruction-tuning datasets (especially the CoT datasets) and conduct an in-depth empirical study based on LLaMA model. Evolving is used to describe the continuous expansion of our instruction-tuning data collection, which will continuously enhance Alpaca's instruction-following capabilities.
- Github Page: https://github.com/PhoebusSi/Alpaca-CoT
- Web Demo: https://code-alpaca-demo.vercel.app/

Contains: Dataset, Finetune Code, Model Weight, Web Demo
This work collected more than 700 diseases and their corresponding symptoms, recommended medications, and required medical tests, and then generated 5K doctor-patient conversations. By fine-tuning models of doctor-patient conversations, these models emerge with great potential to understand patients' needs, provide informed advice, and offer valuable assistance in a variety of medical-related fields. The integration of these advanced language models into healthcare can revolutionize the way healthcare professionals and patients communicate, ultimately improving the overall quality of care and patient outcomes.
- Github Page: https://github.com/Kent0n-Li/ChatDoctor
- Model: link
- Dataset: https://github.com/Kent0n-Li/ChatDoctor#data-and-model
- WebDemo: https://huggingface.co/spaces/kenton-li/ChatDoctor
- Arixv: https://arxiv.org/abs/2303.14070
![]()
Contains: Dataset, Finetune Code
- Github Page: https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM
- Arxiv: https://arxiv.org/abs/2304.03277
This is the repo for the GPT-4-LLM, which aims to share data generated by GPT-4 for building an instruction-following LLMs with supervised learning and reinforcement learning. The repo contains:
- English Instruction-Following Data generated by GPT-4 using Alpaca prompts for fine-tuning LLMs.
- Chinese Instruction-Following Data generated by GPT-4 using Chinese prompts translated from Alpaca by ChatGPT.
- Comparison Data ranked by GPT-4 to train reward models.
- Answers on Unnatural Instructions Data from GPT-4 to quantify the gap between GPT-4 and instruction-tuned models at scale.
Contains: Dataset, Finetune Code, LoRA, Model Weight
中文问诊模型, 基于 ChatGLM-6B + lora 进行finetune
finetune代码来自 https://github.com/ssbuild/chatglm_finetuning
- Github Page: https://github.com/xionghonglin/DoctorGLM
- Model: https://github.com/xionghonglin/DoctorGLM/tree/main/Doctor_GLM
- DataSet: https://github.com/Toyhom/Chinese-medical-dialogue-data
Contains: Dataset, LoRA, Model Weight
-
Github Page: https://github.com/WangRongsheng/ChatGenTitle
-
Model: https://github.com/WangRongsheng/ChatGenTitle#release

通过 arXiv 上开放的论文信息,我们构建了一个包含 220 万篇论文元信息的数据库。这些数据通过数据清洗等被构建成了可以用于大模型微调的数据对。将这些论文元信息引入大模型微调,它可以对生成论文题目涉及的难点产生积极影响,它可以从以下几个方面提供帮助:
\1. 提供更准确、广泛的语言模型:大模型通常使用了大量数据进行训练,因此其语言模型可以更准确地解释自然语言,能够应对更多的语言场景,提升论文题目的语言表达能力;
\2. 提供更加精准的语义理解:大模型采用了深度学习的技术手段,能够构建语言的高维向量表示,从而提供更准确的语义理解能力,帮助生成更精确、准确的论文题目;
\3. 增强创造性和创新性:大模型使用了大量的训练数据,并能够从数据中提取规律,从而提供更多的词汇或句子组合方式,增强了生成论文题目的创造性和创新性;
\4. 提高效率:相比传统的手动方式,使用大模型来生成论文题目可以极大地提高效率,不仅减少了需要写出标题的时间,同时也不容易产生显著的错误,提高了输出的质量。
Contains: Data Genrating Code, Model Weight, LoRA, Benchmark
A Chinese finetuned instruction LLaMA.
- Github Page: https://github.com/LC1332/Chinese-alpaca-lora
- Model: https://huggingface.co/silk-road/luotuo-lora-7b-0.3

Contains: Dataset, Data Genrating Code, Finetune Code, Model Weight, LoRA, Benchmark
The Korean Alpaca model is learned in the same way as the Stanford Alpaca model.
Benchmark
-
Github Page: https://github.com/Beomi/KoAlpaca
-
Telegram app: http://pf.kakao.com/_wdRxcxj
Contains: Dataset, Data Genrating Code, Finetune Code, Model Weight, LoRA, Benchmark
This is the repo for the Chinese-Vicuna project, which aims to build and share an instruction-following Chinese LLaMA model which can run on a single Nvidia RTX-2080TI, that why we named this project Vicuna, small but strong enough !
- Github Page: https://github.com/Facico/Chinese-Vicuna
- Model: https://github.com/Facico/Chinese-Vicuna/tree/master/lora-Vicuna/checkpoint-final

Contains: Model Weight, LoRA,
To promote open research of large models in the Chinese NLP community, this project has open-sourced the Chinese LLaMA model and the Alpaca large model with instruction fine-tuning. These models expand the Chinese vocabulary based on the original LLaMA and use Chinese data for secondary pre-training, further enhancing Chinese basic semantic understanding. Additionally, the project uses Chinese instruction data for fine-tuning on the basis of the Chinese LLaMA, significantly improving the model's understanding and execution of instructions.
- Github Page:https://github.com/ymcui/Chinese-LLaMA-Alpaca
Note: The following models cannot be used directly and must be reconstructed following the steps provided in this project's Model Reconstruction section.
| Model Name | Type | Base Model Required for Reconstruction | Size[2] | LoRA Download Link | SHA256[3] |
|---|---|---|---|---|---|
| Chinese-LLaMA-7B | General | Original LLaMA-7B[1] | 770M | [Cloud Disk Link] (Password: 33hb) | 39b86b......fe0e60 |
| Chinese-Alpaca-7B | Fine-tuned for Instructions | Original LLaMA-7B[1] | 790M | [Cloud Disk Link] (Password:923e) | 9bb5b6......ce2d87 |

Contains: Dataset, Finetune Code, LoRA,
A Japanese finetuned instruction LLaMA.
- Github Page: https://github.com/masa3141/japanese-alpaca-lora
Contains: Dataset, Finetune Code, LoRA, Model Weight,Web Demo
Baize is an open-source chat model fine-tuned with LoRA. It uses 100k dialogs generated by letting ChatGPT chat with itself. We also use Alpaca's data to improve its performance. We have released 7B, 13B and 30B models. 60B model coming soon. Please refer to the paper for more details.
- Github Page: https://github.com/project-baize/baize/tree/main
- Model: https://huggingface.co/project-baize
- Web Demo: https://huggingface.co/spaces/project-baize/baize-lora-7B
- Dataset: https://github.com/project-baize/baize/blob/main/data
- Paper: https://arxiv.org/abs/2304.01196

Contains: Dataset, Finetune Code, Model Weight
- Github Page: https://github.com/ydli-ai/Chinese-ChatLLaMA
- Model: https://huggingface.co/P01son/ChatLLaMA-zh-7B
- Dataset: https://github.com/dbiir/UER-py/wiki/%E9%A2%84%E8%AE%AD%E7%BB%83%E6%95%B0%E6%8D%AE
本项目向社区提供中文对话模型 ChatLLama 、中文基础模型 LLaMA-zh 及其训练数据。 模型基于 TencentPretrain 多模态预训练框架构建, 项目也将陆续开放 7B、13B、30B、65B 规模的中文基础模型 LLaMA-zh 权重。
ChatLLaMA 支持简繁体中文、英文、日文等多语言。 LLaMA 在预训练阶段主要使用英文,为了将其语言能力迁移到中文上,首先进行中文增量预训练, 使用的语料包括中英翻译、中文维基/百度百科、社区互动问答、科学文献等。再通过指令微调得到 ChatLLaMA。

Contains: Model Weight, Dataset, Lora
Guanaco is an instruction-following language model trained on Meta's LLaMA 7B model. Building upon the original 52K data from the Alpaca model, we added an additional 534,530 entries, covering English, Simplified Chinese, Traditional Chinese (Taiwan), Traditional Chinese (Hong Kong), Japanese, Deutsch and various linguistic and grammatical tasks. By retraining and optimizing the model with this rich data, Guanaco demonstrates excellent performance and potential in a multilingual environment.
To promote openness and replicability in research, we have made the Guanaco Dataset publicly available and plan to release the model weights in the future. By providing these resources, we hope to encourage more researchers to engage in related research and jointly advance the development of instruction-following language models.
When using the Guanaco model, please note the following points: - The Guanaco model has not yet been filtered for harmful, biased, or explicit content. During use, outputs that do not conform to ethical norms may be generated. Please pay special attention to this issue in research or practical applications.
- Github Page: https://guanaco-model.github.io/
- Dataset: https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
- Model:
This type of model is mainly fine-tuned for dialogue tasks, so it has good conversation response capabilities.
Contains: Dataset, Evalutaion, Finetune Code, Web Demo
- Blog: https://bair.berkeley.edu/blog/2023/04/03/koala/
- Model: https://huggingface.co/young-geng/koala/tree/main

Koala, a chatbot trained by fine-tuning Meta’s LLaMA on dialogue data gathered from the web. We describe the dataset curation and training process of our model, and also present the results of a user study that compares our model to ChatGPT and Stanford’s Alpaca. Our results show that Koala can effectively respond to a variety of user queries, generating responses that are often preferred over Alpaca, and at least tied with ChatGPT in over half of the cases.

- An online interactive demo of Koala
- EasyLM: our open source framework we used to train Koala
- The code for preprocessing our training data
- Our test set of queries
- Koala model weights diff against the base LLaMA model
Contains: Dataset, Finetune Code, Web Demo
- Github Page: https://github.com/lm-sys/FastChat
- Blog: https://vicuna.lmsys.org/
- Dataset: https://github.com/lm-sys/FastChat/blob/main/playground/data/alpaca-data-conversation.json
- WebDemo: https://chat.lmsys.org/
Vicuna-13B, an open-source chatbot trained by fine-tuning LLaMA on user-shared conversations collected from ShareGPT. Preliminary evaluation using GPT-4 as a judge shows Vicuna-13B achieves more than 90%* quality of OpenAI ChatGPT and Google Bard while outperforming other models like LLaMA and Stanford Alpaca in more than 90%* of cases. The cost of training Vicuna-13B is around $300. The training and serving code, along with an online demo, are publicly available for non-commercial use.

Contains: Model Weight, Web Demo
- Github Page: https://github.com/THUDM/ChatGLM-6B
- Blog: https://chatglm.cn/blog
- Model: Hugging Face Hub
ChatGLM-6B is an open-source, bilingual (Chinese and English) conversational language model based on the General Language Model (GLM) architecture with 6.2 billion parameters. With model quantization technology, users can deploy it locally on consumer-grade graphics cards (with a minimum of only 6GB VRAM at INT4 quantization level). ChatGLM-6B uses similar techniques to ChatGPT and has been optimized for Chinese question answering and dialogue. After training on approximately 1 trillion identifiers in both Chinese and English, combined with supervised fine-tuning, feedback self-help, human feedback reinforcement learning technologies, the 62 billion parameter ChatGLM-6B can generate responses that are quite consistent with human preferences.
Some applications:
- A cost-effective implementation plan for ChatGPT, based on Tsinghua's ChatGLM-6B + LoRA for finetuning: https://github.com/mymusise/ChatGLM-Tuning
- Chatglm 6b finetuning and alpaca finetuning: https://github.com/ssbuild/chatglm_finetuning
- A webui for ChatGLM made by THUDM.https://github.com/Akegarasu/ChatGLM-webui
- 图文生成版 Visual OpenLLM:https://github.com/visual-openllm/visual-openllm
Contains: Model Weight, Data Genrating Code,Dataset
- Github Page: https://github.com/LianjiaTech/BELLE
- Model: https://huggingface.co/BelleGroup
- Zhihu: https://zhuanlan.zhihu.com/p/616079388
The goal of this project is to promote the development of the open-source community for Chinese language large-scale conversational models. This project optimizes Chinese performance in addition to original Alpaca. The model finetuning uses only data generated via ChatGPT (without other data).
- Data Release: The Chinese dataset generated 1M + 0.5M, using Stanford Alpaca as reference
- The model optimized based on BLOOMZ-7B1-mt: BELLE-7B-0.2M,BELLE-7B-0.6M,BELLE-7B-1M,BELLE-7B-2M
- The model optimized based on LLAMA: BELLE-LLAMA-7B-0.6M,BELLE-LLAMA-7B-2M
Contains: Model Weight, Pretrain Code,Finetune Code, Web Demo
- Github Page: https://github.com/clue-ai/ChatYuan
- Model: https://huggingface.co/ClueAI/ChatYuan-large-v2, https://modelscope.cn/models/ClueAI/ChatYuan-large-v2/summary
- Web Demo: https://huggingface.co/spaces/ClueAI/ChatYuan-large-v2
- Discord: https://discord.gg/hUVyMRByaE
ChatYuan-large-v2是一个支持中英双语的功能型对话语言大模型。ChatYuan-large-v2使用了和 v1版本相同的技术方案,在微调数据、人类反馈强化学习、思维链等方面进行了优化。
ChatYuan large v2 is an open-source large language model for dialogue, supports both Chinese and English languages, and in ChatGPT style.
ChatYuan-large-v2是ChatYuan系列中以轻量化实现高质量效果的模型之一,用户可以在消费级显卡、 PC甚至手机上进行推理(INT4 最低只需 400M )。
Contains: Model Weight, Dataset, Finetune Code,
- Github Page: https://github.com/yangjianxin1/Firefly
- Model: https://huggingface.co/YeungNLP/firefly-2b6
- Dataset: https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
Firefly(流萤) 是一个开源的中文对话式大语言模型,使用指令微调(Instruction Tuning)在中文数据集上进行调优。同时使用了词表裁剪、ZeRO、张量并行等技术,有效降低显存消耗和提高训练效率。 在训练中,我们使用了更小的模型参数量,以及更少的计算资源。
我们构造了许多与中华文化相关的数据,以提升模型这方面的表现,如对联、作诗、文言文翻译、散文、金庸小说等。
- 数据集:firefly-train-1.1M , 一份高质量的包含1.1M中文多任务指令微调数据集,包含23种常见的中文NLP任务的指令数据。对于每个任务,由人工书写若干指令模板,保证数据的高质量与丰富度。
- 模型裁剪:LLMPruner:大语言模型裁剪工具 ,使用词表裁剪技术对多语种大语言模型进行权重裁剪,保留预训练知识的前提下,有效减少模型参数量,提高训练效率,并分享裁剪后的多种参数规模的Bloom模型权重。
- 权重分享:在bloom-1b4-zh 和bloom-2b6-zh 的基础上,进行指令微调,获得两种参数规模的中文模型:firefly-1b4 和firefly-2b6
- 训练代码:开源训练代码,支持张量并行、ZeRO、Gemini异构内存空间管理等大模型训练策略。可实现仅使用一张显卡,训练1B-2B参数量的模型(待整理后开源)
Contains: Model Weight, Dataset,LoRa
- Github Page: https://github.com/nomic-ai/gpt4all
- Model: https://huggingface.co/nomic-ai/gpt4all-lora
- Document: Technical Report
- Discord: Discord
Demo, data and code to train an assistant-style large language model with ~800k GPT-3.5-Turbo Generations based on LLaMa
Contains: Model Weight, Dataset, Finetune Code, Web Demo
- Github Page: https://github.com/BlinkDL/ChatRWKV
- Model: https://huggingface.co/BlinkDL
- Document: https://zhuanlan.zhihu.com/p/616351661
- Discord: https://discord.gg/bDSBUMeFpc
ChatRWKV is like ChatGPT but powered by my RWKV (100% RNN) language model, which is the only RNN (as of now) that can match transformers in quality and scaling, while being faster and saves VRAM.
Contains: Model Weight, Dataset, Finetune Code, Web Demo
基于ChatGLM-6B+LoRA在指令数据集上进行微调
基于deepspeed支持多卡微调,速度相比单卡提升8-9倍
- Github Page:https://github.com/yanqiangmiffy/InstructGLM
Contains: Model Weight, Dataset, Finetune Code
This repository contains code for fintune ChatGLM-6b using low-rank adaptation (LoRA).
We also provide a finetuned weight.
The minimum required GPU memory is 24G, RTX3090 is enough for training.
- 2022/4/12: Add tensorboard. Support finetune the entire model (Much faster convergence and usually has better performance)
- 2022/3/28: Optimized code structure, more simple and clear. Add training instruction.
- 2022/3/24: Support Multi-GPU training, DeepSpeed, Batch collate. Using accelerate to launch
train.py
Multimodal models refer to the use of technologies such as prompt, adapter, and Lora to provide prompts or fine-tuning for large language models, enabling them to understand multimodal information such as images. Multimodal language models may have stronger capabilities, but research has also shown that multimodal fine-tuning can damage the performance of the language model itself.
Contains: Dataset, Finetune Code, Model Weight, Web Demo
- Github Page: https://github.com/haotian-liu/LLaVA
- Blog Page: https://llava-vl.github.io/
- Paper: https://arxiv.org/abs/2304.08485
- WebDemo: https://llava.hliu.cc/
- Dataset: https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
- Model: https://huggingface.co/liuhaotian/LLaVA-13b-delta-v0
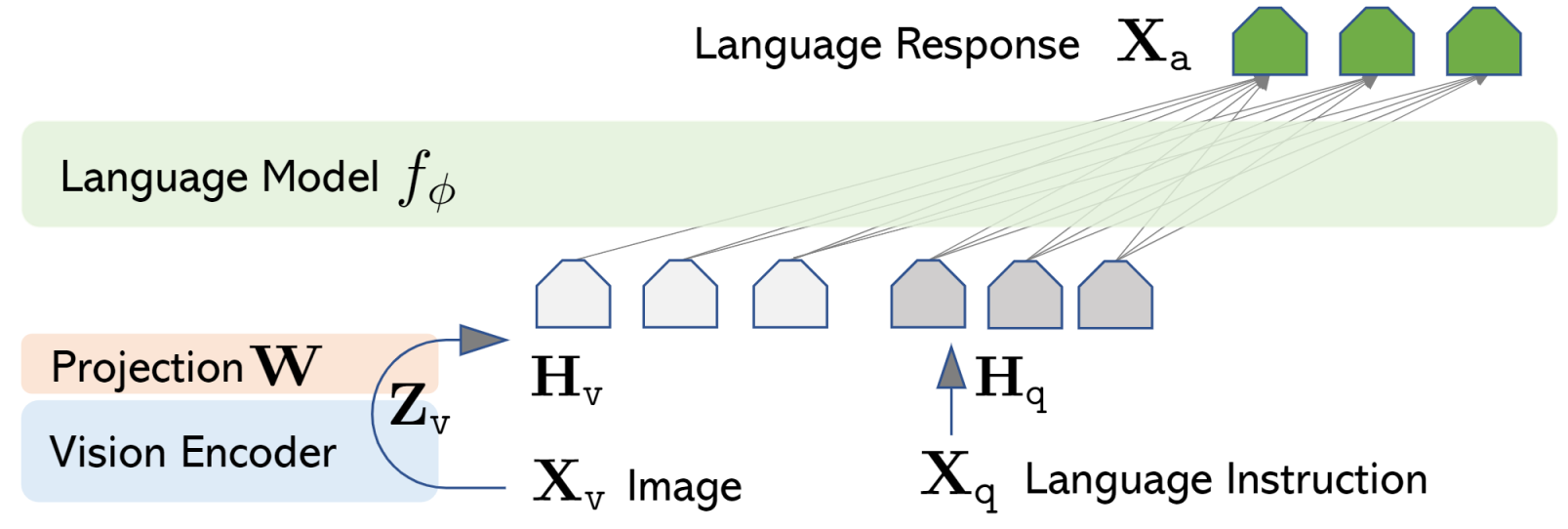
LLaVA represents a novel end-to-end trained large multimodal model that combines a vision encoder and Vicuna for general-purpose visual and language understanding, achieving impressive chat capabilities mimicking spirits of the multimodal GPT-4 and setting a new state-of-the-art accuracy on Science QA.
-
Multimodal Instruct Data. We present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data.
-
LLaVA Model. We introduce LLaVA (Large Language-and-Vision Assistant), an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.
-
Performance. Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%.
-
Open-source. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available.

Contains: Dataset, Finetune Code, Model Weight, Web Demo
- Github Page: https://github.com/Vision-CAIR/MiniGPT-4
- Blog Page: https://minigpt-4.github.io/
- Paper: https://github.com/Vision-CAIR/MiniGPT-4/blob/main/MiniGPT_4.pdf
- WebDemo: https://minigpt-4.github.io/
MiniGPT-4 aligns a frozen visual encoder from BLIP-2 with a frozen LLM, Vicuna, using just one projection layer.
We train MiniGPT-4 with two stages. The first traditional pretraining stage is trained using roughly 5 million aligned image-text pairs in 10 hours using 4 A100s. After the first stage, Vicuna is able to understand the image. But the generation ability of Vicuna is heavilly impacted.
To address this issue and improve usability, we propose a novel way to create high-quality image-text pairs by the model itself and ChatGPT together. Based on this, we then create a small (3500 pairs in total) yet high-quality dataset.
The second finetuning stage is trained on this dataset in a conversation template to significantly improve its generation reliability and overall usability. To our surprise, this stage is computationally efficient and takes only around 7 minutes with a single A100.
MiniGPT-4 yields many emerging vision-language capabilities similar to those demonstrated in GPT-4.
Contains: Dataset, Finetune Code
- Github Page:https://github.com/Vision-CAIR/VisualGPT
- Paper: VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning
The ability to quickly learn from a small quantity oftraining data widens the range of machine learning applications. In this paper, we propose a data-efficient image captioning model, VisualGPT, which leverages the linguistic knowledge from a large pretrained language model(LM). A crucial challenge is to balance between the use of visual information in the image and prior linguistic knowledge acquired from pretraining. We designed a novel self-resurrecting encoder-decoder attention mechanism to quickly adapt the pretrained LM as the language decoder ona small amount of in-domain training data. The proposed self-resurrecting activation unit produces sparse activations but has reduced susceptibility to zero gradients. We train the proposed model, VisualGPT, on 0.1%, 0.5% and 1% of MSCOCO and Conceptual Captions training data. Under these conditions, we outperform the best baseline model by up to 10.8% CIDEr on MS COCO and upto 5.4% CIDEr on Conceptual Captions. Further, Visual-GPT achieves the state-of-the-art result on IU X-ray, a medical report generation dataset. To the best of our knowledge, this is the first work that improves data efficiency of image captioning by utilizing LM pretrained on unimodal data.

Contains: Prompts,
Needs: Openai Keys
Discover the powerful questioning ability of LLMs and their great potential for acquiring information effectively. As an exploration, we introduce ChatCaptioner in image captioning. ChatCaptioner enrichs the image caption of BLIP-2 by prompting ChatGPT to keep asking informative questions to BLIP-2 and summarize the conversation at the end as the final caption.
Official repository of ChatCaptioner and Video ChatCaptioner.
-
Gihub Page: https://github.com/Vision-CAIR/ChatCaptioner
-
ChatCaptioner paper ChatGPT Asks, BLIP-2 Answers: Automatic Questioning Towards Enriched Visual Descriptions
-
Video ChatCaptioner paper Video ChatCaptioner: Towards the Enriched Spatiotemporal Descriptions

Large language models provide powerful foundational capabilities for generative models and are also the basis for model fine-tuning. It is difficult to define what scale of language model can be considered a large language model, as the size of the model's parameters is related to the industry's hardware level (computing power). The scale of large models continues to evolve, and definitions are changing. In addition to OpenAI's GPT series available through an interface, this article lists some other excellent downloadable model weights for commonly used large language models.
Compared to the relatively closed usage of OpenAI's model, fine-tuning this type of language model is also a good choice.
Contains: Model Weights, Web Demo, Finetune Code, Benchmark
CodeGeeX, a large-scale multilingual code generation model with 13 billion parameters, pre-trained on a large code corpus of more than 20 programming languages. As of June 22, 2022, CodeGeeX has been trained on more than 850 billion tokens on a cluster of 1,536 Ascend 910 AI Processors. CodeGeeX has several unique features:
-
Multilingual Code Generation: CodeGeeX has good performance for generating executable programs in several mainstream programming languages, including Python, C++, Java, JavaScript, Go, etc. DEMO
-
Crosslingual Code Translation: CodeGeeX supports the translation of code snippets between different languages. Simply by one click, CodeGeeX can transform a program into any expected language with a high accuracy. DEMO
-
Customizable Programming Assistant: CodeGeeX is available in the VS Code extension marketplace for free. It supports code completion, explanation, summarization and more, which empower users with a better coding experience. VS Code Extension
-
Open-Source and Cross-Platform: All codes and model weights are publicly available for research purposes. CodeGeeX supports both Ascend and NVIDIA platforms. It supports inference in a single Ascend 910, NVIDIA V100 or A100. Apply Model Weights
-
Github Page: https://github.com/THUDM/CodeGeeX
Some applications:
- OneFlow Code: https://github.com/Oneflow-Inc/oneflow
Github Page: https://github.com/AetherCortex/Llama-X
This is the repo for the Llama-X, which aims to:
- Progressively improve the performance of LLaMA to SOTA LLM with open-source community.
- Conduct Llama-X as an open academic research which is long-term, systematic and rigorous.
- Save the repetitive work of community and we work together to create more and faster increment.
The project will follow these principles:
- We will publish all the
code,model,data, andexperimentsdetails. - We will
continuouslyimprove the model version by version and open thenewestmethod. - We will summary the method of each main version as
academic papers. - We announce a complete research plan. The contributors are wellcome to cooperate with each other to progressively improve Llama-X through iteration of the target versions.
- The check-in of the new model must achieve significant improvement with current version on automatic evaluation.

LlamaIndex is a simple, flexible interface between your external data and LLMs. It provides the following tools in an easy-to-use fashion:
-
Offers data connectors to your existing data sources and data formats (API's, PDF's, docs, SQL, etc.)
-
Provides indices over your unstructured and structured data for use with LLM's. These indices help to abstract away common boilerplate and pain points for in-context learning:
- Storing context in an easy-to-access format for prompt insertion.
- Dealing with prompt limitations (e.g. 4096 tokens for Davinci) when context is too big.
- Dealing with text splitting.
-
Provides users an interface to query the index (feed in an input prompt) and obtain a knowledge-augmented output.
-
Offers you a comprehensive toolset trading off cost and performance
-
Github Page: https://github.com/jerryjliu/llama_index
-
Community: https://llamahub.ai
An extensible, convenient, and efficient toolbox for finetuning large machine learning models, designed to be user-friendly, speedy and reliable, and accessible to the entire community.

- Github Page: https://github.com/OptimalScale/LMFlow
- Documentation: https://optimalscale.github.io/LMFlow/
The success of Transformer models has pushed the deep learning model scale to billions of parameters. Due to the limited memory resource of a single GPU, However, the best practice for choosing the optimal parallel strategy is still lacking, since it requires domain expertise in both deep learning and parallel computing. The Colossal-AI system addressed the above challenge by introducing a unified interface to scale your sequential code of model training to distributed environments. It supports parallel training methods such as data, pipeline, tensor, and sequence parallelism, as well as heterogeneous training methods integrated with zero redundancy optimizer. Compared to the baseline system, Colossal-AI can achieve up to 2.76 times training speedup on large-scale models.
-
Github Page: https://github.com/hpcaitech/ColossalAI
-
Arixv: Paper
人工精调的中文对话数据集和一段chatglm的微调代码
当前的聊天对话模型数据集主要都是由英文构成,但是当前中文聊天模型构建的需求也较为迫切,因此我们将斯坦福的alpaca数据集进行中文翻译,并再制造一些对话数据,并开源提供。
- Github Page: https://github.com/hikariming/alpaca_chinese_dataset
