https://learn.microsoft.com/en-us/training/paths/prepare-for-ai-engineering/ https://learn.microsoft.com/en-us/training/paths/provision-manage-azure-cognitive-services/
-> Select the appropriate service for a vision solution
-> Select the appropriate service for a language analysis solution
-> Select the appropriate service for a decision support solution
-> Select the appropriate service in Cognitive Services for a speech solution
-> Select the appropriate Applied AI services
-> Manage account keys
-> Manage authentication for a resource
-> Secure services by using Azure Virtual Networks
-> Plan for a solution that meets Responsible AI principles
-> Create an Azure AI resource
-> Configure diagnostic logging
-> Manage costs for Azure AI services
-> Monitor an Azure AI resource
-> Determine a default endpoint for a service
-> Create a resource by using the Azure portal
-> Integrate Azure AI services into a continuous integration/continuous deployment (CI/CD) pipeline
-> Plan a container deployment
-> Implement prebuilt containers in a connected environment
-> Create a solution that uses Anomaly Detector, part of Cognitive Services
-> Create a solution that uses Azure Content Moderator
-> Create a solution that uses Personalizer, part of Cognitive Services
-> Create a solution that uses Azure Metrics Advisor, part of Azure Applied AI Services
-> Create a solution that uses Azure Immersive Reader, part of Azure Applied AI Services
| Feature | Capability |
|---|---|
| Automated machine learning | This feature enables non-experts to quickly create an effective machine learning model from data. |
| Azure Machine Learning designer | A graphical interface enabling no-code development of machine learning solutions. |
| Data and compute management | Cloud-based data storage and compute resources that professional data scientists can use to run data experiment code at scale. |
| Pipelines | Data scientists, software engineers, and IT operations professionals can define pipelines to orchestrate model training, deployment, and management tasks. |
Language
- Text analysis
- Question answering
- Language understanding
- Translation
Speech
- Speech to Text
- Text to Speech
- Speech Translation
- Speaker Recognition
Vision
- Image analysis
- Video analysis
- Image classification
- Object detection
- Facial analysis
- Optical character recognition
Decision
- Anomaly detection
- Content moderation
- Content personalization
You can use Cognitive Services to build your own AI solutions, and they also underpin Azure Applied AI Services that provide out-of-the-box solutions for common AI scenarios. Applied AI Services include:
Azure Form Recognizer - an optical character recognition (OCR) solution that can extract semantic meaning from forms, such as invoices, receipts, and others.
Azure Metrics Advisor - A service build on the Anomaly Detector cognitive service that simplifies real-time monitoring and response to critical metrics.
Azure Video Analyzer for Media - A comprehensive video analysts solution build on the Video Indexer cognitive service.
Azure Immersive Reader - A reading solution that supports people of all ages and abilities.
Azure Bot Service - A cloud service for delivering conversational AI solutions, or bots.
Azure Cognitive Search - A cloud-scale search solution that uses cognitive services to extract insights from data and documents.
------------------------------------------------------------------------------------------------------------------
Regenerate keys You should regenerate keys regularly to protect against the risk of keys being shared with or accessed by unauthorized users. You can regenerate keys by using the visual interface in the Azure portal, or by using the az cognitiveservices account keys regenerate Azure command-line interface (CLI) command.
Each cognitive service is provided with two keys, enabling you to regenerate keys without service interruption. To accomplish this:
Configure all production applications to use key 2. Regenerate key 1 Switch all production applications to use the newly regenerated key 1. Regenerate key 2.
------------------------------------------------------------------------------------------------------------------
To use the pricing calculator to estimate Cognitive Services costs, create a new estimate and select Azure Cognitive Services in the AI + Machine Learning category.
Diagnostic logging enables you to capture rich operational data for a Cognitive Services resource, which can be used to analyze service usage and troubleshoot problems.
Azure Log Analytics - a service that enables you to query and visualize log data within the Azure portal.
Azure Storage - a cloud-based data store that you can use to store log archives (which can be exported for analysis in other tools as needed).
------------------------------------------------------------------------------------------------------------------
Containers enable you to host Azure Cognitive Services either on-premises or on Azure. For example, if your application uses sensitive data in an on-premises SQL Server to call a cognitive service, you can deploy Cognitive Services in containers on the same network.
What is a container?
A container comprises an application or service and the runtime components needed to run it, while abstracting the underlying operating system and hardware. In practice, this abstraction results in two significant benefits:
-
Containers are portable across hosts, which may be running different operating systems or use different hardware - making it easier to move an application and all its dependencies.
-
A single container host can support multiple isolated containers, each with its own specific runtime configuration - making it easier to consolidate multiple applications that have different configuration requirement.
A container is encapsulated in a container image that defines the software and configuration it must support. Images can be stored in a central registry, such as Docker Hub, or you can maintain a set of images in your own registry.
- A Docker* server.
- An Azure Container Instance (ACI).
- An Azure Kubernetes Service (AKS) cluster.
To deploy and use a Cognitive Services container, the following three activities must occur:
-
The container image for the specific Cognitive Services API you want to use is downloaded and deployed to a container host, such as a local Docker server, an Azure Container Instance (ACI), or Azure Kubernetes Service (AKS).
-
Client applications submit data to the endpoint provided by the containerized service, and retrieve results just as they would from a Cognitive Services cloud resource in Azure.
-
Periodically, usage metrics for the containerized service are sent to a Cognitive Services resource in Azure in order to calculate billing for the service.

| Feature | Image |
|---|---|
| Key Phrase Extraction | This feature enables non-experts to quickly create an effective machine learning model from data. |
| Language Detection | mcr.microsoft.com/azure-cognitive-services/language |
| Sentiment Analysis v3 (English) | mcr.microsoft.com/azure-cognitive-services/sentiment:3.0-en |
When you deploy a Cognitive Services container image to a host, you must specify three settings.
| Setting | Description |
|---|---|
| ApiKey | Key from your deployed Azure Cognitive Service; used for billing. |
| Billing | Endpoint URI from your deployed Azure Cognitive Service; used for billing. |
| Eula | Value of accept to state you accept the license for the container. |
https://microsoftlearning.github.io/AI-102-AIEngineer/Instructions/04-use-a-container.html
Note: In this exercise, you’ve deployed the cognitive services container image for text translation to an Azure Container Instances (ACI) resource. You can use a similar approach to deploy it to a Docker host on your own computer or network by running the following command (on a single line) to deploy the language detection container to your local Docker instance, replacing and with your endpoint URI and either of the keys for your cognitive services resource.
docker run --rm -it -p 5000:5000 --memory 4g --cpus 1 mcr.microsoft.com/azure-cognitive-services/textanalytics/language Eula=accept Billing=<yourEndpoint> ApiKey=<yourKey> ------------------------------------------------------------------------------------------------------------------
Anomaly Detector is an AI service with a set of APIs, which enables you to monitor and detect anomalies in your time series data with little machine learning (ML) knowledge, either batch validation or real-time inference.
https://learn.microsoft.com/en-us/azure/cognitive-services/anomaly-detector/overview
| Feature | Description |
|---|---|
| Univariate Anomaly Detection | This feature enables non-experts to quickly create an effective machine learning model from data. |
| Multivariate Anomaly Detection | Detect anomalies in multiple variables with correlations, which are usually gathered from equipment or other complex system. The underlying model used is a Graph Attention Network. |
Enables you to monitor and detect abnormalities in your time series data without having to know machine learning. The algorithms adapt by automatically identifying and applying the best-fitting models to your data, regardless of industry, scenario, or data volume.
| Feature | Description |
|---|---|
| Streaming detection | Detect anomalies in your streaming data by using previously seen data points to determine if your latest one is an anomaly. This operation generates a model using the data points you send, and determines if the target point is an anomaly. By calling the API with each new data point you generate, you can monitor your data as it's created. |
| Batch detection | Use your time series to detect any anomalies that might exist throughout your data. This operation generates a model using your entire time series data, with each point analyzed with the same model. |
| Change points detection | Use your time series to detect any trend change points that exist in your data. This operation generates a model using your entire time series data, with each point analyzed with the same model. |
The Multivariate Anomaly Detection APIs further enable developers by easily integrating advanced AI for detecting anomalies from groups of metrics, without the need for machine learning knowledge or labeled data. Dependencies and inter-correlations between up to 300 different signals are now automatically counted as key factors.
The following request URLs must be combined with the appropriate endpoint for your subscription. For example:
https://.api.cognitive.microsoft.com/anomalydetector/v1.0/timeseries/entire/detect
- Batch detection
To detect anomalies throughout a batch of data points over a given time range, use the following request URI with your time series data:
/timeseries/entire/detect.
- Streaming detection
To continuously detect anomalies on streaming data, use the following request URI with your latest data point:
/timeseries/last/detect.
By sending new data points as you generate them, you can monitor your data in real time. A model will be generated with the data points you send, and the API will determine if the latest point in the time series is an anomaly.
------------------------------------------------------------------------------------------------------------------
Azure Content Moderator is an AI service that lets you handle content that is potentially offensive, risky, or otherwise undesirable. It includes the AI-powered content moderation service which scans text, image, and videos and applies content flags automatically.
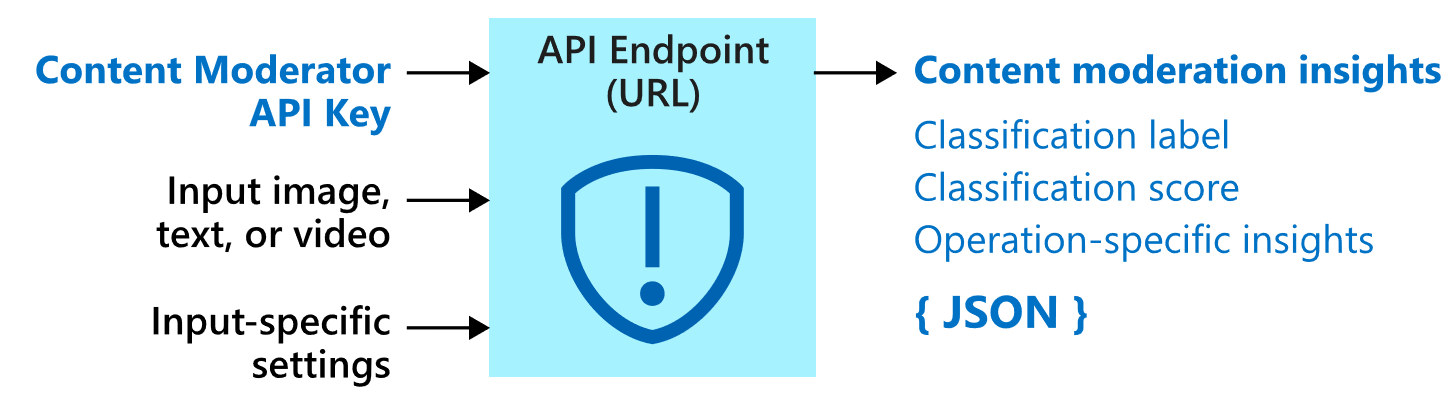
------------------------------------------------------------------------------------------------------------------
https://learn.microsoft.com/en-us/azure/cognitive-services/personalizer/what-is-personalizer
Azure Personalizer is an AI service that your applications make smarter decisions at scale using reinforcement learning. Personalizer processes information about the state of your application, scenario, and/or users (contexts), and a set of possible decisions and related attributes (actions) to determine the best decision to make.
Personalizer can determine the best actions to take in a variety of scenarios:
- E-commerce: What product should be shown to customers to maximize the likelihood of a purchase?
- Content recommendation: What article should be shown to increase the click-through rate?
- Content design: Where should an advertisement be placed to optimize user engagement on a website?
- Communication: When and how should a notification be sent to maximize the chance of a response?
https://learn.microsoft.com/en-us/rest/api/personalizer/
------------------------------------------------------------------------------------------------------------------
https://learn.microsoft.com/en-us/azure/applied-ai-services/metrics-advisor/overview
Metrics Advisor is a part of Azure Applied AI Services that uses AI to perform data monitoring and anomaly detection in time series data. The service automates the process of applying models to your data, and provides a set of APIs and a web-based workspace for data ingestion, anomaly detection, and diagnostics - without needing to know machine learning.
Use Metrics Advisor to:
- Analyze multi-dimensional data from multiple data sources
- Identify and correlate anomalies
- Configure and fine-tune the anomaly detection model used on your data
- Diagnose anomalies and help with root cause analysis

https://learn.microsoft.com/en-us/azure/applied-ai-services/immersive-reader/overview
Immersive Reader is part of Azure Applied AI Services, and is an inclusively designed tool that implements proven techniques to improve reading comprehension for new readers, language learners, and people with learning differences such as dyslexia.
########################################################################################
https://learn.microsoft.com/en-us/training/paths/extract-text-from-images-documents/
-> Select appropriate visual features to meet image processing requirements
-> Create an image processing request to include appropriate image analysis features
-> Interpret image processing responses
-> Extract text from images or PDFs by using the Computer Vision service
-> Convert handwritten text by using the Computer Vision service
-> Extract information using prebuilt models in Azure Form Recognizer
-> Build and optimize a custom model for Form Recognizer
Implement image classification and object detection by using the Custom Vision service, part of Azure Cognitive Services
-> Choose between image classification and object detection models
-> Specify model configuration options, including category, version, and compact
-> Label images
-> Train custom image models, including classifiers and detectors
-> Manage training iterations
-> Evaluate model metrics
-> Publish a trained iteration of a model
-> Export a model to run on a specific target
-> Implement a Custom Vision model as a Docker container
-> Interpret model responses
-> Process a video by using Azure Video Indexer
-> Extract insights from a video or live stream by using Azure Video Indexer
-> Implement content moderation by using Azure Video Indexer
-> Integrate a custom language model into Azure Video Indexer
- Description and tag generation - determining an appropriate caption for an image, and identifying relevant "tags" that can be used as keywords to indicate its subject.
- Object detection - detecting the presence and location of specific objects within the image.
- Face detection - detecting the presence, location, and features of human faces in the image.
- Image metadata, color, and type analysis - determining the format and size of an image, its dominant color palette, and whether it contains clip art.
- Category identification - identifying an appropriate categorization for the image, and if it contains any known landmarks.
- Brand detection - detecting the presence of any known brands or logos.
- Moderation rating - determine if the image includes any adult or violent content.
- Optical character recognition - reading text in the image.
- Smart thumbnail generation - identifying the main region of interest in the image to create a smaller "thumbnail" version.
{
"categories": [
{
"name": "_outdoor_mountain",
"confidence": "0.9"}
],
"adult": {"isAdultContent": "false", …},
"tags": [
{"name": "outdoor", "confidence": 0.9},
{"name": "mountain", " confidence ": 0.9}],
"description": {
"tags":["outdoor", "mountain"],
"captions": [
{"name": "A mountain with snow",
"confidence": 0.9
}
]
},
"metadata":
{"width":60,"height":30, format:"Jpeg"},
"faces": [],
"brands": [],
"color": {"dominantColorForeground": "Brown",…},
"imageType": {"clipArtType": 0, …},
"objects" : [
{
"rectangle": {x:20, y:25, w:10, h:20},
"object": "mountain",
"confidence": 0.9
}
]
}# Authenticate Computer Vision client
credential = CognitiveServicesCredentials(cog_key)
cv_client = ComputerVisionClient(cog_endpoint, credential)
var analysis = await cvClient.AnalyzeImageInStreamAsync(imageData, features);
# Get image analysis
with open(image_file, mode="rb") as image_data:
analysis = cv_client.analyze_image_in_stream(image_data , features)
# Get image description
for caption in analysis.description.captions:
print("Description: '{}' (confidence: {:.2f}%)".format(caption.text, caption.confidence * 100))
# Get image analysis
with open(image_file, mode="rb") as image_data:
analysis = cv_client.analyze_image_in_stream(image_data , features)
# Get image description
for caption in analysis.description.captions:
print("Description: '{}' (confidence: {:.2f}%)".format(caption.text, caption.confidence * 100))
# Get image categories
if (len(analysis.categories) > 0):
print("Categories:")
landmarks = []
for category in analysis.categories:
# Print the category
print(" -'{}' (confidence: {:.2f}%)".format(category.name, category.score * 100))
if category.detail:
# Get landmarks in this category
if category.detail.landmarks:
for landmark in category.detail.landmarks:
if landmark not in landmarks:
landmarks.append(landmark)
# If there were landmarks, list them
if len(landmarks) > 0:
print("Landmarks:")
for landmark in landmarks:
print(" -'{}' (confidence: {:.2f}%)".format(landmark.name, landmark.confidence * 100))
# Get brands in the image
if (len(analysis.brands) > 0):
print("Brands: ")
for brand in analysis.brands:
print(" -'{}' (confidence: {:.2f}%)".format(brand.name, brand.confidence * 100))
# Get objects in the image
if len(analysis.objects) > 0:
print("Objects in image:")
# Prepare image for drawing
fig = plt.figure(figsize=(8, 8))
plt.axis('off')
image = Image.open(image_file)
draw = ImageDraw.Draw(image)
color = 'cyan'
for detected_object in analysis.objects:
# Print object name
print(" -{} (confidence: {:.2f}%)".format(detected_object.object_property, detected_object.confidence * 100))
# Draw object bounding box
r = detected_object.rectangle
bounding_box = ((r.x, r.y), (r.x + r.w, r.y + r.h))
draw.rectangle(bounding_box, outline=color, width=3)
plt.annotate(detected_object.object_property,(r.x, r.y), backgroundcolor=color)
# Save annotated image
plt.imshow(image)
outputfile = 'objects.jpg'
fig.savefig(outputfile)
print(' Results saved in', outputfile)
# Get moderation ratings
ratings = 'Ratings:\n -Adult: {}\n -Racy: {}\n -Gore: {}'.format(analysis.adult.is_adult_content,
analysis.adult.is_racy_content,
analysis.adult.is_gory_content)
print(ratings)
# Generate a thumbnail
with open(image_file, mode="rb") as image_data:
# Get thumbnail data
thumbnail_stream = cv_client.generate_thumbnail_in_stream(100, 100, image_data, True)
# Save thumbnail image
thumbnail_file_name = 'thumbnail.png'
with open(thumbnail_file_name, "wb") as thumbnail_file:
for chunk in thumbnail_stream:
thumbnail_file.write(chunk)
print('Thumbnail saved in.', thumbnail_file_name)
https://learn.microsoft.com/en-us/rest/api/computer-vision/?source=recommendations
Header param: Ocp-Apim-Subscription-Key:{Key}
POST
https://azrajcog.cognitiveservices.azure.com/vision/v1.0/analyze?visualFeatures=Categories,Tags,Description,Faces,ImageType,Color,Adult
Request:
{"url":"https://wallpapercave.com/wp/wp9801001.jpg"}
Response:
{
"categories": [
{
"name": "people_",
"score": 0.58203125
}
],
"adult": {
"isAdultContent": false,
"isRacyContent": false,
"adultScore": 0.007187211886048317,
"racyScore": 0.021118562668561935
},
"color": {
"dominantColorForeground": "White",
"dominantColorBackground": "Orange",
"dominantColors": [
"Orange",
"White"
],
"accentColor": "C1940A",
"isBwImg": false,
"isBWImg": false
},
"imageType": {
"clipArtType": 0,
"lineDrawingType": 0
},
"tags": [
{
"name": "person",
"confidence": 0.9967427253723145
},
{
"name": "human face",
"confidence": 0.9841591119766235
},
{
"name": "smile",
"confidence": 0.817595899105072
},
{
"name": "man",
"confidence": 0.7422456741333008
},
{
"name": "clothing",
"confidence": 0.7328047752380371
},
{
"name": "portrait",
"confidence": 0.5366792678833008
}
],
"description": {
"tags": [
"person",
"man",
"table",
"standing",
"woman",
"food",
"water",
"wearing",
"shirt",
"holding",
"glasses",
"phone",
"young",
"people"
],
"captions": [
{
"text": "a person posing for the camera",
"confidence": 0.9687843244692304
}
]
},
"faces": [
{
"faceRectangle": {
"left": 302,
"top": 193,
"width": 221,
"height": 221
}
}
],
"requestId": "2a46cfbd-d1e6-49a0-b922-54111d2b931f",
"metadata": {
"height": 768,
"width": 1024,
"format": "Jpeg"
}
}
POST
https://azrajcog.cognitiveservices.azure.com/vision/v1.0/describe
Request:
{"url":"https://wallpapercave.com/wp/wp9801001.jpg"}
Response:
{
"description": {
"tags": [
"person",
"man",
"table",
"standing",
"woman",
"food",
"water",
"wearing",
"shirt",
"holding",
"glasses",
"phone",
"young",
"people"
],
"captions": [
{
"text": "a person posing for the camera",
"confidence": 0.9687843161121992
}
]
},
"requestId": "ce84ef1a-9cbb-44f7-b49c-9476d67922c8",
"metadata": {
"height": 768,
"width": 1024,
"format": "Jpeg"
}
}
POST
https://azrajcog.cognitiveservices.azure.com/vision/v1.0/generateThumbnail?width=50&height=50&smartCropping=true
{"url":"https://wallpapercave.com/wp/wp9801001.jpg"}
POST
https://azrajcog.cognitiveservices.azure.com/vision/v1.0/tag
{"url":"https://wallpapercave.com/wp/wp9801001.jpg"}
Response:
{
"tags": [
{
"name": "person",
"confidence": 0.9967427253723145
},
{
"name": "human face",
"confidence": 0.9841591119766235
},
{
"name": "smile",
"confidence": 0.817595899105072
},
{
"name": "man",
"confidence": 0.7422456741333008
},
{
"name": "clothing",
"confidence": 0.7328047752380371
},
{
"name": "portrait",
"confidence": 0.5366792678833008
}
],
"requestId": "36f0b603-c966-48cb-bed8-1f752ff06b5d",
"metadata": {
"height": 768,
"width": 1024,
"format": "Jpeg"
}
}------------------------------------------------------------------------------------------------------------------
- Facial recognition - detecting the presence of individual people in the image. This requires Limited Access approval.
- Optical character recognition - reading text in the video.
- Speech transcription - creating a text transcript of spoken dialog in the video.
- Topics - identification of key topics discussed in the video.
- Sentiment - analysis of how positive or negative segments within the video are.
- Labels - label tags that identify key objects or themes throughout the video.
- Content moderation - detection of adult or violent themes in the video.
- Scene segmentation - a breakdown of the video into its constituent scenes.
https://api.videoindexer.ai.your_endpoint/Videos
{
"results": [
{
"accountId": "1234abcd-9876fghi-0156kihb-00123",
"id": "a12345bc6",
"name": "Responsible AI",
"description": "Microsoft Responsible AI video",
"created": "2021-01-05T15:33:58.918+00:00",
"lastModified": "2021-01-05T15:50:03.123+00:00",
"lastIndexed": "2021-01-05T15:34:08.007+00:00",
"processingProgress": "100%",
"durationInSeconds": 114,
"sourceLanguage": "en-US",
}
],
}------------------------------------------------------------------------------------------------------------------
The Custom Vision service enables you to build your own computer vision models for image classification or object detection.
To use the Custom Vision service, you must provision two kinds of Azure resource:
A training resource (used to train your models). This can be:
- A Cognitive Services resource.
- A Custom Vision (Training) resource.
A prediction resource, used by client applications to get predictions from your model. This can be:
- A Cognitive Services resource.
- A Custom Vision (Prediction) resource.
------------------------------------------------------------------------------------------------------------------
Object detection is used to locate and identify objects in images. You can use Custom Vision to train a model to detect specific classes of object in images.
Object detection is a form of computer vision in which a model is trained to detect the presence and location of one or more classes of object in an image.
Use the Custom Vision service for object detection You can use the Custom Vision cognitive service to train an object detection model. To use the Custom Vision service, you must provision two kinds of Azure resource:
A training resource (used to train your models). This can be:
- A Cognitive Services resource.
- A Custom Vision (Training) resource.
A prediction resource, used by client applications to get predictions from your model. This can be:
- A Cognitive Services resource.
- A Custom Vision (Prediction) resource.
POST
https://azrajcog.cognitiveservices.azure.com/vision/v3.1/detect
{"url":"https://wallpapercave.com/wp/wp9801001.jpg"}
Response:
{
"objects": [
{
"rectangle": {
"x": 108,
"y": 25,
"w": 798,
"h": 743
},
"object": "person",
"confidence": 0.782
}
],
"requestId": "bf88cbd6-2273-4bc0-8e17-063b650c4d3a",
"metadata": {
"height": 768,
"width": 1024,
"format": "Jpeg"
}
}------------------------------------------------------------------------------------------------------------------

The Computer Vision service enables you to detect human faces in an image, as well as returning a bounding box for its location.
The Face service offers more comprehensive facial analysis capabilities than the Computer Vision service, including:
- Face detection (with bounding box).
- Comprehensive facial feature analysis (including head pose, presence of spectacles, blur, facial landmarks, occlusion and others).
- Face comparison and verification.
- Facial recognition.
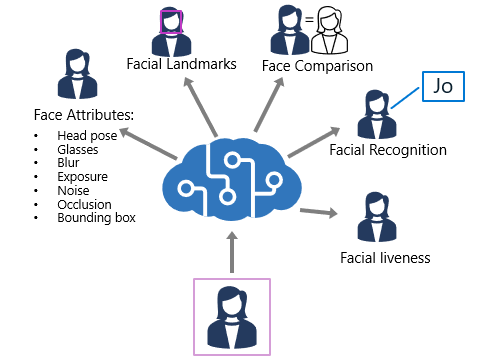
- Face detection - for each detected face, the results include an ID that identifies the face and the bounding box coordinates indicating its location in the image.
- Face attribute analysis - you can return a wide range of facial attributes, including:
- Head pose (pitch, roll, and yaw orientation in 3D space)
- Glasses (NoGlasses, ReadingGlasses, Sunglasses, or Swimming Goggles)
- Blur (low, medium, or high)
- Exposure (underExposure, goodExposure, or overExposure)
- Noise (visual noise in the image)
- Occlusion (objects obscuring the face)
- Facial landmark location - coordinates for key landmarks in relation to facial features (for example, eye corners, pupils, tip of nose, and so on)
- Face comparison - you can compare faces across multiple images for similarity (to find individuals with similar facial features) and verification (to determine that a face in one image is the same person as a face in another image)
- Facial recognition - you can train a model with a collection of faces belonging to specific individuals, and use the model to identify those people in new images.
REST: https://learn.microsoft.com/en-us/rest/api/faceapi/face/detect-with-url?tabs=HTTP
https://azrajcog.cognitiveservices.azure.com/face/v1.0/detect
{"url":"https://wallpapercave.com/wp/wp9801001.jpg"}
Response:
[
{
"faceId": "c5c24a82-6845-4031-9d5d-978df9175426",
"recognitionModel": "recognition_01",
"faceRectangle": {
"width": 78,
"height": 78,
"left": 394,
"top": 54
},
"faceLandmarks": {
"pupilLeft": {
"x": 412.7,
"y": 78.4
},
"pupilRight": {
"x": 446.8,
"y": 74.2
},
"noseTip": {
"x": 437.7,
"y": 92.4
},
"mouthLeft": {
"x": 417.8,
"y": 114.4
},
"mouthRight": {
"x": 451.3,
"y": 109.3
},
"eyebrowLeftOuter": {
"x": 397.9,
"y": 78.5
},
"eyebrowLeftInner": {
"x": 425.4,
"y": 70.5
},
"eyeLeftOuter": {
"x": 406.7,
"y": 80.6
},
"eyeLeftTop": {
"x": 412.2,
"y": 76.2
},
"eyeLeftBottom": {
"x": 413,
"y": 80.1
},
"eyeLeftInner": {
"x": 418.9,
"y": 78
},
"eyebrowRightInner": {
"x": 4.8,
"y": 69.7
},
"eyebrowRightOuter": {
"x": 5.5,
"y": 68.5
},
"eyeRightInner": {
"x": 441.5,
"y": 75
},
"eyeRightTop": {
"x": 446.4,
"y": 71.7
},
"eyeRightBottom": {
"x": 447,
"y": 75.3
},
"eyeRightOuter": {
"x": 451.7,
"y": 73.4
},
"noseRootLeft": {
"x": 428,
"y": 77.1
},
"noseRootRight": {
"x": 435.8,
"y": 75.6
},
"noseLeftAlarTop": {
"x": 428.3,
"y": 89.7
},
"noseRightAlarTop": {
"x": 442.2,
"y": 87
},
"noseLeftAlarOutTip": {
"x": 424.3,
"y": 96.4
},
"noseRightAlarOutTip": {
"x": 446.6,
"y": 92.5
},
"upperLipTop": {
"x": 437.6,
"y": 105.9
},
"upperLipBottom": {
"x": 437.6,
"y": 108.2
},
"underLipTop": {
"x": 436.8,
"y": 111.4
},
"underLipBottom": {
"x": 437.3,
"y": 114.5
}
},
"faceAttributes": {
"age": 71,
"gender": "male",
"smile": 0.88,
"facialHair": {
"moustache": 0.8,
"beard": 0.1,
"sideburns": 0.02
},
"glasses": "sunglasses",
"headPose": {
"roll": 2.1,
"yaw": 3,
"pitch": 1.6
},
"emotion": {
"anger": 0.575,
"contempt": 0,
"disgust": 0.006,
"fear": 0.008,
"happiness": 0.394,
"neutral": 0.013,
"sadness": 0,
"surprise": 0.004
},
"hair": {
"bald": 0,
"invisible": false,
"hairColor": [
{
"color": "brown",
"confidence": 1
},
{
"color": "blond",
"confidence": 0.88
},
{
"color": "black",
"confidence": 0.48
},
{
"color": "other",
"confidence": 0.11
},
{
"color": "gray",
"confidence": 0.07
},
{
"color": "red",
"confidence": 0.03
}
]
},
"makeup": {
"eyeMakeup": true,
"lipMakeup": false
},
"occlusion": {
"foreheadOccluded": false,
"eyeOccluded": false,
"mouthOccluded": false
},
"accessories": [
{
"type": "headWear",
"confidence": 0.99
},
{
"type": "glasses",
"confidence": 1
},
{
"type": "mask",
"confidence": 0.87
}
],
"blur": {
"blurLevel": "Medium",
"value": 0.51
},
"exposure": {
"exposureLevel": "GoodExposure",
"value": 0.55
},
"noise": {
"noiseLevel": "Low",
"value": 0.12
}
}
}
]------------------------------------------------------------------------------------------------------------------
The Computer Vision service offers two APIs that you can use to read text.
The Read API:
- Use this API to read small to large volumes of text from images and PDF documents.
- This API uses a newer model than the OCR API, resulting in greater accuracy.
- The Read API can read printed text in multiple languages, and handwritten text in English.
- The initial function call returns an asynchronous operation ID, which must be used in a subsequent call to retrieve the results.
The Image Analysis API:
- Currently still in preview, with reading text functionality added version 4.0.
- Use this API to read small amounts of text from images.
- Returns contextual information, including line number and position.
- Results are returned immediately (synchronous) from a single function call.
- Has functionality for analyzing images past extracting text, including detecting content (such as brands, faces, and domain-specific content), describing or categorizing an image, generating thumbnails and more
SDK: https://microsoftlearning.github.io/AI-102-AIEngineer/Instructions/20-ocr.html
Form Recognizer is one of many Cognitive Services, cloud-based artificial intelligence (AI) services with REST APIs and client library SDKs that can be used to build intelligence into your applications.
Form Recognizer uses Optical Character Recognition (OCR) capabilities and deep learning models to extract text, key-value pairs, selection marks, and tables from documents.
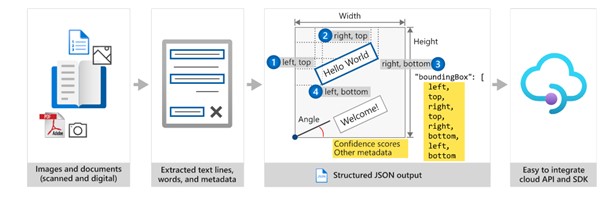
Form Recognizer service components Form Recognizer is composed of the following services:
Document analysis models: which take an input of JPEG, PNG, PDF, and TIFF files and return a JSON file with the location of text in bounding boxes, text content, tables, selection marks (also known as checkboxes or radio buttons), and document structure.
Prebuilt models: which detect and extract information from document images and return the extracted data in a structured JSON output. Form Recognizer currently supports prebuilt models for several forms, including:
W-2 forms Invoices Receipts ID documents Business cards Custom models: custom models extract data from forms specific to your business. Custom models can be trained by calling the Build model API, or through Form Recognizer Studio.
Form Recognizer works on input documents that meet these requirements:
- Format must be JPG, PNG, BMP, PDF (text or scanned), or TIFF.
- The file size must be less than 500 MB for paid (S0) tier and 4 MB for free (F0) tier.
- Image dimensions must be between 50 x 50 pixels and 10000 x 10000 pixels.
- The total size of the training data set must be 500 pages or less.
To extract form data using a custom model, use the analyze document REST API function with your model ID (generated during model training). This function starts the form analysis and returns a result ID, which you can pass in a subsequent call to the get analyze results function to retrieve the results.
A successful JSON response contains readResults and documentResults nodes.
The readResults node contains all of the recognized text. Text is organized by page, then by line, then by individual words.
The documentResults node contains the form-specific values that the model discovered. This is where you'll find useful key/value pairs like the first name, last name, company name and more.
Depending on the form analyzed, the response may also contain pageResults, which includes the tables extracted. https://learn.microsoft.com/en-us/rest/api/formrecognizer/2.0/get-analyze-form-result/get-analyze-form-result?tabs=HTTP
{
"status": "succeeded",
"createdDateTime": "2021-03-29T21:12:40Z",
"lastUpdatedDateTime": "2021-03-29T21:12:44Z",
"analyzeResult": {
"version": "2.1.0",
"readResults": [
{
...
"lines": [
{
"text": "Northwind Traders",
"boundingBox": [
20,
17,
235,
17,
235,
44,
20,
44
],
"words": [
{
"text": "Northwind",
"boundingBox": [
20,
17,
140,
17,
140,
45,
20,
45
],
"confidence": 0.994
},
{
"text": "Traders",
"boundingBox": [
148,
17,
234,
17,
234,
45,
147,
45
],
"confidence": 0.996
...,
"documentResults": [
{
"docType": "prebuilt:receipt",
"pageRange": [
1,
1
],
"fields": {
"Items": {
"type": "array",
"valueArray": [
{
"type": "object",
"valueObject": {
"Name": {
"type": "string",
"valueString": "Apple",
"text": "Apple",
"boundingBox": [
32,
267,
92,
267,
92,
291,
32,
291
],
"page": 1,
"confidence": 0.991,
"elements": [
"#/readResults/0/lines/4/words/1"
]
},
...
}########################################################################################
https://learn.microsoft.com/en-us/training/paths/process-translate-text-azure-cognitive-services/
-> Retrieve and process key phrases
-> Retrieve and process entities
-> Retrieve and process sentiment
-> Detect the language used in text
-> Detect personally identifiable information (PII)
-> Implement and customize text-to-speech
-> Implement and customize speech-to-text
-> Improve text-to-speech by using SSML and Custom Neural Voice
-> Improve speech-to-text by using phrase lists and Custom Speech
-> Implement intent recognition
-> Implement keyword recognition
-> Translate text and documents by using the Translator service
-> Implement custom translation, including training, improving, and publishing a custom model
-> Translate speech-to-speech by using the Speech service
-> Translate speech-to-text by using the Speech service
-> Translate to multiple languages simultaneously
-> Create intents and add utterances
-> Create entities
-> Train evaluate, deploy, and test a language understanding model
-> Optimize a Language Understanding (LUIS) model
-> Integrate multiple language service models by using Orchestrator
-> Import and export language understanding models
-> Create a question answering project
-> Add question-and-answer pairs manually
-> Import sources
-> Train and test a knowledge base
-> Publish a knowledge base
-> Create a multi-turn conversation
-> Add alternate phrasing
-> Add chit-chat to a knowledge base
-> Export a knowledge base
-> Create a multi-language question answering solution
-> Create a multi-domain question answering solution
-> Use metadata for question-and-answer pairs
The Language service is designed to help you extract information from text. It provides functionality that you can use for:
- Language detection - determining the language in which text is written.
- Key phrase extraction - identifying important words and phrases in the text that indicate the main points.
- Sentiment analysis - quantifying how positive or negative the text is.
- Named entity recognition - detecting references to entities, including people, locations, time periods, organizations, and more.
- Entity linking - identifying specific entities by providing reference links to Wikipedia articles.
The Language Detection API evaluates text input and, for each document submitted, returns language identifiers with a score indicating the strength of the analysis. The Language service recognizes up to 120 languages.
Language detection can work with documents or single phrases. It's important to note that the document size must be under 5,120 characters. The size limit is per document and each collection is restricted to 1,000 items (IDs).
POST
https://azrajcog.cognitiveservices.azure.com/text/analytics/v3.1/languages
REQUEST BODY:
{
"documents": [
{
"countryHint": "US",
"id": "1",
"text": "Hello world"
},
{
"id": "2",
"text": "Bonjour tout le monde"
},
{
"id": "3",
"text": "La carretera estaba atascada. Había mucho tráfico el día de ayer."
}
]
}
RESPONSE:
{
"documents": [
{
"id": "1",
"detectedLanguage": {
"name": "English",
"iso6391Name": "en",
"confidenceScore": 0.98
},
"warnings": []
},
{
"id": "2",
"detectedLanguage": {
"name": "French",
"iso6391Name": "fr",
"confidenceScore": 1
},
"warnings": []
},
{
"id": "3",
"detectedLanguage": {
"name": "Spanish",
"iso6391Name": "es",
"confidenceScore": 1
},
"warnings": []
}
],
"errors": [],
"modelVersion": "2022-10-01"
}Key phrase extraction is the process of evaluating the text of a document, or documents, and then identifying the main points around the context of the document(s).
Key phrase extraction works best for larger documents (the maximum size that can be analyzed is 5,120 characters).
POST https://azrajcog.cognitiveservices.azure.com/text/analytics/v3.1/keyPhrases
REQUEST BODY:
{
"documents": [
{
"id": "1",
"language": "en",
"text": "You must be the change you wish to see in the world."
},
{
"id": "2",
"language": "en",
"text": "The journey of a thousand miles begins with a single step."
}
]
}
RESPONSE:
{
"documents": [
{
"id": "1",
"keyPhrases": [
"change",
"world"
],
"warnings": []
},
{
"id": "2",
"keyPhrases": [
"thousand miles",
"single step",
"journey"
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2022-10-01"
}Sentiment analysis is used to evaluate how positive or negative a text document is, which can be useful in various workloads, such as:
Evaluating a movie, book, or product by quantifying sentiment based on reviews. Prioritizing customer service responses to correspondence received through email or social media messaging. When using the Language service to evaluate sentiment, the response includes overall document sentiment and individual sentence sentiment for each document submitted to the service.
POST https://azrajcog.cognitiveservices.azure.com/text/analytics/v3.1/sentiment
REQUEST BODY:
{
"documents": [
{
"language": "en",
"id": "1",
"text": "Hello world. This is some input text that I love."
},
{
"language": "en",
"id": "2",
"text": "It's incredibly sunny outside! I'm so happy."
},
{
"language": "en",
"id": "3",
"text": "Pike place market is my favorite Seattle attraction."
}
]
}
RESPONSE:
{
"documents": [
{
"id": "1",
"sentiment": "positive",
"confidenceScores": {
"positive": 0.99,
"neutral": 0.01,
"negative": 0
},
"sentences": [
{
"sentiment": "neutral",
"confidenceScores": {
"positive": 0.26,
"neutral": 0.73,
"negative": 0.01
},
"offset": 0,
"length": 13,
"text": "Hello world. "
},
{
"sentiment": "positive",
"confidenceScores": {
"positive": 0.99,
"neutral": 0.01,
"negative": 0
},
"offset": 13,
"length": 36,
"text": "This is some input text that I love."
}
],
"warnings": []
},
{
"id": "2",
"sentiment": "positive",
"confidenceScores": {
"positive": 0.99,
"neutral": 0.01,
"negative": 0
},
"sentences": [
{
"sentiment": "neutral",
"confidenceScores": {
"positive": 0.26,
"neutral": 0.72,
"negative": 0.02
},
"offset": 0,
"length": 31,
"text": "It's incredibly sunny outside! "
},
{
"sentiment": "positive",
"confidenceScores": {
"positive": 0.99,
"neutral": 0.01,
"negative": 0
},
"offset": 31,
"length": 13,
"text": "I'm so happy."
}
],
"warnings": []
},
{
"id": "3",
"sentiment": "positive",
"confidenceScores": {
"positive": 0.99,
"neutral": 0.01,
"negative": 0
},
"sentences": [
{
"sentiment": "positive",
"confidenceScores": {
"positive": 0.99,
"neutral": 0.01,
"negative": 0
},
"offset": 0,
"length": 52,
"text": "Pike place market is my favorite Seattle attraction."
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2022-11-01"
}Named Entity Recognition identifies entities that are mentioned in the text. Entities are grouped into categories and subcategories, for example:
- Person
- Location
- DateTime
- Organization
- Address
- URL
POST
https://azrajcog.cognitiveservices.azure.com/text/analytics/v3.1/entities/recognition/general
REQUEST BODY:
{
"documents": [
{
"language": "en",
"id": "1",
"text": "I had a wonderful trip to Seattle last week."
},
{
"language": "en",
"id": "2",
"text": "I work at Microsoft."
},
{
"language": "en",
"id": "3",
"text": "I visited Space Needle 2 times."
}
]
}
RESPONSE:
{
"documents": [
{
"id": "1",
"entities": [
{
"text": "trip",
"category": "Event",
"offset": 18,
"length": 4,
"confidenceScore": 0.74
},
{
"text": "Seattle",
"category": "Location",
"subcategory": "GPE",
"offset": 26,
"length": 7,
"confidenceScore": 1
},
{
"text": "last week",
"category": "DateTime",
"subcategory": "DateRange",
"offset": 34,
"length": 9,
"confidenceScore": 0.8
}
],
"warnings": []
},
{
"id": "2",
"entities": [
{
"text": "Microsoft",
"category": "Organization",
"offset": 10,
"length": 9,
"confidenceScore": 0.99
}
],
"warnings": []
},
{
"id": "3",
"entities": [
{
"text": "Space Needle",
"category": "Location",
"offset": 10,
"length": 12,
"confidenceScore": 0.96
},
{
"text": "2",
"category": "Quantity",
"subcategory": "Number",
"offset": 23,
"length": 1,
"confidenceScore": 0.8
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2021-06-01"
}In some cases, the same name might be applicable to more than one entity. For example, does an instance of the word "Venus" refer to the planet or the goddess from mythology?
Entity linking can be used to disambiguate entities of the same name by referencing an article in a knowledge base. Wikipedia provides the knowledge base for the Text Analytics service. Specific article links are determined based on entity context within the text.
POST
https://azrajcog.cognitiveservices.azure.com/text/analytics/v3.1/entities/linking
REQUEST BODY:
{
"documents": [
{
"language": "en",
"id": "1",
"text": "I had a wonderful trip to Seattle last week."
},
{
"language": "en",
"id": "2",
"text": "I work at Microsoft."
},
{
"language": "en",
"id": "3",
"text": "I visited Space Needle 2 times."
}
]
}
RESPONSE:
{
"documents": [
{
"id": "1",
"entities": [
{
"bingId": "5fbba6b8-85e1-4d41-9444-d9055436e473",
"name": "Seattle",
"matches": [
{
"text": "Seattle",
"offset": 26,
"length": 7,
"confidenceScore": 0.19
}
],
"language": "en",
"id": "Seattle",
"url": "https://en.wikipedia.org/wiki/Seattle",
"dataSource": "Wikipedia"
}
],
"warnings": []
},
{
"id": "2",
"entities": [
{
"bingId": "a093e9b9-90f5-a3d5-c4b8-5855e1b01f85",
"name": "Microsoft",
"matches": [
{
"text": "Microsoft",
"offset": 10,
"length": 9,
"confidenceScore": 0.25
}
],
"language": "en",
"id": "Microsoft",
"url": "https://en.wikipedia.org/wiki/Microsoft",
"dataSource": "Wikipedia"
}
],
"warnings": []
},
{
"id": "3",
"entities": [
{
"bingId": "f8dd5b08-206d-2554-6e4a-893f51f4de7e",
"name": "Space Needle",
"matches": [
{
"text": "Space Needle",
"offset": 10,
"length": 12,
"confidenceScore": 0.17
}
],
"language": "en",
"id": "Space Needle",
"url": "https://en.wikipedia.org/wiki/Space_Needle",
"dataSource": "Wikipedia"
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2021-06-01"
}The Translator Azure Cognitive Service provides an API for translating text between 90 supported languages.
The Translator service provides a multilingual text translation API that you can use for:
- Language detection
- One-to-many translation
- Script transliteration (converting text from its native script to an alternative script)
To translate text from one language to another, use the translate function; specifying a single from parameter to indicate the source language, and one or more to parameters to specify the languages into which you want the text translated.
REST:
POST
https://api.cognitive.microsofttranslator.com/translate?api-version=3.0&from=en&to=ta
HEADERS:
Content-Type:application/json
Ocp-Apim-Subscription-Key:448bfc9f5e7c4d5a83ca73bf4074313a
Ocp-Apim-Subscription-Region:eastus
REQUEST BODY:
[
{
"Text": "I would really like to speak to you."
}
]
RESPONSE:
[
{
"translations": [
{
"text": "நான் உங்களுடன் பேச விரும்புகிறேன்.",
"to": "ta"
}
]
}
]Our Japanese text is written using Hiragana script, so rather than translate it to a different language, you may want to transliterate it to a different script - for example to render the text in Latin script (as used by English language text).
REST:
POST
https://api.cognitive.microsofttranslator.com/transliterate?api-version=3.0&language=ja&fromScript=jpan&toScript=latn
HEADERS:
Content-Type:application/json
Ocp-Apim-Subscription-Key:448bfc9f5e7c4d5a83ca73bf4074313a
Ocp-Apim-Subscription-Region:eastus
REQUEST BODY:
[
{
"script": "Latn",
"text": "Kon'nichiwa"
}
]
RESPONSE:
[
{
"text": "kon'nichiwa",
"script": "latn"
}
]------------------------------------------------------------------------------------------------------------------
After creating your Azure resource, you will need the following information to use it from a client application through one of the supported SDKs:
- The location in which the resource is deployed (for example, eastus)
- One of the keys assigned to your resource.
You can view of these values on the Keys and Endpoint page for your resource in the Azure portal.
https://learn.microsoft.com/en-us/training/modules/transcribe-speech-input-text/3-speech-to-text
The Speech service supports speech recognition through two REST APIs:
-The Speech-to-text API, which is the primary way to perform speech recognition.
- The Speech-to-text Short Audio API, which is optimized for short streams of audio (up to 60 seconds).
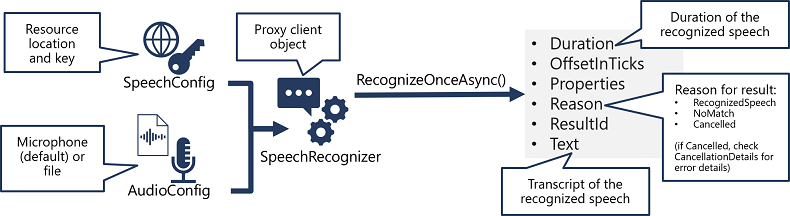
- Use a SpeechConfig object to encapsulate the information required to connect to your Speech resource. Specifically, its location and key.
- Optionally, use an AudioConfig to define the input source for the audio to be transcribed. By default, this is the default system microphone, but you can also specify an audio file.
- Use the SpeechConfig and AudioConfig to create a SpeechRecognizer object. This object is a proxy client for the Speech-to-text API.
- Use the methods of the SpeechRecognizer object to call the underlying API functions. For example, the RecognizeOnceAsync() method uses the Speech service to asynchronously transcribe a single spoken utterance.
- Process the response from the Speech service. In the case of the RecognizeOnceAsync() method, the result is a SpeechRecognitionResult object that includes the following properties:
- Duration
- OffsetInTicks
- Properties
- Reason
- ResultId
- Text
Similarly to Speech-to-text APIs, the Speech service offers two REST APIs for speech synthesis:
- The Text-to-speech API, which is the primary way to perform speech synthesis.
- The Text-to-speech Long Audio API, which is designed to support batch operations that convert large volumes of text to audio - for example to generate an audio-book from the source text.
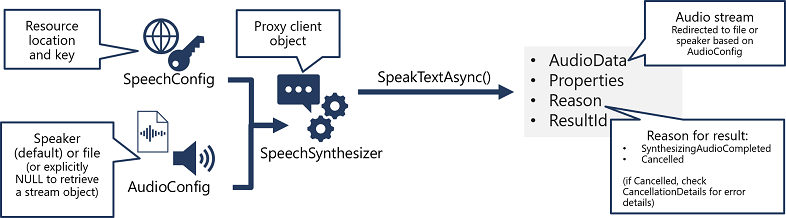
- Use a SpeechConfig object to encapsulate the information required to connect to your Speech resource. Specifically, its location and key.
- Optionally, use an AudioConfig to define the output device for the speech to be synthesized. By default, this is the default system speaker, but you can also specify an audio file, or by explicitly setting this value to a null value, you can process the audio stream object that is returned directly.
- Use the SpeechConfig and AudioConfig to create a SpeechSynthesizer object. This object is a proxy client for the Text-to-speech API.
- Use the methods of the SpeechSynthesizer object to call the underlying API functions. For example, the SpeakTextAsync() method uses the Speech service to convert text to spoken audio.
- Process the response from the Speech service. In the case of the SpeakTextAsync method, the result is a SpeechSynthesisResult object that contains the following properties:
- AudioData
- P-roperties
- Reason
- ResultId
When speech has been successfully synthesized, the Reason property is set to the SynthesizingAudioCompleted enumeration and the AudioData property contains the audio stream (which, depending on the AudioConfig may have been automatically sent to a speaker or file).
The Speech service supports multiple output formats for the audio stream that is generated by speech synthesis. Depending on your specific needs, you can choose a format based on the required:
- Audio file type
- Sample-rate
- Bit-depth
The supported formats are indicated in the SDK using the SpeechSynthesisOutputFormat enumeration.
For example, SpeechSynthesisOutputFormat.Riff24Khz16BitMonoPcm.
speechConfig.SetSpeechSynthesisOutputFormat(SpeechSynthesisOutputFormat.Riff24Khz16BitMonoPcm);
The Speech service provides multiple voices that you can use to personalize your speech-enabled applications. There are two kinds of voice that you can use:
- Standard voices - synthetic voices created from audio samples.
- Neural voices - more natural sounding voices created using deep neural networks.
Voices are identified by names that indicate a locale and a person's name - for example en-GB-George.
To specify a voice for speech synthesis in the SpeechConfig, set its SpeechSynthesisVoiceName property to the voice you want to use:
speechConfig.SpeechSynthesisVoiceName = "en-GB-George";
While the Speech SDK enables you to submit plain text to be synthesized into speech (for example, by using the SpeakTextAsync() method), the service also supports an XML-based syntax for describing characteristics of the speech you want to generate. This Speech Synthesis Markup Language (SSML) syntax offers greater control over how the spoken output sounds, enabling you to:
- Specify a speaking style, such as "excited" or "cheerful" when using a neural voice.
- Insert pauses or silence.
- Specify phonemes (phonetic pronunciations), for example to pronounce the text "SQL" as "sequel".
- Adjust the prosody of the voice (affecting the pitch, timbre, and speaking rate). Use common "say-as" rules, for example to specify that a given string should be expressed as a date, time, telephone number, or other form.
- Insert recorded speech or audio, for example to include a standard recorded message or simulate background noise.
speechSynthesizer.SpeakSsmlAsync(ssml_string);
The Speech service provides robust, machine learning and artificial intelligence-based speech translation services, enabling developers to add end-to-end, real-time, speech translations to their applications or services.
Before you can use the Speech service, you need to create a Speech resource in your Azure subscription. You can use either a dedicated Speech resource or a multi-service Cognitive Services resource.
After creating your Azure resource, you will need the following information to use it from a client application through one of the supported SDKs:
The location in which the resource is deployed (for example, eastus) One of the keys assigned to your resource.
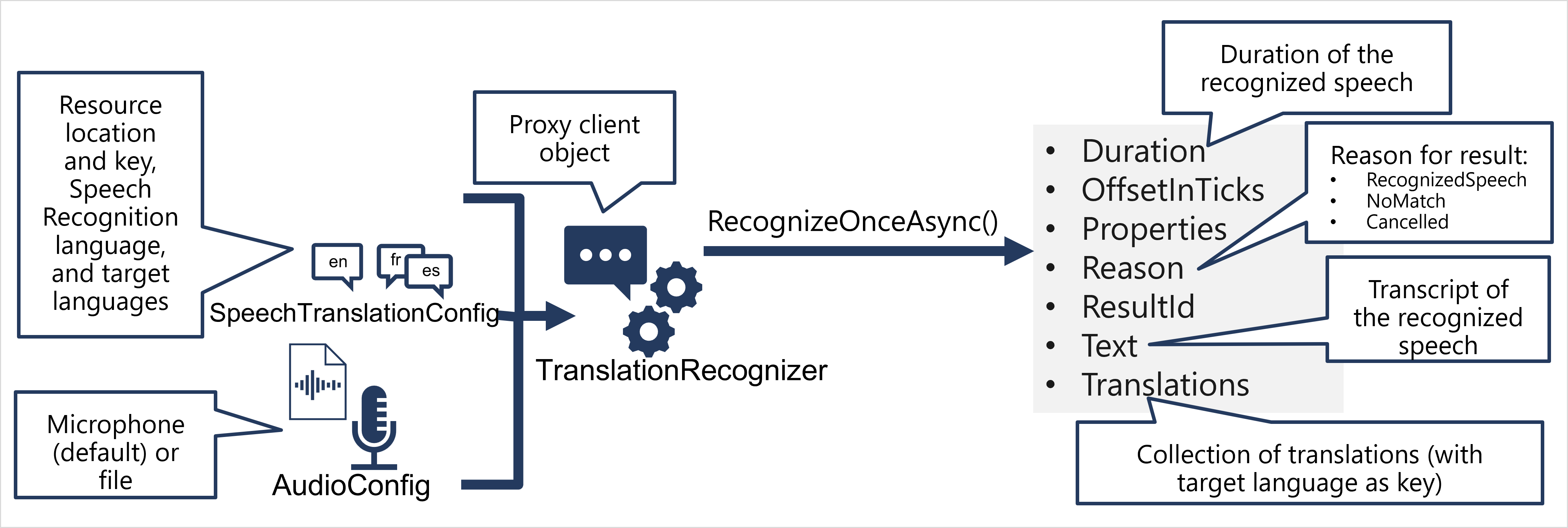
- Use a SpeechConfig object to encapsulate the information required to connect to your Speech resource. Specifically, its location and key.
- Use a SpeechTranslationConfig object to specify the speech recognition language (the language in which the input speech is spoken) and the target languages into which it should be translated.
- Optionally, use an AudioConfig to define the input source for the audio to be transcribed. By default, this is the default system microphone, but you can also specify an audio file.
- Use the SpeechConfig, SpeechTranslationConfig, and AudioConfig to create a TranslationRecognizer object. This object is a proxy client for the Speech service translation API.
- Use the methods of the TranslationRecognizer object to call the underlying API functions. For example, the RecognizeOnceAsync() method uses the Speech service to asynchronously translate a single spoken utterance.
- Process the response from the Speech service. In the case of the RecognizeOnceAsync() method, the result is a SpeechRecognitionResult object that includes the following properties:
- Duration
- OffsetInTicks
- Properties
- Reason
- ResultId
- Text T- ranslations If the operation was successful, the Reason property has the enumerated value RecognizedSpeech, the Text property contains the transcription in the original language, and the Translations property contains a dictionary of the translations (using the two-character ISO language code, such as "en" for English, as a key).
The TranslationRecognizer returns translated transcriptions of spoken input - essentially translating audible speech to text.
When you want to perform 1:1 translation (translating from one source language into a single target language), you can use event-based synthesis to capture the translation as an audio stream. To do this, you need to:
- Specify the desired voice for the translated speech in the TranslationConfig.
- Create an event handler for the TranslationRecognizer object's Synthesizing event.
- In the event handler, use the GetAudio() method of the Result parameter to retrieve the byte stream of translated audio.
Manual synthesis is an alternative approach to event-based synthesis that doesn't require you to implement an event handler. You can use manual synthesis to generate audio translations for one or more target languages.
Manual synthesis of translations is essentially just the combination of two separate operations in which you:
- Use a TranslationRecognizer to translate spoken input into text transcriptions in one or more target languages.
- Iterate through the Translations dictionary in the result of the translation operation, using a SpeechSynthesizer to synthesize an audio stream for each language.
https://learn.microsoft.com/en-us/training/paths/create-language-solution-azure-cognitive-services/
-
Summarization - A summarization query will be sent to an endpoint similar to the following, with the task specified as extractiveSummarizationTasks or ConversationalSummarizationTask
-
Named entity recognition - An entity recognition query will be sent to an endpoint similar to the following, with the task specified as EntityRecognition
-
Personally identifiable information (PII) detection - A PII query will be sent to an endpoint similar to the following, with the task specified as PiiEntityRecognition.
-
Key phrase extraction - KeyPhraseExtraction
-
Sentiment analysis - SentimentAnalysis
-
Language detection - LanguageDetection
-
Conversational language understanding (CLU)
CLU is one of the core custom features offered by Azure Cognitive Services for Language. CLU helps users to build custom natural language understanding models to predict overall intent and extract important information from incoming utterances. CLU does require data to be tagged by the user to teach it how to predict intents and entities accurately.
A language detection query will be sent to an endpoint similar to the following, with the task specified as Conversation. These custom features require extra parameters in the JSON body, including the projectName and deploymentName of your model.
Language Studio - Preview portal at https://language.cognitive.azure.com.
QA:
[POST]
https://premlanguage.cognitiveservices.azure.com/language/:analyze-conversations?api-version=2022-10-01-preview
Header:
Ocp-Apim-Subscription-Key: {*your key}
Apim-Request-Id: {* your value}
Request:
{
"kind": "Conversation",
"analysisInput": {
"conversationItem": {
"id": "1",
"text": "What’s the time in Sydney",
"modality": "text",
"language": "EN",
"participantId": "PARTICIPANT_ID_HERE"
}
},
"parameters": {
"projectName": "Clock",
"verbose": true,
"deploymentName": "production",
"stringIndexType": "TextElement_V8"
}
}
Response:
{
"kind": "ConversationResult",
"result": {
"query": "What’s the time in Sydney",
"prediction": {
"topIntent": "GetTime",
"projectKind": "Conversation",
"intents": [
{
"category": "GetTime",
"confidenceScore": 0.7823135
},
{
"category": "GetDay'",
"confidenceScore": 0.6592359
},
{
"category": "None",
"confidenceScore": 0
}
],
"entities": [
]
}
}
}from azure.core.credentials import AzureKeyCredential
from azure.ai.language.conversations import ConversationAnalysisClient
from azure.ai.language.conversations.models import ConversationAnalysisOptionsclient = ConversationAnalysisClient(
ls_prediction_endpoint, AzureKeyCredential(ls_prediction_key)) convInput = ConversationAnalysisOptions(
query = userText
)
cls_project = 'Clock'
deployment_slot = 'production'
with client:
result = client.analyze_conversations(
convInput,
project_name=cls_project,
deployment_name=deployment_slot
) top_intent = result.prediction.top_intent
entities = result.prediction.entities
print("view top intent:")
print("\ttop intent: {}".format(result.prediction.top_intent))
print("\tcategory: {}".format(result.prediction.intents[0].category))
print("\tconfidence score: {}\n".format(result.prediction.intents[0].confidence_score))
print("view entities:")
for entity in entities:
print("\tcategory: {}".format(entity.category))
print("\ttext: {}".format(entity.text))
print("\tconfidence score: {}".format(entity.confidence_score))
print("query: {}".format(result.query))########################################################################################
https://learn.microsoft.com/en-us/training/paths/build-qna-solution/
Understand question answering
You can enable multi-turn responses when importing questions and answers from an existing web page or document based on its structure, or you can explicitly define follow-up prompts and responses for existing question and answer pairs.
For example, suppose an initial question for a travel booking knowledge base is "How can I cancel a reservation?". A reservation might refer to a hotel or a flight, so a follow-up prompt is required to clarify this detail. The answer might consist of text such as "Cancellation policies depend on the type of reservation" and include follow-up prompts with links to answers about canceling flights and canceling hotels.
When you define a follow-up prompt for multi-turn conversation, you can link to an existing answer in the knowledge base or define a new answer specifically for the follow-up. You can also restrict the linked answer so that it is only ever displayed in the context of the multi-turn conversation initiated by the original question.
QA:
[POST]
https://premlanguage.cognitiveservices.azure.com/language/:query-knowledgebases?projectName=LearnFAQ&api-version=2021-10-01&deploymentName=production
Header:
Ocp-Apim-Subscription-Key: {*your key}
Request:
{
"top": 3,
"question": "YOUR_QUESTION_HERE",
"includeUnstructuredSources": true,
"confidenceScoreThreshold": "YOUR_SCORE_THRESHOLD_HERE",
"answerSpanRequest": {
"enable": true,
"topAnswersWithSpan": 1,
"confidenceScoreThreshold": "YOUR_SCORE_THRESHOLD_HERE"
},
"filters": {
"metadataFilter": {
"logicalOperation": "YOUR_LOGICAL_OPERATION_HERE",
"metadata": [
{
"key": "YOUR_ADDITIONAL_PROP_KEY_HERE",
"value": "YOUR_ADDITIONAL_PROP_VALUE_HERE"
}
]
}
}
}
Response:
{
"answers": [
{
"questions": [
"How can I cancel a reservation?"
],
"answer": "Call us on 555 123 4567 to cancel a reservation.",
"confidenceScore": 1.0,
"id": 6,
"source": "https://margies-travel.com/faq",
"metadata": {},
"dialog": {
"isContextOnly": false,
"prompts": []
}
}
]
}Active learning can help you make continuous improvements so that it gets better at answering user questions correctly over time.
Active learning helps improve the knowledge base in two ways:
Implicit feedback: As incoming requests are processed, the service identifies user-provided questions that have multiple, similarly scored matches in the knowledge base. These are automatically clustered as alternate phrase suggestions for the possible answers that you can accept or reject in the Suggestions page for your knowledge base in Language Studio.
Explicit feedback. When developing a client application you can control the number of possible question matches returned for the user's input by specifying the top parameter, as shown here:
{
"synonyms": [
{
"alterations": [
"reservation",
"booking",,
]
}
]
}
(https://learn.microsoft.com/en-us/training/paths/build-custom-text-analytics/)
Create custom text classification solutions:
Single label classification (json request with **customClassificationTasks**) - you can assign only one class to each file. Following the above example, a video game summary could only be classified as "Adventure" or "Strategy".
Multiple label classification (json request with **customMultiClassificationTasks**) - you can assign multiple classes to each file. This type of project would allow you to classify a video game summary as "Adventure" or "Adventure and Strategy".
Recall - Of all the actual labels, how many were identified; the ratio of true positives to all that was labeled.
Precision - How many of the predicted labels are correct; the ratio of true positives to all identified positives.
F1 Score - A function of recall and precision, intended to provide a single score to maximize for a balance of each component
- Consuming Deployed model:
[POST]
https://premaztextclassify.cognitiveservices.azure.com/text/analytics/v3.2-preview.2/analyze
Header:
Ocp-Apim-Subscription-Key: {*your key}
Request:
{
"displayName": "myJob",
"analysisInput": {
"documents": [
{
"id": "doc1",
"text": "Text for document 1"
},
{
"id": "doc2",
"text": "Text for document 2"
}
]
},
"displayName": "myClassification",
"tasks": {
"customClassificationTasks": [
{
"parameters": {
"project-name": "*ClassifyLab",
"deployment-name": "*artices"
}
}
]
}
} Response: (202) Look for response header with key: operation-location - https://premaztextclassify.cognitiveservices.azure.com/text/analytics/v3.2-preview.2/analyze/jobs/ee45db01-9g89-4de8-bbac-3281c6971c1f
- Get the classification results:
[GET]
https://premaztextclassify.cognitiveservices.azure.com/text/analytics/v3.2-preview.2/analyze/jobs/ee45db01-9g89-4de8-bbac-3281c6971c1f
Header:
Ocp-Apim-Subscription-Key: {* your value}
Response:
{
"jobId": "0e8ddcfe-b081-4d26-8010-ca4a4d5c7e1c",
"lastUpdateDateTime": "2023-03-25T11:07:19Z",
"createdDateTime": "2023-03-25T11:07:18Z",
"expirationDateTime": "2023-03-26T11:07:18Z",
"status": "succeeded",
"errors": [],
"displayName": "myClassification",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"customSingleClassificationTasks": [
{
"lastUpdateDateTime": "2023-03-25T11:07:19.7010658Z",
"state": "succeeded",
"results": {
"documents": [
{
"id": "doc1",
"classification": {
"category": "Entertainment",
"confidenceScore": 0.26
},
"warnings": []
},
{
"id": "doc2",
"classification": {
"category": "Entertainment",
"confidenceScore": 0.26
},
"warnings": []
}
],
"errors": [],
"projectName": "ClassifyLab", {* your value}
"deploymentName": "artices" {* your value}
}
}
]
}
}
------------------------------------------------------------------------------------------------------------------
Custom named entity recognition (NER)

Diversity - use as diverse of a dataset as possible without losing the real-life distribution expected in the real data. You'll want to use sample data from as many sources as possible, each with their own formats and number of entities. It's best to have your dataset represent as many different sources as possible.
Distribution - use the appropriate distribution of document types. A more diverse dataset to train your model will help your model avoid learning incorrect relationships in the data.
Accuracy - use data that is as close to real world data as possible. Fake data works to start the training process, but it likely will differ from real data in ways that can cause your model to not extract correctly.
To submit an extraction task, the API requires the JSON body to specify which task to execute. For custom NER, the task for the JSON payload is customEntityRecognitionTasks.
{
"displayName": "string",
"analysisInput": {
"documents": [
{
"id": "doc1",
"text": "string"
},
{
"id": "doc2",
"text": "string"
}
]
},
"tasks": {
"customEntityRecognitionTasks": [
{
"parameters": {
"project-name": "myProject",
"deployment-name": "myDeployment"
}
}
]
}
}
Precision : The ratio of successful entity recognitions to all attempted recognitions. A high score means that as long as the entity is recognized, it's labeled correctly.
Recall : The ratio of successful entity recognitions to the actual number of entities in the document. A high score means it finds the entity or entities well, regardless of if it assigns them the right label
F1 score: Combination of precision and recall providing a single scoring metric
Ideally we want our model to score well in both precision and recall, which means the entity recognition works well. If both metrics have a low score, it means the model is both struggling to recognize entities in the document, and when it does extract that entity, it doesn't assign it the correct label with high confidence.
If precision is low but recall is high, it means that the model recognizes the entity well but doesn't label it as the correct entity type.
If precision is high but recall is low, it means that the model doesn't always recognize the entity, but when the model extracts the entity, the correct label is applied.
########################################################################################
https://learn.microsoft.com/en-us/training/paths/implement-knowledge-mining-azure-cognitive-search/
-> Provision a Cognitive Search resource
-> Create data sources
-> Define an index
-> Create and run an indexer
-> Query an index, including syntax, sorting, filtering, and wildcards
-> Manage knowledge store projections, including file, object, and table projections
-> Attach a Cognitive Services account to a skillset
-> Select and include built-in skills for documents
-> Implement custom skills and include them in a skillset
-> Implement incremental enrichment
------------------------------------------------------------------------------------------------------------------
Indexing and querying wide range of data sources.
In Azure Cognitive Search, you can apply artificial intelligence (AI) skills as part of the indexing process to enrich the source data with new information, which can be mapped to index fields.
The skills used by an indexer are encapsulated in a skillset that defines an enrichment pipeline in which each step enhances the source data with insights obtained by a specific AI skill.
The indexer is the engine that drives the overall indexing process. It takes the outputs extracted using the skills in the skillset, along with the data and metadata values extracted from the original data source, and maps them to fields in the index.
The index is the searchable result of the indexing process. It consists of a collection of JSON documents, with fields that contain the values extracted during indexing.
By including filter criteria in a simple search expression.
By providing an OData filter expression as a $filter parameter with a full syntax search expression.
search=London
$filter=author eq 'Reviewer'
queryType=Full
Facets are a useful way to present users with filtering criteria based on field values in a result set. They work best when a field has a small number of discrete values that can be displayed as links or options in the user interface.
search=*
facet=author
-
Search-as-you-type (DocumentsOperationsExtensions.Suggest and DocumentsOperationsExtensions.Autocomplete)
-
Custom scoring and result boosting
By default, search results are sorted by a relevance score that is calculated based on a term-frequency/inverse-document-frequency (TF/IDF) algorithm.
You can customize the way this score is calculated by defining a scoring profile that applies a weighting value to specific fields - essentially increasing the search score for documents when the search term is found in those fields
------------------------------------------------------------------------------------------------------------------
You can use the predefined skills in Azure Cognitive Search to greatly enrich an index by extracting additional information from the source data. However, there may be occasions when you have specific data extraction needs that cannot be met with the predefined skills and require some custom functionality.
To support these scenarios, you can implement custom skills as web-hosted services (such as Azure Functions) that support the required interface for integration into a skillset. https://learn.microsoft.com/en-us/training/modules/create-enrichment-pipeline-azure-cognitive-search/9-create-custom-skill
Input Schema
{
"values": [
{
"recordId": "<unique_identifier>",
"data":
{
"<input1_name>": "<input1_value>",
"<input2_name>": "<input2_value>",
...
}
},
{
"recordId": "<unique_identifier>",
"data":
{
"<input1_name>": "<input1_value>",
"<input2_name>": "<input2_value>",
...
}
},
...
]
}
Output Schema
{
"values": [
{
"recordId": "<unique_identifier_from_input>",
"data":
{
"<output1_name>": "<output1_value>",
...
},
"errors": [...],
"warnings": [...]
},
{
"recordId": "< unique_identifier_from_input>",
"data":
{
"<output1_name>": "<output1_value>",
...
},
"errors": [...],
"warnings": [...]
},
...
]
}
To integrate a custom skill into your indexing solution, you must add a skill for it to a skillset using the Custom.WebApiSkill skill type.
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
------------------------------------------------------------------------------------------------------------------
Since the index is essentially a collection of JSON objects, each representing an indexed record, it might be useful to export the objects as JSON files for integration into a data orchestration process using tools such as Azure Data Factory.
You may want to normalize the index records into a relational schema of tables for analysis and reporting with tools such as Microsoft Power BI.
Having extracted embedded images from documents during the indexing process, you might want to save those images as files.
Azure Cognitive Search supports these scenarios by enabling you to define a knowledge store in the skillset that encapsulates your enrichment pipeline. The knowledge store consists of projections of the enriched data, which can be JSON objects, tables, or image files. When an indexer runs the pipeline to create or update an index, the projections are generated and persisted in the knowledge store.
The projections of data to be stored in your knowledge store are based on the document structures generated by the enrichment pipeline in your indexing process
To simplify the mapping of these field values to projections in a knowledge store, it's common to use the Shaper skill to create a new, field containing a simpler structure for the fields you want to map to projections.
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
To define the knowledge store and the projections you want to create in it, you must create a knowledgeStore object in the skillset that specifies the Azure Storage connection string for the storage account where you want to create projections, and the definitions of the projections themselves.
For object and file projections, the specified container will be created if it does not already exist. An Azure Storage table will be created for each table projection, with the mapped fields and a unique key field with the name specified in the generatedKeyName property. ------------------------------------------------------------------------------------------------------------------
Azure Cognitive Search lets you query an index using a REST endpoint or inside the Azure portal with the search explorer tool.
-
Boolean operators: AND, OR, NOT for example luxury AND 'air con'
-
Fielded search: fieldName:search term for example Description:luxury AND Tags:air con
-
Fuzzy search: ~ for example Description:luxury~ returns results with misspelled versions of luxury
-
Term proximity search: "term1 term2"~n for example "indoor swimming pool"~3 returns documents with the words indoor swimming pool within three words of each other
-
Regular expression search: /regular expression/ use a regular expression between / for example /[mh]otel/ would return documents with hotel and motel
-
Wildcard search: , ? where * will match many characters and ? matches a single character for example 'air con' would find air con and air conditioning
-
Precedence grouping: (term AND (term OR term)) for example (Description:luxury OR Category:luxury) AND Tags:air?con*
-
Term boosting: ^ for example Description:luxury OR Category:luxury^3 would give hotels with the category luxury a higher score than luxury in the description
########################################################################################
https://learn.microsoft.com/en-us/training/paths/create-conversational-ai-solutions/
-> Design conversational logic for a bot
-> Choose appropriate activity handlers, dialogs or topics, triggers, and state handling for a bot
-> Create a bot from a template
-> Create a bot from scratch
-> Implement activity handlers, dialogs or topics, and triggers
-> Implement channel-specific logic
-> Implement Adaptive Cards
-> Implement multi-language support in a bot
-> Implement multi-step conversations
-> Manage state for a bot
-> Integrate Cognitive Services into a bot, including question answering, LUIS, and Speech service
-> Test a bot using the Bot Framework Emulator or the Power Virtual Agents web app
-> Test a bot in a channel-specific environment
-> Troubleshoot a conversational bot
-> Deploy bot logic
Create conversational AI solutions
Azure Bot Service - A cloud service that enables bot delivery through one or more channels, and integration with other services.
Bot Framework Service - A component of Azure Bot Service that provides a REST API for handling bot activities.
Bot Framework SDK - A set of tools and libraries for end-to-end bot development that abstracts the REST interface, enabling bot development in a range of programming languages.
Empty Bot - a basic bot skeleton.
Echo Bot - a simple "hello world" sample in which the bot responds to messages by echoing the message text back to the user.
Core Bot - a more comprehensive bot that includes common bot functionality, such as integration with the Language Understanding service.
Bot application classes and logic The template bots are based on the Bot class defined in the Bot Framework SDK, which is used to implement the logic in your bot that receives and interprets user input, and responds appropriately. Additionally, bots make use of an Adapter class that handles communication with the user's channel.
Conversations in a bot are composed of activities, which represent events such as a user joining a conversation or a message being received. These activities occur within the context of a turn, a two-way exchange between the user and bot. The Bot Framework Service notifies your bot's adapter when an activity occurs in a channel by calling its Process Activity method, and the adapter creates a context for the turn and calls the bot's Turn Handler method to invoke the appropriate logic for the activity. QA:
https://microsoftlearning.github.io/AI-102-AIEngineer/Instructions/13-bot-framework.html
Conversations in a bot are composed of activities, which represent events such as a user joining a conversation or a message being received
These activities occur within the context of a turn, a two-way exchange between the user and bot.
- The Bot Framework Service notifies your bot's adapter when an activity occurs in a channel by calling its Process Activity method,
- And the adapter creates a context for the turn and calls the bot's Turn Handler method to invoke the appropriate logic for the activity.
The logic for processing the activity can be implemented in multiple ways. The Bot Framework SDK provides classes that can help you build bots that manage conversations using:
Activity handlers: Event methods that you can override to handle different kinds of activities.
Dialogs: More complex patterns for handling stateful, multi-turn conversations.
When an activity occurs in a channel, the Bot Framework Service calls the bot adapter's Process Activity function, passing the activity details. The adapter creates a turn context for the activity and passes it to the bot's turn handler, which calls the individual, event-specific activity handler.

Turn context:
An activity occurs within the context of a turn, which represents a single two-way exchange between the user and the bot. Activity handler methods include a parameter for the turn context, which you can use to access relevant information. For example, the activity handler for a message received activity includes the text of the message
For more complex conversational flows where you need to store state between turns to enable a multi-turn conversation, you can implement dialogs.
- Component dialogs
- Adaptive dialogs
A component dialog is a dialog that can contain other dialogs, defined in its dialog set. Often, the initial dialog in the component dialog is a waterfall dialog, which defines a sequential series of steps to guide the conversation.

An adaptive dialog is another kind of container dialog in which the flow is more flexible, allowing for interruptions, cancellations, and context switches at any point in the conversation. In this style of conversation, the bot initiates a root dialog, which contains a flow of actions (which can include branches and loops), and triggers that can be initiated by actions or by a recognizer

------------------------------------------------------------------------------------------------------------------
- Power Virtual Agents
- Bot Framework Composer
- Bot Framework SDK
Enables users to build a chatbot without requiring any code. PVA lets users use an interface to build conversations, send messages, publish, monitor, and configure your bot all within the PVA app.
Bot Framework Composer is an app for developers to build, test, and publish your bot via an interactive interface. Composer is built on the Bot Framework SDK, and supports extending your bot with code for more complex interactions.
The Bot Framework SDK is a collection of libraries and tools to build, test, publish, and manage conversational bots. The SDK can connect to other AI services, covers end-to-end bot development, and offers the most authoring flexibility.
One or more actions that define the flow of message activities in the dialog. These include sending a message, prompting the user for input, asking a question, and branching the conversation.
A Trigger, which invokes the dialog logic for certain conditions or based on intent detected.
A recognizer, which interprets user input to determine semantic intent. Recognizers are based on the Language Understanding service by default, but you can also use other types of recognizer; such as the QnA Service or simple regular expression matches.
In addition to these elements, a dialog has memory in which values are stored as properties. Properties can be defined at various scopes, including the user scope (variables that store information for the lifetime of the user session with the bot, such as user.greeted) and dialog scope (variables that persist for the lifetime of the dialog, such as dialog.response).