This repository provides State-of-the-Art classical deep neural network(DNN) models of different deep learning frameworks which are easy to train and deploy, achieving the best reproducible performance with NVIDIA GPU Server Clusters.
DLPerf measures how fast deep learning frameworks can train DNN models, so both DL frameworks and DNN models are involved in this benchmark test.
Multiple deep learning frameworks are evaluated in this repository, they are:
- OneFlow
- TensorFlow 1.x and 2.x
- PyTorch
- MXNet
- PaddlePaddle
- MindSpore
More frameworks will be included in the future, such as MegEngine, etc.
There are two main types of model cases tested in this repository, generally including :
-
Common cases
-
Special cases
The first type is classical deep neural network models that used to evaluate the performance of each framework, such as:
- ResNet-50 v1.5
- BERT-Base
The second type is that some models use special techniques or frameworks with unique implementations, such as implementation of Megatron-LM based on Microsoft's framwork deepspeed, Wide and Deep Learning(W&D) based on HugeCTR(Designed for CTR estimation training and implemented by NVIDIA).
| Model | Framework | Source |
|---|---|---|
| Wide and Deep Learning (W&D) | OneFlow | OneFlow-Benchmark |
| Wide and Deep Learning (W&D) | HugeCTR | samples/wdl |
In general, there are a lot of different implementations of these DNN models, we choose official benchmark source as well as NVIDIA-DeepLearningExamples. In most cases, we avoid changing the original scripts and codes. If we have to, changes are mentioned in the documents.
More DNN models will be tested in the future.
Each DNN model of a framework should be tested on a multi-node cluster with different batch sizes, XLA enabled or not, auto mixed precision enabled or not.
We suggest to perform each test with 1-node-1-device, 1-node-8-device, 2-node-16-device, 4-node-32-device configuration.
In this repository, when talking about batch size, it always means the number of samples per device during training. The total batch size is scaled up with the total number of devices for training.
Because each DL framework has its own device memory management strategy, so the maximum batch size per device is different between DL frameworks. For this reason, we perform several group tests with different batch sizes.
Normally, larger batch size produces better performance.
XLA (Accelerated Linear Algebra) is a domain-specific compiler for linear algebra that can accelerate models with potentially no source code changes.
We plan to test these DNN models with or without XLA if the framework supports.
On some NVIDIA GPUs, Automatic Mixed Precision(AMP) uses FP16 to deliver a performance boost of 3X versus FP32.
We plan to test these DNN models with or without AMP if the framework supports.
According to chapter Benchmark Test Scopes, each test case varies with following parameters:
- number of nodes, number of devices
- batch size per device
- XLA
- AMP
Each test case will repeat several times(suggest 7 times). The median value is chose as the final result.
Throughput is the average training samples per second, e.g. images/sec for image classification.
To get a continuous and stable output, first several training steps are ignored. In practice, we ignore 20 training steps of the beginning, and measure the following 100 steps processing time to calculate throughput.
README.md: introduces general information of this repository.NVIDIADeepLearningExamples/: holds the reproducible scripts and test reports for DNN models from NVIDIA DeepLearningExamples, which includes the frameworks (like TensorFlow 1.x, PyTorch, MXNet) and the corresponding models optimized by NVIDIA;OneFlow/: holds the reproducible scripts and test reports for DNN models from OneFlow official benchmark;PaddlePaddle/: holds the reproducible scripts and test reports for DNN models from PaddlePaddle official benchmark;TensorFlow/: holds the reproducible scripts and test reports for DNN models from TensorFlow 2.x official benchmark;PyTorch/: holds the reproducible scripts and test reports for DNN models from PyTorch official benchmark;MxNet/: holds the reproducible scripts and test reports for DNN models from gluon-nlp and gluon-cv;MindSpore/: holds the reproducible scripts and test reports for DNN models from MindSpore official benchmark;reports: holds rounds of DNN's benchmark test reports.
This section maintains a summary of the results of the common models.For more details, please refer to reports folder.
DLPerf Benchmark Test Report v1.0 on 4 nodes with 8x Tesla V100-SXM2-16GB GPUs each.
Our results were obtained by running the applicable training scripts on 4 nodes with 8x Tesla V100-SXM2-16GB GPUs each. The specific training script that was run is documented in the corresponding model's README. The bsz means batch size per GPU.
The difference between v1 and v1.5 is in the bottleneck blocks which require down sampling. ResNet50 v1 has stride = 2 in the first 1x1 convolution, whereas v1.5 has stride = 2 in the 3x3 convolution
This difference makes ResNet50 v1.5 slightly more accurate (~0.5% top1) than v1, but comes with a small performance drawback (~5% images/sec).
| Framework | Source | FP32 throughput (img/s) bsz=128 |
FP32 speedup bsz=128 |
AMP throughput (img/s) bsz=256 |
AMP speedup bsz=256 |
|---|---|---|---|---|---|
| OneFlow | OneFlow-Benchmark | 12411.97 | 31.21 | 33141.02 | 22.50 |
| NGC MXNet | NVIDIA-DeepLearningExamples | 11233.92 | 28.67 | 30713.68 | 22.03 |
| NGC TensorFlow 1.x | NVIDIA-DeepLearningExamples | 9514.64 | 26.25 | [1]29171.69w/XLA 24734.22 |
24.34w/XLA 26.17 |
| NGC PyTorch | NVIDIA-DeepLearningExamples | 10917.09 | 29.72 | 22551.16 | 28.09 |
| MXNet | gluon-cv | 9579.74 | 24.93 | 10565.55 | 12.67 |
| TensorFlow 2.x | TensorFlow-models | 9418.44 | 29.27 | 19314.31 | 17.96 |
| PyTorch | PyTorch-examples | 10021.29 | 28.75 | [2] - | - |
| PaddlePaddle | PaddleCV | 9348.17 | 26.50 | [3]10633.22 11617.57w/DALI |
10.2 13.1w/DALI |
| MindSpore | MindSpore-model_zoo | 10731.78 | 29.02 | 24183.95 | 21.67 |
[1]: AMP throughput of TensorFlow 1.x is obtained with or without XLA and using bsz = 224, because when bsz = 256 OOM (out of memory) will be encountered.
[2]: The PyTorch official benchmark repository PyTorch-examples does NOT support AMP, we will use NVIDIA-APEX plug-in for testing in the near future.
[3]: The AMP throughput 10633.22 img/s of PaddlePaddle is obtained with bsz = 224 and without DALI, because when bsz = 256 OOM will be encountered. The throughput 11617.57 img/s is obtained with bsz = 196 and with DALI-paddle plug-in because using DALI will occupy more GPU device memory, so bsz = 224 or 256 both encounters OOM. The official data 28594 img/s provided by PaddlePaddle is tested on V100 32G and the PaddlePaddle docker image with DALI not released, so we cannot replicate this result. If anyone can help us improve PaddlePaddle test results, please contact us by issue.
Our results were obtained by running the applicable training scripts on 4 nodes with 8x Tesla V100-SXM2-16GB GPUs each. The specific training script that was run is documented in the corresponding model's README. The bsz means batch size per GPU.
| Framework | Source | FP32 throughput bsz=max |
FP32 throughput bsz=32 |
AMP throughput bsz=max |
AMP throughput bsz=64 |
|---|---|---|---|---|---|
| OneFlow | OneFlow-Benchmark | 4664.10 bsz=96 |
3689.80 | 15724.70 bsz=160 |
9911.78 |
| NGC TensorFlow 1.x | NVIDIA-DeepLearningExamples | 3089.74 bsz=48 |
2727.90 | 11650.0w/XLA bsz=96 |
[4]9409.2w/XLA 5189.07W/O XLA |
| NGC PyTorch | NVIDIA-DeepLearningExamples | 3039.3 bsz=48 |
2885.81 | 10349.12 bsz=96 |
9331.72 |
| PaddlePaddle | PaddleNLP | 3167.68 bsz=96 |
2073.60 | 5452.35 bsz=160 |
3406.36 |
| OneFlowW/O clip | OneFlow-Benchmark | 4799.64 bsz=96 |
4019.45 | 17210.63 bsz=160 |
11195.72 |
| [5]MXNetW/O clip | gluon-nlp | 4340.89 bsz=64 |
3671.45 | 14822.31 bsz=128 |
11269.14 |
| TensorFlow 2.x | TensorFlow-models | 2244.38 bsz=64 |
1551.52 | 4168.79 bsz=96 |
3194.02 |
| MindSpore | MindSpore-model_zoo | 3051.3 bsz=64 |
2457.8 | 6068.55 bsz=128 |
4659.76 |
[4]: AMP throughput of TensorFlow 1.x is obtained with or without XLA.
[5]: The MXNet BERT script of the gluon-nlp repository does NOT support clip_by_ global_norm operation in Adam optimizer. W/O clip_by_global_norm operation, the throughput will be larger and the the fine-tuning accuracy may be lower. So we also tested OneFlow data W/O clip operation for comparison.
This section maintains the results of the special case models:
- WideDeepLearning,
- InsightFace,
- Generative Pre-trained Transformer (GPT).
on 4 nodes with 8x Tesla V100-SXM2-16GB GPUs each.
| Framework | Version | Source |
|---|---|---|
| OneFlow | 0.2.0 | OneFlow-Benchmark |
| HugeCTR | 2.2 | samples/wdl |
We take GPU memory usage and latency(the time consumption of each iter) as the standard of performance evaluation.
Our results were obtained by running the applicable training scripts on 4 nodes with 8x Tesla V100-SXM2-16GB GPUs each. In addition, the main parameters are as follows:
batch_size = 16384, deep_embedding_vec_size = 32, hidden_units_num = 7
| deep_vocab_size | OneFlow Latency per Iteration / ms | HugeCTR Latency per Iteration / ms | OneFlow Mem Usage / MB | HugeCTR Mem Usage / MB | Mem Usage Ratio |
|---|---|---|---|---|---|
| 3200000 | 22.414 | 21.843 | 1,115 | 3217 | 35% |
| 6400000 | 22.314 | 26.375 | 1,153 | 4579 | 25% |
| 12800000 | 22.352 | 36.214 | 1,227 | 7299 | 17% |
| 25600000 | 22.399 | 57.718 | 1,379 | 12745 | 11% |
| 51200000 | 22.31 | OOM | 1,685 | OOM | - |
| 102400000 | 22.444 | OOM | 2,293 | OOM | - |
| 204800000 | 22.403 | OOM | 3,499 | OOM | - |
| 409600000 | 22.433 | OOM | 5,915 | OOM | - |
| 819200000 | 22.407 | OOM | 10,745 | OOM | - |
- notes:OOM is the abbreviation of out of memory, which means an error is reported due to insufficient GPU memory
on 1 node with 8x Tesla V100-SXM2-16GB GPUs.
| Framework | Version | Source |
|---|---|---|
| OneFlow | 0.3.4 | oneflow_face |
| deepinsight | 2021-01-20 update | deepinsight/insightface |
| node_num | gpu_num_per_node | batch_size_per_device | FP16 | Model Parallel | Partial FC | OneFlow num_classes | MXNet num_classes |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 64 | True | True | True | 2000000 | 1800000 |
| 1 | 8 | 64 | True | True | True | 13500000 | 12000000 |
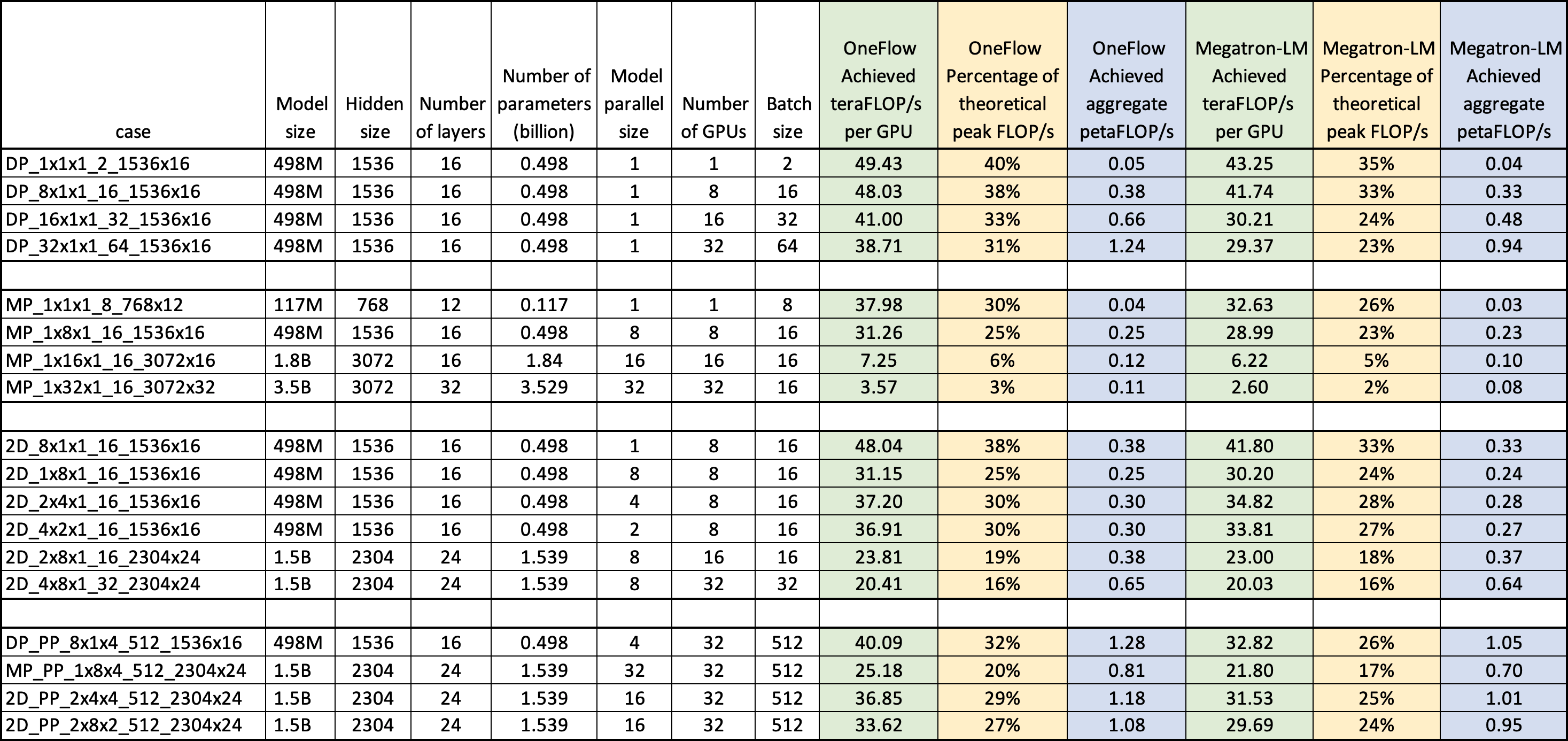
Following figure shows the achieved floating-point operations per second for both OneFlow-GPT and Megatron-LM on a claster with 4 Nodes (each equiped with 8x Tesla V100-SXM2-16GB GPUs and InfiniBand 100 Gb/sec ethernet connection). All results show that OneFlow-GPT has better performance than Megatron-LM under the same environment. Please find more detail in DLPerf GPT Benchmark Test Report.