-
First of all, please do install Anaconda in your machine
-
Go to the .\Scripts folder and run the script that will perform the environment setup:
- environment.bat (if you are running Windows)
- ./environment.sh (for you, Linux folks)
-
Once the script finishes running, that environment will be active. The name of the environment is cntk24-cntkveinteractive, in case you want to activate it manually.
-
Run the main.py to check that the CNTK environment and dependencies have been propertly setup. The output will show the version of the CNTK distribution, as well as the number of CPUs and GPUs available in our machine.
The workshop will use the following datasets:
* MNIST Hand Written Digits
* NIST SD4 Fingerprints
The data is not provided in this repo, but instead needs to be downloaded and processed sepparately. These can be downloaded, and have the needed transformations applied automatically, by running the following Python command from the base directory:
python retrieve_datasets.py
Both datasets are described to a greater extent in the next sections:
The initial exercises of this workshop will use the MNIST Handwritten Digits database; this publicly available dataset has become a sort of de facto industry standard to test the performance of certain image classification algorithms. Even though a detailed description of this data set is not intended here (more information here), suffice to say that each image represents a handwrittend digit, from 0 to 9, as an array of 9x9 pixels.
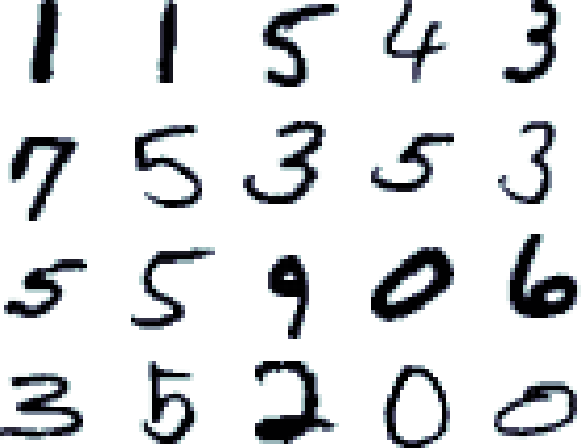
The folder ./mnistdata contains both the script to download the data set, as well as the classes tasked with reading and writing the images. The mnist_downloader.py file will download the images into the directory specified in the settings.py file. Then, both the training and test datasets will be serialized individually into two files in CTF format.
These files will then be easily read by CNTK using the built-in CTF deserializer.
The NIST-SD4 is a freely available fingerprint collection, compiled and curated by the NIST (National Institute of Standards and Technology). It contains 2000 8-bit gray scale fingerprint image pairs. Each image is 512-by-512 pixels with 32 rows of white space at the bottom and classified using one of the five following classes:
- Arch (A)
- Left Loop (L)
- Right Loop (R)
- Tented Arch (T)
- Whorl (W)
The database is evenly distributed over each of the five classifications with 400 fingerprint pairs from each class.
The text file that accompanies each image gives the Gender, Class and History information extracted from the ANSI/NIST-ITL formatted (AN2) file.
NIST Special Database 4 has the following features:
- 2000 8-bit gray scale fingerprint image pairs including classifications
- 400 fingerprint pairs from each of the five classifications - Arch, Left and Right Loops, Tented Arch, Whirl)
- each of the fingerprint pairs are two completely different rollings of the same fingerprint
- 19.7 pixels per millimeter resolution
- Suitable for automated fingerprint classification research, the database can be used for algorithm development and system training and testing.
The default file layout and names in the dataset is not very convenient for the training and testing processes that will be done as part of this experiment. The following transformations will be done to the files:
- All files are distributed in two folders: Test and Train.
- Test files is a subset of 500 images (250 pairs), corresponding to the figs_0 folder of the original data set.
- The remaining 1750 pairs of images - corresponding to the figs_1 to figs_7 folders - are localted in the Train folder.
- All text files have been removed.
- Naming convention of file names has changed to XXXX_O_FF_G_C.png, with the following placeholders:
- XXXX: Identifier of the individual
- 0: Order
- FF: Finger number
- G: Gender, with possible values F and M
- C: Fingerprint Class
Once the files have been distributed and renamed, a last processing stage takes place. The goal is to convert the images into a text file, with the labels in One-Hot Encoding format, followed by the list of all the pixels in a single vector of 262.144 bytes, which will be the format that will be fed to the autoencoder.
Codes for Order of fingerprint
| Code | Description |
|---|---|
| F | First |
| S | Second |
Codes for Gender
| Code | Description |
|---|---|
| M | Male |
| F | Female |
Codes for Finger numbers^
| Number | Finger |
|---|---|
| 01 | Right Thumb |
| 02 | Right Index |
| 03 | Right Middle |
| 04 | Right Ring |
| 05 | Right Little |
| 06 | Left Thumb |
| 07 | Left Index |
| 08 | Left Middle |
| 09 | Left Ring |
| 10 | Left Little |
Codes for Fingerprint class:
| Class | Description |
|---|---|
| A | Arch |
| L | Left Loop |
| R | Right Loop |
| T | Tented Arch |
| W | Whorl |
Pablo Álvarez Doval - @PabloDoval
Rodrigo Cabello - @mrcabellom