
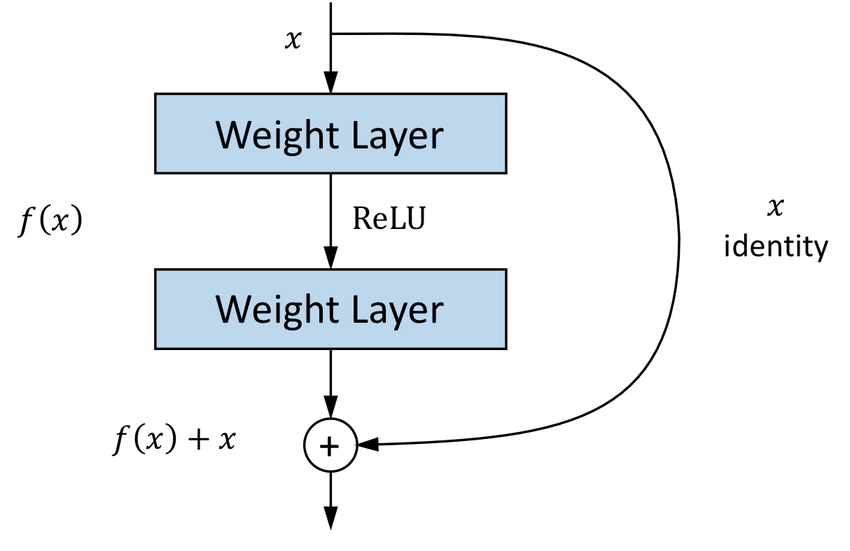
The formulation of F(x)+x can be realized by feedforward neural networks with ''shortcut connections'' (see scheme). Shortcut connections are those skipping one or more layers. In our case, the shortcut connections simply perform identity mapping, and their outputs are added to the outputs of the stacked layers (see scheme). Identity shortcut connections add neither extra parameter nor computational complexity. The entire network can still be trained end-to-end by SGD with backpropagation, and can be easily implemented using common libraries
Example of ResNet50 vs Xception vs Inception-V3 vs VGG-19 vs VGG-16 as reference model.

Detailed example of GoogLeNet a.k.a. Inception-V1 (Szegedy, 2015) as reference model.
.png)
- [Article] Kaiming He et al Deep Residual Learning for Image Recognition. (CVPR 2015)
- [Image] A Basic Residual Block
- [Image] Deep Feature-Based Classifiers for Fruit Fly Identification (Diptera: Tephritidae)
- [Image] Googlenet/InceptionV1 architecture
- [Notebook] skin cancer resnet50
- [Notebook] MinorProject_skinLesions