Bagimli Degisken(Y): bir olay veya deneyin ciktisini temsil eder. Bagimli degiskenimiz, deneydeki diger degiskenlerin hareketliliginden etkilenir. y ile sembolize ediyoruz.
Tahmin edilmek istenen deger
Bagimsiz Degisken(X): Bagimli degisken uzerinde etki yaratan degiskenlere denir. X ile gosteriyoruz.
Bagimli degiskenin bagimsiz degiskenlerle olan iliskini modellemek icin kullanilan istatisksel bir yontemdir.
Regresyon Modelleri:
- Doğrusal Regresyon: Bağımlı değişken ile bağımsız değişkenler arasındaki ilişkiyi doğrusal bir denklemle ifade eder.
- Polinom Regresyon: Bağımlı değişken ile bağımsız değişkenler arasındaki ilişkiyi polinom bir denklemle ifade eder.
- Lojistik Regresyon: Bağımlı değişkenin iki kategorik sınıf arasındaki ilişkisini modellemek için kullanılır.
Regresyon Analizinin Uygulama Alanları:
- Pazarlama: Ürün fiyatlarının talep üzerindeki etkisini tahmin etmek.
- Ekonomi: Ekonomik değişkenler arasındaki ilişkileri analiz etmek.
- Sağlık: Hastalık riskini tahmin etmek veya tedavi sonuçlarını değerlendirmek.
- Finans: Hisse senedi fiyatlarını tahmin etmek veya risk analizi yapmak.
house = pd.read_csv("../resources/housing.csv")
house
# Konut fiyatlarini etkileyen cesitli faktorleri incelemek
# icin olusturulmus bir dataframe
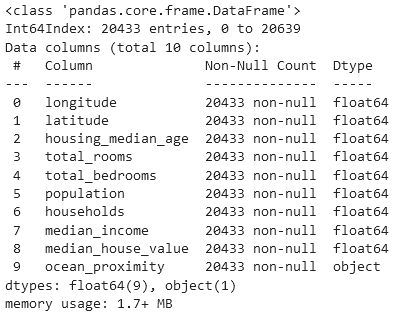
house.info()
# **total_bedrooms** inceledigimizde, 207 tane bos veri var.
# Bunlar analiz icin sorun cikartir.
Bakildiginda, elimizdeki dataframe’de eksik veriler var. Bunun icin birkac yontem var.
- Eksik Verileri Silme:
- Eğer eksik verilerin olduğu satırların sayısı çok az ise, bu satırları veri setinden tamamen çıkarabilirsiniz. Ancak, veri setinizdeki önemli bilgileri kaybetme riski olduğunu unutmayın
- Eksik Verileri Doldurma:
- Eksik verileri, o kolondaki diğer verilerin istatistiksel özelliklerini kullanarak doldurabilirsiniz. Örneğin, eksik verileri o kolondaki diğer verilerin ortalaması, medyanı veya modu ile doldurabilirsiniz.
- Eksik verileri doldurmak için pandas kütüphanesindeki fillna() fonksiyonunu kullanabilirsiniz. Örneğin, eksik verileri ortalamayla doldurmak için aşağıdaki gibi bir kod kullanabilirsiniz:
df['eksik_kolon'].fillna(df['eksik_kolon'].mean(), inplace=True)-
Eksik Verileri Tahmin Etme:
- Eksik verileri, diğer bağımsız değişkenlerin kullanıldığı bir tahmin modeli kullanarak tahmin edebilirsiniz. Örneğin, eksik verileri bir doğrusal regresyon modeli kullanarak tahmin edebilirsiniz.
- Eksik verileri tahmin etmek için sklearn kütüphanesindeki LinearRegression() sınıfını kullanabilirsiniz. Örneğin, eksik verileri doğrusal regresyon ile tahmin etmek için aşağıdaki gibi bir kod kullanabilirsiniz:
Biz ise inceledigimiz dataframe’de once ortalama ve medyan degerlerine bakalim.
from statistics import median print(f"Ortalama = {house.total_bedrooms.mean()}") print(f"Medyan = {median(house.total_bedrooms)}") #Bu kod ile total_bedrooms icin **ortalama'sini** ve **Medyan** degerinin hesaplanmasini gosteriyor. #Eger kullanmaya elverisli olup olmadigini gormek istersek buradan hesapliyoruz. # Cikti => Ortalama = 537.8705525375618 Medyan = 429.0
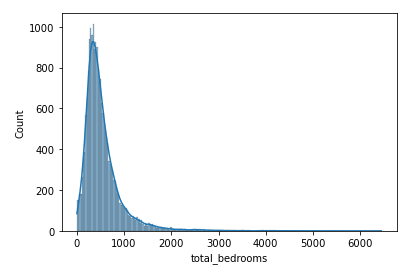
import seaborn as sns sns.histplot(house.total_bedrooms, kde=True) # kde = True -> yogunluk cizgisi olarak adlandiririz. # elimizdeki verileri gorsellestiriyoruz. """ Seaborn kutuphanesini import edip **total_bedrooms** icin histogram cizdiriyoruz. histogram cizmek icin **histplot** fonksiyonu kullaniriz **kde=True** => yogunluk egrisi """
house.dropna(inplace=True) # eksik degerlere sahip satirlari siliyoruz ve kaydediyoruz. house.info() # total_bedrooms'taki eksik degerli olan satirlari sildik ve tum dataframe'de # eksik satir kalmadi. # eksik satir problemi icin 3 farkli yol var. # 1. Medyan ile doldur # 2. Ortalama ile doldur # 3. Dropna ile satirlari sil.
sns.histplot(house.total_bedrooms, kde=True)
from scipy.stats import skew
scipy.stats kutuphanesinden skew() fonksiyonunu import ettik. total_bedrooms sutunun carpikligini(skewness) degerini hesaplamak icin kullanacagiz.
Bir veri dagiliminin simetrisizligini veya simetrik olma durumunu gormek icin hesaplanir.
Negatif bir değer: Veri setinin sol tarafta uzandığını (sağa çarpık olduğunu) gösterir. Pozitif bir değer: Veri setinin sağ tarafta uzandığını (sola çarpık olduğunu) gösterir. Sıfıra yakın bir değer: Dağılımın daha simetrik olduğunu ifade eder.
0'a Yakın Değerler: Dağılımın simetrik olduğunu veya çarpıklığın çok az olduğunu gösterir. 0 ile ±0.5 Arası Değerler: Çok hafif bir çarpıklığı gösterir. ±0.5 ile ±1 Arası Değerler: Orta düzeyde çarpıklık olduğunu ifade eder. ±1'den Büyük Değerler: Yüksek çarpıklığı belirtir
import numpy as np from scipy.stats import skew # Sayı dizisi data = np.array([1, 1, 1, 2, 3, 4, 4, 5, 18, 190]) # Çarpıklık hesaplaması skewness = skew(data) # Sonucu yazdırma print("Çarpıklık:", skewness) # Cikti # Çarpıklık: 2.6316589096189
Negatif Carpiklik:
import numpy as np from scipy.stats import skew # Negatif çarpıklığa sahip veri seti negative_skewed_data = np.array([1000, 900, 800, 700, 600, 500, 400, 300, 20, 10]) #baska bir veri ornegi # negative_skewed_data = np.array([1, 2000, 3000, 4000, 5000, 6000, 7000]) skewness = skew(negative_skewed_data) # Sonucu yazdırma print("Çarpıklık:", skewness) # Çarpıklık: -0.24697270438946498
Verisetimiz icin konusacak olursakta eger:
skew(house.total_bedrooms) #cikti: **3.45929235876747**
total_bedrooms sutunun carpiklik degeri pozitif olarak 3.45. Bu bize saga dogru carpiklasmanin oldugunu soyluyor. Yani ortalamamiz normalde daha dusuk iken ortalamayi yukseltip yukari cikartan birkac deger var. Bunun yuksek olmasi, genel verilerimiz icin ortalama degerin dogru bir yorumlamaya acik olmadigini gosterir. Yani 10 tane verimiz var elimizde. Bunlardan 8 tanesi cok dusuk, eger bunlara gore ortalama bir deger hesabi yaparsak ortalamamiz dusuk cikar. Ama kalan 2 deger o kadar yuksek ki, ortalama degerimizi yukari yonlu bir degere cikartiyor. Bu da genel verilerimiz icin ortalama degerin dogru bir veri olmadigini soylemis oluyor.
Korelasyon, iki değişken arasındaki ilişkiyi ölçen istatistiksel bir kavramdır. Korelasyon, değişkenlerin birlikte nasıl hareket ettiğini ve birbirlerine ne kadar bağımlı olduklarını gösterir. Korelasyon katsayısı, -1 ile 1 arasında değer alır. Pozitif bir korelasyon katsayısı, iki değişken arasında doğrusal bir ilişki olduğunu gösterirken, negatif bir korelasyon katsayısı ise iki değişken arasında ters yönlü bir ilişki olduğunu gösterir. Korelasyon katsayısı 0 ise, iki değişken arasında bir ilişki olmadığını gösterir.
house.drop("ocean_proximity", axis=1).corr()
ocean_proximity sutunu icin herhangi bir corelasyon yapamayacagimiz icin once onu kaldiriyoruz. Daha sonra .corr() fonksiyonunu cagiriyoruz ve her alanin kendi iclerindeki corelasyonunu hesapliyoruz. korelasyon katsayilari +1 ile -1 arasinda degeri vardir. +1'e yakin olan bir degerde, iki degisken arasinda guclu bir korelasyonun oldugunu gosterir. Bir degiskenin degeri artarken, diger degiskende onunla beraber arttigini gosterir. Bu iyidir.
-1'e yaklasan negatif bir korelasyon ise iki degisken arasinda guclu bir bag olmadiigini, birisi artarken digerinin de azaldigini gosterir. Guclu bir dogrusal iliski vardir.
0'a yakin korelasyonda ise iki degisken arasindaki bagin zayif oldugunu gosterir.
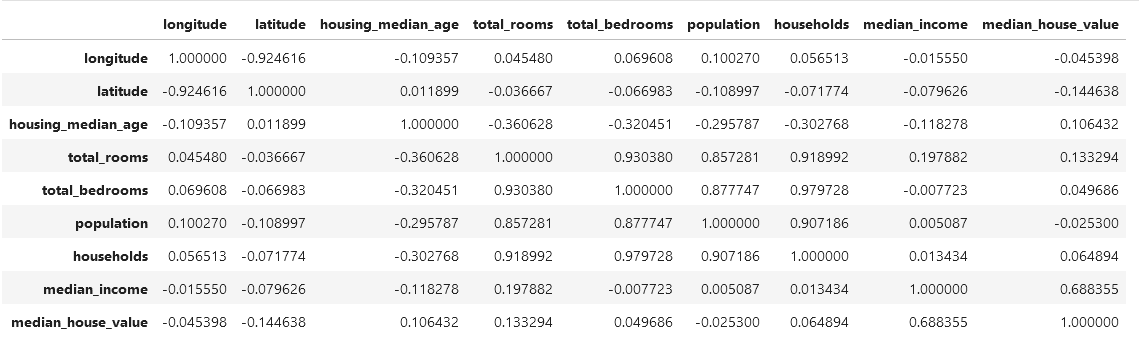
Örneğin, median_house_value (ortalama ev değeri) ile median_income (ortalama gelir) arasında 0.688 olan pozitif bir korelasyon var. Bu değer, ortalama gelir ile ev değeri arasında orta düzeyde pozitif bir ilişki olduğunu gösterir. Yani, genellikle ortalama gelir arttıkça ev değeri de artma eğilimindedir.
longitude ve latitude arasında -0.92 olan güçlü negatif bir korelasyon vardır. Bu, coğrafi olarak birbirine yakın bölgelerin koordinatları arasında güçlü bir ters ilişki olduğunu gösterir. Yani, enlem ve boylam arasında güçlü bir ters ilişki vardır, yani biri artarken diğeri azalma eğilimindedir.
sns.heatmap(house.drop("ocean_proximity", axis=1).corr(), annot=True)
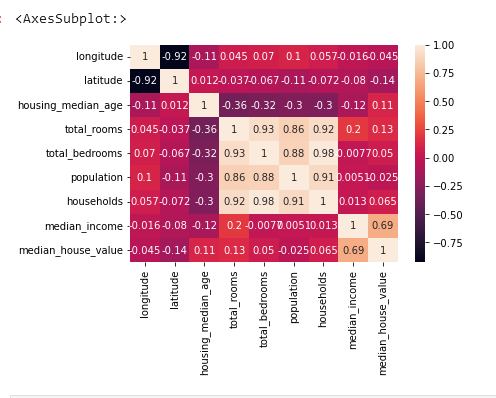
COKLU BAGLANTI PROBLEMI VAR
Dataframe’e baktigimiz zaman, kategorik degerleri sayisallastirirsak eger modelimizin anlayacagi bir sekile getirmis oluruz
Bunun icin once pd.get.dummies() fonksiyonunu kullanacagiz. Bu fonksiyon elimizde bulunan kategorik sutunu, yeni bir dataframe olusturarak benzersiz degerler icin birer sutun olusturur. Her id’nin hangi degerdeyse, o degere 1 koyar, diger degerlere 0 koyar. Bu sayede, kategorik sutunumuz sayisallasmis olur.
Bu dataframe’de ise ocean_proximity sutununa bakiyoruz. Benzersiz degerleri
array(['NEAR BAY', '<1H OCEAN', 'INLAND', 'NEAR OCEAN', 'ISLAND']bunlar.
Bunlar icin once hepsine sutun olusturup; 1 ve 0 degerlerini yerlestiriyor.
house_new = house[["median_income", "ocean_proximity", "median_house_value"]] house_new
ocean_proximity sutunun benzersiz degerlerine bakiyoruz
house_new.ocean_proximity.unique() # array(['NEAR BAY', '<1H OCEAN', 'INLAND', 'NEAR OCEAN', 'ISLAND'], # dtype=object)
pd.get_dummies(house_new.ocean_proximity, dtype=int) # ocean_proximity sutunu, metin tabanli bir sutun. Bunu sayisal forma donusturmek icin kullaniyoruz.
olusturdugumuz yeni dataframe’i sectikten sonra fonksiyonumuzu uyguluyoruz.
Simdi olusturdugumuz house_new adli yeni dataframe’e kategoriden sayisal veri haline getirdgimiz yeni sutunlari ekleyelim.
Daha sonra da kategori halinde olan ocean_proximity sutununu silelim.
house_new = house_new.join(pd.get_dummies(house_new.ocean_proximity, dtype=int)) house_new.drop("ocean_proximity", axis=1, inplace=True) house_new
Simdi tahmin etmesini istedigimiz median_house_value sutununu dataframe’den kaldiriyoruz. Kaldirdiktan sonra olusan yeni dataframe’imiz BAGIMSIZ DEGISKEN(X)’leri iceriyor sadece.
X = house_new.drop("median_house_value", axis=1) X
Bagimli Degisken: Bir deneyin sonucunu veya incelenen olayin ciktisini temsil eder. Bagimli degisken, diger degiskenlerden etkilenir. Genellikle tahmin etmeye calistigimiz veya anlamaya calistigimiz degiskendir. Dataframe'imizde ise ev fiyatlari bagimli degisken oluyor. Evin konumu, buyuklugu, oda sayilari gibi degiskenler bagimli degiskenimizi etkiliyor olabilir.
Bagimsiz Degisken: Bagimli degisken uzerinde etki yaratan degiskenlerdir. Bagimsiz degiskenler, bagimli degisken uzerinde etki yaratir. Bagimli degiskeni aciklamak veya tahmin etmek icin kullanilir.
X = house_new.drop("median_house_value", axis=1)
Bu satırda, house_new DataFrame'inden "median_house_value" sütunu drop() fonksiyonuyla çıkarılıyor. Burada "median_house_value" bağımlı değişkeni temsil ediyor olabilir. Ardından, geriye kalan sütunlar, yani "median_income", "<1H OCEAN", "INLAND", "ISLAND", "NEAR BAY", "NEAR OCEAN" bağımsız değişkenler olarak X'e atanıyor. Yani X, bağımsız değişkenleri içeren bir DataFrame oluyor. Bu veriler, muhtemelen bir makine öğrenimi modelinde bağımlı değişkeni tahmin etmek için kullanılacak özelliklerdir.
Simdi ise tahmin edilmesini istedigimiz sutunu alip, y degiskenine atiyoruz. Bu sayede bunu modele egitmek icin verecegiz. Egitim sonrasinda modelimiz tahminlerini yapacak.
y = house_new["median_house_value"] y
Bu kod, house_new DataFrame'indeki "median_house_value" sütununu bağımlı değişken olarak (yani hedef değişkeni olarak) kullanmak için ayrıştırıyor.
Bu satır, house_new DataFrame'inde bulunan "median_house_value" sütununu seçiyor. Bu sütun, muhtemelen modelin öğrenmeye çalışacağı ve tahmin etmeye çalışacağı değer olan ev fiyatlarını (median_house_value) içeriyor. y değişkenine bu sütunun verileri atandı.
Elimizdeki veri setinim egitim ve test setlerine ayirmak icin train_test_split fonksiyonunu kullanacagiz.
Verisetini ayirip, egitim setiyle modelimizi egitecegiz. Daha sonra daha once hic gormedigi veriler olan test setleri ile de modelimizi deneyecegiz.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42)
Egitimde kullanilacak degiskenlerimiz X_train ve y_train
Test icin kullanacaklarimiz ise, X_test ve y_test’tir.
burada yer alan test_size degeri ise, test setinin boyutunu belirtir. Burada verilerimizin yuzde 20’sini kullanacagini soyluyoruz.
Bagimli degiskenler ile bagimli degisken arasindaki lineer iliskiyi anlamak ve tahmin yapmak icin kullanilir.
Lineer regresyon, bağımsız değişkenlerin doğrusal bir kombinasyonunu kullanarak bağımlı değişkeni tahmin etmeye çalışır. Örneğin, ev fiyatlarını tahmin etmek istiyorsanız ve evin büyüklüğü, odaların sayısı gibi özellikleri kullanıyorsanız, lineer regresyon bu özelliklerin ağırlıklı toplamını kullanarak bir evin fiyatını tahmin etmeye çalışır.
from sklearn.linear_model import LinearRegression
sklearn.linear_model modülü, farklı lineer modellerin ve regresyon analizinin bulunduğu bir kütüphanedir.
model = LinearRegression() # lineer regresyon modeli olusturuldu model.fit(X_train, y_train) # olusturulan modele, egitim icin hazirlanan setler ile egitildi.
LinearRegression() fonksiyonu ile birlikte lineer regresyon modeli olusturup, model degiskenine atadik.
fit() fonksiyonu ile de olusturdugumuz verisetlerini parametre olarak verdik.
model.fit() işlemi tamamlandığında, model artık eğitilmiş bir lineer regresyon modelini temsil eder ve bu model, veriler üzerinde tahminler yapmak için kullanılabilir.
model.coef_ # array([ 37236.91280563, -27364.78639333, -105348.03795271, # 150467.39394476, -6918.61452005, -10835.95507867])
model.coef_, eğitilmiş bir lineer regresyon modelinin katsayılarını (coefficients) döndüren bir özelliktir. Bu katsayılar, bağımsız değişkenlerin (özelliklerin) model üzerindeki etkisini temsil eder.
Pozitif bir katsayı, o özelliğin artan bir değere sahip olduğunda bağımlı değişkenin de artacağını gösterirken, negatif bir katsayı tam tersini ifade eder.
X.columns # X veri setinin sutunlarinin adlarini verir. # Index(['median_income', '<1H OCEAN', 'INLAND', 'ISLAND', 'NEAR BAY', # 'NEAR OCEAN'], # dtype='object')
model.intercept_ # Cikti: 110311.42503458945
model’imizin intercept_ ozelligine erisiyoruz. Bu ozellik, dogrusal regresyon modelimizin kesim noktasi’ini temsil eder.
Kesim noktasi, bagimli degiskenin tahminindeki sabit terimi ifade eder.
Örneğin, ev fiyatlarını tahmin etmek istediğinizi düşünelim. Evin bulunduğu yer, odaların sayısı, gelir düzeyi gibi özellikleri kullanarak bir model oluşturdunuz. Modelin kesme noktası, bu özelliklerin tümü sıfır olduğunda, yani hiçbir etkenin hesaba katılmadığı bir durumda ev fiyatının tahmin edilen başlangıç değeridir.
Simdi egittigimiz modelimizden cikti almamiz gerekiyor. Bagimsiz degiskenleri(odaların sayısı, metrekare, konum vb.)
y_test_predict = model.predict(X_test)
model.predict() fonksiyonu, eğitilmiş bir makine öğrenimi modeli üzerinde yeni veri noktaları veya veri setleri için tahmin yapmaya olanak sağlar.
model.predict(X_test), eğitilmiş bir modelin test verileri üzerinde tahmin yapmasını sağlar. Yani, bu kod satırı, eğitilmiş bir modeli kullanarak test veri setindeki bağımsız değişkenlerin (X_test) değerlerine dayanarak bağımlı değişkenin (tahmin edilmek istenen değer) tahminlerini üretir.
from sklearn.metrics import r2_score r2_score(y_test, y_test_predict) # 0.5756744531463729
r2_score, R-kare olarak da bilinen belirli bir regresyon modelinin uyumunu değerlendirmek için kullanılan bir metrik veya ölçüttür. Bu metrik, bir regresyon modelinin veriye ne kadar iyi uyduğunu, yani bağımlı değişkenin (gerçek değerler) ne kadarını açıkladığını ölçer.
Verilen tahminler ve gerçek değerler arasındaki ilişkiyi değerlendirmek için kullanılır. Eğer tahmin edilen değerler gerçek değerlere daha yakınsa, R-kare değeri 1'e daha yakın olur. Ancak, eğer tahminler gerçek değerlerden çok uzaksa veya değişkenlik çok yüksekse, R-kare değeri düşük olur.
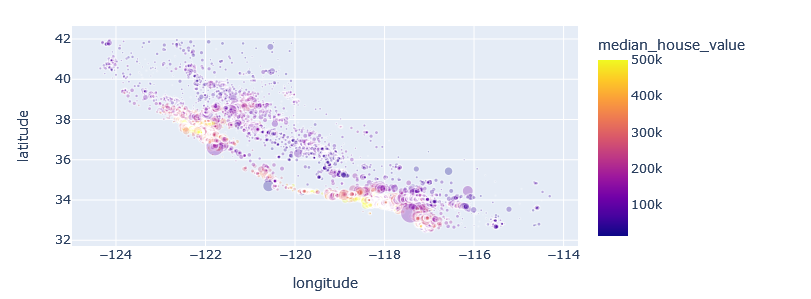
import plotly.express as px px.scatter(data_frame=house, x="longitude", y="latitude", color="median_house_value", size=house.population / 100, hover_data=["ocean_proximity"], opacity=0.3)










Siniflandirma, elimizdeki verileri belirli bir kategoriye alma islemidir. Ornegin bir e-postanin spam veya normal bir mail oldugunu belirlenmesinde kullanilir.
Veya bir goruntunun kopek mi kedi mi oldugunu belirlemede kullanilir.
Siniflandirma algoritmalarinda en cok kullanilanlar bunlardir:
Sınıflandırma algoritmaları arasında en yaygın olanları şunlardır:
- Naive Bayes
- Karar Ağaçları
- K-En Yakın Komşu (KNN)
- Destek Vektör Makineleri (SVM)
- Lojistik Regresyon
- Yapay Sinir Ağları

df = pd.read_csv("../resources/customer_data.csv")

df.info()
fea_2 sutununda eksik veriler mevcut, diger sutunlar 1125 veri icerirken, fea_2 ise 976 veri iceriyor.
float64 ve int64 DType ler olduguna gore, baskin tipler bunlar. Hic kategori verisinin olmadigini soyluyor.

df.describe()
describe() fonksyonu, sayisal sutunlarin istatistikel ozetini sunar.
Count: Gözlemlenen veri sayısı. Sutunda bulunan veri sayisini soyler. fea_2 icin 1125
Mean: Ortalama değer
Std: Standart sapma, verilerin ne kadar dağıldığını gösterir.
Min: En küçük değer
25%: Alt çeyrek (25. yüzdelik)
50%: Medyan (orta değer)
75%: Üst çeyrek (75. yüzdelik)
Max: En büyük değer
Bu istatistikler, her bir sayısal sütunun genel dağılımını ve merkezi eğilimini gösterir. Örneğin, fea_2 sütununda eksik veri var (count değeri farklı). Diğer sayısal sütunlardaki değerlerin dağılımı ve ortalaması da görülebilir.
???????????????????????
Verileri küçükten büyüğe sıraladığınızda, yüzde 25'lik dilim, tüm verilerin en düşük %25'ini, yüzde 50'lik dilim (veya medyan) tüm verilerin orta değerini ve yüzde 75'lik dilim ise tüm verilerin en yüksek %25'ini temsil eder. Bu, veri dağılımının genel bir görünümünü sağlar. Örneğin, fea_2 için medyan değeri 1281.5'tir. Verilerin yarısı bu değerden küçük, yarısı bu değerden büyüktür demektir. Bu istatistikler, veri setindeki değerlerin nasıl dağıldığını anlamak için kullanılır.

df.describe().T
Okunurlulugu arttirmak icin Transpoz aliyoruz.

df.label
df.fea_2.mean(), df.fea_2.median()
# (1283.9113729508197, 1281.5)Bu iki değer, "fea_2" sütunundaki verilerin merkezi eğilimini anlamamıza yardımcı olur. Örneğin, burada ortalamaya yakın bir medyan değeri var, bu da bu sütunun dağılımının ortalamaya yakın simetrik bir şekilde olduğunu gösterebilir.
df.fea_2.fillna(df.fea_2.mean(), inplace=True)
df.isna().sum()
Bos degerleri bulunan fea_2 sutununu, fea_2 sutunun ortalamasiyla dolduruyoruz. isna().sum() metoduyla da o sutunda eksik veri kalip kalmadigini kontrol ediyoruz. Ciktiya gore herhangi bir eksik veri kalmamis.
df.label.value_counts()
# 0 900
# 1 225
# Name: label, dtype: int64label sutununda 2 deger var, [0, 1]
0 degerinden 900 tane, 1 degerinden ise 225 tane varmis. Goruldugu uzere sinifsal dagilimda buyuk dengesizlik var. Model egitimi sirasinda sorun cikartabilir. Cunku, model egitimi sirasinda verisi cok olan sinifa daha fazla egilim gosterir. Bu da modelimizin yanilticiligini gosterir.
import seaborn as sns
import matplotlib.pyplot as plt
label_count = pd.DataFrame(
{
"Risk_Duzeyi":df.label.value_counts().index,
"Toplam_Sayi":df.label.value_counts().values
}
)
plt.title("Risk Dağılım Grafiği")
#sns.barplot(data=label_count, x="Risk_Duzeyi", y="Toplam_Sayi", hue="Risk_Duzeyi")
sns.barplot(x=df.label.value_counts().index,
y=df.label.value_counts().values,hue=df.label.value_counts().index)
Bu kod, veri setinizdeki "label" sütununda bulunan farklı değerlerin sayısını hesaplar. Bu değerlerin her birini, "Risk_Duzeyi" olarak ve her bir değerin kaç kez geçtiğini, "Toplam_Sayi" olarak içeren bir veri çerçevesi oluşturur. Ardından, bu verileri kullanarak bir çubuk grafiği oluşturur.
hue=df.label.value_counts().index olarak belirtilmiş. Bu, label sütunundaki farklı değerleri temsil eder ve her bir değer için farklı bir renk atanmasını sağlar. Örneğin, 0 ve 1 gibi iki farklı etiket varsa, her bir etiket farklı bir renkte gösterilebilir.
Tahminini yapacagimiz label sutununu Bagimsiz Degiskenler'i iceren verisetimizden cikartip yeni versetimizi olusturuyoruz.

X = df.drop(”label”, axis=1) X
Bagimli degiskenimizi de, y degiskenine atiyoruz
X = df.drop("label", axis=1)
y = df.labelX = df.drop("label", axis=1): Bu satır, "label" sütununu hedef değişken olarak kabul edip, geri kalan tüm sütunları (bağımsız değişkenleri) içeren bir veri seti oluşturur. drop fonksiyonu, "label" sütununu (axis=1 ile sütun olarak belirtilmiş) veri setinden çıkarır ve geri kalan tüm sütunları X adlı değişkene atar. Yani, X veri çerçevesi bağımsız değişkenleri içerir.
y = df.label: Bu satır, "label" sütununu (bu durumda tahmin edilmek istenen değerler) içeren veri setini y adlı değişkene atar. Bu, genellikle makine öğrenimi modellerinde tahmin edilmek istenen hedef değişkeni temsil eder.

y
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=42,
stratify=y)Bu kod, veri setini eğitim ve test alt kümelerine bölmek için kullanılır.
- train_test_split() fonksiyonu, veri setini bağımsız değişkenler (X) ve hedef değişken (y) olmak üzere iki farklı kısma böler.
- test_size=0.2 parametresi, veri setinin ne kadarının test seti olarak ayrılacağını belirtir. Bu durumda, veri setinin %20'si test seti olarak ayrılacaktır.
- random_state=42 parametresi, veri setini rastgele bölerken kullanılacak olan rastgelelik durumunu belirler. Bu sayede işlemi tekrarladığınızda aynı rastgele bölme elde edilir, sonuçların tekrarlanabilir olmasını sağlar.
- stratify=y parametresi, veri setinin dengesiz sınıflara sahip olması durumunda sınıf dengesizliğini korumak için kullanılır. Burada y (hedef değişken) tarafından belirtilen sınıf oranlarını eğitim ve test setlerinde korur. stratify parametresi, genellikle sınıflandırma problemlerinde kullanılır. Özellikle dengesiz sınıflara sahip veri setlerinde, sınıf dengesizliğini korumak için oldukça önemlidir.
Sınıf dengesizliği, bir sınıfın diğerlerine göre çok daha fazla temsil edilmesi veya az temsil edilmesi durumudur. Örneğin, hastalık tespiti gibi durumlarda hastalıklı insanlar genellikle sağlıklı insanlara göre daha azdır. Eğer veri setindeki hastalıklı hastalar az temsil edilirse (örneğin, yalnızca %5), model hastalıklı olmayanları çok iyi tahmin edebilirken, hastalıklı olanları doğru bir şekilde tahmin etmekte zorlanabilir.
Bu durumu önlemek için stratify parametresi, hedef değişkenin (genellikle y) sınıf dağılımını korur. train_test_split fonksiyonu, veri setini bölmeden önce her iki alt kümede de orijinal veri setindeki sınıf oranlarını koruyacak şekilde böler. Yani, eğitim ve test setleri oluşturulurken her iki alt kümede de sınıf dağılımı oranı, ana veri setiyle aynı olur. Bu, modelin her iki veri setinde de eğitilirken, her sınıfın temsil edilme oranının korunmasını sağlar. Bu da modelin her sınıf için daha dengeli bir şekilde eğitilmesine olanak tanır ve daha iyi genelleme yapmasına yardımcı olabilir.
🤖 **RandomForestClassifier:** Birden çok karar ağacını eğiterek ve her bir ağacın tahminlerini bir araya getirerek sınıflandırma yapan bir ensemble (ensambl) modelidir. Her bir ağaç, rastgele örneklemlerden ve rastgele özelliklerden oluşan alt veri setleri üzerinde eğitilir. Ardından, bu ağaçların tahminleri bir araya getirilerek en doğru sonucun elde edilmesi hedeflenir.from sklearn.ensemble import RandomForestClassifier
model_rf = RandomForestClassifier()
model_rf.fit(X_train, y_train)Bu kodda RandomForestClassifier sınıfından bir model oluşturup ardından bu modeli eğittiniz. RandomForestClassifier, rastgele orman algoritmasını kullanan bir sınıflandırma modelidir.
model_rf = RandomForestClassifier() ile bir rastgele orman modeli oluşturuldu ve daha sonra model_rf.fit(X_train, y_train) komutuyla bu model, eğitim veri seti (X_train ve y_train) üzerinde eğitildi. fit fonksiyonu, modelin veriyi kullanarak içsel olarak parametrelerini ayarladığı ve veriyi temsil eden bir yapı oluşturduğu aşamadır. Eğitim süreci, modelin veriler arasındaki ilişkileri öğrenmesini sağlar, böylece daha sonra test veri seti üzerinde doğru tahminler yapabilir.
from sklearn.metrics import classification_report, confusion_matrix
print(classification_report(y_test, model_rf.predict(X_test)))
classification_report, doğruluk, hassasiyet, duyarlılık (recall), F1 skoru ve destek (support) gibi değerleri içeren bir rapor sunar. y_test, gerçek etiketlerin olduğu test seti verileri. model_rf.predict(X_test), modelin test seti üzerindeki tahminlerini yapar.
classification_report
True Positive (TP): Gerçek değeri pozitif olan ve model tarafından doğru bir şekilde pozitif olarak tahmin edilen örnekler.
False Positive (FP): Gerçek değeri negatif olan ancak model tarafından yanlış bir şekilde pozitif olarak tahmin edilen örnekler.
True Negative (TN): Gerçek değeri negatif olan ve model tarafından doğru bir şekilde negatif olarak tahmin edilen örnekler.
False Negative (FN): Gerçek değeri pozitif olan ancak model tarafından yanlış bir şekilde negatif olarak tahmin edilen örnekler.
Predicted Positive Predicted Negativie
Actual Positive TP FN
Actual Negative FP TN
Hassasiyet (Precision): Bu, modelin pozitif olarak tahmin ettiği örneklerin gerçekten pozitif olanların oranını ifade eder. Yani, modelin doğru pozitif tahminlerinin, tüm pozitif olarak tahmin edilen örneklerin oranıdır. Formülü şu şekildedir:
TP
Precision = ----------
TP + FP
Duyarlılık (Recall): Bu, gerçek pozitiflerin, modelin doğru bir şekilde pozitif olarak tahmin ettiği örneklerin oranını gösterir. Yani, gerçekten pozitif olan örneklerin, modelin tüm pozitif olarak tahmin ettiği örneklerin içinde ne kadarının doğru bir şekilde tanımlandığını gösterir. Formülü şu şekildedir
TP
Recall = -------------
TP + FN
F1-score, özellikle dengesiz sınıf dağılımlarına sahip veri setlerinde model performansını değerlendirmek için önemli bir metriktir. Bu ölçüm, precision ve recall arasındaki dengeyi sağlar. Eğer sınıflar arasında dengesizlik varsa (örneğin, bir sınıf diğerine göre çok daha az örneğe sahipse), doğruluk oranı yetersiz bir performans gösterebilir. F1-score, precision ve recall metriklerini birleştirerek, dengeli bir değerlendirme sunar. Eğer hem precision hem de recall yüksekse, F1-score da yüksek olacaktır. Ancak, bu metriklerden biri diğerine göre çok daha düşükse,
F1-score da düşük olur. Bu nedenle, dengesiz veri setlerinde model performansının daha iyi bir ölçütü olarak kullanılabilir.
Precision x Recall
F1-Score = ----------------------
Precision + Recall
support, her bir sınıf için veri setindeki gerçek örnek sayısını temsil eder. Formülü yoktur, bu sadece her bir sınıfın veri setindeki gözlemlenen örnek sayısını ifade eder. Sınıf dengesizliği durumunda, her bir sınıfın support değeri farklı olabilir. Özellikle çok az örneğe sahip sınıflar, modelin bu sınıfı öğrenme yeteneğini etkileyebilir. Bu durumda, modelin daha az destekle karşılaştığı sınıfların performansı daha düşük olabilir. support metriği, her sınıfın model performansını değerlendirirken göz önünde bulundurulmasına yardımcı olur.
Macro Average: Sınıf bazında hesaplanan metriklerin (precision, recall, f1-score gibi) ortalaması alınır. Her sınıfın metriği eşit ağırlıkta değerlendirilir.
Weighted Average: Sınıf bazında hesaplanan metriklerin (precision, recall, f1-score gibi) ağırlıklı ortalaması alınır. Bu ağırlıklar, sınıfların veri setindeki örnek sayılarına göre belirlenir. Büyük sınıfların performansı daha fazla etkiler.
Confision Matris

sns.heatmap(confusion_matrix(y_test, model_rf.predict(X_test)),
annot=True, fmt=".1f")
🤖 **DecisionTreeClassifier:** Temel bir sınıflandırma algoritmasıdır. Veri setini belirli koşullara göre bölerek bir karar ağacı oluşturur. Her bir düğüm, en iyi bölünme noktasını bulmaya çalışır ve veri setini bu özelliklerin değerlerine göre böler. Böylece veriyi sınıflandırmak için bir dizi kararlar zinciri oluşturur.
Modelimizi olusturuyoruz.
from sklearn.tree import DecisionTreeClassifier
model_tree = DecisionTreeClassifier()
model_tree.fit(X_train, y_train)
# DecisionTreeClassifier()
print(classification_report(y_test, model_tree.predict(X_test)))
Bu rapora göre, modelin sınıflandırma performansı düşük olarak değerlendirilebilir. Precision değerleri sınıf 0 için 0.82, sınıf 1 için ise 0.26 olarak hesaplanmıştır. Bu, sınıflandırılan örneklerin sadece yaklaşık olarak %26'sının gerçek sınıfı 1 olan örnekler olduğunu gösterir. Recall değerleri sınıf 0 için 0.78, sınıf 1 için ise 0.31 olarak hesaplanmıştır. Bu, gerçek sınıfı 1 olan örneklerin sadece yaklaşık olarak %31'inin doğru bir şekilde sınıflandırıldığını gösterir.
F1-score değerleri sınıf 0 için 0.80, sınıf 1 için ise 0.28 olarak hesaplanmıştır. F1-score, precision ve recall metriklerinin harmonik ortalamasını temsil eder. Bu değerler, modelin sınıflandırma performansının düşük olduğunu gösterir.
Accuracy değeri 0.68 olarak hesaplanmıştır. Bu, tüm sınıfların doğru bir şekilde sınıflandırılma oranının %68 olduğunu gösterir. Ancak, bu değer tek başına modelin performansını tam olarak yansıtmayabilir, çünkü sınıflar arasındaki dengesizlikleri göz ardı eder.
RandomOverSampler, azınlık sınıfındaki örneklerin sayısını çoğaltırken rastgele seçim yapar. Bu seçim işlemi, azınlık sınıfındaki örneklerin kopyalarını alarak veri setini dengeler. Örneğin, azınlık sınıfında 100 örnek varken, RandomOverSampler kullanıldığında bu örneklerin kopyaları alınarak veri setinde daha fazla azınlık sınıfı örneği oluşturulabilir.
from imblearn.over_sampling import RandomOverSamplersampler = RandomOverSampler()
X_new, y_new = sampler.fit_resample(X, y)fit_resample fonksiyonu, örnek sayısını artırmak veya azaltmak için bir örnekleme stratejisi uygular.
Öncelikle, RandomOverSampler() bir sampler nesnesi oluşturur. Daha sonra fit_resample yöntemi, X ve y verilerini alarak, X_new ve y_new olarak yeniden örnekleme yapmaktadır. Bu işlem, orijinal veri kümesindeki sınıf dengesizliğini ele almak için azınlık sınıfındaki örnekleri artırırken, çoğunluk sınıfındaki örnekleri azaltır veya değiştirir.

y_new.value_counts()
X_newtr, X_newts, y_newtr, y_newts = train_test_split(X_new, y_new, test_size=0.2,
random_state=42)X_new ve y_new veri setlerini train ve test setlerine bölmek için train_test_split işlevini kullanır. test_size=0.2 parametresi, veri setinin %20'sini test seti olarak ayarlar. random_state=42 parametresi ise bölme işleminin rastgele yapılmasını sağlar, bu sayede her çalıştırıldığında aynı rastgele bölme elde edilir. Böylece eğitim ve test verileri rastgele ve dengelenmiş şekilde ayrılır.
model_rfn = RandomForestClassifier()
model_rfn.fit(X_newtr, y_newtr)
# RandomForestClassifier()
print(classification_report(y_newts, model_rfn.predict(X_newts)))
Precision: Doğru pozitif tahminlerin toplam pozitif tahminlere oranıdır. 0 sınıfı için %93, 1 sınıfı için %88. Recall: Gerçek pozitiflerin doğru bir şekilde tahmin edilme oranıdır. 0 sınıfı için %86, 1 sınıfı için %93. F1-Score: Precision ve recall metriklerinin harmonik ortalamasıdır. Denge metriği olarak kullanılır. 0 sınıfı için %89, 1 sınıfı için %91. Accuracy: Doğru tahminlerin toplam tahminlere oranıdır. %90. Macro Avg: Sınıflar arasında ağırlıklandırılmamış ortalamadır. Sınıf sayısına bağlı olarak dengelenmemiş bir ölçüdür. Weighted Avg: Her sınıfın desteğine (support) göre ağırlıklı ortalamadır. Sınıflar arasındaki dengesizliği göz önünde bulundurur.
Bu sonuçlar, modelin genel olarak iyi performans gösterdiğini ve sınıflar arasında dengeli bir tahmin yapabildiğini gösteriyor.
sns.heatmap(confusion_matrix(y_newts, model_rfn.predict(X_newts)),
annot=True, fmt=".1f")

Siniflandirma problemlerinde, elimizdeki verileri bir etiket atayip, onu hangi veri oldugunu dogrudan soyleyebiliyoruz. Bunu (b) seklinde rahatca gorebiliriz. Ama Cluster bolumune gectigimiz zaman ise elimizdeki sonuc verilerini herhangi bir sonuca baglayamiyoruz. Sadece verileri belirli gruplara bolup oraya ait olduklarini soyluyoruz.
- Musteri Segmentasyonu
- Pazar Segmentasyonu
- Saglik ve Goruntu Isleme
Cluster benzer ozellikteki verileri bir araya getirerek gruplar olustururuz. Unsupervised(gozetimsiz) ogrenme yontemidir. Veri setindeki örneklerin birbirine olan benzerliklerini ölçerek, bu örnekleri gruplara ayırır. Bu gruplar, veri setindeki yapıyı ve ilişkileri anlamamıza yardımcı olur.
Cluster analizi icin kullanilan en yaygin yontem ise K-Means algoritmasidir.
Veri setindeki ornekler belirli kumelere bolunur. K-Means ise onceden belirlenen belirli sayida kumeye sahip olacagimizi varsayar, her bir kume icin merkez noktasi secer. Daha sonra ise her bir ornegi en yakin merkeze atar. Bu islemleri tekrar ederek optimum bir kume merkezi guncellemis olur.
Cluster’in basari kriteri; kume elemanlarini, kume merkezine olan uzakligini minimum seviyede tutmak, Kumeler arasi mesafeyi ise maximum tutmaktir.

import pandas as pd
df = pd.read_csv("../resources/Mall_Customers.csv")
dfVeri seti, bir alışveriş merkezindeki müşterilere ilişkin bilgileri içermektedir. DataFrame'in sütunları, "CustomerID" (müşteri kimliği), "Gender" (cinsiyet), "Age" (yaş), "Annual Income" (yıllık gelir) ve "Spending Score" (harcama puanı) olarak adlandırılmıştır.
import seaborn as sns
sns.scatterplot(data=df, x="Age", y="Annual Income (k$)",
hue="Gender", alpha=0.5)
Bu saçılma grafiği, müşterilerin yaşları ile yıllık gelirlerini cinsiyete göre gösteriyor gibi görünüyor.
müşterilerin yaşları ve yıllık gelirleri arasındaki ilişkiyi cinsiyet üzerinden görselleştiriyor.
sns.scatterplot(data=df, x="Age", y="Spending Score (1-100)",
hue="Gender", alpha=0.5)
Yaş ile harcama puanları arasındaki ilişkiyi cinsiyete göre gösteriyor gibi görünüyor.
Harcama puanları, yaşa göre nasıl dağılıyor, hangi yaş grubundaki müşterilerin daha yüksek veya düşük harcama puanına sahip olduğu gibi konularda fikir verebilir.
X = df[["Age", "Spending Score (1-100)"]]
X
from sklearn.cluster import KMeans
uzaklik = []
for n in range(1 , 11):
model = KMeans(n_clusters = n ,init='k-means++', n_init = 10 ,max_iter=300,
tol=0.0001, random_state= 42)
model.fit(X)
uzaklik.append(model.inertia_)Bu kod, sklearn kütüphanesindeki KMeans algoritmasını kullanarak farklı küme sayıları için KMeans modeli oluşturuyor. uzaklik adında bir boş liste oluşturuluyor. Daha sonra range(1, 11) döngüsü ile küme sayısını 1'den 10'a kadar artarak değiştiriyoruz. Her iterasyonda, belirtilen küme sayısı (n_clusters) ve diğer parametrelerle birlikte (init, n_init, max_iter, tol, random_state) K-Means modeli oluşturuluyor. Bu modeller fit() metodu ile veri setine(X) uyduruluyor.Modelin inertia değeri (model.inertia_) hesaplanıp, bu değer uzaklik listesine ekleniyor. Bu değer, KMeans algoritmasının o küme sayısı için inertia değerini temsil eder.Sonuç olarak, bu kod farklı küme sayıları için KMeans modeli oluşturup, her bir küme sayısı için inertia değerlerini hesaplayarak bu değerleri uzaklik listesine kaydeder. Bu değerler, küme sayısını belirlemede yardımcı olabilir, optimal küme sayısını belirlemek için inertia değerlerinin grafiği incelenebilir. Kod farklı küme sayıları için KMeans algoritmasını kullanarak her bir küme sayısının "inertia_" değerini hesaplar. Bu değer, veri noktalarının küme merkezine olan karesel uzaklıklarının toplamını ifade eder. Azalan inertia değeri, veri noktalarının kümeler içinde daha yoğun ve merkezlere daha yakın olduğunu gösterir. "uzaklik" listesi, farklı küme sayıları için inertia değerlerini içerir ve genellikle en uygun küme sayısını belirlemek için "dirsek" yöntemiyle kullanılır. Bu yöntem, veri setinin homojenliğini ve kümeler arasındaki farklılıkları anlamamıza yardımcı olur. İnertia, KMeans algoritması tarafından belirlenen küme merkezlerinin, her veri noktasının merkeze olan uzaklıklarının karelerinin toplamını ifade eder. Bu, her bir veri noktasının kendi küme merkezine olan uzaklığının ölçüsüdür ve bu uzaklıkların kareleri toplamıdır. Uzaklık ise genel olarak bir noktanın diğer bir noktaya olan mesafesini belirtir. İnertia, KMeans algoritmasının kümeleme performansını değerlendirmek için kullanılırken, uzaklık genellikle iki nokta arasındaki mesafeyi belirtmek için kullanılır. Kısacası, inertia, küme merkezlerine olan toplam uzaklık miktarını temsil ederken, uzaklık ise genellikle iki nokta arasındaki mesafeyi belirtir.
import matplotlib.pyplot as plt
import numpy as np
plt.figure(1 , figsize = (15 ,6))
plt.plot(np.arange(1 , 11) , uzaklik , 'o')
plt.plot(np.arange(1 , 11) , uzaklik , '-' , alpha = 0.5)
plt.xlabel('Küme Sayısı') , plt.ylabel('Uzaklık')
plt.show()
Bu kod, küme sayısının artışıyla inertia değerlerinin nasıl değiştiğini görselleştirmek için kullanılır.
matplotlib kütüphanesi kullanılarak bir grafik oluşturuluyor. figure() fonksiyonu bir figür oluşturur ve figsize parametresiyle figürün boyutları belirlenir.
plt.plot() fonksiyonu, küme sayısının değişimi ile inertia değerlerinin nasıl değiştiğini göstermek için kullanılır. np.arange(1, 11) ile x-ekseni (küme sayısı) değerleri belirlenirken, uzaklik listesindeki inertia değerleri y-ekseni (uzaklık) olarak atanır. 'o' parametresiyle nokta grafikleri, '-' parametresiyle ise çizgi grafiği çizilir. alpha=0.5 ise çizgilerin saydamlığını ayarlar.
plt.xlabel() ve plt.ylabel() ile x ve y eksenlerine etiketler atanır.
Son olarak, plt.show() ile grafiğin görüntülenmesi sağlanır.
Bu grafik, küme sayısının artışıyla inertia değerlerinin nasıl değiştiğini göstererek, optimal küme sayısını belirlemede yardımcı olabilir. Genellikle "dirsek yöntemi" olarak adlandırılan yaklaşım, grafikte dirsek şeklinde bir kırılma noktasının olduğu yerin optimal küme sayısı olabileceğini gösterir.
model = KMeans(n_clusters = 4 ,init='k-means++', n_init = 10 ,max_iter=300,
tol=0.0001, random_state= 42 , algorithm='elkan')
model.fit(X)
new_labels = model.labels_
merkezler = model.cluster_centers_n_clusters = 4: Oluşturulacak küme sayısıdır. Burada 4 küme belirlenmiştir.
init='k-means++': Başlangıç merkezlerinin 'k-means++' yöntemiyle belirlenmesini sağlar. Bu yöntem, daha iyi başlangıç merkezi konumları elde etmeye çalışır.
n_init = 10: Rastgele başlangıç merkezleri seçimi için tekrar sayısıdır. Bu durumda, 10 farklı rastgele başlangıç seçimi yapılır ve en iyi sonuçları veren başlangıçlar seçilir.
max_iter=300: Her bir tekrar için maksimum iterasyon sayısıdır. Algoritma, maksimum iterasyon sayısına ulaşana veya kümeleme konverge edene kadar çalışır.
tol=0.0001: Kümelerin değişim miktarı (tolerans) bu değerin altına düştüğünde algoritmanın sonlanmasını sağlar.
random_state= 42: Rastgele sayı üretimi için seed değeridir. Bu sayede algoritmanın tekrar çalıştırılması durumunda aynı sonuçları alabiliriz.
algorithm='elkan': Kullanılacak algoritma türüdür. 'elkan', KMeans algoritmasının hızlandırılmış bir versiyonudur.
model.fit(X): Modelin verilerle eğitilmesini sağlar. Veri seti X ile eğitilir.
new_labels = model.labels_: Her bir veri noktasının, k-means algoritması tarafından atanan etiketlerini içeren labels_ özelliği kullanılarak yeni etiketler oluşturulur.
merkezler = model.cluster_centers_: Küme merkezlerini içeren cluster_centers_ özelliği kullanılarak, her kümenin merkezi bulunur.
new_labels
Bu çıktı, her bir veri noktasının hangi kümeye atandığını gösteren etiketleri içerir. Her bir etiket, o veri noktasının hangi kümeye ait olduğunu belirtir. Örneğin, new_labels dizisinin ilk elemanı 3 ise, ilk veri noktasının 4. kümeye ait olduğunu gösterir. Bu etiketler, KMeans algoritması tarafından belirlenen kümeleri temsil eder. Etiketler, her bir veri noktasını ilgili kümelere atayarak kümeleme işlemini gerçekleştirir.