爬取看准网 TOP 90 IT/互联网公司 信息
- 爬取看准网 TOP 90 IT/互联网行业公司的排行和基本信息
- 爬取的内容: 公司名称、排名、业务范围、地点、人数规模、网址、评分、平均工资
http://www.kanzhun.com/plc52p1.html?ka=paging1 http://www.kanzhun.com/plc52p2.html?ka=paging2 ... http://www.kanzhun.com/plc52p10.html?ka=paging10
URL 的规律,注意有两个 {page} :
http://www.kanzhun.com/plc52p{page}.html?ka=paging{page}
Python 列表推导式,熟练构造 URL 列表:
urls = ['http://www.kanzhun.com/plc52p{page}.html?ka=paging{page}'.format(page=page) for page in range(1, 11)]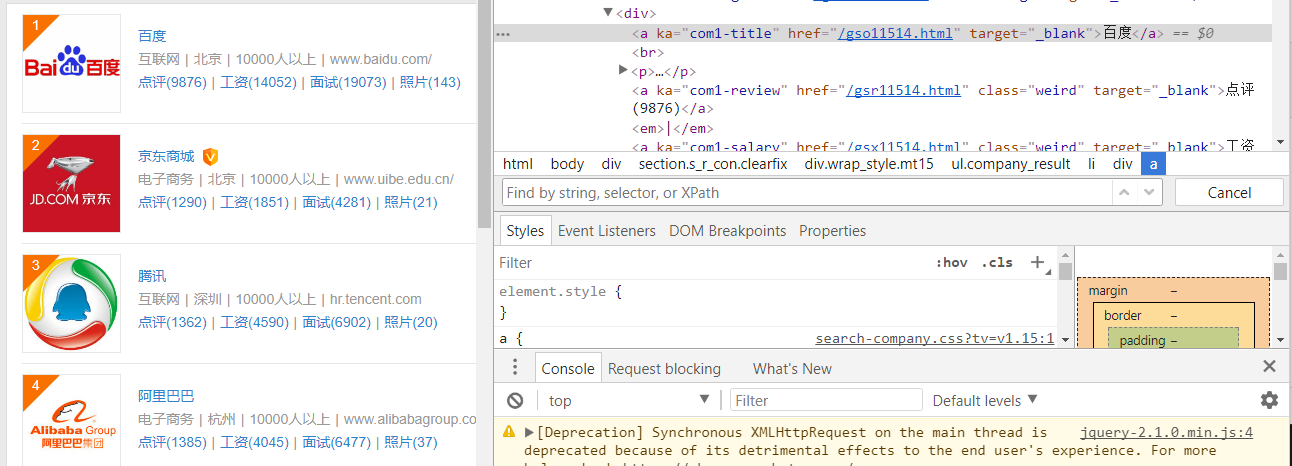
开始采用 BS 的 select 方法,但是没有抓到任何东西,可能是网页的反爬构造,有待研究。无奈用正则式加 re 模块。观察网页源代码,构造公司名称的正则式:
'<a ka="com\d+-title" href="/.*?.html" target="_blank">(.*?)</a>'然后,调用 re.findall()
companys = re.findall('<a ka="com\d+-title" href="/.*?.html" target="_blank">(.*?)</a>', res.text)其余的排名、业务范围、地点、人数规模、网址、评分、平均工资,也是同样的操作:
kinds = re.findall('<p>(.*?)<em>', res.text)
addresses = re.findall('<p>.*?<em>\|</em>(.*?)<em>\|', res.text)
people = re.findall('<p>.*?<em>\|</em>.*?<em>\|</em>(.*?)<em>\|', res.text)
websites = re.findall('<span class="urladdress">(.*?)</span>', res.text)
reviews = re.findall('<dd><span class="grade_star ps_start mr10"><i style="width:.*?;"></i></span>(.*?)</dd>', res.text)
salarys = re.findall('<dd class="grey_99">.*? .(.*?)</dd>', res.text)for company, kind, address, person, website, review, salary in zip(companys,kinds,addresses,people,websites,reviews,salarys):
count += 1
print('Top:{}'.format(count))
print('公司:'+company)
print('行业:'+kind)
print('地址:'+address)
print('人数:'+person)
print('主页:'+website)
print('评分:'+review)
print('平均月薪:'+salary)第4个页面的甲骨文公司没有网址,导致正则式抓取网址时,在该页面上从甲骨文公司开始的公司网址错位 http://www.kanzhun.com/plc52p4.html?ka=paging4 原因:for 循环中,zip() 函数匹配列表长度最短的。由于漏掉了甲骨文的网址,websites 少了1个长度,该页面的最后一个公司信息没有打印。
业务范围、地点、人数规模、网址尝试用一个正则式同时抓取,用字典结构,缺失的值用缺省值代替