This repository contains some examples of MLOps with code
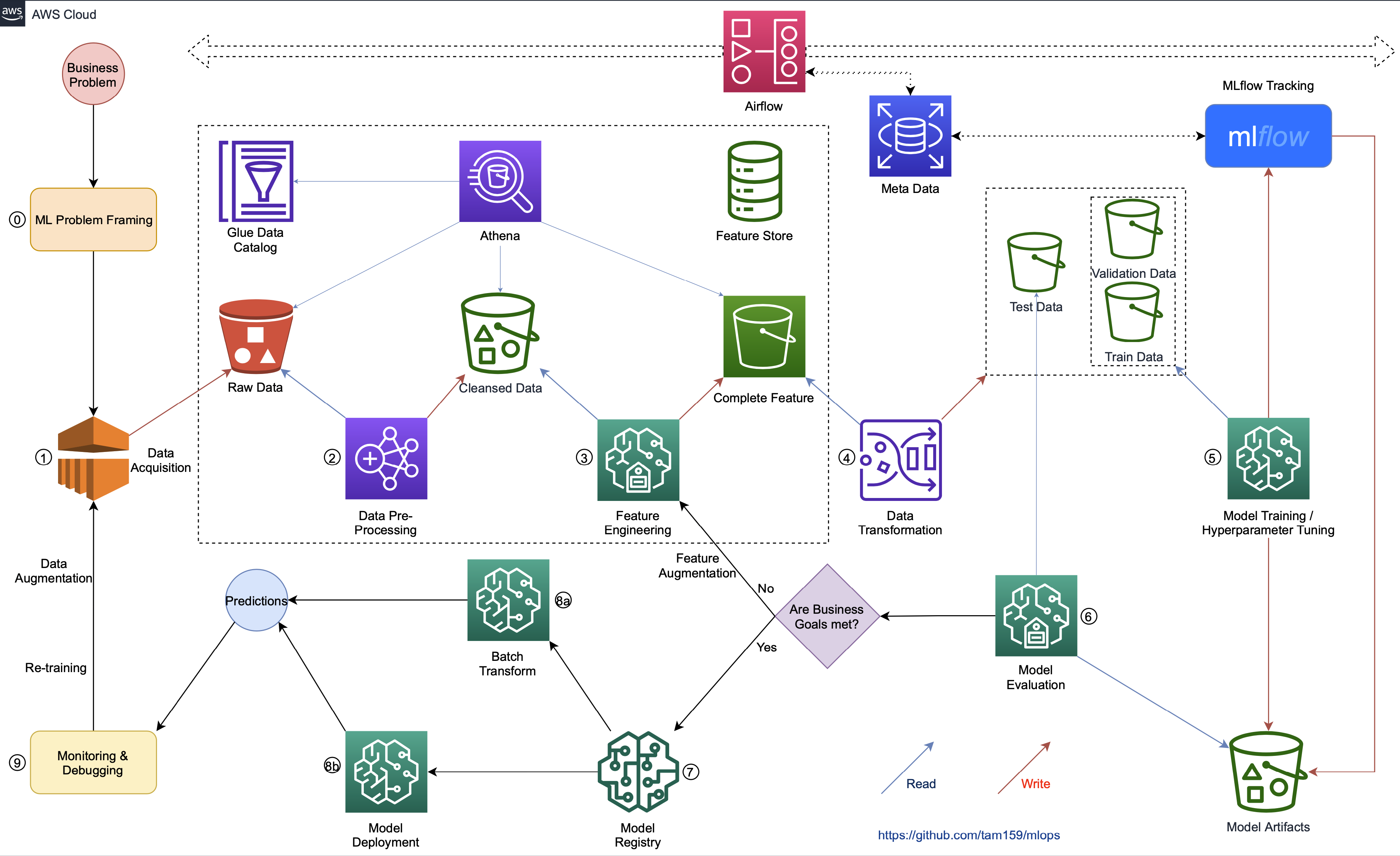
- The business problem is framed as a machine learning problem: what is observed and what is predicted.
- Data acquisition: ingesting data from sources including data collection, data integration and data quality checking.
- Data pre-processing: handling missing data, outliers, long tails, .etc.
- Feature engineering: running experiments with different features, adding, removing and changing features.
- Data transformation: standardizing data, converting data format compatible with training algorithms.
- Job training: training’s parameters, metrics, .etc are tracked in the MLflow. We can also run SageMaker Hyperparameter Optimization with many training jobs then search the metrics and params in the MLflow for a comparison with minimal effort to find the best version of a model.
- Model evaluation: analyzing model performance based on predicted results on test data.
- If business goals are met, the model will be registered in the SageMaker Inference Models. We can also register the model in the MLflow.
- Getting predictions in any of the following ways:
- Using SageMaker Batch Transform to get predictions for an entire dataset.
- Setting up a persistent endpoint to get one prediction at a time using SageMaker Inference Endpoints.
- Monitoring and debugging the workflow, re-training with a data augmentation.
- EMR: providing a Hadoop ecosystem cluster including pre-installed Spark, Flink, .etc. We should use a transient cluster to process the data and terminate it when all done.
- Glue job: providing a server-less Apache Spark, Python environments. Glue’ve supported Spark 3.1 since 2021 Aug.
- SageMaker Processing jobs: running in containers, there are many prebuilt images supporting data science. It also supports Spark 3.
For other steps, we can use AWS SageMaker for job training, hyperparameter tuning, model serving and production monitoring
- All data stored in S3 can be queried via Athena with metadata from Glue data catalog.
- We can also ingest the data into SageMaker Feature Store in batches directly to the offline store.