Note
面试指南,记录着我面经过程所遇到的问题以及总结的知识点,希望能够对大家有所帮助
📑 目录
⚡️ 算法
这是我整理的高频面试算法题,旨在帮助找工作的同学用最少的时间,刷最多套路的题。这里所挑选的算法难度都是中等,不适合算法入门者,算法涵盖了动态规划、深度/广度优先遍历、前缀和、字典树、滑动窗口、双指针、回溯等算法技巧,如果你面试的公司是字节跳动,阿里巴巴,强烈建议刷完里面的题目。
https://www.yuque.com/docs/share/4f4d37f2-3ada-42f0-876f-db7b23e479a1?# 《算法笔记》
➕ C/C++
内存模型
内存管理
下面详细讲解一下内存分配的几个区:
栈:就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数等。在一个进程中,位于用户虚拟地址空间顶部的是用户栈,编译器用它来实现函数的调用。和堆一样,用户栈在程序执行期间可以动态地扩展和收缩。
自由存储区:就是那些由 new 分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个 new 就要对应一个 delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。堆可以动态地扩展和收缩。
堆:就是那些由 malloc 等分配的内存块,他和堆是十分相似的,不过它是用 free 来结束自己的生命的。
全局/静态存储区,全局变量和静态变量被分配到同一块内存中,在以前的 C 语言中,全局变量又分为初始化的和未初始化的(初始化的全局变量和静态变量在一块区域,未初始化的全局变量与静态变量在相邻的另一块区域,同时未被初始化的对象存储区可以通过 void* 来访问和操纵,程序结束后由系统自行释放),在 C++ 里面没有这个区分了,他们共同占用同一块内存区。
常量存储区,这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改(当然,你要通过非正当手段也可以修改,而且方法很多)
堆栈的主要的区别由以下几点:
1、管理方式不同;
2、空间大小不同;
3、能否产生碎片不同;
4、生长方向不同;
5、分配方式不同;
6、分配效率不同;
管理方式:对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制,容易产生memory leak。
空间大小:一般来讲在 32 位系统下,堆内存可以达到4G的空间,从这个角度来看堆内存几乎是没有什么限制的。但是对于栈来讲,一般都是有一定的空间大小的,例如,在VC6下面,默认的栈空间大小是1M(好像是,记不清楚了)。当然,我们可以修改:打开工程,依次操作菜单如下:Project->Setting->Link,在 Category 中选中 Output,然后在 Reserve 中设定堆栈的最大值和 commit。注意:reserve 最小值为 4Byte;commit 是保留在虚拟内存的页文件里面,它设置的较大会使栈开辟较大的值,可能增加内存的开销和启动时间。
碎片问题:对于堆来讲,频繁的 new/delete 势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内存块从栈中间弹出,在他弹出之前,在他上面的后进的栈内容已经被弹出,详细的可以参考数据结构,这里我们就不再一一讨论了。
生长方向:对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。
分配方式:堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由 malloc 函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。
分配效率:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是 C/C++ 函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。
内存对齐
对于结构体变量内存对齐遵循以下三个原则:
- 变量的起始地址能够被其对齐值整除,结构体变量的对齐值为最宽的成员大小。
- 结构体每个成员相对于起始地址的偏移能够被其自身对齐值整除,如果不能则在前一个成员后面补充字节。
- 结构体总体大小能够被最宽的成员的大小整除,如不能则在后面补充字节。
此外还有编译器的默认对齐值,一般默认对齐值为4(结构体的实际对齐值会取结构体对齐值和编译器默认对齐值中较小的那一个)。
那么为什么要内存对齐?
- 为了减少使用的内存
- 为了提升数据读取的效率
深拷贝与浅拷贝
浅拷贝就是简单的数值拷贝,如果类不定义复制构造函数,默认就是浅拷贝。
深拷贝指的就是当拷贝对象中有对其他资源(如堆、文件、系统等)的引用时(引用可以是指针或引用)时,对象的另开辟一块新的资源,而不再对拷贝对象中有对其他资源的引用的指针或引用进行单纯的赋值。
/*
c++默认的拷贝构造函数是浅拷贝
浅拷贝就是对象的数据成员之间的简单赋值,如你设计了一个没有类而没有提供它的复制构造函数,
当用该类的一个对象去给令一个对象赋值时所执行的过程就是浅拷贝
*/
class A
{
public:
A(int _data) : data(_data) {}
A() {}
private:
int data;
};
/*
对于堆、文件等资源一般要进行进行深层拷贝,以堆上的指针为例子,如果是浅层拷贝,俩个对象的指针指向同一块内存
在进行析构时,内存会释放俩次,俩次delete
*/
class B
{
public:
B() { data = new int; }
B(int _data) {
data = new int;
*data = _data;
}
B(B& a) {
data = new int;
*data = *(a.data);
}
B& operator= (const B & a) {
*data = *(a.data);
}
private:
int* data;
};
int main() {
A a1(5);
A a2= a1;//浅拷贝,直接拷贝其数据
B b1(10);
B b2 = b1;//已经定义了构造函数,且是深拷贝
getchar();
return 0;
}
C++11特性
lambda表达式
存在的意义:使语法更加简洁,逻辑更加清晰,如果传入的是指针函数,那么编译器通常不会将其内联展开,但是如果是lambda表达式,编译器可能会将其内联展开,减少函数调用的开销。
每当你定义一个lambda表达式后,编译器会自动生成一个匿名类(这个类当然重载了()运算符),我们称为闭包类型lambda表达式有俩种捕获值得方式,引用捕获跟复制捕获。复制捕获相当于在匿名类里面生成一个非静态数据成员,无法直接对其进行修改,因为函数调用运算符的重载方法是const属性的,需要用mutable进行修饰,对于引用捕获方式,无论是否标记mutable,都可以在lambda表达式中修改捕获的值。至于闭包类中是否有对应成员,C++标准中给出的答案是:不清楚的,看来与具体实现有关。
int main()
{
int x = 10;
int &p = x;
auto add_x = [&x](int a) { x *= 2; return a + x; }; // 引用捕捉x
auto mutil_x = [x](int a) mutable { x *= 2; return a + x; }; // 复制捕捉x
cout << add_x(10) << endl; // 输出 30
cout << x << endl;
//从C++14开始,lambda表达式支持泛型:其参数可以使用自动推断类型的功能
auto add_two_num = [](auto a, auto b) { return a + b; };
string a= "123.153";
string b = "115.15";
cout << add_two_num(10, 12.5) << " " << add_two_num(a,b) << endl;;
getchar();
return 0;
}
move
move的作用:
- 进行语义转移,将一个对象的所有权或者说管理权转移到另一个对象上
- 减少不必要的拷贝,提升效率,临时对象的产生、拷贝会造成系统的性能的下降,可以用Move语义减少临时对象的拷贝。
move的实现:move的实现依赖于类型萃取以及引用折叠。
template<typename T>
typename std::remove_reference<T>::type&&
move(T&& t)
{
return static_cast<typename std::remove_reference<T>::type&&>(t);
}
首先我们需要了解一下左值引用以及右值引用,在c++11之前,右值引用仅局限于常引用,但是现在可以使用右值引用,且能对其值进行修改。
const string &a="123456"; //常量右值应用
string &&a="12345"; //c++11之后可以使用右值引用,且能进行修改值的大小
string&& h = "13456";
h = "afadf";
cout << h << endl; //输出结果 afadf
引用折叠,简单理解就是把 &&&看成&&就是把&&引用的引用看成是右值引用。
move其实就是利用引用折叠,将左值引用跟右值引用都引用折叠为右值引用,然后返回该右值引用。为什么是返回右值引用呢:原因就是减少临时对象的复制构造,对于POD(内置类型)而言,右值引用性能提升不大,但是对于实现了移动语义的类的而言,使用右值引用能够让其调用移动构造函数,性能能够大大提升。
#include<iostream>
#include<string>
#include<vector>
using namespace std;
class MyString {
private:
char* _data;
size_t _len;
void _init_data(const char *s) {
_data = new char[_len + 1];
memcpy(_data, s, _len);
_data[_len] = '\0';
}
public:
MyString() {
_data = NULL;
_len = 0;
std::cout << "consurt data" << this << endl;
}
MyString(const char* p) {
_len = strlen(p);
_init_data(p);
std::cout << "consurt data" << this << endl;
}
MyString(const MyString& str) {
_len = str._len;
_init_data(str._data);
std::cout << "Copy Constructor is called! source: " << str._data << std::endl;
}
MyString( MyString&& str) {
_len = str._len;
_init_data(str._data);
str._len = 0;
str._data = NULL;
//str.~MyString();
std::cout << "Move Constructor is called! source: " << _data<<" "<< std::endl;
}
MyString& operator=(const MyString& str) {
if (this != &str) {
_len = str._len;
_init_data(str._data);
}
std::cout << "Copy Assignment is called! source: " << str._data << std::endl;
return *this;
}
virtual ~MyString() {
if (_data) free(_data);
std::cout << "free data " << this << endl;
}
};
void showString(string&& s) {
std::cout << s << endl;
}
int main() {
MyString a;
a = MyString("Hello");
std::vector<MyString> vec;
vec.push_back(MyString("World"));
vec.push_back(a);
getchar();
return 0;
}
关键字
NULL与nullptr的区别
NULL:一个宏定义,无类型,NULL被定义为0,编译器总是优先把0视为一个整型常量造成的。0在C++98中是有二义性的,编译器首先解释它是一个整型常量,其次是一个无类型指针(void*)
nullptr有类型:typedef decltype(nullptr) nullptr_t;
NULL的缺点:
- 函数重载会出现问题,会优先选择参数为整形变量的函数
- 异常抛出难以解决,不知道捕获什么类型,都是整型常量0
NULL其实是一个宏定义,字面常量为0,即上述两种方式本质上是一样的。于是,这样就有了一些麻烦,比如函数重载时
#include<iostream>
using namespace std;
void f(char* c)
{
cout << "invoke f(char* c)" << endl;
}
void f(int i)
{
cout << "invoke f(int)" << endl;
}
int main()
{
f(0);
f(NULL);
f((char*)0);
f(nullptr);
return EXIT_SUCCESS;
}
原文链接:https://blog.csdn.net/u012333003/java/article/details/25226749
可见,f(NULL)并没有调用想要的指针版本,而是调用了f(int)版本,这是因为NULL被定义为0,编译器总是优先把0视为一个整型常量造成的。0在C++98中是有二义性的,编译器首先解释它是一个整型常量,其次是一个无类型指针(void*)。
C++11中,首先为了兼容性考虑并没消除0的二义性,但给出了一种新的方案,使用指针空值nullptr去初始化指针。指针空值的类型被命名为nullptr_t。它是这么来的:
typedef decltype(nullptr) nullptr_t; 充分利用了decltype 。即nullptr也是有类型的。且仅可以被隐式转化为指针类型。于是f(nullptr)会调用f(char*)版本。这样用户也就能表达自己的意图了。
上面我们已经知道nullptr的类型为nullptr_t,我们再看看这种类型有什么特点
1.nullptr_t是一种内置数据内型
2.nullptr_t类型 数据可以隐式转换为任意一种指针类型,但无论你想什么方式都不能转换为非指针类型。
3.nullptr_t类型数据不可用于算术运算
4.nullptr_t类型数据可以用于同类型数据之间进行关系运算。
nullptr是一个编译时期的常量,能为编译器识别。而(void*)0只是一个强制转换表达式,返回一个void* 指针类型的数据而已。而且nullptr到任何指针的转换都是隐式的。而且我们不要对nullptr进行去地址操作,因为它是一个右值常量,取nullptr的地址通常也没有意义。
原文链接:https://blog.csdn.net/u012333003/java/article/details/25226749
new与malloc的区别
| 特征 | new/delete | malloc/free |
|---|---|---|
| 分配内存的位置 | 自由存储区 | 堆 |
| 内存分配成功的返回值 | 完整类型指针 | void* |
| 内存分配失败的返回值 | 默认抛出异常 | 返回NULL |
| 分配内存的大小 | 由编译器根据类型计算得出 | 必须显式指定字节数 |
| 处理数组 | 有处理数组的new版本new[] | 需要用户计算数组的大小后进行内存分配 |
| 已分配内存的扩充 | 无法直观地处理 | 使用realloc简单完成 |
| 是否相互调用 | 可以,看具体的operator new/delete实现 | 不可调用new |
| 分配内存时内存不足 | 客户能够指定处理函数或重新制定分配器 | 无法通过用户代码进行处理 |
| 函数重载 | 允许 | 不允许 |
| 构造函数与析构函数 | 调用 | 不调用 |
1. 申请的内存所在位置
new操作符从自由存储区(free store)上为对象动态分配内存空间,而malloc函数从堆上动态分配内存。自由存储区是C++基于new操作符的一个抽象概念,凡是通过new操作符进行内存申请,该内存即为自由存储区。那么自由存储区是否能够是堆(问题等价于new是否能在堆上动态分配内存),这取决于operator new 的实现细节。自由存储区不仅可以是堆,还可以是静态存储区,这都看operator new在哪里为对象分配内存。
特别的,new甚至可以不为对象分配内存!定位new的功能可以办到这一点:
new (place_address) type
place_address为一个指针,代表一块内存的地址。当使用上面这种仅以一个地址调用new操作符时,new操作符调用特殊的operator new,也就是下面这个版本:
void * operator new (size_t,void *) //不允许重定义这个版本的operator new
这个operator new不分配任何的内存,它只是简单地返回指针实参,然后右new表达式负责在place_address指定的地址进行对象的初始化工作。
2.返回类型安全性
new操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,无须进行类型转换,故new是符合类型安全性的操作符。而malloc内存分配成功则是返回void * ,需要通过强制类型转换将void*指针转换成我们需要的类型。 类型安全很大程度上可以等价于内存安全,类型安全的代码不会试图方法自己没被授权的内存区域。关于C++的类型安全性可说的又有很多了。
3.内存分配失败时的返回值
new内存分配失败时,会抛出bac_alloc异常,它不会返回NULL;malloc分配内存失败时返回NULL。 在使用C语言时,我们习惯在malloc分配内存后判断分配是否成功:
4.是否需要指定内存大小
使用new操作符申请内存分配时无须指定内存块的大小,编译器会根据类型信息自行计算,而malloc则需要显式地指出所需内存的尺寸。
5.是否调用构造函数/析构函数
使用new操作符来分配对象内存时会经历三个步骤:
- 第一步:调用operator new 函数(对于数组是operator new[])分配一块足够大的,原始的,未命名的内存空间以便存储特定类型的对象。
- 第二步:编译器运行相应的构造函数以构造对象,并为其传入初值。
- 第三部:对象构造完成后,返回一个指向该对象的指针。
使用delete操作符来释放对象内存时会经历两个步骤:
- 第一步:调用对象的析构函数。
- 第二步:编译器调用operator delete(或operator delete[])函数释放内存空间。
6.对数组的处理
C++提供了new[]与delete[]来专门处理数组类型:
A * ptr = new A[10];//分配10个A对象
使用new[]分配的内存必须使用delete[]进行释放:
delete [] ptr;
new对数组的支持体现在它会分别调用构造函数函数初始化每一个数组元素,释放对象时为每个对象调用析构函数。注意delete[]要与new[]配套使用,不然会找出数组对象部分释放的现象,造成内存泄漏。
至于malloc,它并知道你在这块内存上要放的数组还是啥别的东西,反正它就给你一块原始的内存,在给你个内存的地址就完事。所以如果要动态分配一个数组的内存,还需要我们手动自定数组的大小:
int * ptr = (int *) malloc( sizeof(int)* 10 );//分配一个10个int元素的数组
7.new与malloc是否可以相互调用
operator new /operator delete的实现可以基于malloc,而malloc的实现不可以去调用new。下面是编写operator new /operator delete 的一种简单方式,其他版本也与之类似:
void * operator new (sieze_t size)
{
if(void * mem = malloc(size)
return mem;
else
throw bad_alloc();
}
void operator delete(void *mem) noexcept
{
free(mem);
}
8.是否可以被重载
opeartor new /operator delete可以被重载。标准库是定义了operator new函数和operator delete函数的8个重载版本:
9.能够直观地重新分配内存
使用malloc分配的内存后,如果在使用过程中发现内存不足,可以使用realloc函数进行内存重新分配实现内存的扩充。realloc先判断当前的指针所指内存是否有足够的连续空间,如果有,原地扩大可分配的内存地址,并且返回原来的地址指针;如果空间不够,先按照新指定的大小分配空间,将原有数据从头到尾拷贝到新分配的内存区域,而后释放原来的内存区域。
new没有这样直观的配套设施来扩充内存。
10. 客户处理内存分配不足
在operator new抛出异常以反映一个未获得满足的需求之前,它会先调用一个用户指定的错误处理函数,这就是new-handler。new_handler是一个指针类型
面向对象
- 面向对象:封装是基础,继承是手段,多态是目的。
- 泛型编程:参数化类型是基础,模板是手段,通用是目的。
- 面向对象的编程依赖运行时多态,泛型编程是编译时多态。
Const关键字
用于修饰常量性,即不可修改,可修饰变量、引用、指针、函数、类
const可以用在对象需要保护的场所,有以下好处:
- 避免被间接修改
- 避免被误用为左值,例如函数返回值
string getString(string b)
return b;
//误用右值
if(getString(b)="afff")
//可以用const避免这种情况
const string getString(string b)
return b;
//会报错
if(getString(b)="asff")
Static关键字
3个作用:
-
延长生命周期:当其修饰变量时,可以让变量存在的生命周期与程序同样 长
-
限制函数范围:修饰函数时,可以限制其作用域仅在本文件
-
共享内存或者方法:当方法被static修饰时,类中所有对象都可以访问该变量或者方法
不可以同时用const和static修饰成员函数。
C++编译器在实现const的成员函数的时候为了确保该函数不能修改类的实例的状态,会在函数中添加一个隐式的参数const this*。但当一个成员为static的时候,该函数是没有this指针的。也就是说此时const的用法和static是冲突的。
我们也可以这样理解:两者的语意是矛盾的。static的作用是表示该函数只作用在类型的静态变量上,与类的实例没有关系;而const的作用是确保函数不能修改类的实例的状态,与类型的静态变量没有关系。因此不能同时用它们。
inline
将函数体直接展开,省去函数调用的开销,inline只是建议,具体是否展开取决于编译器
编译器对inline函数展开的步骤:
- 将inline函数体移动到inline函数调用处
- 为Inline函数局部变量分配空间
- 将inline函数的输入参数跟返回值映射到调用方法的局部变量空间
- 如果 inline 函数有多个返回点,将其转变为 inline 函数代码块末尾的分支(使用 GOTO)
inline有2个好处跟3个缺点
- 好处
- 省去函数调用的开销
- 编译器会对inline函数进行优化
- 坏处
- 过分使用inline会造成代码膨胀,降低指令缓冲器的击中率,造成系统性能下降
- inline修改时,包含其头文件的都需要重新编译,无法降低编译依存性
- inline函数无法使用断点调式
值得注意的是:程序员可以隐式或者显式生明inline函数,但是具体执行与否取决于编译器,inline函数一般不能修饰虚构函数,因为虚构函数会在运行时多态联编,而inline是编译期间展开,只有在虚函数不表现多态性时才可以用inline
volatile
- volatile 关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素(操作系统、硬件、其它线程等)更改。所以使用 volatile 告诉编译器不应对这样的对象进行优化。
- volatile 关键字声明的变量,每次访问时都必须从内存中取出值(没有被 volatile 修饰的变量,可能由于编译器的优化,从 CPU 寄存器中取值)
- const 可以是 volatile (如只读的状态寄存器)
- 指针可以是 volatile
strcu 与class
struct与class几乎一样,在描述数据结构上几乎可相互代替,但是其还是存在一点区别,就是默认的成员访问限制
- struct默认的成员访问限制是private,class是public
union 联合
联合(union)是一种节省空间的特殊的类,一个 union 可以有多个数据成员,但是在任意时刻只有一个数据成员可以有值。当某个成员被赋值后其他成员变为未定义状态。联合有如下特点:
- 默认访问控制符为 public
- 可以含有构造函数、析构函数
- 不能含有引用类型的成员
- 不能继承自其他类,不能作为基类
- 不能含有虚函数
- 匿名 union 在定义所在作用域可直接访问 union 成员
- 匿名 union 不能包含 protected 成员或 private 成员
- 全局匿名联合必须是静态(static)的
匿名联合的作用:
1.共享内存
2.自动类型转换
/*匿名联合的另一个用途是:自动类型转换(自动类型转换是不安全的)。例如:当要把一个指针看作十进制数时,你可以如下面的联合一样声明。*/
int some_val;
union
{
void *p;
int n;
};
p = &some_val;
//现在没有必要把指针显式的转为int类型的:
std::cout << ”address of p is:” << n << std::endl;
:: 范围解析运算符
分类
- 全局作用域符(
::name):用于类型名称(类、类成员、成员函数、变量等)前,表示作用域为全局命名空间 - 类作用域符(
class::name):用于表示指定类型的作用域范围是具体某个类的 - 命名空间作用域符(
namespace::name):用于表示指定类型的作用域范围是具体某个命名空间的
多态
- 多态,即多种状态(形态)。简单来说,我们可以将多态定义为消息以多种形式显示的能力。
- 多态是以封装和继承为基础的。
- C++ 多态分类及实现:
- 重载多态(Ad-hoc Polymorphism,编译期):函数重载、运算符重载
- 子类型多态(Subtype Polymorphism,运行期):虚函数
- 参数多态性(Parametric Polymorphism,编译期):类模板、函数模板
- 强制多态(Coercion Polymorphism,编译期/运行期):基本类型转换、自定义类型转换
Python
关键字参数
关键字声明
python的函数值传递可以通过关键字声明,也可以通过参数对齐的方式来进行传递
def f(pos1, pos2, /, pos_or_kwd, *, kwd1, kwd2):
----------- ---------- ----------
| | |
| Positional or keyword |
| - Keyword only
-- Positional only
def f(pos1, pos2, /, pos_or_kwd, *, kwd1, kwd2):
print(pos1,pos2,pos_or_kwd,kwd1,kwd2)
#pos1、pos2参数只能通过参数对齐的方式来传递,而kwd1, kwd2只能通过关键字来传递形参
#可以用以下方式进行调用
f(1,2,3,kwd1="fasf",kwd2="df")
解包参数列表
解包的操作与c++解引用类似,可以理解为把列表变成一个个单独的元素
list(range(3, 6)) # normal call with separate arguments
args = [3, 6]
list(range(*args)) # call with arguments unpacked from a list
#同样的方式,字典可使用 ** 操作符 来提供关键字参数:
lambda表达式
与c++ java的lambda的用法差不多,其更多实现的细节没去深究
参数传递
这里需要注意浅拷贝跟深拷贝的区别,以及python对象类型的区别
浅拷贝可以看作是对引用的拷贝,例如 A对象拷贝B对象,当A指向的内容做出修改时,B也随着更改,这就是浅拷贝,拷贝数据的引用,而非数据本身
深拷贝则是会拷贝该对象所指向的数据
浅拷贝操作
使用切片[:]操作
使用工厂函数(如list/dir/set)
使用copy模块中的copy()函数
深拷贝操作
使用copy.deepcopy()进行深拷贝
这里还需要了解一个概念就是python的对象类型,int,str,原子类型,{list,set,dict}(容器类型)
对于非容器类型没有拷贝的说法,pyhton的数字、字符串都是用的同一对象,原子类型的对象也是没办法拷贝
所以参数的值传递对于容易类型是浅拷贝
数据结构
list是一个强大的数据结构,支持像C++一样deququ的操作,可以双向进行添加与删除,也可以再任意处插入或者删除
python的线性数据结构只有list,没有提供stack,queue,但是我们却可以用list去模拟queue跟stack
del 语言可以用来删除元素,只通过下标就可以删除该元素
set 集合对象也支持像 联合,交集,差集,对称差分等数学运算
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a # unique letters in a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # letters in a but not in b
{'r', 'd', 'b'}
>>> a | b # letters in a or b or both
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # letters in both a and b
{'a', 'c'}
>>> a ^ b # letters in a or b but not both
{'r', 'd', 'b', 'm', 'z', 'l'}
循环的技巧
通过zip函数可以实现将不同容器的元素组成一个元组
>>> questions = ['name', 'quest', 'favorite color']
>>> answers = ['lancelot', 'the holy grail', 'blue']
>>> for q, a in zip(questions, answers):
... print('What is your {0}? It is {1}.'.format(q, a))
...
What is your name? It is lancelot.
What is your quest? It is the holy grail.
What is your favorite color? It is blue.
zip函数的具体实现如下:
def zip(*iterables):
# zip('ABCD', 'xy') --> Ax By
sentinel = object()
#将参数列表中容器的迭代器加入到列表中
iterators = [iter(it) for it in iterables]
while iterators:
result = []
#将不同容器的元素,同一迭代位置的元素加入到tuple中
for it in iterators:
elem = next(it, sentinel)
if elem is sentinel:
return
result.append(elem)
#通过yeild生成器来产生可迭代元素
yield tuple(result)
内置库
os
sys.addaudithook(hook)
将可调用的 hook 附加到当前解释器的活动的审核钩子列表中。
通过 sys.audit() 函数引发审计事件时,将按照加入钩子的先后顺序调用每个钩子,调用时将带有事件名称和参数元组。首先调用由 PySys_AddAuditHook() 添加的静态钩子,然后调用添加到当前解释器中的钩子。
引发一个 审计事件 sys.addaudithook,没有附带参数。
这里需要理解一下什么是钩子,可以理解为是一种函数监听回调机制
sys._current_frames()
返回一个字典,存放着每个线程的标识符与(调用本函数时)该线程栈顶的帧(当前活动的帧)之间的映射。注意 traceback 模块中的函数可以在给定某一帧的情况下构建调用堆栈。
这对于调试死锁最有用:本函数不需要死锁线程的配合,并且只要这些线程的调用栈保持死锁,它们就是冻结的。在调用本代码来检查栈顶的帧的那一刻,非死锁线程返回的帧可能与该线程当前活动的帧没有任何关系。
这个函数应该只在内部为了一些特定的目的使用。
引发一个 审计事件 sys._current_frames,没有附带参数。
base64
存在一个疑问,就是为什么需要用到base64编码,有什么业务场景?
引用知乎的回答:我们知道在计算机中的字节共有256个组合,对应就是ascii码,而ascii码的128~255之间的值是不可见字符。而在网络上交换数据时,比如说从A地传到B地,往往要经过多个路由设备,由于不同的设备对字符的处理方式有一些不同,这样那些不可见字符就有可能被处理错误,这是不利于传输的。所以就先把数据先做一个Base64编码,统统变成可见字符,这样出错的可能性就大降低了。 对证书来说,特别是根证书,一般都是作Base64编码的,因为它要在网上被许多人下载。电子邮件的附件一般也作Base64编码的,因为一个附件数据往往是有不可见字符的。
作者:wuxinliulei
链接:https://www.zhihu.com/question/36306744/answer/71626823
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
json
需要了解俩个比较重要的函数,json.dump()将dict对象转为json对象,json.load()则是将json对象转化为dict,是dump()的逆过程
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
# Dictionary mapping names to known classes
classes = {
'Point' : Point
}
#将json对象转为Point对象
def unserialize_object(d):
clsname = d.pop('__classname__', None)
if clsname:
cls = classes[clsname]
obj = cls.__new__(cls) # Make instance without calling __init__
for key, value in d.items():
setattr(obj, key, value)
return obj
else:
return d
#用法如下:
p = Point(2,3)
s = json.dumps(p, default=serialize_instance)
#a is a Point object
a = json.loads(s, object_hook=unserialize_object)
值得一提的是,python除了json序列化还有pickle可以进行对象的序列化,pickle序列化后的对象对于非python可能是无效的
JSON 是一个文本序列化格式(它输出 unicode 文本,尽管在大多数时候它会接着以 utf-8 编码),而 pickle 是一个二进制序列化格式;
JSON 是我们可以直观阅读的,而 pickle 不是;
JSON是可互操作的,在Python系统之外广泛使用,而pickle则是Python专用的;
默认情况下,JSON 只能表示 Python 内置类型的子集,不能表示自定义的类;但 pickle 可以表示大量的 Python 数据类型(可以合理使用 Python 的对象内省功能自动地表示大多数类型,复杂情况可以通过实现 specific object APIs 来解决)。
不像pickle,对一个不信任的JSON进行反序列化的操作本身不会造成任意代码执行漏洞。
datetime
其内部类的继承关系如下所示:
object
timedelta
tzinfo
timezone
time
date
datetime
timedelta 对象表示两个 date 或者 time 的时间间隔,俩个timedelta对象可以进行算术运算
date对象用来表示日期
datetime对象功能比较强大,包含前俩个类的信息
面向切面编程AOP
就是代码只要考虑主要的逻辑,将一些通用的功能性任务交付给其他类去完成,把和主业务无关的事情,放到代码外面去做。,例如验证一个用户是否有权限访问这一功能就可以交由一个代理类去完成。
AOP可以用一个代理类来实现,可以是动态代理(运行时代理)也可以是静态代理(自己写的类)
AOP的好处:对原有代码毫无入侵性,将一些功能通用,代码重复的函数进行复用,减少代码的重复
Python中的重载
函数重载主要是为了解决两个问题。
- 可变参数类型。
- 可变参数个数。
对于情况1,python可以接受任何类型的参数,所以无需重载,对于情况2,python可以用缺省参数接受多个 参数,因此python不需要函数重载
新式类与旧式类
python3的类都是新式类,新式类继承object类,其内置了许多常见的基本魔术方法,不单是这个不同,其多重继承的机制也不同,新式类继承是根据C3算法,旧式类是深度优先
#新式类
class C(object):
pass
#经典类
class B:
pass
#在python2运行旧式类
class A():
def foo1(self):
print "A"
class B(A):
def foo2(self):
pass
class C(A):
def foo1(self):
print "C"
class D(B, C):
pass
d = D()
d.foo1()
#结果是输出'A'
"""
按照经典类的查找顺序从左到右深度优先的规则,在访问d.foo1()的时候,D这个类是没有的..那么往上查找,先找到B,里面没有,深度优先,访问A,找到了foo1(),所以这时候调用的是A的foo1(),从而导致C重写的foo1()被绕过
"""
为什么采用C3算法
C3算法最早被提出是用于Lisp的,应用在Python中是为了解决原来基于深度优先搜索算法不满足本地优先级,和单调性的问题。 本地优先级:指声明时父类的顺序,比如C(A,B),如果访问C类对象属性时,应该根据声明顺序,优先查找A类,然后再查找B类。
class A(O):pass
class B(O):pass
class C(O):pass
class E(A,B):pass
class F(B,C):pass
class G(E,F):pass
mro(F) = [F] + merge(mro(B), mro(C), [B,C])
= [F] + merge([B,O], [C,O], [B,C])
= [F,B] + merge([O], [C,O], [C])
= [F,B,C] + merge([O], [O])
= [F,B,C,O]
mro(G) = [G] + merge(mro[E], mro[F], [E,F])
= [G] + merge([E,A,B,O], [F,B,C,O], [E,F])
= [G,E] + merge([A,B,O], [F,B,C,O], [F])
= [G,E,A] + merge([B,O], [F,B,C,O], [F])
= [G,E,A,F] + merge([B,O], [B,C,O])
= [G,E,A,F,B] + merge([O], [C,O])
= [G,E,A,F,B,C] + merge([O], [O])
= [G,E,A,F,B,C,O]
init与new的区别
"""
真正创建对象的是__new__方法,__init__只是完成初始化工作
"""
class Person(object):
def __new__(cls, *args, **kwargs):
print("in __new__")
instance = object.__new__(cls, *args, **kwargs)
return instance
def __init__(self, name, age):
print("in __init__")
self._name = name
self._age = age
p = Person("Wang", 33)
"""
用__new__实现singleton模式
"""
class singleton(object):
def __new__(cls,*args, **kwargs):
if not hasattr(cls, '_instance'):
orig = super(Singleton, cls)
cls._instance = orig.__new__(cls, *args, **kw)
return cls._instance
Pyhton2 和Python3的差异
- print函数
- 整除 python2: 3/2=1,3/2.0=1.5
- Unicode
- xrange range不同
is与==
is比较的是地址,==比较的值
GIL线程全局锁
线程全局锁(Global Interpreter Lock),即Python为了保证线程安全而采取的独立线程运行的限制,说白了就是一个核只能在同一时间运行一个线程.对于io密集型任务,python的多线程起到作用,但对于cpu密集型任务,python的多线程几乎占不到任何优势,还有可能因为争夺资源而变慢。
Python垃圾回收机制
python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略
Python GC主要使用引用计数(reference counting)来跟踪和回收垃圾。在引用计数的基础上,通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用问题,通过“分代回收”(generation collection)以空间换时间的方法提高垃圾回收效率。
检查内存泄露的工具:valgrind
algrind [valgrind-options] [your-program] [your-program-options]
valgrind的底层模拟了一个核心,即一个软件模拟的CPU,被调试的程序就是运行在这个假核心上,此外还包含一系列调试工具。它的工具运行依赖于底层的核心,由于是模块化架构,工具可单独开发,只要与核心的版本匹配即可。它的默认工具是memcheck,通过--tool=来指定运行的工具。
valgrind指令
valgrind --tool=memcheck --leak-check=full ./test
-h –help 显示帮助信息。(除了以下参数,可用帮助-h查看更多信息)
--version 显示valgrind内核的版本,每个工具都有各自的版本。
-q –quiet 安静地运行,只打印错误信息。
-v –verbose 更详细的信息, 增加错误数统计。
--trace-children=no|yes 跟踪子线程? [no]
--track-fds=no|yes 跟踪打开的文件描述?[no]
--time-stamp=no|yes 增加时间戳到LOG信息? [no]
--log-fd= 输出LOG到描述符文件 [2=stderr]
--log-file= 将输出的信息写入到filename.PID的文件里,PID是运行程序的进行ID
--log-file-exactly= 输出LOG信息到 file
--log-file-qualifier= 取得环境变量的值来做为输出信息的文件名。 [none]
--log-socket=ipaddr:port 输出LOG到socket ,ipaddr:port
--xml=yes 将信息以xml格式输出,只有memcheck可用
--num-callers= show callers in stack traces [12]
--error-limit=no|yes 如果太多错误,则停止显示新错误? [yes]
--error-exitcode= 如果发现错误则返回错误代码 [0=disable]
--db-attach=no|yes 当出现错误,valgrind会自动启动调试器gdb。[no]
--db-command= 启动调试器的命令行选项[gdb -nw %f %p]
适用于Memcheck工具的相关选项
--leak-check=no|summary|full 要求对leak给出详细信息? [summary]
--leak-resolution=low|med|high how much bt merging in leak check [low]
--show-reachable=no|yes show reachable blocks in leak check? [no]
==3185== Use of uninitialised value of size 8
==3185== at 0x108602: main (a.c:6)
这种情况是很常见的, 原因是使用了未初始化的的地址, 这时候应该查看一下程序是否使用了未初始化的指针
==3223== Invalid write of size 4
==3223== at 0x108602: main (a.c:6)8
==3223== Address 0x0 is not stack’d, malloc’d or (recently) free’d
这个错误原因是往错误的地址写入值, 这时候我们也应该查看一下程序用未初始化的指针赋值, 或者指针未被赋值. 和这个错误相对应的, 还有Invalid read of size 4错误提示.
==3397== Conditional jump or move depends on uninitialised value(s)
==3397== at 0x108656: main (in /home/ciaiy/Desktop/codingSpace/c/free/a)
这个错误原因是变量未被初始化, 就被使用
==3886== Invalid free() / delete / delete[] / realloc()
==3886== at 0x4C2CE1B: free (vg_replace_malloc.c:530)
==3886== by 0x1086CD: main (a.c:10)
这个错误原因是free掉了不属于自己的空间, 错误原因有可能是指针指向的内存不再属于它了
==3839== HEAP SUMMARY:
==3839== in use at exit: 412 bytes in 1 blocks
==3839== total heap usage: 2 allocs, 1 frees, 924 bytes allocated
最后一个是堆内存分析, 如上面的提示所示, 程序在退出时, 仍有412字节的空间未被free
更多valgrind错误分析可看博客https://blog.csdn.net/ciaiy/article/details/81276155
☁️ 计算机网络
TCP
建立连接
TCP建立连接是三次握手,以客户端主动建立连接例
(1). 第一次握手(SYN=1,Ack(标志位)=0,ACK(确认号)=0, seq=x)
client发送SYN数据段,进入SYN_SEND状态

(2).第二次握手(SYN=K,Ack(标志位)=1,ACK(确认号)=j+1,seq=y)
服务器必须确认客户A的SYN(ACK=j+1),同时自己也发送一个SYN包(SYN=k),即SYN+ACK包,服务器端选择自己 ISN 序列号,放到 Seq 域里此时服务器B进入SYN_RECV状态

(3). 第三次握手(ACK=K+1)
客户端再次发送确认包(ACK)SYN标志位为0,ACK标志位为1.并且把服务器发来ACK的序号字段+1,放在确定字段中发送给对方.并且在数据段放写ISN的+1,发送最后一次ACK,客户端进入ESTABLISHED状态, 服务器接受到ACK进入ESTABLISHED状态

TCP断开连接采用的是四次握手,以客户端主动断开连接为例子
(1). 客户端发送FIN,进入FIN_WAIT1状态
(2). 服务器接受FIN,关闭读通道进入CLOSED_WAIT状态,然后发送ACK确认接受FIN
(3). 客户端接受到ACK开始关闭写通道,进入FIN_WAIT2状态,然后服务器发送FIN字段,进入LAST状态
(4). 客户端接受FIN字段,关闭读通道,进入TIME_WAIT状态,发送ACK字段,服务器接受ACK字段关闭写通道,进入CLOASED状态
如果服务器是端口不可达,也就是可以访问到该主机,但是端口没有listen,此时返回RST复位报文段,如果主机不可达,也就是该由于器不存在该端口的缓存,或在是某一条链路断开,此时返回ICMP主机不可达报文端。
- connect出错:
(1) 若TCP客户端没有收到syn分节的响应,则返回ETIMEOUT错误;调用connect函数时,内核发送一个syn,若无响应则等待2s后再发送一个,若仍然无响应则等待4s后在发送一个,连续发送7次,1 2 4 6 8 16 32 64,若仍未收到响应则,交给底层IP ARP协议去完成,返回本错误;
(2) 若对客户的syn响应是rst,则表明该服务器在我们指定的端口上没有进程在等待与之连接,这是一种硬错误,客户一收到rst马上返回ECONNREFUSED错误;
(3) 若客户发送的syn在中间的某个路由器上引发了目的不可达icmp错误,则认为是一种软错误。客户主机内核保存该消息,并按照第一种情况的时间间隔继续发送syn,咋某个规定时间后仍未收到响应,则把保存的消息作为EHOSTUNREACH或者ENETUNREACH错误返回给进程,在我测试的环境下当收到2个ICMP不可达报文时,通常就会确认为无法连接进行断开;
发送数据
丢包问题
TCP是基于不可靠的网络实现可靠的传输,肯定也会存在掉包的情况,如果通信中发现缺少数据或者丢包,那么,最大的可能在于程序发送的过程或者接收的过程出现问题。
例如服务端要给客户端发送大量数据,Send频率很高,那么就很有可能在Send环节出现错误(1.程序处理逻辑错误,2.多线程同步问题,3.缓冲区溢出等),如果没有对Send发送失败做处理,那么客户端收到的数据比理论要收到的数据少,就会造成丢数据,丢包现象。
常用的解决方法有:拆包,加包头,发送组合包
粘包问题的解决策略
由于底层的TCP无法理解上层的业务逻辑,所以在底层是无法确保数据包不被拆分和重组的,这个问题只能通过上层的应用协议栈设计来解决,根据业界的主流协议的解决方案,归纳如下:
1.消息定长,例如每个报文的大小为固定长度200字节,如果不够,空位补空格;
2.在包尾增加回车换行符进行分割,例如FTP协议;
3.将消息分为消息头和消息体,消息头中包含表示消息总长度(或者消息体长度)的字段,通常设计思路是消息头的第一个字段用int来表示消息的总长度;(我之前linux C开发,就用的这种)。
4.更复杂的应用层协议;
原文链接:https://blog.csdn.net/q764424567/article/details/78034622
TCP可靠传输的设计
- 超时重传:tcp设计了超时记时器,如果数据没有收到期待的响应则会重复数据包
- 接受确认:tcp采用累加确认的方法,每个数据包都有一个序号x,接受方要发送x+1的序号或在是当发送多个数据时y时,返回x+y+1的确认
- 滑动窗口协议:用来告知对方的接受窗口容量,用于控制流量
- 数据分片:发送端对数据进行分片,接受端要对数据进行重组,由TCP确定分片的大小并控制分片和重组
- 失序处理:作为IP数据报来传输的TCP分片到达时可能会失序,TCP将对收到的数据进行重新排序,将收到的数据以正确的顺序交给应用层
- 数据校验:TCP将保持它首部和数据的检验和,这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到分片的检验或有差错,TCP将丢弃这个分片,并不确认收到此报文段导致对端超时并重发
TCP数据校验
伪首部共有12字节,包含IP首部的一些字段,有如下信息:32位源IP地址、32位目的IP地址、8位保留字节(置0)、8位传输层协议号(TCP是6,UDP是17)、16位TCP报文长度(TCP首部+数据)。
伪首部是为了增加TCP校验和的检错能力:通过伪首部的目的IP地址来检查TCP报文是否收错了、通过伪首部的传输层协议号来检查传输层协议是否选对了。
检验和计算过程
TCP首部校验和计算三部分:TCP首部+TCP数据+TCP伪首部。
发送端:
首先,把伪首部、TCP报头、TCP数据分为16位的字,如果总长度为奇数个字节,则在最后增添一个位都为0的字节。
把TCP报头中的校验和字段置为0。
其次,用反码相加法(对每16bit进行二进制反码求和)累加所有的16位字(进位也要累加,进位则将高位叠加到低位
最后,将上述结果作为TCP的校验和,存在检验和字段中。
接收端:
将所有原码相加,高位叠加到低位, 如计算结果的16位中每一位都为1,则正确,否则说明发生错误。
验证示例: 校验和 反码求和过程 以4bit 为例
验证示例: 校验和 反码求和过程 以4bit 为例 发送端计算: 数据: 1000 0100 校验和 0000 则反码:0111 1011 1111 叠加: 0111+1011+1111 = 0010 0001 高于4bit的, 叠加到低4位 0001 + 0010 = 0011 即为校验和
接收端计算:
数据: 1000 0100 检验和 0011
反码: 0111 1011 1100
发送端计算:
数据: 1000 0100 校验和 0000
则反码:0111 1011 1111
叠加: 0111+1011+1111 = 0010 0001 高于4bit的, 叠加到低4位 0001 + 0010 = 0011 即为校验和
接收端计算:
数据: 1000 0100 检验和 0011
反码: 0111 1011 1100
叠加: 0111 + 1011 +1100 = 0001 1110 叠加为4bit为1111. 全为1,则正确
Linux抓包工具TCPDUMP
tcpdump采用命令行方式,它的命令格式为:
tcpdump [ -adeflnNOpqStvx ] [ -c 数量 ] [ -F 文件名 ]
[ -i 网络接口 ] [ -r 文件名] [ -s snaplen ]
[ -T 类型 ] [ -w 文件名 ] [表达式 ]
tcpdump的选项介绍
-a 将网络地址和广播地址转变成名字;
-d 将匹配信息包的代码以人们能够理解的汇编格式给出;
-dd 将匹配信息包的代码以c语言程序段的格式给出;
-ddd 将匹配信息包的代码以十进制的形式给出;
-e 在输出行打印出数据链路层的头部信息,包括源mac和目的mac,以及网络层的协议;
-f 将外部的Internet地址以数字的形式打印出来;
-l 使标准输出变为缓冲行形式;
-n 指定将每个监听到数据包中的域名转换成IP地址后显示,不把网络地址转换成名字;
-nn: 指定将每个监听到的数据包中的域名转换成IP、端口从应用名称转换成端口号后显示
-t 在输出的每一行不打印时间戳;
-v 输出一个稍微详细的信息,例如在ip包中可以包括ttl和服务类型的信息;
-vv 输出详细的报文信息;
-c 在收到指定的包的数目后,tcpdump就会停止;
-F 从指定的文件中读取表达式,忽略其它的表达式;
-i 指定监听的网络接口;
-p: 将网卡设置为非混杂模式,不能与host或broadcast一起使用
-r 从指定的文件中读取包(这些包一般通过-w选项产生);
-w 直接将包写入文件中,并不分析和打印出来;
-s snaplen snaplen表示从一个包中截取的字节数。0表示包不截断,抓完整的数据包。默认的话 tcpdump 只显示部分数据包,默认68字节。
-T 将监听到的包直接解释为指定的类型的报文,常见的类型有rpc (远程过程调用)和snmp(简单网络管理协议;)
-X 告诉tcpdump命令,需要把协议头和包内容都原原本本的显示出来(tcpdump会以16进制和ASCII的形式显示),这在进行协议分析时是绝对的利器。
1)只想查目标机器端口是21或80的网络包,其他端口的我不关注:
sudo tcpdump -i eth0 -c 10 'dst port 21 or dst port 80'
(2) 想要截获主机172.16.0.11 和主机210.45.123.249或 210.45.123.248的通信,使用命令(注意括号的使用):
sudo tcpdump -i eth0 -c 3 'host 172.16.0.11 and (210.45.123.249 or210.45.123.248)'
(3)想获取使用ftp端口和ftp数据端口的网络包
sudo tcpdump 'port ftp or ftp-data'
这里 ftp、ftp-data到底对应哪个端口? linux系统下 /etc/services这个文件里面,就存储着所有知名服务和传输层端口的对应关系。如果你直接把/etc/services里
的ftp对应的端口值从21改为了3333,那么tcpdump就会去抓端口含有3333的网络包了。
(4) 如果想要获取主机172.16.0.11除了和主机210.45.123.249之外所有主机通信的ip包,使用命令:
sudo tcpdump ip ‘host 172.16.0.11 and ! 210.45.123.249’
(5) 抓172.16.0.11的80端口和110和25以外的其他端口的包
sudo tcpdump -i eth0 ‘host 172.16.0.11 and! port 80 and ! port 25 and ! port 110’
HTPP相关
- HTTP 协议构建于 TCP/IP 协议之上,是一个应用层协议,默认端口号是 80
- HTTP 是无连接无状态的(HTTP1.1才加入keep_alive机制)
HTTP的状态字:
1xx表示信息 例如 100表示服务器同意信息处理
2xx表示成功 例如 200表示请求成功,204表示没有内容
3xx表示重定向 例如 301表示页面移动
4xx表示客户端错误,例如404表示页面找不到,403表示禁止页面
5xx表示服务器错误,例如 500表示服务器内部错误,503表示服务器忙碌,再试一次
条件GET
为了加速页面访问,HTTP使用了缓存机制,保存下页面的内容,当再次访问相同页面,服务器有俩种策
1.页面验证:通过Expries头来判断页面内容是否已经更新,不需要访问服务器,高速有效,但是该方法存在一定的风险,也就是页面可能不提供Expries头 ,另外,浏览器可能会采用自启发的方法来判断内容是否更改,例如该页面一年未曾更改,则判断其在接下来的一年基本不会更改,该方法存在一定的风险
2.条件get:客户端向服务器发送一个查询包,服务器返回页面是否更改,如果没更改啊,则直接从缓存取出页面
持久连接
HTTP是无连接、无状态的协议,其每次发送一个请求就要新建立一个TCP链接,这种做法速度缓慢,原因有俩个
1.tcp拥塞控制采用了慢启动,启动速度缓慢
2.多个tcp建立、释放需要浪费一定的时间以及系统开销
因此在HTTP1.1协议,每个链接建立后不立即释放,如果之后还有请求则继续使用该链接,如果一定时间内没有新的请求才释放链接,或者是链接太多才释放tcp链接
会话
-
什么是会话?
客户端打开与服务器的连接发出请求到服务器响应客户端请求的全过程称之为会话。
-
什么是会话跟踪?
会话跟踪指的是对同一个用户对服务器的连续的请求和接受响应的监视。
-
为什么需要会话跟踪?
浏览器与服务器之间的通信是通过HTTP协议进行通信的,而HTTP协议是”无状态”的协议,它不能保存客户的信息,即一次响应完成之后连接就断开了,下一次的请求需要重新连接,这样就需要判断是否是同一个用户,所以才有会话跟踪技术来实现这种要求。
HTTPS相关
HPPTS=HTTP+SSL/TLS
HTTP是明文传输协议,HTTPS是加密传输协议
什么是HTTPS
HTTPS(全称:Hypertext Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL
HTTPS的作用
内容加密建立一个信息安全通道,来保证数据传输的安全;
身份认证确认网站的真实性
数据完整性防止内容被第三方冒充或者篡改**
HTTPS与HTTP的区别
https协议需要到CA申请证书。
http是超文本传输协议,信息是明文传输;https 则是具有安全性的ssl加密传输协议。
http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
http默认使用80端口,https默认使用443端口

HTTPS通信过程
服务器向证书颁发机构申请证书,利用证书进行身份验证,防止黑客恶意冒充,然后利用对称加密算法进行内容加密,防止泄露。
(1).客户端向服务器发出请求 client hello
- 支持的版本协议:比如TLS 1.0版
- 支持的压缩格式:如zip
- 支持的加密算法:如RSA对称加密
- 一个随机数:稍后用于生成密钥
(2). 服务器响应 server hello
- 确认使用的加密通信协议版本,比如TLS 1.0版本。如果浏览器与服务器支持的版本不一致,服务器关闭加密通信。
- SSL证书
- 一个服务器生成的随机数,稍后用于生成"对话密钥"。
- 确认使用的加密算法
(3). 客户端回应
- 根据SSL证书开始计算证书的真伪,判断证书的域名与从颁发机构计算得到的是否正确,日期是否过期
- 产生最后一个随机数,"pre-master key",该随机数用公钥进行加密传输给服务器,同时与前俩个随机数一起通过一个密钥导出器最终导出一个对称密钥
- 加密协议改变通知:告知服务器加密方式已经发生了改变
- 客户端握手结束通知
(4).服务器最后回应
- 编码改变的通知:以后双方都用商定的加密方式进行加密方法跟密钥的发送
- 服务器握手结束通知,这一项同时也是前面发送的所有内容的hash值,用来供客户端校验。
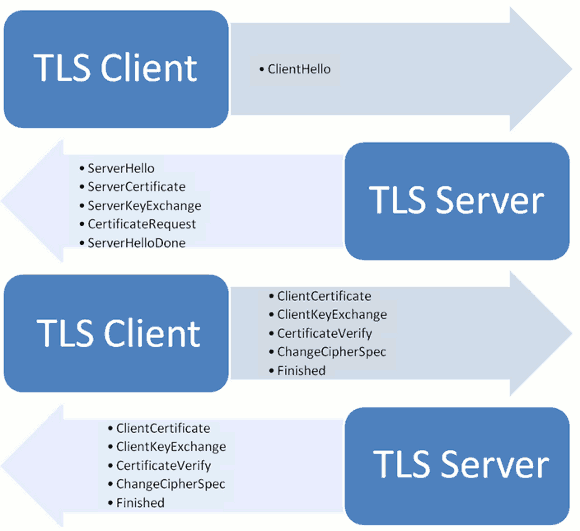

HTTPS的缺点
- HTTPS协议多次握手,导致页面的加载时间延长近50%;
- HTTPS连接缓存不如HTTP高效,会增加数据开销和功耗;
- 申请SSL证书需要钱,功能越强大的证书费用越高。
- SSL涉及到的安全算法会消耗 CPU 资源,对服务器资源消耗较大。
公钥加密计算量太大,如何减少耗用的时间?
解决方法:每一次对话(session),客户端和服务器端都生成一个"对话密钥"(session key),用它来加密信息。由于"对话密钥"是对称加密,所以运算速度非常快,而服务器公钥只用于加密"对话密钥"本身,这样就减少了加密运算的消耗时间。
为什么一定要用三个随机数,来生成"会话密钥"
"不管是客户端还是服务器,都需要随机数,这样生成的密钥才不会每次都一样。由于SSL协议中证书是静态的,因此十分有必要引入一种随机因素来保证协商出来的密钥的随机性。
对于RSA密钥交换算法来说,pre-master-key本身就是一个随机数,再加上hello消息中的随机,三个随机数通过一个密钥导出器最终导出一个对称密钥。
pre master的存在在于SSL协议不信任每个主机都能产生完全随机的随机数,如果随机数不随机,那么pre master secret就有可能被猜出来,那么仅适用pre master secret作为密钥就不合适了,因此必须引入新的随机因素,那么客户端和服务器加上pre master secret三个随机数一同生成的密钥就不容易被猜出了,一个伪随机可能完全不随机,可是是三个伪随机就十分接近随机了,每增加一个自由度,随机性增加的可不是一。"
💻 操作系统
进程与线程
进程是资源分配的基本单位
线程是独立调度的基本单位,多个线程可以共享一个进程的资源
区别:
-
线程是独立调度的基本单位,在同一进程中,线程的切换不会引起进程切换,从一个进程中的线程切换到另一个进程中的线程时,会引起进程切换。
-
线程不拥有资源,但是可以访问其隶属进程的资源
-
在创建撤销进程时,系统需要为之分配或回收资源,如内存空间、I/O 设备等,所以其创建、撤销的系统开销比线程大,在进行进程切换时,涉及当前执行进程 CPU 环境的保存及新调度进程 CPU 环境的设置,而线程切换时只需保存和设置少量寄存器内容,开销很小。
进程之间私有和共享的资源
-
私有:地址空间、堆、全局变量、栈、寄存器
-
共享:代码段,公共数据,进程目录,进程 ID
线程之间私有和共享的资源
-
私有:线程栈,寄存器,程序计数器
-
共享:堆,地址空间,全局变量,静态变量
管程
进程同步
- 同步:多个进程因为合作产生的直接制约关系,使得进程有一定的先后执行关系。
- 互斥:多个进程在同一时刻只有一个进程能进入临界区。
可以通过信号量或者其他IPC实现进程同步
进程通信
进程同步与进程通信很容易混淆,它们的区别在于:
- 进程同步:控制多个进程按一定顺序执行;
- 进程通信:进程间传输信息。
进程通信是一种手段,而进程同步是一种目的。也可以说,为了能够达到进程同步的目的,需要让进程进行通信,传输一些进程同步所需要的信息。
-
管道:管道是通过调用 pipe 函数创建的,fd[0] 用于读,fd[1] 用于写,管道有以下几个限制
- 只能用户父子进程或者兄弟进程
- 只支持半双工通信(单向交替传输);
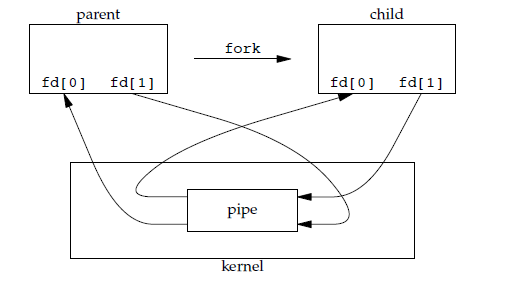
-
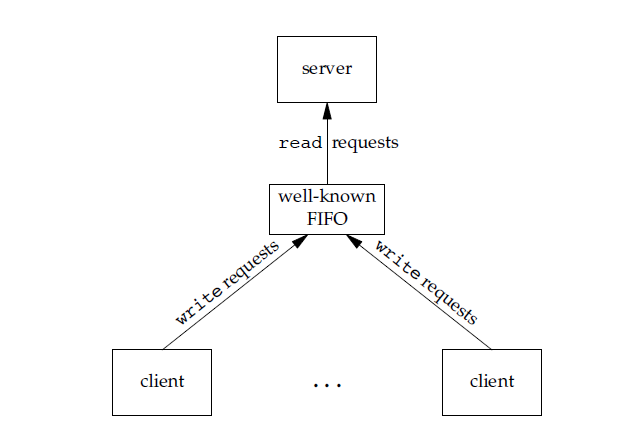
FIFO:也称为命名管道,去除了管道只能在父子进程中使用的限制。FIFO 常用于客户-服务器应用程序中,FIFO 用作汇聚点,在客户进程和服务器进程之间传递数据。
-
信号量:它是一个计数器,用于为多个进程提供对共享数据对象的访问。
-
消息队列:消息队列可以独立于读写进程存在
-
socket:扩展性好,可靠性强,存在以下优点:
- 可拓展到多个机器
- TCP是可靠通信,保证了数据的可靠传输


线程通信
线程间的通信方式主要是用于同步或者互斥访问临界区,不需要向进程一样进行数据交换。
-
锁机制:
- 互斥锁:通过互斥锁来实现线程安全,互斥地访问临界资源,互斥锁又分为俩种,可重入锁跟不可重入锁,不可重复锁在对用一个锁再次上锁时会造成死锁,不可重入锁允许多次对该锁上锁,所以在对某个临界资源上锁后可能存在其他线程访问并修改它的情况,造成程序崩溃,相比起可重入锁,不可重入锁更加容易及时发现跟解决问题。
- 读写锁:适用于读者-写者问题,允许同时读,但是对于写线程是互斥的,读锁是可重入,死锁不可重入,为了防止写进程饥饿,写锁会阻塞后来的读锁,因此reader lock 在重入的时候可能死锁。写锁阻塞读锁的做法也不适用于追求低延迟读取的场景。
2.条件变量:条件变量是用来等待而不是用来上锁的。条件变量用来自动阻塞一个线程,直到某特殊情况发生为止。通常条件变量和互斥锁同时使用。
- 假唤醒:由系统原因造成,inux的phread_cond_wait是futex系统调用,是慢速系统调用,
内存管理
程序链接
程序经过编译器编译之后,可以通过链接器,将可重定位的文件经过链接成一个可执行的目标文件。程序链接使得不同的模块文件可以分开编写,分开编译。
程序链接的步骤
程序链接主要是符号解析跟符号重定位俩个步骤,每个文件都有一个符号表,记录三种该文件的符号,主要有3种:
- 文件本身定义的可供其他文件使用的符号,非static函数跟全局变量
- 系统本身没定义的,引用其他文件的符号,如extern声明的变量等
- 系统本身定义,其他文件无法看到的,如局部变量,static函数
在编译时,编译器会将符号写入符号表,如果文件的定义跟使用都在同一个文件,那么就直接写入该符号的地址即可,如果符号是引用其他文件的,那么编译器就写上一个条目,告诉链接器该符号的定义在其他文件,链接器如果在其他文件找不到该符号的定义就会发送错误报告并终止该程序的链接。
程序解析符号表后会将各个模块的文件聚合在一起,给各个符号分配运行时内存。
静态链接、动态链接、装入时动态链接的区别
静态链接是在链接时一次性将所有的链接文件进行链接,完成各种符号的内存分配,链接完成后,当某个链接文件发生更改,不会影响该程序的运行,因为已经链接完成了,比较占用内存,因为要一次全部装完。
动态链接是程序一开始不链接完成所有文件,而是等到运行时需要用到这一部分的符号再去链接,所以如果在运行期间存在链接文件修改的情况,可能会发生错误,动态链接运行速度会比较慢,因为边运行边链接。
装入时动态链接是程序在装入时,一边装入一边链接
程序的装入
程序的编译让程序变为二进制代码,链接将分离的多个模块聚合链接成一个可执行文件,此时已经分配好逻辑空间,但是并没有实际的内存物理空间。只有在装入时,程序才会将逻辑地址映射成物理地址。
装入分配3种
- 绝对装入:在装入内存的时候写入的地址是绝对地址
- 动态装入:链接完成的都是逻辑地址,通过地址变换将逻辑地址映射成物理地址
操作系统有几种内存分配方式
- 连续内存分配:固定分区分配、可变式分区分配
- 内存分配的方法:最佳适应算法、首次适应算法、最坏适应算法
- 基本分页系统
- 基本分段系统
- 段页式系统
2 3 4都是非连续的内存分配方式
讲一下内存的碎片化
内存的碎片化主要分为俩种:外部碎片化跟内部碎片化
- 外部碎片化:在基本分页系统中,以每页1Kb为例子,如果你先申请了20页(0-19页被申请),然后在申请4页(20-23被申请),当你用完20页后释放,此时(20-23被占用,0-19被释放),当有人申请一个30页的时候只能从24开始申请,0-19的内存无法使用,造成内存的一个碎片化
- 内部碎片化:假设系统1页1kb,我现在一个程序只需要100b,也是分配1页,那么造成900b的内存浪费,这就是内部的碎片化
怎么解决
内存的外部碎片化可以采用伙伴算法,linux采用该算法来避免内存的外部碎片化,内部碎片化可以采用slab分配器
伙伴算法
伙伴算法的**就是内存中有11组链表,每个链表存放的是内存大小相等的内存块,每组链表元素的内存大小依次递增,例如第一组链表包含所有内存为1个页框大小的内存块,第二组内存是2个页框大小,第三组内存为4个页框大小,第11组内存为1024个页框大小,一个页框一般是4kb,所以最大可以分配一块4MB的内存。
在进行内存分配的时候,例如要申请一块32个页框大小的内存,先去32的链表组里面找,如果找到了,就直接分配,如果找不到则去64页框内存的那个链表去找,如果找到,则64分为2块,一块用以程序使用,一块加入到页框大小为32的链表。
内存的释放相当于一个逆过程,加入到32的链表里面,然后判断是否存在伙伴,如果有则合并成一个内存块,加入到64的链表中,然后再判断64的链表里面是否有伙伴,有的继续合并。
这里伙伴必须满足3个条件,缺一不可:
- 内存大小相等
- 物理地址连续
- 假设该块的内存页框大小为b,第一块内存的起始地址必须是2 * b * 4kb的整数倍,也即是说在内存框大小为32的链表中,0与1是伙伴,2-3是伙伴,但是1-2不是伙伴,因为1的地址为 1 * 32 * 4kb不是整数倍
slab分配器

伙伴算法只能解决内存的外部锁片化,内存的内部碎片化得用slab分配器
在linux内核中伙伴系统用来管理物理内存,其分配的单位是页,但是向用户程序一样,内核也需要动态分配内存,而伙伴系统分配的粒度又太大。由于内核无法借助标准的C库,因而需要别的手段来实现内核中动态内存的分配管理,linux采用的是slab分配器。slab分配器不仅可以提供动态内存的管理功能,而且可以作为经常分配并释放的内存的缓存。通过slab缓存,内核能够储备一些对象,供后续使用。需要注意的是slab分配器只管理内核的常规地址空间(准确的说是直接被映射到内核地址空间的那部分内存包括ZONE_NORMAL和ZONE_DMA)。
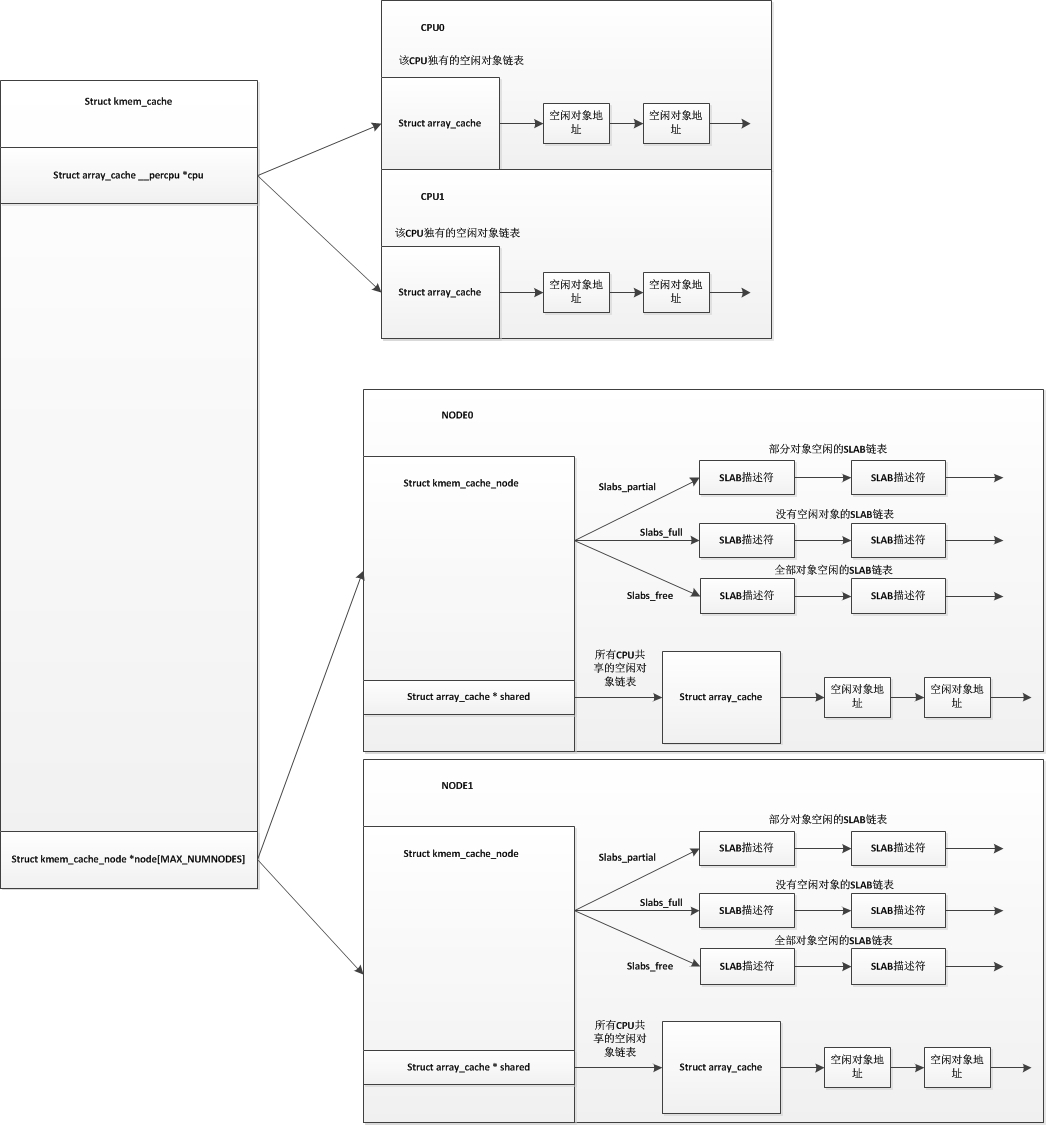
slab分配器预先从body system中申请一大块连续的内存,然后中分配成小的、固定大小的内存块,当需要时,直接进行分配,不需要再向系统申请,用完内存后不进行释放,而是返回到原来的slab链表中。
为了提升效率,SLAB分配器为每一个CPU都提供了对应各个CPU的数据结构struct array_cache,该结构指向被释放的对象。当CPU需要使用申请某一个对象的内存空间时,会先检查array_cache中是否有空闲的对象,如果有的话就直接使用。如果没有空闲对象,就像SLAB分配器进行申请。 slab分配器有俩种类型,一种是通用slab,用来分配小内存,一种是专用的slab为特定的对象分配内存,例如tcp,cpu等。
slab有几个优点:‘
- 预先分配内存,以空间换时间提高运行效率,省去申请、初始化、释放的系统开销
- 分配的内存比较小,解决了内部碎片化问题
slab适用的场所:
- 频繁申请跟释放内存
- 内存块固定大小,且比较小,小于或者等于一页
每个缓存都包含了一个 slabs 列表,这是一段连续的内存块(通常都是页面)。存在 3 种 slab:
-
slabs_full
完全分配的 slab
-
slabs_partial
部分分配的 slab
-
slabs_empty
空 slab,或者没有对象被分配
刚开始创建kmem_cache完成后,这三个链表都为空,只有在申请对象时发现没有可用的slab时才会创建一个新的SLAB,并加入到这三个链表中的一个中。也就是说kmem_cache中的SLAB数量是动态变化的,当SLAB数量太多时,kmem_cache会将一些SLAB释放回页框分配器中。

关于SLAB着色
slab着色就是希望通过的偏移量提高cache的击中率。
SLAB着色就是在同一个kmem_cache中对不同的SLAB添加一个偏移量,就让相同对象号的对象不会对齐,也就不会放入硬件高速缓存的同一行中,提高了效率。假设cpu的缓存一行为32字节,cpu包含 512 个缓存行(缓存大小16K )。 假设对象 A,B均为32字节,且 A 的地址从 0 开始, B 的地址从 16K 开始,则根据组相联或直接相联映射方式(全相联方式很少使用), A,B 对象很可能映射到缓存的第0行,此时,如果CPU 交替的访问 A,B 各 50 次,每一次访问 缓存的第 0 行都失效,从而需要从内存传送数据。而 slab 着色就是为解决该问题产生的,不同的颜色代表了不同的起始对象偏移量,对于 B 对象,如果将其位置偏移向右偏移 32字节 ,则其可能会被映射到 cache 的第 1 行上,这样交替的访问 A,B 各 50 次,只需要 2 次内存访问即可。 这里的偏移量就代表了 slab 着色中的一种颜色,不同的颜色代表了不同的偏移量,尽量使得不同的对象的对应到不同的硬件高速缓存行上,以最大限度的提高效率。实际的情况比上面的例子要复杂得多, slab 的着色还要考虑内存对齐等因素,以及 slab内未用字节的大小,只有当未用字节数足够大时,着色才起作用。
思考的问题
为什么Linux内存管理要用到slab分配器?
它能解决什么问题?
它的核心**是什么?
- 使用对象的概念来管理内存
- 以空间换时间,预先申请内存、用完不释放内存,直接回收等待下次使用
它的最小分配单元是多大?最大分配单元又是多少?
- 最小的是32KB,最大分配单元依赖体系架构。
它是否依赖buddy系统?或者和buddy系统有啥关系?
它有什么优点?又有什么缺点?
-
slab系统的缺点也是存在的,有以下几点:
1). 缓存队列管理复杂;2). 管理数据存储开销大;3). 对NUMA支持复杂;4). 调试调优困难
为什么要着色?着色有什么好处?又有什么不好的地方?
高速缓存
高速缓存又分成两种类型:普通的和专用的。普通高速缓存是slab用于自己目的的缓存,比方kmem_cache就是slab用来分配其余高速缓存描述符的,再比如上面讲到的kmalloc对应的缓存。而专用缓存是内核其它地方用到的缓存。普通缓存调用kmem_cache_init接口来初始化,其中cache_cache保存着第一个缓存描述符。专用缓存调用的是kmem_cache_create接口来创建。
虚拟存储器
我们先来分析一下如果所有的进程直接访问同一块连续的物理地址有什么弊端呢?
- 主存的容量有限。虽然我们现在的主存容量在不断上升,4G,8G,16G的主存都出现在市面上。但是我们的进程是无限,如果计算机上的每一个进程都独占一块物理存储器(即物理地址空间)。那么,主存就会很快被用完。但是,实际上,每个进程在不同的时刻都是只会用同一块主存的数
但是,总要有个建议的阈值吧,关于这个值。阮一峰在自己的博客中有过以下建议:
当系统负荷持续大于0.7,你必须开始调查了,问题出在哪里,防止情况恶化。
当系统负荷持续大于1.0,你必须动手寻找解决办法,把这个值降下来。
当系统负荷达到5.0,就表明你的系统有很严重的问题,长时间没有响应,或者接近死机了。你不应该让系统达到这值。 以上指标都是基于单CPU的,但是现在很多电脑据,这就说明了其实只要在进程想要主存数据的时候我们把需要的主存加载上就好,换进换出。针对这样的需求,直接提供一整块主存的物理地址就明显不符合。
- 进程间通信的需求。如果每个进程都 独占一块物理地址,这样就只能通过socket这样的手段进行进程通信,但如果进程间能使用同一块物理地址就可以解决这个问题。
- 主存的保护问题。对于主存来说,需要说明这段内存是可读的,可写的,还是可执行的。针对这点,光用物理地址也是很难做到的。 针对物理地址的直接映射的许多弊端,计算机的设计中就采取了一个虚拟化设计,就是虚拟内存。CPU通过发出虚拟地址,虚拟地址再通过MMU翻译成物理地址,最后获得数据。

虚拟内存是计算机系统管理内存的一种技术,它通过虚拟的逻辑地址,使得应用似乎在使用一大块连续的内存空间,虚拟内存不只是“用磁盘空间来扩展物理内存”的意思,而是指将主存以及外存的地址与虚拟地址进行映射,对用户来说好像是一整块连续的内存空间,但是实际上背后隐藏着很多的技术细节来实现这种虚拟。
虚拟内存技术实际上就是建立了 “内存一外存”的两级存储器的结构,利用局部性原理实现髙速缓存。
实现:
- 地址变换结构:需要虚拟地址与真实物理的地址的映射
- 缺页中断机制:当内存不够时,需要有一个缺页中断处理
- 页面置换函数:对页面进行换入换出,当发生缺页中断时,需要进行页面置换
〽️ 高性能服务器设计
高性能是每个后端开发工程师所追求的目标,要想设计一个高性能的服务器,然后我们就需要知道高性能服务器的指标,怎样才算高性能?影响服务器性能有哪些因素?如何去进行测试?
高性能服务器指标
平常的工作中,在衡量服务器的性能时,经常会涉及到几个指标,load、cpu、mem、qps、rt,其中load、cpu、mem来衡量机器性能,qps、rt来衡量应用性能。
qps: 一秒钟内完成的请求数量
rt: 一个请求完成的时间
Tic: 线程的cpu计算时间
Tiw: 线程的等待时间(io/网络/锁)
Tn: 线程数
Tno: 最佳线程数
Cn: cpu核数
Cu: cpu使用率
关于上述指标的计算以及意义可以参考以下这篇博客:https://blog.csdn.net/weixin_33725807/article/details/90588634?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
首先我们谈谈影响应用性能的俩个因素qps、rt
应用性能
1.一秒钟内完成的请求数量:该数量的多少与硬件有关,更与我们的程序代码有关,影响其主要的因素有以下几种:
(1). 请求的数据大小
(2). 请求的计算量大小
(3). 如果需要进行磁盘IO还需要看磁盘IO的读取速度
(4). 网络带宽
(5). GC SWAP等内存操作
2. 一个请求完成的时间: 与1类似,也是很受到程序代码的影响
机器性能
接下来让我们来看看衡量机器性能的指标——load 和 cpu使用率。
cpu使用率:程序在运行期间实时使用的cpu比率。
load:代表着一段时间内正在使用和等待使用cpu的任务平均数
机器负荷高,但应用负荷不高
即机器的load很高,但是应用的qps、rt都不高,这种情况可能有以下几种原因:
其他资源导致cpu利用率上不去,大量线程在执行其他动作或者在等待,比如io的速度太慢,内存gc等。
如果系统资源不是瓶颈,则由可能是锁竞争、后端依赖的服务吞吐低、没有充分利用多核资源,多核却使用单线程。
查看机器load高的常见方法:
机器的io(磁盘io、网络io):vmstat、iostat、sar -b等。
网络io:iftop、iptraf、ntop、tcpdump等。
内存:gc、swap、sar -r。
锁竞争、上下文切换、后端依赖。
机器负荷高,应用负荷也高
即机器load很高,应用qps也很高
典型的cpu型应用,rt中Tiw很小,基本上全是cpu计算,可以尝试查找cpu耗的较多的线程,降低cpu计算的复杂度。
应用的负荷真的很大,当所有优化手段都做了,还是无法降下来,可以考虑加机器,不丢人。
导致负载高的原因可能很复杂,有可能是硬件问题也可能是软件问题。 如果是硬件问题,那么说明机器性能确实就不行了,那么解决起来很简单,直接换机器就可以了。 CPU使用、内存使用、IO消耗都可能导致负载高。如果是软件问题,有可能由于的某些线程被长时间占用、大量内存持续占用等导致。建议从以下几个方面排查代码问题:
1、是否有内存泄露
2、是否有死锁发生
3、是否有大字段的读写
4、会不会是数据库操作导致的,排查SQL语句问题。
这里还有个建议,如果发现线上机器Load飙高,可以考虑先把堆栈内存dump下来后,进行重启,暂时解决问题,然后再考虑回滚和排查问题。
零拷贝操作
简单一点来说,零拷贝就是一种避免 CPU 将数据从一块存储拷贝到另外一块存储的技术。
零拷贝技术可以减少数据拷贝和共享总线操作的次数,消除传输数据在存储器之间不必要的中间拷贝次数,从而有效地提高数据传输效率。
而且,零拷贝技术减少了用户应用程序地址空间和操作系统内核地址空间之间因为上下文切换而带来的开销。进行大量的数据拷贝操作其实是一件简单的任务,从操作系统的角度来说,如果 CPU 一直被占用着去执行这项简单的任务,那么这将会是很浪费资源的;如果有其他比较简单的系统部件可以代劳这件事情,从而使得 CPU 解脱出来可以做别的事情,那么系统资源的利用则会更加有效。
零拷贝技术的要点:
避免操作系统内核缓冲区之间进行数据拷贝操作。
避免操作系统内核和用户应用程序地址空间这两者之间进行数据拷贝操作。
用户应用程序可以避开操作系统直接访问硬件存储。
数据传输尽量让 DMA 来做。
DMA:是指外部设备不通过CPU而直接与系统内存交换数据的接口技术。
零拷贝技术分类 Linux 中的零拷贝技术主要有下面这几种:
直接 I/O
mmap
sendfile
splice
三.sendfile实现零拷贝的原理
1.描述 sendfile系统调用在两个文件描述符之间直接传递数据(完全在内核中操作),从而避免了数据在内核缓冲区和用户缓冲区之间的拷贝,操作效率很高,被称之为零拷贝。
2.原理 sendfile() 系统调用利用 DMA 引擎将文件中的数据拷贝到操作系统内核缓冲区中,然后数据被拷贝到与 socket 相关的内核缓冲区中去。接下来,DMA 引擎将数据从内核 socket 缓冲区中拷贝到协议引擎中去。
sendfile() 系统调用不需要将数据拷贝或者映射到应用程序地址空间中去,所以 sendfile() 只是适用于应用程序地址空间不需要对所访问数据进行处理的情况。因为 sendfile 传输的数据没有越过用户应用程序 / 操作系统内核的边界线,所以 sendfile () 也极大地减少了存储管理的开销。
简单归纳上述的过程:
sendfile系统调用利用DMA引擎将文件数据拷贝到内核缓冲区,之后数据被拷贝到内核socket缓冲区中
DMA引擎将数据从内核socket缓冲区拷贝到协议引擎中
这里没有用户态和内核态之间的切换,也没有内核缓冲区和用户缓冲区之间的拷贝,大大提升了传输性能。 四.带有 DMA 收集拷贝功能的 sendfile
上面介绍的 sendfile() 技术在进行数据传输仍然还需要一次多余的数据拷贝操作,通过引入一点硬件上的帮助,这仅有的一次数据拷贝操作也可以避免。为了避免操作系统内核造成的数据副本,需要用到一个支持收集操作的网络接口。主要的方式是待传输的数据可以分散在存储的不同位置上,而不需要在连续存储中存放。这样一来,从文件中读出的数据就根本不需要被拷贝到 socket 缓冲区中去,而只是需要将缓冲区描述符传到网络协议栈中去,之后其在缓冲区中建立起数据包的相关结构,然后通过 DMA 收集拷贝功能将所有的数据结合成一个网络数据包。网卡的 DMA 引擎会在一次操作中从多个位置读取包头和数据。Linux 2.4 版本中的 socket 缓冲区就可以满足这种条件,这种方法不但减少了因为多次上下文切换所带来开销,同时也减少了处理器造成的数据副本的个数。对于用户应用程序来说,代码没有任何改变。
主要过程如下: 首先,sendfile() 系统调用利用 DMA 引擎将文件内容拷贝到内核缓冲区去;然后,将带有文件位置和长度信息的缓冲区描述符添加到 socket 缓冲区中去,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,DMA 引擎会将数据直接从内核缓冲区拷贝到协议引擎中去,这样就避免了最后一次数据拷贝。 五.总结
上述的两种几种I/O操作对比:
1.传统I/O 硬盘—>内核缓冲区—>用户缓冲区—>内核socket缓冲区—>协议引擎
2.sendfile 硬盘—>内核缓冲区—>内核socket缓冲区—>协议引擎
3.sendfile( DMA 收集拷贝) 硬盘—>内核缓冲区—>协议引擎
Tips:用户态和内核态切换的代价在哪?
首先,用户态一个进程,内核态一个进程,切换就要进行进程间的切换。 拿系统调用举例来说,系统调用一般都需要保存用户程序得上下文(context), 在进入内核得时候需要保存用户态得寄存器,在内核态返回用户态得时候会恢复这些寄存器得内容。这是一个开销的地方。
如果需要在不同用户程序间切换的话,那么还要更新cr3寄存器,这样会更换每个程序的虚拟内存到物理内存映射表的地址,也是一个比较高负担的操作。
而且内核代码对用户不信任,需要进行额外的检查。系统调用的返回过程有很多额外工作,比如检查是否需要调度等。
作者:叫我不矜持 链接:https://www.jianshu.com/p/028cf0008ca5 来源:简书
mmap原理:
一般的写
用户空间(程序调用write)----copy data---->内核空间(查看页缓存)
|----------击中-------->写入内存
|----------没有-------->根据文件innode查看磁盘所在位置---copy data---->磁盘
一般的读
用户空间(程序调用read)---->内核空间(查看页缓存)
|--------击中------>读取内存数据----copy data-->内核空间------copy data------->用户空间
|--------没有------>加载磁盘到内存---缺页终端---->磁盘-------copy data--->内核----copy data------->用户空间
mmap的写
用户空间-----直接映射------->内存
|----------击中-------->写入内存
|----------没有-------->根据文件innode查看磁盘所在位置---加载到内存---->内存
mmap的读
磁盘空间----直接映射--->用户空间
|----------击中-------->读到内存
|----------没有-------->根据文件innode查看磁盘所在位置---加载到内存---->内存
mmap的步骤:
1.用户空间调用mmap,先进行进程空间的初始化
2.内核空间调用mmap(与用户空间的不同),建立页表,将虚拟地址与文件地址一一映射
3.前2步做好了前期功能,但是没有将页表加载到内存,在进行读写操作时,会发生却页中断,将页表加载到内存
mmap的优点:
1.mmap绕过页缓存机制,将用户程序空间与磁盘空间进行映射,直接进行数据读写,减少了用户空间到内核空间的数据拷贝。
2.可以被多个进程共享,作为进程间的IPC
mmap缺点:
1.缺乏同步机制,作为进程间通信的方式,需要进行额外的同步操作
2.在内存紧张需要进行换页的系统,由于mmap不需要经过页缓存,所以会被经常换出,造成性能下降
3.其中一个访问出错会对另一个进程造成影响。
我们做个测试:
场景A:物理内存+swap space: 16G,映射文件30G,使用一个进程进行mmap,成功后映射后持续写入数据
场景B:物理内存+swap space: 16G,映射文件15G,使用两个进程进行mmap,成功后映射后持续写入数据
| 场景 | 序列 | 映射类型 | 结果 |
|---|---|---|---|
| A | 1 | MAP_PRIVATE | mmap报错 |
| A | 2 | MAP_PRIVATE + MAP_NORESERVE | mmap成功,在持续写入情况下,遇到OOM Killer |
| A | 3 | MAP_SHARED | mmap成功,在持续写入正常 |
| B | 4 | MAP_PRIVATE | mmap成功,在持续写入情况下,有一个进程会遇到OOM Killer |
| B | 5 | MAP_PRIVATE + MAP_NORESERVE | mmap成功,在持续写入情况下,有一个进程会遇到OOM Killer |
| B | 6 | MAP_SHARED | mmap成功,在持续写入正常 |
从上述测试可以看出,从现象上看,NORESERVE是绕过mmap的校验,让其可以mmap成功。但其实在RESERVE的情况下(序列4),从测试结果看,也没有保障。
mmap考参以下链接
作者:招财二师兄
https://www.jianshu.com/p/eece39beee20
mmap 函数的深入理解https://blog.csdn.net/qq_33611327/article/details/81738195
linux文件读写 https://www.cnblogs.com/huxiao-tee/p/4657851.html
Linux
Linux文件系统
linux文件系统为了兼容多种不同的底层文件系统的实现,设计了一个虚拟文件系统(vfs),提供统一的接口供系统调用。vfs的优点如下:
- 允许跨文件系统进行访问
- 允许对不同文件进行共享文件

VFS的数据结构
1、超级块(super_block):用于保存一个文件系统的所有元数据,相当于这个文件系统的信息库,为其他的模块提供信息。因此一个超级块可代表一个文件系统。文件系统的任意元数据修改都要修改超级块。超级块对象是常驻内存并被缓存的,存放于磁盘的特定扇区中。
2、目录项模块: 管理路径的目录项。比如一个路径 /home/foo/hello.txt,那么目录项有home, foo, hello.txt。目录项的块,存储的是这个目录下的所有的文件的inode号和文件名等信息。其内部是树形结构,操作系统检索一个文件,都是从根目录开始,按层次解析路径中的所有目录,直到定位到文件。
3、inode模块: 管理一个具体的文件,是文件的唯一标识,一个文件对应一个inode。通过inode可以方便的找到文件在磁盘扇区的位置。同时inode模块可链接到address_space模块,方便查找自身文件数据是否已经缓存。
4、打开文件列表模块: 包含所有内核已经打开的文件。已经打开的文件对象由open系统调用在内核中创建,也叫文件句柄。打开文件列表模块中包含一个列表,每个列表表项是一个结构体struct file,结构体中的信息用来表示打开的一个文件的各种状态参数。
5、file_operations模块: 这个模块中维护一个数据结构,是一系列函数指针的集合,其中包含所有可以使用的系统调用函数,例如open、read、write、mmap等。每个打开文件(打开文件列表模块的一个表项)都可以连接到file_operations模块,从而对任何已打开的文件,通过系统调用函数,实现各种操作。
6、address_space模块: 它表示一个文件在页缓存中已经缓存了的物理页。它是页缓存和外部设备中文件系统的桥梁。如果将文件系统可以理解成数据源,那么address_space可以说关联了内存系统和文件系统。我们会在文章后面继续讨论。

打开文件
首先俩个概念先说明一下:
- 每个打开的文件都有一个文件对象,同一个文件可以对应多个文件对象,文件系统通过文件对象来跟进程进行交互。
- 每个进程的task_struct有一个打开文件列表的数据,通过下标索引(也就是用户空间看到的文件描述符)可以获得一个打开文件对象,所以同一个文件在不同的进程文件描述符可能不同。
在调用open()函数时,内核空间会调用 sys_open()函数,首先sys_open()函数会去查找是否有文件,没有就进行创建。该函数首先获得系统的一个可用文件数组索引下标,每个进程的task_struct有一个打开文件列表的数组,通过下标可以获得一个打开文件对象,找到/创建文件之后,建立文件对象与文件描述符之间的一个联系。
读取文件
用户空间调用read(),根据文件描述符去进程的打开文件对象列表找出对应的文件对象,然后根据文件的innode找到对应的adress_sapce,然后在address_space中访问该文件的页缓存,如果页缓存命中,那么直接返回文件内容,如果页缓存缺失,那么产生一个页缺失异常,创业一个页缓存页,然后从磁盘中读取相应文件的页填充该缓存页,租后从页缺失异常中恢复,继续往下读。
加入一个进程render要读取一个scene.dat文件,实际发生的步骤如下
- render进程向内核发起读scene.dat文件的请求
- 内核根据scene.dat的inode找到对应的address_space,在address_space中查找页缓存,如果没有找到,那么分配一个内存页page加入到页缓存
- 从磁盘中读取scene.dat文件相应的页填充页缓存中的页,也就是第一次复制
- 从页缓存的页复制内容到render进程的堆空间的内存中,也就是第二次复制

读取后的内存中存在俩个数据内容 (scene.dat#2)

我们经常说mamp是数据复制一次,mmap只有一次页缓存的复制,从磁盘文件复制到页缓存中。
mmap会创建一个虚拟内存区域vm_area_struct,进程的task_struct维护着这个进程所有的虚拟内存区域信息,虚拟内存区域会更新相应的进程页表项,让这些页表项直接指向页缓存所在的物理页page。mmap新建的这个虚拟内存区域和进程堆的虚拟内存区域不是同一个,所以mmap是在堆外空间。

写文件
与读文件类似,普通文件IO也是要先把文件数据复制到页内存,然后再由页内存写入到磁盘。
一个页缓存中的页如果被修改,那么会被标记成脏页。脏页需要写回到磁盘中的文件块。有两种方式可以把脏页写回磁盘,也就是flush。
- 手动调用sync()或者fsync()系统调用把脏页写回
- pdflush进程会定时把脏页写回到磁盘
参考博客:https://blog.csdn.net/ITer_ZC/article/details/44195731
内存
共享内存
共享内存是进程间通信最快的方式,其数据拷贝只需要俩次即可,从用户空间写入到共享内存,从共享内存读出,具体过程可以看前文的文件读写描述部分。linux提供了俩种内存共享操作函数,shmget系列函数以及mmap系列函数.
shm原理
每个进程中的共享内存部分都映射到了同一块物理内存中。即是在物理内存中创建了一块空间,让进程一起使用。
每一个共享内存区都有一个控制结构struct shmid_kernel,shmid_kernel是共享内存区域中非常重要的一个数据结构,它是存储管理和文件系统结合起来的桥梁,定义如下:
struct shmid_kernel /* private to the kernel */
{
struct kern_ipc_perm shm_perm;
struct file * shm_file;
int id;
unsigned long shm_nattch;
unsigned long shm_segsz;
time_t shm_atim;
time_t shm_dtim;
time_t shm_ctim;
pid_t shm_cprid;
pid_t shm_lprid;
};
该结构中最重要的一个域应该是shm_file,它存储了将被映射文件的地址。每个共享内存区对象都对应特殊文件系统shm中的一个文件,一般情况下,特殊文件系统shm中的文件是不能用read()、write()等方法访问的,当采取共享内存的方式把其中的文件映射到进程地址空间后,可直接采用访问内存的方式对其访问。

mmap
mmap是建立文件与进程空间的联系,相当于是在硬盘(外存)建立联系

1.mmap有一个好处是当机器重启,因为mmap把文件保存在磁盘上,这个文件还保存了操作系统同步的映像,所以mmap不会丢失,但是shmget在内存里面就会丢失。
2.shm保存在物理内存,这样读写的速度肯定要比磁盘要快,但是存储量不是特别大。mmap将需要的数据再读入到内存中,可以处理大文件。
3.共享内存是在内存中创建空间,每个进程映射到此处。内存映射是创建一个文件,并且映射到每个进程开辟的空间中。
本节内容参考自博客 https://www.callmejiagu.com/2018/12/24/Linux-shm%E5%92%8Cmmap/
https://blog.csdn.net/al_xin/article/details/38602093
💾 数据库
数据库引擎
mysql数据库主要有俩种存储引擎,innodb,myisam。
数据库查询过程
查询过程
mysql的查询过程首先就是先判断是否击中查询缓存(只有开启了查询缓存才需要判断),是的话直接返回,否则进入解析器进行解析,然后进入到查询优化器进行优化,最后就执行该sql语句。

查询缓存
MySQL将缓存存放在一个引用表(不要理解成table,可以认为是类似于HashMap的数据结构),通过一个哈希值索引,这个哈希值通过查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息计算得来。所以两个查询在任何字符上的不同(例如:空格、注释),都会导致缓存不会命中。
如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、mysql库中的系统表,其查询结果都不会被缓存。比如函数NOW()或者CURRENT_DATE()会因为不同的查询时间,返回不同的查询结果,再比如包含CURRENT_USER或者CONNECION_ID()的查询语句会因为不同的用户而返回不同的结果,将这样的查询结果缓存起来没有任何的意义。
**既然是缓存,就会失效,那查询缓存何时失效呢?**MySQL的查询缓存系统会跟踪查询中涉及的每个表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。正因为如此,在任何的写操作时,MySQL必须将对应表的所有缓存都设置为失效。如果查询缓存非常大或者碎片很多,这个操作就可能带来很大的系统消耗,甚至导致系统僵死一会儿。而且查询缓存对系统的额外消耗也不仅仅在写操作,读操作也不例外:
- 任何的查询语句在开始之前都必须经过检查,即使这条SQL语句永远不会命中缓存
- 如果查询结果可以被缓存,那么执行完成后,会将结果存入缓存,也会带来额外的系统消耗
基于此,我们要知道并不是什么情况下查询缓存都会提高系统性能,缓存和失效都会带来额外消耗,只有当缓存带来的资源节约大于其本身消耗的资源时,才会给系统带来性能提升。但要如何评估打开缓存是否能够带来性能提升是一件非常困难的事情,也不在本文讨论的范畴内。如果系统确实存在一些性能问题,可以尝试打开查询缓存,并在数据库设计上做一些优化,比如:
- 用多个小表代替一个大表,注意不要过度设计
- 批量插入代替循环单条插入
- 合理控制缓存空间大小,一般来说其大小设置为几十兆比较合适
- 可以通过
SQL_CACHE和SQL_NO_CACHE来控制某个查询语句是否需要进行缓存
最后的忠告是不要轻易打开查询缓存,特别是写密集型应用。如果你实在是忍不住,可以将query_cache_type设置为DEMAND,这时只有加入SQL_CACHE的查询才会走缓存,其他查询则不会,这样可以非常自由地控制哪些查询需要被缓存,生成cache之后,只要该select中涉及到的table有任何的数据变动(insert,update,delete操作等),**相 关的所有cache都会被删除。**因此只有数据很少变动的table,引入mysql 的cache才较有意义
缓存是如何使用内存的?
mysql查询缓存采用内存池的方式来使用内存,内存池使用的基本单位是变长的block, 用来存储类型、大小、数据等信息;一个result set的cache通过链表把这些block串起来。block最短长度为query_cache_min_res_unit,每次都从空闲快将query 的结果保存下来,如果一块不够就申请多块,在释放时直接释放内存块,所以会造成内存的锁片化.
如何控制内存的碎片化?
- 选择合适的block大小
- 使用 FLUSH QUERY CACHE 命令整理碎片.这个命令在整理缓存期间,会导致其他连接无法使用查询缓存 PS: 清空缓存的命令式 RESET QUERY CACHE
事务对查询缓存有何影响
语法解析
MySQL通过关键字将SQL语句进行解析,并生成一颗对应的解析树。这个过程解析器主要通过语法规则来验证和解析。比如SQL中是否使用了错误的关键字或者关键字的顺序是否正确等等。预处理则会根据MySQL规则进一步检查解析树是否合法。比如检查要查询的数据表和数据列是否存在等等。
查询优化
MySQL使用基于成本的优化器,它尝试预测一个查询使用某种执行计划时的成本,并选择其中成本最小的一个。在MySQL可以通过查询当前会话的last_query_cost的值来得到其计算当前查询的成本。
有非常多的原因会导致MySQL选择错误的执行计划,比如统计信息不准确、不会考虑不受其控制的操作成本(用户自定义函数、存储过程)、MySQL认为的最优跟我们想的不一样(我们希望执行时间尽可能短,但MySQL值选择它认为成本小的,但成本小并不意味着执行时间短)等等。
MySQL的查询优化器是一个非常复杂的部件,它使用了非常多的优化策略来生成一个最优的执行计划:
- 重新定义表的关联顺序(多张表关联查询时,并不一定按照SQL中指定的顺序进行,但有一些技巧可以指定关联顺序)
- 优化
MIN()和MAX()函数(找某列的最小值,如果该列有索引,只需要查找B+Tree索引最左端,反之则可以找到最大值,具体原理见下文) - 提前终止查询(比如:使用Limit时,查找到满足数量的结果集后会立即终止查询)
- 优化排序(在老版本MySQL会使用两次传输排序,即先读取行指针和需要排序的字段在内存中对其排序,然后再根据排序结果去读取数据行,而新版本采用的是单次传输排序,也就是一次读取所有的数据行,然后根据给定的列排序。对于I/O密集型应用,效率会高很多)
使用索引进行排序
MySQL中,有两种方式生成有序结果集:一是使用filesort,二是按索引顺序扫描
利用索引进行排序操作是非常快的,而且可以利用同一索引同时进 行查找和排序操作。当索引的顺序与ORDER BY中的列顺序相同且所有的列是同一方向(全部升序或者全部降序)时,可以使用索引来排序,如果查询是连接多个表,仅当ORDER BY中的所有列都是第一个表的列时才会使用索引,其它情况都会使用filesort
数据库事务
数据库事务(简称:事务)是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。事务的使用是数据库管理系统区别文件系统的重要特征之一。
事务拥有四个重要的特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),人们习惯称之为 ACID 特性。下面我逐一对其进行解释。
-
原子性
(Atomicity)
事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样。例如,如果一个事务需要新增 100 条记录,但是在新增了 10 条记录之后就失败了,那么数据库将回滚对这 10 条新增的记录。也就是说事务是一个不可分割的整体,就像化学中学过的原子,是物质构成的基本单位。
-
一致性
(Consistency)
指事务将数据库从一种状态转变为另一种一致的的状态。事务开始前和结束后,数据库的完整性约束没有被破坏。例如工号带有唯一属性,如果经过一个修改工号的事务后,工号变的非唯一了,则表明一致性遭到了破坏。
-
隔离性
(Isolation)
要求每个读写事务的对象对其他事务的操作对象能互相分离,即该事务提交前对其他事务不可见。 也可以理解为多个事务并发访问时,事务之间是隔离的,一个事务不应该影响其它事务运行效果。这指的是在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。由并发事务所做的修改必须与任何其他并发事务所做的修改隔离。例如一个用户在更新自己的个人信息的同时,是不能看到系统管理员也在更新该用户的个人信息(此时更新事务还未提交)。
注:MySQL 通过锁机制来保证事务的隔离性。
-
持久性
(Durability)
事务一旦提交,则其结果就是永久性的。即使发生宕机的故障,数据库也能将数据恢复,也就是说事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。这只是从事务本身的角度来保证,排除 RDBMS(关系型数据库管理系统,例如 Oracle、MySQL 等)本身发生的故障。
注:MySQL 使用
redo log来保证事务的持久性。数据库隔离级别
了解了数据的锁机制,数据库的隔离级别也就好理解多了。每一种隔离级别满足不同的数据要求,使用不同程度的锁。
Read Uncommitted,读写均不使用锁,数据的一致性最差,也会出现许多逻辑错误。
Read Committed,使用写锁,但是读会出现不一致,不可重复读。
Repeatable Read, 使用读锁和写锁,解决不可重复读的问题,但会有幻读。
Serializable, 使用事务串形化调度,避免出现因为插入数据没法加锁导致的不一致的情况。
读不提交,造成脏读(Read Uncommitted) 一个事务中的读操作可能读到另一个事务中未提交修改的数据,如果事务发生回滚就可能造成错误。
例子:A打100块给B,B看账户,这是两个操作,针对同一个数据库,两个事物,如果B读到了A事务中的100块,认为钱打过来了,但是A的事务最后回滚了,造成损失。
避免这些事情的发生就需要我们在写操作的时候加锁,使读写分离,保证读数据的时候,数据不被修改,写数据的时候,数据不被读取。从而保证写的同时不能被另个事务写和读。
读提交(Read Committed) 我们加了写锁,就可以保证不出现脏读,也就是保证读的都是提交之后的数据,但是会造成不可重读,即读的时候不加锁,一个读的事务过程中,如果读取数据两次,在两次之间有写事务修改了数据,将会导致两次读取的结果不一致,从而导致逻辑错误。
可重读(Repeatable Read) 解决不可重复读问题,一个事务中如果有多次读取操作,读取结果需要一致(指的是固定一条数据的一致,幻读指的是查询出的数量不一致)。 这就牵涉到事务中是否加读锁,并且读操作加锁后是否在事务commit之前持有锁的问题,如果不加读锁,必然出现不可重复读,如果加锁读完立即释放,不持有,那么就可能在其他事务中被修改,若其他事务已经执行完成,此时该事务中再次读取就会出现不可重复读,
所以读锁在事务中持有可以保证不出现不可重复读,写的时候必须加锁且持有,这是必须的了,不然就会出现脏读。Repeatable Read(可重读)也是MySql的默认事务隔离级别,上面的意思是读的时候需要加锁并且保持
可串行化(Serializable) 解决幻读问题,在同一个事务中,同一个查询多次返回的结果不一致。事务A新增了一条记录,事务B在事务A提交前后各执行了一次查询操作,发现后一次比前一次多了一条记录。幻读是由于并发事务增加记录导致的,这个不能像不可重复读通过记录加锁解决,因为对于新增的记录根本无法加锁。需要将事务串行化,才能避免幻读。 这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争
数据库锁
锁机制
共享锁与排他锁
- 共享锁(读锁):其他事务可以读,但不能写。
- 排他锁(写锁) :其他事务不能读取,也不能写。
粒度锁
MySQL 不同的存储引擎支持不同的锁机制,所有的存储引擎都以自己的方式显现了锁机制,服务器层完全不了解存储引擎中的锁实现:
-
MyISAM 和 MEMORY 存储引擎采用的是表级锁(table-level locking)
-
BDB 存储引擎采用的是页面锁(page-level locking),但也支持表级锁
-
InnoDB 存储引擎既支持行级锁(row-level locking),也支持表级锁,但默认情况下是采用行级锁。
默认情况下,表锁和行锁都是自动获得的, 不需要额外的命令。
但是在有的情况下, 用户需要明确地进行锁表或者进行事务的控制, 以便确保整个事务的完整性,这样就需要使用事务控制和锁定语句来完成。
不同粒度锁的比较:
- 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
-
- 这些存储引擎通过总是一次性同时获取所有需要的锁以及总是按相同的顺序获取表锁来避免死锁。
- 表级锁更适合于以查询为主,并发用户少,只有少量按索引条件更新数据的应用,如Web 应用
- 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
-
- 最大程度的支持并发,同时也带来了最大的锁开销。
- 在 InnoDB 中,除单个 SQL 组成的事务外, 锁是逐步获得的,这就决定了在 InnoDB 中发生死锁是可能的。
- 行级锁只在存储引擎层实现,而Mysql服务器层没有实现。 行级锁更适合于有大量按索引条件并发更新少量不同数据,同时又有并发查询的应用,如一些在线事务处理(OLTP)系统
- 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
数据库锁一般可以分为两类,一个是悲观锁,一个是乐观锁。
乐观锁一般是指用户自己实现的一种锁机制,假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。乐观锁的实现方式一般包括使用版本号和时间戳。
悲观锁一般就是我们通常说的数据库锁机制,以下讨论都是基于悲观锁。
悲观锁主要表锁、行锁、页锁。在MyISAM中只用到表锁,不会有死锁的问题,锁的开销也很小,但是相应的并发能力很差。innodb实现了行级锁和表锁,锁的粒度变小了,并发能力变强,但是相应的锁的开销变大,很有可能出现死锁。同时inodb需要协调这两种锁,算法也变得复杂。InnoDB行锁是通过给索引上的索引项加锁来实现的,只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁。
表锁和行锁都分为共享锁和排他锁(独占锁),而更新锁是为了解决行锁升级(共享锁升级为独占锁)的死锁问题。
innodb中表锁和行锁一起用,所以为了提高效率才会有意向锁(意向共享锁和意向排他锁)
原文链接:https://blog.csdn.net/C_J33/article/details/79487941
考虑这个例子:
事务A锁住了表中的一行,让这一行只能读,不能写。
之后,事务B申请整个表的写锁。
如果事务B申请成功,那么理论上它就能修改表中的任意一行,这与A持有的行锁是冲突的。
数据库需要避免这种冲突,就是说要让B的申请被阻塞,直到A释放了行锁。
数据库要怎么判断这个冲突呢?
step1:判断表是否已被其他事务用表锁锁表 step2:判断表中的每一行是否已被行锁锁住。
注意step2,这样的判断方法效率实在不高,因为需要遍历整个表。 于是就有了意向锁。
在意向锁存在的情况下,事务A必须先申请表的意向共享锁,成功后再申请一行的行锁。
在意向锁存在的情况下,上面的判断可以改成
step1:不变 step2:发现表上有意向共享锁,说明表中有些行被共享行锁锁住了,因此,事务B申请表的写锁会被阻塞。
注意:申请意向锁的动作是数据库完成的,就是说,事务A申请一行的行锁的时候,数据库会自动先开始申请表的意向锁,不需要我们程序员使用代码来申请
作者:发条地精
链接:https://www.zhihu.com/question/51513268/answer/127777478
行锁的算法
InnoDB 存储引擎使用三种行锁的算法用来满足相关事务隔离级别的要求。
-
Record Locks
该锁为索引记录上的锁,如果表中没有定义索引,InnoDB 会默认为该表创建一个隐藏的聚簇索引,并使用该索引锁定记录。当索引为唯一索引,隔离机制为RR时,使用Record Locks
-
Gap Locks
该锁会锁定一个范围,但是不括记录本身。可以通过修改隔离级别为
READ COMMITTED或者配置innodb_locks_unsafe_for_binlog参数为ON。当索引为辅助索引,且隔离机制为RR时,使用GAP锁定. -
Next-key Locks
该锁就是 Record Locks 和 Gap Locks 的组合,即锁定一个范围并且锁定该记录本身。InnoDB 使用 Next-key Locks 解决幻读问题。需要注意的是,如果索引有唯一属性,则 InnnoDB 会自动将 Next-key Locks 降级为 Record Locks。举个例子,如果一个索引有 1, 3, 5 三个值,则该索引锁定的区间为
(-∞,1], (1,3], (3,5], (5,+ ∞)。
更多锁的机制可参考https://www.cnblogs.com/zhoujinyi/p/3435982.html
MVCC多版本并发控制
Mysql的大多数事务型存储引擎实现都不是简单的行级锁,基于并发性能考虑,一般都实现了MVCC多版本并发控制。MVCC是通过保存数据在某个时间点的快照来实现的。不管事务执行多长时间,事务看到的数据都是一致的。
MVCC只在READ COMMITED 和 REPEATABLE READ 两个隔离级别下工作。READ UNCOMMITTED总是读取最新的数据行,而不是符合当前事务版本的数据行。而SERIALIZABLE 则会对所有读取的行都加锁。
innodb存储引擎
innodb存储引擎中,每行数据都包含了一些隐藏字段:DB_ROW_ID、DB_TRX_ID、DB_ROLL_PTR和DELETE_BIT。

- DB_TRX_ID:用来标识最近一次对本行记录做修改的事务的标识符,即最后一次修改本行记录的事务id。delete操作在内部来看是一次update操作,更新行中的删除标识位DELELE_BIT。
- DB_ROLL_PTR:指向当前数据的undo log记录,回滚数据通过这个指针来寻找记录被更新之前的内容信息。
- DB_ROW_ID:包含一个随着新行插入而单调递增的行ID, 当由innodb自动产生聚集索引时,聚集索引会包括这个行ID的值,否则这个行ID不会出现在任何索引中。
- DELELE_BIT:用于标识该记录是否被删除。
数据操作
-
insert
创建一条记录,DB_TRX_ID为当前事务ID,DB_ROLL_PTR为NULL。
-
delete
将当前行的DB_TRX_ID设置为当前事务ID,DELELE_BIT设置为1。
-
update 复制一行,新行的DB_TRX_ID为当前事务ID,DB_ROLL_PTR指向上个版本的记录,事务提交后DB_ROLL_PTR设置为NULL。
-
select
1、只查找创建早于当前事务ID的记录,确保当前事务读取到的行都是事务之前就已经存在的,或者是由当前事务创建或修改的;
2、行的DELETE BIT为1时,查找删除晚于当前事务ID的记录,确保当前事务开始之前,行没有被删除。
一致性读
Mysql的一致性读是通过read view结构来实现。 read view主要是用来做可见性判断的,它维护的是本事务不可见的当前其他活跃事务。其中最早的事务ID为up_limit_id,最迟的事务ID为low_limit_id。low_limit_id应该是当前系统尚未分配的下一个事务ID(从这个语义来更容易理解),也就是目前已经出现过的事务ID的最大值+1。
trx_id_t low_limit_id;
/*!< The read should not see any transaction
with trx id >= this value. In other words,
this is the "high water mark". */
trx_id_t up_limit_id;
/*!< The read should see all trx ids which
are strictly smaller (<) than this value.
In other words,
this is the "low water mark". */
SELECT操作返回结果的可见性是由以下规则决定的:
DB_TRX_ID < up_limit_id -> 此记录的最后一次修改在read_view创建之前,可见
DB_TRX_ID > low_limit_id -> 此记录的最后一次修改在read_view创建之后,不可见 -> 需要用DB_ROLL_PTR查找undo log(此记录的上一次修改),然后根据undo log的DB_TRX_ID再计算一次可见性
up_limit_id <= DB_TRX_ID <= low_limit_id -> 需要进一步检查read_view中是否含有DB_TRX_ID
DB_TRX_ID ∉ read_view -> 此记录的最后一次修改在read_view创建之前,可见
DB_TRX_ID ∈ read_view -> 此记录的最后一次修改在read_view创建时尚未保存,不可见 -> 需要用DB_ROLL_PTR查找undo log(此记录的上一次修改),然后根据undo log的DB_TRX_ID再从头计算一次可见性
经过上述规则的决议,我们得到了这条记录相对read_view来说,可见的结果。
此时,如果这条记录的delete_flag为true,说明这条记录已被删除,不返回。
如果delete_flag为false,说明此记录可以安全返回给客户端
用MVCC这一种手段可以同时实现RR与RC隔离级别
它们的不同之处在于:
RR:read view是在first touch read时创建的,也就是执行事务中的第一条SELECT语句的瞬间,后续所有的SELECT都是复用这个read view,所以能保证每次读取的一致性(可重复读的语义)
RC:每次读取,都会创建一个新的read view。这样就能读取到其他事务已经COMMIT的内容。
所以对于InnoDB来说,RR虽然比RC隔离级别高,但是开销反而相对少。
补充:RU的实现就简单多了,不使用read view,也不需要管什么DB_TRX_ID和DB_ROLL_PTR,直接读取最新的record即可。
MVCC机制到底是控制记录可见性的补充知识
InnoDB RR隔离界别下,MVCC对记录可见性控制,还有如下关键判定逻辑:
- 事务ID并非在事务begin时就分配,而是在事务首次执行非快照读操作(SELECT ... FOR UPDATE/IN SHARE MODE、UPDATE、DELETE)时分配。
注:
如果事务中只有快照读,InnoDB对只有快照读事务有特殊优化,这类事务不会拥有事务ID,因为它们不会在系统中留下任何修改(甚至连锁都不会建),所以也没有留下事务ID的机会。
虽然使用SELECT TRX_ID FROM INFORMATION_SCHEMA.INNODB_TRX WHERE TRX_MYSQL_THREAD_ID = CONNECTION_ID();
查询此类事务ID时,会输出一个很大的事务ID(比如328855902652352),不过这只是MySQL在输出时临时随机分配的一个用于显示的ID而已。
- 每个事务首次执行快照读操作时,会创建一个read_view对象(可以理解为在当前事务中,为数据表建立了一个逻辑快照,read_view对象就是用来控制此逻辑快照的可见范围的)。事务提交后,其创建的read_view对象将被销毁。
read_view对象中有三个关键字段用于判断记录的可见范围。它们分别是trx_ids、low_limit_id、up_limit_id。
1. read_view->trx_ids:创建该read_view时,记录正活跃的其他事务的ID集合。事务ID在集合中降序排列,便于二分查找。
2. read_view->low_limit_id:当前活跃事务中的最大事务ID+1(即系统中最近一个尚未分配出去的事务号)。
3. read_view->up_limit_id:当前活跃事务中的最小事务ID。
- 如果记录的版本号比自己事务的read_view->up_limit_id小,则该记录的当前版本一定可见。因为这些版本的内容形成于快照创建之前,且它们的事务也肯定已经commit了。或者如果记录的版本号等于自己事务的事务ID,则该记录的当前版本也一定可见,因为该记录版本就是本事务产生的。
- 如果记录的版本号与自己事务的read_view->low_limit_id一样或比它更大,则该版本的记录的当前版本一定不可见。因为这些版本的内容形成于快照创建之后。
不可见有如下两层含义:
1. 如果该记录是新增或修改后形成的新版本记录,则对新增和修改行为不可见,即看不到最新的内容;
2. 如果该记录是标记为已删除形成的新版本记录,则对该删除行为不可见,即可以看到删除前的内容。
- 当无法通过4和5快速判断出记录的可见性时,则查找该记录的版本号是否在自己事务的read_view->trx_ids列表中,如果在则该记录的当前版本不可见,否则该记录的当前版本可见。
- 当一条记录判断出其当前版本不可见时,通过记录的DB_ROLL_PTR(undo段指针),尝试去当前记录的undo段中提取记录的上一个版本进行4~6中同样的可见性判断,如果可以则该记录的上一个版本可见。
作者:梦之痕
链接:https://juejin.im/post/5c519bb8f265da617831cfff
来源:掘金
Innodb 存储 ---page结构
InnoDB`采取的方式是:将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,InnoDB中页的大小一般为 16KB。InnnoDB page的数据结构 如下表:
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
| File Header | 文件头 | 38字节 | 描述页的信息(存在俩个首尾指针指向其他页) |
| Page Header | 页头 | 56字节 | 页的状态信息 |
| Infimum + SupreMum | 最小记录和最大记录 | 26字节 | 两个虚拟的行记录(后面会说明) |
| User Records | 用户记录 | 不确定 | 实际存储的行记录内容 |
| Free Space | 空闲空间 | 不确定 | 页中尚未使用的空间 |
| Page Directory | 页目录 | 不确定 | 页中的记录相对位置 |
| File Trailer | 文件结尾 | 8字节 | 结尾信息 |
File Header:
一张表中可以有成千上万条记录,一个页只有16KB,所以可能需要好多页来存放数据,FIL_PAGE_PREV和FIL_PAGE_NEXT就分别代表本页的上一个和下一个页的页号(双向链表)。

Page Header:
记录头部的一些状态信息
Uuser record:
人们在存储数据的时候,记录会存储到User Records部分 。但是在一个页新形成的时候是不存在User Records 这个部分的,每当我们在插入一条记录的时候,都会从Free Space中去申请一块大小符合该记录大小的空间并划分到User Records,当Free Space的部分空间全部被User Records部分替换掉之后,就意味着当前页使用完毕,如果还有新的记录插入,需要再去申请新的页
页中记录是一个按照大小从下到大连续的单向链表,现在来想想,当我们根据主键查询一条记录的时候是怎样进行的,我们来看看;
SELECT * FROM page_demo WHERE c1 = 3;
复制代码
上面是一条查询语句,我们想想它的执行方式可能是:
从最小记录开始,沿着链表一直往后找,总有一天会找到(或者找不到),在找的时候还能投机取巧,因为链表中各个记录的值是按照从小到大顺序排列的,所以当链表的某个节点代表的记录的主键值大于您想要查找的主键值时,如果这个时候还没找到数据的话您就可以停止查找了(代表找不到),因为该节点后边的节点的主键值都是依次递增。
上面的方式存在的问题就是,当页中的存储的记录数量比较少的情况用起来也没啥问题,但是如果一个页中存储了非常多的记录,这么查找对性能来说还是有损耗的,所以这个方式很笨啊。
我们来看看InnoDB 的处理方式:InnoDB 的处理方式相当于我们平时看书的时候,想看那一章的时候不会傻到去一页一页的找,而是通过目录去找到对应的页数,直接就定位过去了。说说InnoDB 这样处理的步骤吧:
1. 将所有正常的记录(包括最大和最小记录,不包括标记为已删除的记录)划分为几个组。
2. 每个组的最后一条记录的头信息中的n_owned属性表示该组内共有几条记录。
3. 将每个组的最后一条记录的地址偏移量按顺序存储起来,每个地址偏移量也被称为一个槽(英文名:Slot)。这些地址偏移量都会被存储到靠近页的尾部的地方,页中存储地址偏移量的部分也被称为Page Directory 。
InnoDB 对每个分组中的记录条数是有规定的,对于最小记录所在的分组只能有 1 条记录,最大记录所在的分组拥有的记录条数只能在 1~8 条之间,剩下的分组中记录的条数范围只能在是 4~8 条之间。所以分组是按照下边的步骤进行的:
- 初始情况下一个数据页里面只有最小记录和最大记录(伪记录),它们属于不同的分组,也就是两个;
- 之后插入的每一条记录都会放到最大记录所在的组,直到最大记录所在组的记录数等于8条;
- 当最大记录所在组中的记录数等于8条的时候,如果还有记录插入的话,就会将最大记录所在组平均分裂成2个组,这个时候最大记录所在组就只剩下4条记录,这里再把这条记录再放入最大记录所在组;
我们一口气又往表中添加了12条记录,现在就一共有16条正常的记录了(包括最小和最大记录),这些记录被分成了5个组,如图所示:

因为各个槽代表的记录的主键值都是从小到大排序的,所以我们可以使用二分法来进行快速查找。4个槽的编号分别是:0、1、2、3、4,所以初始情况下最低的槽就是low=0,最高的槽就是high=4。比方说我们想找主键值为5的记录,现在我们再来看看查找一条记录的步骤:
1. 首先得到中间槽的位置:(0 + 4)/2 = 2 ,所以得到槽2,根据槽2的地址偏移量知道它的主键值是8,因为8>5,设置high=2 ,low不变;
2. 再次计算中间槽的位置:(0 + 2)/2 = 1 ,所以得到槽1,根据槽1的地址偏移量知道它的主键值是4, 因为4<5,设置low=1 ,high不变;
3. 因为high - low的值为1,所以确定主键值为5的记录在槽1和槽2之间,接下来就是遍历链表的查找了;
1.每个记录的头信息中都有一个next_record属性,从而使页中的所有记录串联成一个单向链表。
2.InnoDB会为把页中的记录划分为若干个组,每个组的最后一个记录的地址偏移量作为一个槽,存放在Page Directory
中,所以在一个页中根据主键查找记录是非常快的,分为两步:
- 通过二分法确定该记录所在的槽。
- 通过记录的next_record属性组成的链表遍历查找该槽中的各个记录。
3.每个数据页的File Header部分都有上一个和下一个页的编号,所以所有的数据页会组成一个双链表。
4.为保证从内存中同步到磁盘的页的完整性,在页的首部和尾部都会存储页中数据的校验和和LSN值,如果首部和尾部的校验和和LSN值校验不成功的话,就说明同步过程出现了问题
作者:你的益达_
链接:https://juejin.im/post/5cb3e3dfe51d456e3428c0db
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
插入记录
核心入口函数在page_cur_insert_rec_low。核心步骤如下:
- 获取记录的长度。函数传入参数就有已经组合好的完整记录,所以只需要从记录的元数据中获取即可。
- 首先从
PAGE_FREE链表中尝试获取足够的空间。仅仅比较链表头的一个记录,如果这个记录的空间大于需要插入的记录的空间,则复用这块空间(包括heap_no),否则就从PAGE_HEAP_TOP分配空间。如果这两个地方都没有,则返回空。这里注意一下,由于只判断Free链表的第一个头元素,所以算法对空间的利用率不是很高,估计也是为了操作方便。假设,某个数据页首先删除了几条大的记录,但是最后一条删除的是比较小的记录A,那么后续插入的记录大小只有比记录A还小,才能把Free链表利用起来。举个例子,假设先后删除记录的大小为4K, 3K, 5K, 2K,那么只有当插入的记录小于2K时候,这些被删除的空间才会被利用起来,假设新插入的记录是0.5K,那么Free链表头的2K,可以被重用,但是只是用了前面的0.5K,剩下的1.5K依然会被浪费,下次插入只能利用5K记录所占的空间,并不会把剩下的1.5K也利用起来。这些特性,从底层解释了,为什么InnoDB那么容易产生碎片,经常需要进行空间整理。 - 如果Free链表不够,就从
PAGE_HEAP_TOP分配,如果分配成功,需要递增PAGE_N_HEAP。 - 如果这个数据页有足够的空间,则拷贝记录到指定的空间。
- 修改新插入记录前驱上的next指针,同时修改这条新插入记录的指针next指针。这两步主要是保证记录上链表的连续性。
- 递增
PAGE_N_RECS。设置heap_no。设置owned值为0。 - 更新
PAGE_LAST_INSERT,PAGE_DIRECTION,PAGE_N_DIRECTION,设置这些参数后,可以一定程度上提高连续插入的性能,因为插入前需要先定位插入的位置,有了这些信息可以加快查找。详见查找记录代码分析。 - 修改数据目录。因为增加了一条新的记录,可能有些目录own的记录数量超过了最大值(目前是8条),需要重新整理一下这个数据页的目录(
page_dir_split_slot)。算法比较简单,就是找到中间节点,然后用这个中间节点重新构建一个新的目录,为了给这个新的目录腾空间,需要把后续的所有目录都平移,这个涉及一次momove操作(page_dir_split_slot和page_dir_add_slot)。 - 写redolog日志,持久化操作。
- 如果有blob字段,则处理独立的off-page。
删除记录
注意这里的删除操作是指真正的删除物理记录,而不是标记记录为delete-mark。核心函数入口函数在page_cur_delete_rec。步骤如下:
- 如果需要删除的记录是这个数据页的最后一个记录,那么直接把这个数据页重新初始化成空页(
page_create_empty)即可。 - 如果不是最后一条,就走正常路径。首先记录redolog日志。
- 重置
PAGE_LAST_INSERT和递增block的modify clock。后者主要是为了让乐观的查询失效。 - 找到需要删除记录的前驱和后继记录,然后修改指针,使前驱直接指向后继。这样记录的链表上就没有这条记录了。
- 如果一个目录指向这条被删除的记录,那么让这个目录指向删除记录的前驱,同时减少这个目录own的记录数。
- 如果这个记录有blob的off-page,则删除。
- 把记录放到
PAGE_FREE链表头部,然后递增PAGE_GARBAGE的大小,减小PAGE_N_RECS用户记录的值。 - 由于第五步中递减了own值,可能导致own的记录数小于最小值(目前是4条)。所以需要重新均衡目录,可能需要删除某些目录(
page_dir_balance_slot)。具体算法也比较简单,首先判断是否可以从周围的目录中挪一条记录过来,如果可以直接调整一下前后目录的指针即可。这种简单的调整要求被挪出记录的目录own的记录数量足够多,如果也没有足够的记录,就需要删除其中一个目录,然后把后面的目录都向前平移(page_dir_delete_slot)。
查找记录/定位位置
在InnoDB中,需要查找某条件记录,需要调用函数page_cur_search_with_match,但如果需要定位某个位置,例如大于某条记录的第一条记录,也需要使用同一个函数。定位的位置有PAGE_CUR_G,PAGE_CUR_GE,PAGE_CUR_L,PAGE_CUR_LE四种,分别表示大于,大于等于,小于,小于等于四种位置。 由于数据页目录的存在,查找和定位就相对简单,先用二分查找,定位周边的两个目录,然后再用线性查找的方式定位最终的记录或者位置。 此外,由于每次插入前,都需要调用这个函数确定插入位置,为了提高效率,InnoDB针对按照主键顺序插入的场景做了一个小小的优化。因为如果按照主键顺序插入的话,能保证每次都插入在这个数据页的最后,所以只需要直接把位置直接定位在数据页的最后(PAGE_LAST_INSERT)就可以了。至于怎么判断当前是否按照主键顺序插入,就依赖PAGE_N_DIRECTION,PAGE_LAST_INSERT,PAGE_DIRECTION这几个信息了,目前的代码中要求满足5个条件:
- 当前的数据页是叶子节点
- 位置查询模式为PAGE_CUR_LE
- 相同方向的插入已经大于3了(
page_header_get_field(page, PAGE_N_DIRECTION) > 3) - 最后插入的记录的偏移量为空(
page_header_get_ptr(page, PAGE_LAST_INSERT) != 0) - 从右边插入的(
page_header_get_field(page, PAGE_DIRECTION) == PAGE_RIGHT)
数据库缓存
mysql数据库缓存
MySQL 提供了一系列的 Global Status 来记录 Query Cache 的当前状态,具体如下:
Qcache_free_blocks:目前还处于空闲状态的 Query Cache 中内存 Block 数目
Qcache_free_memory:目前还处于空闲状态的 Query Cache 内存总量
Qcache_hits:Query Cache 命中次数
Qcache_inserts:向 Query Cache 中插入新的 Query Cache 的次数,也就是没有命中的次数
Qcache_lowmem_prunes:当 Query Cache 内存容量不够,需要从中删除老的 Query Cache 以给新的 Cache 对象使用的次数
Qcache_not_cached:没有被 Cache 的 SQL 数,包括无法被 Cache 的 SQL 以及由于 query_cache_type 设置的不会被 Cache 的 SQL
Qcache_queries_in_cache:目前在 Query Cache 中的 SQL 数量
Qcache_total_blocks:Query Cache 中总的 Block 数量
查询是否开启
mysql> ``select @@query_cache_type;
query_cache_type有3个值 0代表关闭查询缓存OFF,1代表开启ON,2(DEMAND)代表当sql语句中有SQL_CACHE关键词时才缓存,如:select SQL_CACHE user_name from users where user_id = ‘100’; 这样 当我们执行 select id,name from tableName; 这样就会用到查询缓存。
mysql缓存的优缺点
优点Query Cache的查询,发生在MySQL接收到客户端的查询请求、查询权限验证之后和查询SQL解析之前。也就是说,当MySQL接收到客户端的查询SQL之后,仅仅只需要对其进行相应的权限验证之后,就会通过Query Cache来查找结果,甚至都不需要经过Optimizer模块进行执行计划的分析优化,更不需要发生任何存储引擎的交互。由于Query Cache是基于内存的,直接从内存中返回相应的查询结果,因此减少了大量的磁盘I/O和CPU计算,导致效率非常高。
缺点Query Cache的优点很明显,但是也不能忽略它所带来的一些缺点:
- 查询语句的hash计算和hash查找带来的资源消耗。如果将query_cache_type设置为1(也就是ON),那么MySQL会对每条接收到的SELECT类型的查询进行hash计算,然后查找这个查询的缓存结果是否存在。虽然hash计算和查找的效率已经足够高了,一条查询语句所带来的开销可以忽略,但一旦涉及到高并发,有成千上万条查询语句时,hash计算和查找所带来的开销就必须重视了。
- Query Cache的失效问题。如果表的变更比较频繁,则会造成Query Cache的失效率非常高。表的变更不仅仅指表中的数据发生变化,还包括表结构或者索引的任何变化。
- 查询语句不同,但查询结果相同的查询都会被缓存,这样便会造成内存资源的过度消耗。查询语句的字符大小写、空格或者注释的不同,Query Cache都会认为是不同的查询(因为他们的hash值会不同)。
- 相关系统变量设置不合理会造成大量的内存碎片,这样便会导致Query Cache频繁清理内存。
mysql缓存的的评价
检查是否从查询缓存中受益的最简单的办法就是检查缓存命中率,当服务器收到SELECT 语句的时候,Qcache_hits 和Com_select 这两个变量会根据查询缓存的情况进行递增。
查询缓存碎片率 = Qcache_free_blocks / Qcache_total_blocks / 100%*
如果查询缓存碎片率超过20%,可以用FLUSH QUERY CACHE整理缓存碎片,或者试试减小query_cache_min_res_unit,如果你的查询都是小数据量的话。
查询缓存利用率 = (query_cache_size – Qcache_free_memory) / query_cache_size / 100%*
查询缓存利用率在25%以下的话说明query_cache_size设置的过大,可适当减小;查询缓存利用率在80%以上而且 Qcache_lowmem_prunes > 50的话说明query_cache_size可能有点小,要不就是碎片太多。
查询缓存命中率 = (Qcache_hits – Qcache_inserts) / Qcache_hits / 100%*
示例服务器 查询缓存碎片率 = 20.46%,查询缓存利用率 = 62.26%,查询缓存命中率 = 1.94%,命中率很差,可能写操作比较频繁吧,而且可能有些碎片
MYSQL优化
遇到的问题
1.用户请求量太大
因为单服务器TPS,内存,IO都是有限的。 解决方法:分散请求到多个服务器上; 其实用户请求和执行一个sql查询是本质是一样的,都是请求一个资源,只是用户请求还会经过网关,路由,http服务器等。
2.单库太大
单个数据库处理能力有限;单库所在服务器上磁盘空间不足;单库上操作的IO瓶颈 解决方法:切分成更多更小的库
3.单表太大
CRUD都成问题;索引膨胀,查询超时 解决方法:切分成多个数据集更小的表。
使用缓存
分表分库
水平分表:mysql的数据文件跟索引文件是放在同一个文件(.idb)的,因此当数据文件太大时,整棵索引树很大,造成查询性能的下降(一般得是亿万级的数据才会有比较大的影响),可以采用水平分表,将一个表例如 studen表格,可以加上一个数字后缀,例如student1,student2,student3等表格,然后通过哈希算法去选择哪一个数据库表格进行数据读写。
垂直分表:表的记录并不多,但是字段却很长,表占用空间很大,一般是表中的字段较多,将不常用的, 数据较大,长度较长(比如text类型字段)的拆分到“扩展表,检索表的时候需要执行大量的IO,严重降低了性能。这时需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系。对于一个列数比较多的表格,可以将该表格按照业务拆分成多个小表,例如 student表存在id,name,date,school,grade等数据,可以拆分成 (id,name ,date),(id,school,grade)俩个表格,避免查询时,数据量太大造成的“跨页”问题,但是它无法解决单表数据过大的问题。垂直分表的另一个好处就是说可以优化缓存,例如说学生表的grade经常更新,但是school确实不经常更新的,所以会造成数据缓存的经常失效,如果分开表格,就不会影响到另一部分的缓存。
水平分库可以解决单个服务器中CPU、IO瓶颈问题。
读写分离
对于读场景多,写场景少的业务场景,可以采用读写分离的方式,因为写业务是比较费时的,而读业务的时间比较短暂,通过读写分离可以这种集群方式的本质就是把访问的压力从主库转移到从库,也就是在单机数据库无法支撑并发读写的时候,并且读的请求很多的情况下适合这种读写分离的数据库集群。如果写的操作很多的话不适合这种集群方式,因为你的数据库压力还是在写操作上,即使主从了之后压力还是在主库上和单机区别就不大了。
读写分离相对来说比较简单,当访问压力大的时候可以采用服务器集群,读写分离的方式来抗住访问压力,但是它无法缓解存储压力,对于单表数据过大造成索引膨胀以及当行数据量太大造成跨页访问等存储问题只能用分表分库来做。
但是有两点要注意:主从同步延迟、分配机制的考虑;
1、二次读取
二次读取的意思就是读从库没读到之后再去主库读一下,只要通过对数据库访问的API进行封装就能实现这个功能。很简单,并且和业务之间没有耦合。但是有个问题,如果有很多二次读取相当于压力还是回到了主库身上,等于读写分离白分了。而且如有人恶意攻击,就一直访问没有的数据,那主库就可能爆了。
2、写之后的马上的读操作访问主库
也就是写操作之后,立马的读操作指定访问主库,之后的读操作采取访问从库。这就等于写死了,和业务强耦合了。
3、关键业务读写都由主库承担,非关键业务读写分离
类似付钱的这种业务,读写都到主库,避免延迟的问题,但是例如改个头像啊,个人签名这种比较不重要的就读写分离,查询都去从库查,毕竟延迟一下影响也不大,不会立马打客服电话哈哈。
作者:yes的练级攻略
链接:https://juejin.im/post/5cbdaf80f265da038d0b444e
语句优化
- 索引不会包含有NULL值的列
只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。
- 使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
- 索引列排序
MySQL查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
- like语句操作
一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引而like “aaa%”可以使用索引。
- 不要在列上进行运算
例如:select * from users where YEAR(adddate)<2007,将在每个行上进行运算,这将导致索引失效而进行全表扫描,因此我们可以改成:select * from users where adddate<’2007-01-01′,因为在进行类型转换时,mysql可能不会触发索引直接进行全表搜索
作者:小小少年Boy