- Summary
- Current Status and History
- Where To Download Stuff
- Setting Up and Running KataGo
- Features for Developers
- Compiling KataGo
- Selfplay Training
- Contributors
- License
As of early/mid 2020, KataGo is one of the strongest open source Go bots available online, and should be stronger than Leela Zero in most positions.
KataGo was trained using an AlphaZero-like process with many enhancements and improvements, learning entirely from scratch with no outside data. Some of the improvements take advantage of game-specific features and training targets, but also many of the techniques are general and could be applied in other games. As a result, early training is immensely faster than in other zero-style bots - with only a few strong GPUs for a few days, any researcher/enthusiast should be able to train a neural net from nothing to high amateur dan strength on the full 19x19 board. If tuned well, a training run using only a single top-end consumer GPU could possibly train a bot from scratch to beyond human pro strength within a few months.
Experimentally, KataGo did also try some limited ways of using external data at the end of its June 2020 run. The results were mixed, and did not clearly appear to give any improvements in overall playing strength, which prior to that point had already surpassed that of other known open-source bots at the time.
KataGo's latest run used about 28 GPUs, rather than thousands (like AlphaZero and ELF), first reached superhuman levels on that hardware in perhaps just three to six days, and reached strength similar to ELF in about 14 days. With minor adjustments and some more GPUs, starting around 40 days it roughly began to match surpass Leela Zero in some tests with different configurations, time controls, and hardware. The run continued for a total of about five months of training time, reaching several hundred Elo stronger than Leela Zero and likely other open-source bots. The run has ended for now, but we hope to be able to continue it or begin another run in the future!
Paper about the major new ideas and techniques used in KataGo: Accelerating Self-Play Learning in Go (arXiv). A few further improvements have been found and incorporated into the latest run that are not described in this paper - some post about this might happen eventually.
Many thanks to Jane Street for providing the computation power necessary to train KataGo, as well to run numerous many smaller testing runs and experiments. Blog posts about the initial release and some interesting subsequent experiments:
KataGo's engine also aims to be a useful tool for Go players and developers, and supports the following features:
- Estimates territory and score, rather than only "winrate", helping analyze kyu and amateur dan games besides only on moves that actually would swing the game outcome at pro/superhuman-levels of play.
- Cares about maximizing score, enabling strong play in handicap games when far behind, and reducing slack play in the endgame when winning.
- Supports alternative values of komi (including integer values) and good high-handicap game play.
- Supports board sizes ranging from 7x7 to 19x19, and as of May 2020 may be the strongest open-source bot on both 9x9 and 13x13 as well.
- Supports a wide variety of rules, including rules that match Japanese rules in almost all common cases, and ancient stone-counting-like rules.
- For tool/back-end developers - supports a JSON-based analysis engine that can batch multiple-game evaluations efficiently and be easier to use than GTP.
KataGo has completed its third major official run! It lasted from December 2019 to June 2020 using about 5 months of time (KataGo did not run entirely continuously during that time) and appears to have reached significantly stronger than Leela Zero's final official 40-block nets at moderate numbers of playouts (thousands to low tens of thousands), including with only its 20-block net. Earlier, it also surpassed the prior 19-day official run from June 2019 in only about 12-14 days, and by the end reached more than 700 Elo stronger. This is due to various training improvements which were not present in prior runs. In addition to reaching stronger faster, this third run adds support for Japanese rules, stronger handicap play, and more accurate score estimation.
Strong networks are available for download! See the releases page for the latest release and these neural nets. A history of older and alternative neural nets can be found here, including a few very strong smaller nets. These include a fast 10-block network that nearly matches the strength of many earlier 15 block nets, including KataGo best 15-block net from last year and Leela Zero's LZ150. This new run also features a very strong 15-block network that should be approximately the strength of ELFv2, a 20-block network, at least at low thousands of playouts. They may be useful for users with weaker hardware. However, KataGo's latest 20-block network is so vastly much stronger than the 15-block net (perhaps 500-800 Elo at equal playouts!) that even on fairly weak hardware it likely dominates the 15-block net even taking into account how much slower it runs.
Here is a graph of the improvement so over the course of the 157 training days of the run:
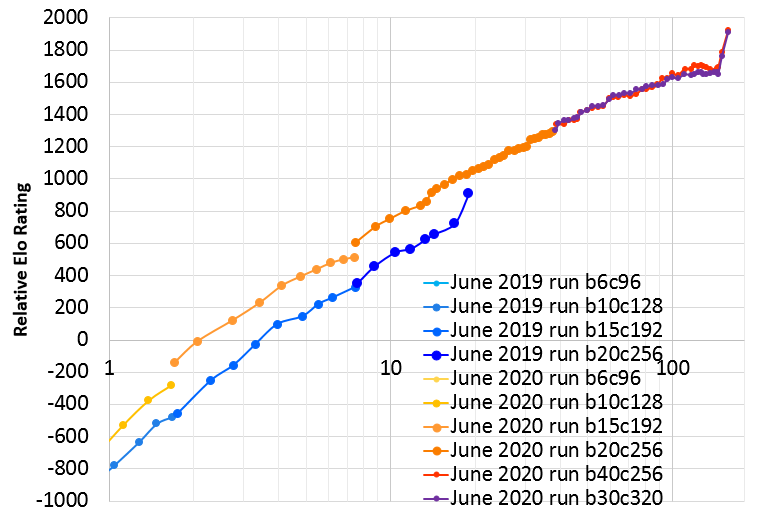 |
| X axis is days of training, log scale. (note: hardware is not entirely consistent during this time but most of the time was 44 V100 GPUs). Y axis is relative Elo rating based on some 1200-visit test matches. The abrupt jumps at the ends of each run are due to learning rate drops at the ends of those runs. The instability just before the jump in the June 2020 run, visible particularly in the 40-block Elo, is due to the last 40 days of that run being used to play with experimental changes, not all of which were improvements. 117 days is the last "clean" point prior to these changes. |
The first 117 days of the run were clean and adhered to "semi-zero" standards. In particular, game-specific input features and auxiliary training targets were used, most of which are described in KataGo's paper. However there was no use of outside data nor any special heuristics or expert logic encoded into the search for biasing or selecting moves, beyond some minor optimizations to end finished games a little faster. Only minimal adjustments were made to the ongoing training, via high-level hyperparameters (e.g. decaying the learning rate, the schedule for enlarging the neural net, etc). The last 40 days of the run then began to experiment with some limited ways of using external data to see the effects.
The run used about 46 GPUs for most of its duration. Of these, 40 were for self-play data generation, and up to 4 for training the main neural nets for the run, and 2 for gating games. Only 28 GPUs were used to surpass last year's run in the first 14 days. For days 14 to 38 this was increased to 36 GPUs, then from day 38 onward increased again to the current 46 GPUs, which was the number used for the rest of the run. One extra 47th GPU was used sometimes during the experimental changes in the last 40 days. Additionally, at times up to 3 more GPUs were used for training some extra networks such as extended smaller networks for end-users with weaker hardware, but these played no role in the run proper.
Just for fun, are tables of the Elo strength of selected versions, based on a few tens of thousands of games between these and other versions in a pool (1200 visits). These are based on fixed search tree size, NOT fixed computation time. For the first 117 days:
| Neural Net | Note | Approx Days Selfplay | Elo |
|---|---|---|---|
| g170-b6c96-s175395328-d26788732 | (last selfplay 6 block) | 0.75 | -1184 |
| g170-b10c128-s197428736-d67404019 | (last selfplay 10 block) | 1.75 | -280 |
| g170e-b10c128-s1141046784-d204142634 | (extended training 10 block) | - | 300 |
| g170-b15c192-s497233664-d149638345 | (last selfplay 15 block) | 7.5 | 512 |
| g170e-b15c192-s1305382144-d335919935 | (extended training 15 block) | - | 876 |
| g170e-b15c192-s1672170752-d466197061 | (extended training 15 block) | - | 935 |
| g170-b20c256x2-s668214784-d222255714 | (20 block) | 15.5 | 959 |
| g170-b20c256x2-s1039565568-d285739972 | (20 block) | 21.5 | 1073 |
| g170-b20c256x2-s1420141824-d350969033 | (20 block) | 27.5 | 1176 |
| g170-b20c256x2-s1913382912-d435450331 | (20 block) | 35.5 | 1269 |
| g170-b20c256x2-s2107843328-d468617949 | (last selfplay 20 block) | 38.5 | 1293 |
| g170e-b20c256x2-s2430231552-d525879064 | (extended training 20 block) | 47.5 | 1346 |
| g170-b30c320x2-s1287828224-d525929064 | (30 block more channels) | 47.5 | 1412 |
| g170-b40c256x2-s1349368064-d524332537 | (40 block less channels) | 47 | 1406 |
| g170e-b20c256x2-s2971705856-d633407024 | (extended training 20 block) | 64.5 | 1413 |
| g170-b30c320x2-s1840604672-d633482024 | (30 block more channels) | 64.5 | 1524 |
| g170-b40c256x2-s1929311744-d633132024 | (40 block less channels) | 64.5 | 1510 |
| g170e-b20c256x2-s3354994176-d716845198 | (extended training 20 block) | 78 | 1455 |
| g170-b30c320x2-s2271129088-d716970897 | (30 block more channels) | 78 | 1551 |
| g170-b40c256x2-s2383550464-d716628997 | (40 block less channels) | 78 | 1554 |
| g170e-b20c256x2-s3761649408-d809581368 | (extended training 20 block) | 92 | 1513 |
| g170-b30c320x2-s2846858752-d829865719 | (30 block more channels) | 96 | 1619 |
| g170-b40c256x2-s2990766336-d830712531 | (40 block less channels) | 96 | 1613 |
| g170e-b20c256x2-s4384473088-d968438914 | (extended training 20 block) | 117 | 1529 |
| g170-b30c320x2-s3530176512-d968463914 | (30 block more channels) | 117 | 1643 |
| g170-b40c256x2-s3708042240-d967973220 | (40 block less channels) | 117 | 1687 |
Neural nets following some of the more experimental training changes in the last 40 days, where various changes to the training involving external data were tried, with mixed results:
| Neural Net | Note | Approx Days Selfplay | Elo |
|---|---|---|---|
| g170-b30c320x2-s3910534144-d1045712926 | (30 block more channels) | 129 | 1651 |
| g170-b40c256x2-s4120339456-d1045882697 | (40 block less channels) | 129 | 1698 |
| g170e-b20c256x2-s4667204096-d1045479207 | (extended training 20 block) | 129 | 1561 |
| g170-b30c320x2-s4141693952-d1091071549 | (30 block more channels) | 136.5 | 1653 |
| g170-b40c256x2-s4368856832-d1091190099 | (40 block less channels) | 136.5 | 1680 |
| g170e-b20c256x2-s4842585088-d1091433838 | (extended training 20 block) | 136.5 | 1547 |
| g170-b30c320x2-s4432082944-d1149895217 | (30 block more channels) | 145.5 | 1648 |
| g170-b40c256x2-s4679779328-d1149909226 | (40 block less channels) | 145.5 | 1690 |
| g170e-b20c256x2-s5055114240-d1149032340 | (extended training 20 block) | 145.5 | 1539 |
Neural nets resulting from final learning rate drops. Some of the experimental uses of external data were continued here, but the large gains are most definitely due to learning rate drops rather than those uses. The last three nets in this table are KataGo's final nets from this run!
| Neural Net | Note | Approx Days Selfplay | Elo |
|---|---|---|---|
| g170-b30c320x2-s4574191104-d1178681586 | (learning rate drop by 3.5x) | 150 | 1759 |
| g170-b40c256x2-s4833666560-d1179059206 | (learning rate drop by 3.5x) | 150 | 1788 |
| g170e-b20c256x2-s5132547840-d1177695086 | (learning rate drop by 2x) | 150 | 1577 |
| g170-b30c320x2-s4824661760-d122953669 | (learning rate drop by another 2x) | 157 | 1908 |
| g170-b40c256x2-s5095420928-d1229425124 | (learning rate drop by another 2x) | 157 | 1919 |
| g170e-b20c256x2-s5303129600-d1228401921 | (learning rate drop by another 2x) | 157 | 1645 |
And for comparison to the old 2019 June official run: (these Elos are directly measured rather than inferred, as these older networks competed directly in the same pool of test games):
| Neural Net | Note | Approx Days Selfplay | Elo |
|---|---|---|---|
| g104-b6c96-s97778688-d23397744 | (last selfplay 6 block) | 0.75 | -1146 |
| g104-b10c128-s110887936-d54937276 | (last selfplay 10 block) | 1.75 | -476 |
| g104-b15c192-s297383936-d140330251 | (last selfplay 15 block) | 7.5 | 327 |
| g104-b20c256-s447913472-d241840887 | (last selfplay 20 block) | 19 | 908 |
As of June 2020, KataGo appears to be significantly stronger than several other major open-source bots in a variety of tests and conditions.
For some tests versus Leela Zero and ELF, see lightvector#254, as well as #test-results in https://discord.gg/bqkZAz3 and various casual tests run by various users in https://lifein19x19.com/viewtopic.php?f=18&t=17195 and https://lifein19x19.com/viewtopic.php?f=18&t=17474 at various points in KataGo's progression. See also the paper for test results regarding KataGo's June 2019 run ("g104") against some opponents - but also note that KataGo's June 2019 run learned somewhere between 1.5x and 2x less efficiently than more recent and much better June 2020 run ("g170").
Based on some of these tests, although most of these used all different parameters and match conditions and hardware, if one were to try to put Leela Zero on the same Elo scale as in the above tables, one could maybe guess LZ272 to be very roughly somewhere between 1250 and 1450 Elo. But note also that the above Elos, due to being computed primarily by match games with earlier networks in the same run (although selected with high variety to avoid "rock-paper-scissors" issues) are likely to not be fully linear/transitive to other bots. Or even to other KataGo networks, particularly for larger differences. For example, it would not be surprising if one were to take two networks that were a large 400 Elo apart, and discover that in a direct test that the stronger one did not win quite precisely win 10 games per 1 lost game as the Elo model would predict, although one might expect still something close.
On 9x9 (KataGo's same networks can handle all common board sizes), KataGo topped the CGOS ladder in May 2020 using one V100 GPU, playing more than 100 games against other top bots including many specially-trained 9x9 bots, as well as many games against moderately weaker 9x9 bots. Against the strongest several opponents, it won close to half of these games, while losing only one game ever (the rest of the games were draws). An alternate version configured to be more aggressive and/or even to deliberately overplay won more than half of its games against the strongest opponents, seemingly drawing less often at the cost of losing a few additional games.
The first serious run of KataGo ran for 7 days in February 2019 on up to 35 V100 GPUs. This is the run featured the early versions of KataGo's research paper. It achieved close to LZ130 strength before it was halted, or up to just barely superhuman.
Following some further improvements and much-improved hyperparameters, KataGo performed a second serious run in May-June 2019 with a max of 28 V100 GPUs, surpassing the February run after just three and a half days. The run was halted after 19 days, with the final 20-block networks reaching a final strength slightly stronger than LZ-ELFv2! (This is Facebook's very strong 20-block ELF network, running on Leela Zero's search architecture). Comparing to the yet larger Leela Zero 40-block networks, KataGo's network falls somewhere around LZ200 at visit parity, despite only itself being 20 blocks. Recent versions of the paper have been updated to reflect this run. Here is a graph of Elo ratings of KataGo's June run compared to Leela Zero and ELF based on a set of test games, where the X axis is an approximate measure of self-play computation required (note: log scale).
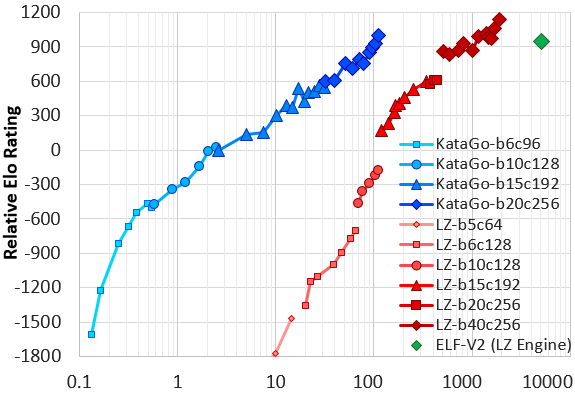 |
| June run of KataGo vs LZ and ELF. X axis is approx selfplay compute spent, log scale. Y axis is relative Elo rating. Leela Zero goes up to LZ225 on this graph. KataGo trains efficiently compared to other bots. See paper for details. |
The self-play training data from the run and full history of accepted models of these two older runs is available here.
See also https://github.com/lightvector/GoNN for some earlier research. KataGo is essentially a continuation of that research, but that old repo has been preserved since the changes in this repo are not backwards compatible, and to leave the old repo intact to continue as a showcase of the many earlier experiments performed there.
You can download precompiled executables for KataGo on the releases page for Windows and Linux.
You can download a few selected neural nets from the releases page or download additional other neural nets from here). There are two different model formats, indicated by ".txt.gz" versus ".bin.gz". This was due to a model format change starting with v1.3.3 - recent versions of KataGo support both but the latter will be both smaller on disk and faster to load.
KataGo implements just a GTP engine, which is a simple text protocol that Go software uses. It does NOT have a graphical interface on its own. So generally, you will want to use KataGo along with a GUI or analysis program. A few of them bundle KataGo in their download so that you can get everything from one place rather than downloading separately and managing the file paths and commands.
This is by no means a complete list - there are lots of things out there. But, writing as of 2020, a few of the easier and/or popular ones might be:
- KaTrain - KaTrain might be the easiest to set up for non-technical users, offering an all-in-one package (no need to download KataGo separately!), modified-strength bots for weaker players, and good analysis features.
- Lizzie - Lizzie is very popular for running long interactive analyses and visualizing them as they happen. Lizzie also offers an all-in-one package. However keep mind that KataGo's OpenCL version may take quite a while to tune and load on the very first startup as described here, and Lizzie does a poor job of displaying this progress as it happens. And in case of an actual error or failure, Lizzie's interface is not the best at explaining these errors and will appear to hang forever. The version of KataGo packaged with Lizzie is quite strong but might not always be the newest or strongest, so once you have it working, you may want to download KataGo and a newer network from releases page and replace Lizzie's versions with them.
- q5Go and Sabaki are general SGF editors and GUIs that support KataGo, including KataGo's score estimation, and many high-quality features.
Generally, for GUIs that don't offer an all-in-one package, you will need to download KataGo (or any other Go engine of your choice!) and tell the GUI the proper command line to run to invoke your engine, with the proper file paths involved. See How To Use below for details on KataGo's command line interface.
KataGo currently officially supports both Windows and Linux, with precompiled executables provided each release. Not all different OS versions and compilers have been tested, so if you encounter problems, feel free to open an issue. KataGo can also of course be compiled from source on Windows via MSVC on Windows or on Linux via usual compilers like g++, documented further down.
The community also provides KataGo packages for Homebrew on MacOS - releases there may lag behind official releases slightly.
Use brew install katago. The latest config files and networks are installed in KataGo's share directory. Find them via brew list --verbose katago. A basic way to run katago will be katago gtp -config $(brew list --verbose katago | grep gtp*.cfg) -model $(brew list --verbose katago | grep .gz | head -1). You should choose the Network according to the release notes here and customize the provided example config as with every other way of installing KataGo.
KataGo has three backends, OpenCL (GPU), CUDA (GPU), and Eigen (CPU).
The quick summary is:
- Use OpenCL if you have any good or decent GPU.
- Use Eigen with AVX2 if you don't have a GPU or if your GPU is too old/weak to work with OpenCL, and you just want a plain CPU KataGo.
- Use Eigen without AVX2 if your CPU is old or on a low-end device that doesn't support AVX2.
- You can try CUDA you have a top-end NVIDIA FP16 + tensor-core GPU and you are willing to go through the hassle to install CUDA+CUDNN. It might or might not be faster than OpenCL, you can try it out to see.
More in detail:
- OpenCL is a general GPU backend should be able to run with any GPUs or accelerators that support OpenCL, including NVIDIA GPUs, AMD GPUs, as well CPU-based OpenCL implementations or things like Intel Integrated Graphics. This is the most general GPU version of KataGo and doesn't require a complicated install like CUDA does, so is most likely to work out of the box as long as you have a fairly modern GPU. However, it also need to take some time when run for the very first time to tune itself. For many systems, this will take 5-30 seconds, but on a few older/slower systems, may take many minutes or longer. Also, the quality of OpenCL implementations is sometimes inconsistent, particularly for Intel Integrated Graphics and for AMD GPUs that are older than several years, so it might not work for very old machines, as well as specific buggy newer AMD GPUs, see also Issues with specific GPUs or GPU drivers.
- CUDA is a GPU backend specific to NVIDIA GPUs (it will not work with AMD or Intel or any other GPUs) and requires installing CUDA and CUDNN and a modern NVIDIA GPU. On most GPUs, the OpenCL implementation will actually beat NVIDIA's own CUDA/CUDNN at performance. The exception is for top-end NVIDIA GPUs that support FP16 and tensor cores, in which case sometimes one is better and sometimes the other is better.
- Eigen is a CPU backend that should work widely without needing a GPU or fancy drivers. Use this if you don't have a good GPU or really any GPU at all. It will be quite significantly slower than OpenCL or CUDA, but on a good CPU can still often get 10 to 20 playouts per second if using the smaller (15 or 20) block neural nets. Eigen can also be compiled with AVX2 and FMA support, which can provide a big performance boost for Intel and AMD CPUs from the last few years. However, it will not run at all on older CPUs (and possibly even some recent but low-power modern CPUs) that don't support these fancy vector instructions.
For any implementation, it's recommended that you also tune the number of threads used if you care about optimal performance, as it can make a factor of 2-3 difference in the speed. See "Tuning for Performance" below. However, if you mostly just want to get it working, then the default untuned settings should also be still reasonable.
Again, KataGo is just an engine and does not have its own graphical interface. So generally you will want to use KataGo along with a GUI or analysis program. If you encounter any problems while setting this up, check out Common Questions and Issues.
KataGo supports several commands.
All of these commands require a "model" file that contains the neural net, which ends in a .bin.gz or a .txt.gz or occasionally just a .gz extension. However, you can omit specifying the model if it is named default_model.bin.gz or default_model.txt.gz and located in the same directory as the katago executable.
Most of these commands also require a GTP "config" file that ends in .cfg that that specifies parameters for how KataGo behaves. However, you can omit specifying the GTP config if it is named default_gtp.cfg and located in the same directory as the katago executable.
If you are running KataGo for the first time, you may want to run the benchmark OR the genconfig commands on the command line before anything else, to test if KataGo works and pick a number of threads. And on the OpenCL version, to give KataGo a chance to autotune OpenCL, which could take a while.
To run a GTP engine using a downloaded KataGo neural net and GTP config:
./katago gtp -model <NEURALNET>.gz -config <GTP_CONFIG>.cfg- Or from a different path:
whatever/path/to/katago gtp -model whatever/path/to/<NEURALNET>.gz -config /whatever/path/to/<GTP_CONFIG>.cfg - This is the command to tell your GUI (Lizzie, q5Go, Sabaki, GoGui, etc) to use to run KataGo (with the actual paths to everything substituted currectly, of course).
Or as noted earlier, if you have a default config and model named correctly in the same directory as KataGo:
./katago gtp- Or from a different path:
whatever/path/to/katago gtp - Alternatively, this is the command you want to tell your GUI (Lizzie, q5Go, Sabaki, GoGui, etc) to use to run KataGo (if you have a default config and model).
To run a benchmark to test performance and help you choose how many threads to use for best performance. You can then manually edit your GTP config to use this many threads:
./katago benchmark -model <NEURALNET>.gz -config <GTP_CONFIG>.cfg
Or as noted earlier, if you have a default config and model named correctly in the same directory as KataGo:
./katago benchmark
To automatically tune threads and other settings for you based on asking simple questions, and generate a GTP config for you:
./katago genconfig -model <NEURALNET>.gz -output <PATH_TO_SAVE_GTP_CONFIG>.cfg
Run a JSON-based analysis engine that can do efficient batched evaluations for a backend Go service:
./katago analysis -model <NEURALNET>.gz -config <ANALYSIS_CONFIG>.cfg
The most important parameter to optimize for KataGo's performance is the number of threads to use - this can easily make a factor of 2 or 3 difference.
Secondarily, you can also read over the parameters in your GTP config (default_gtp.cfg or gtp_example.cfg or configs/gtp_example.cfg, etc). A lot of other settings are described in there that you can set to adjust KataGo's resource usage, or choose which GPUs to use. You can also adjust things like KataGo's resign threshold, pondering behavior or utility function. Most parameters are documented directly inline in the example config file. Many can also be interactively set when generating a config via the genconfig command described above.
This section summarizes a number of common questions and issues when running KataGo.
If you are observing any crashes in KataGo while attempting to run the benchmark or the program itself, and you have one of the below GPUs, then this is likely the reason.
- AMD Radeon RX 5700 - AMD's drivers for OpenCL for this GPU have been buggy ever since this GPU was released, and as of May 2020 AMD has still never released a fix. If you are using this GPU, you will just not be able to run KataGo (Leela Zero and other Go engines will probably fail too) and will probably also obtain incorrect calculations or crash if doing anything else scientific or mathematical that uses OpenCL. See for example these reddit threads: [1] or [2] or this L19 thread.
- OpenCL Mesa - These drivers for OpenCL are buggy. Particularly if on startup before crashing you see KataGo printing something like
Found OpenCL Platform 0: ... (Mesa) (OpenCL 1.1 Mesa ...) ...then you are using the Mesa drivers. You will need to change your drivers, see for example this KataGo issue which links to this thread. - Intel Integrated Graphics - For weaker/older machines or laptops or devices that don't have a dedicated GPU, KataGo might end up using the weak "Intel Integrated Graphics" that is built in with the CPU. Often this will work fine (although KataGo will be slow and only get a tiny number of playouts compared to using a real GPU), but various versions of Intel Integrated Graphics can also be buggy and not work at all. If a driver update doesn't work for you, then the only solution is to upgrade to a better GPU. See for example this issue or this issue, or this other Github's issue.
-
KataGo seems to hang or is "loading" forever on startup in Lizzie/Sabaki/q5go/GoReviewPartner/etc.
- Likely either you have some misconfiguration, have specified file paths incorrectly, a bad GPU, etc. Many of these GUIs do a poor job of reporting errors and may completely swallow the error message from KataGo that would have told you what was wrong. Try running KataGo's
benchmarkorgtpdirectly on the command line, as described above. - Sometimes there is no error at all, it is merely that the first time KataGo runs on a given network size, it needs to do some expensive tuning, which may take a few minutes. Again this is clearer if you run the
benchmarkcommand directly in the command line. After tuning, then subsequent runs will be faster.
- Likely either you have some misconfiguration, have specified file paths incorrectly, a bad GPU, etc. Many of these GUIs do a poor job of reporting errors and may completely swallow the error message from KataGo that would have told you what was wrong. Try running KataGo's
-
KataGo works on the command line but having trouble specifying the right file paths for the GUI.
- As described above, you can name your config
default_gtp.cfgand name whichever network file you've downloaded todefault_model.bin.gz(for newer.bin.gzmodels) ordefault_model.txt.gz(for older.txt.gzmodels). Stick those into the same directory as KataGo's executable, and then you don't need to specify-configor-modelpaths at all.
- As described above, you can name your config
-
KataGo gives an error like
Could not create filewhen trying to run the initial tuning.- KataGo probably does not have access permissions to write files in the directory where you placed it.
- On Windows for example, the
Program Filesdirectory and its subdirectories are often restricted to only allow writes with admin-level permissions. Try placing KataGo somewhere else.
-
I'm getting a different error or still want further help.
- Check out the discord chat where Leela Zero, KataGo, and other bots hang out and ask in the "#help" channel.
- If you think you've found a bug in KataGo itself, feel free also to open an issue.
-
How do I make KataGo use Japanese rules or other rules?
- KataGo supports some GTP extensions for developers of GUIs to set the rules, but unfortunately as of June 2020, only a few of them make use of this. So as a workaround, there are a few ways:
- Edit KataGo's config (
default_gtp.cfgorgtp_example.cfgorgtp.cfg, or whatever you've named it) to userules=japaneseorrules=chineseor whatever you need, or set the individual ruleskoRule,scoringRule,taxRule, etc. to what they should be. See here for where this is in the config, or and see this webpage for the full description of KataGo's ruleset. - Use the
genconfigcommand (./katago genconfig -model <NEURALNET>.gz -output <PATH_TO_SAVE_GTP_CONFIG>.cfg) to generate a config, and it will interactively help you, including asking you for what default rules you want. - If your GUI allows access directly to the GTP console (for example, press
Ein Lizzie), then you can runkata-set-rules japaneseor similar for other rules directly in the GTP console, to change the rules dynamically in the middle of a game or an analysis session.
- Edit KataGo's config (
- KataGo supports some GTP extensions for developers of GUIs to set the rules, but unfortunately as of June 2020, only a few of them make use of this. So as a workaround, there are a few ways:
-
How do I make KataGo show me a wider range of possible good moves and options during analysis?
- Add
analysisWideRootNoise = Xto the config (default_gtp.cfgorgtp_example.cfgorgtp.cfg, or whatever you've named it). A value of 0.03 will mildly widen the range of moves that get searched and evaluated. A value of 0.10 will very noticeably widen the search. Much larger values will start pushing KataGo toward evaluating every move on the board, at the cost of evaluating the best moves less thoroughly. You can play with this parameter to see what you prefer. You can also change it at runtime by typingkata-set-param analysisWideRootNoise Xinto the GTP console, if your GUI program exposes the GTP console for you to provide direct commands.
- Add
-
Which model/network should I use?
- For weaker or mid-range GPUs, try the final 20-block network from here, which is the best of its size.
- For top-tier GPUs and/or for the highest-quality analysis if you're going to use many thousands and thousands of playouts and long thinking times, try the final 40-block network from here, which is more costly to run but should be the strongest and best overall.
- If you care a lot about theoretical purity - no outside data, bot learns strictly on its own - use the 20 or 40 block nets from this release, which are pure in this way and still much stronger than Leela Zero, but also not quite as strong as the final nets.
- If you want some nets that are much faster to run, and each with their own interesting style of play due to their unique stages of learning, try any of the "b10c128" or "b15c192" Extended Training Nets here which are 10 block and 15 block networks from earlier in the run that are much weaker but still pro-level-and-beyond.
In addition to a basic set of GTP commands, KataGo supports a few additional commands, for use with analysis tools and other programs.
KataGo's GTP extensions are documented here.
-
Notably: KataGo exposes a GTP command
kata-analyzethat in addition to policy and winrate, also reports an estimate of the expected score and a heatmap of the predicted territory ownership of every location of the board. Expected score should be particularly useful for reviewing handicap games or games of weaker players. Whereas the winrate for black will often remain pinned at nearly 100% in a handicap game even as black makes major mistakes (until finally the game becomes very close), expected score should make it more clear which earlier moves are losing points that allow white to catch up, and exactly how much or little those mistakes lose. If you're interested in adding support for this to any analysis tool, feel free to reach out, I'd be happy to answer questions and help. -
KataGo also exposes a few GTP extensions that allow setting what rules are in effect (Chinese, AGA, Japanese, etc). See again here for details.
KataGo also implements a separate engine that can evaluate much faster due to batching if you want to analyze whole games at once and might be much less of a hassle than GTP if you are working in an environment where JSON parsing is easy. See here for details.
KataGo is written in C++. It should compile on Linux or OSX via g++ that supports at least C++14, or on Windows via MSVC 15 (2017) and later. Other compilers and systems have not been tested yet. This is recommended if you want to run the full KataGo self-play training loop on your own and/or do your own research and experimentation, or if you want to run KataGo on an operating system for which there is no precompiled executable available.
- Requirements
- CMake with a minimum version of 3.10.2 - for example
sudo apt install cmakeon Debian, or download from https://cmake.org/download/ if that doesn't give you a recent-enough version. - Some version of g++ that supports at least C++14.
- If using the OpenCL backend, a modern GPU that supports OpenCL 1.2 or greater, or else something like this for CPU. But if using CPU, Eigen should be better.
- If using the CUDA backend, CUDA 10.2 and CUDNN 7.6.5 (https://developer.nvidia.com/cuda-toolkit) (https://developer.nvidia.com/cudnn) and a GPU capable of supporting them. I'm unsure how version compatibility works with CUDA, there's a good chance that later versions than these work just as well, but they have not been tested.
- If using the Eigen backend, Eigen3. With Debian packages, (i.e. apt or apt-get), this should be
libeigen3-dev. - zlib, libzip, boost filesystem. With Debian packages (i.e. apt or apt-get), these should be
zlib1g-dev,libzip-dev,libboost-filesystem-dev. - If you want to do self-play training and research, probably Google perftools
libgoogle-perftools-devfor TCMalloc or some other better malloc implementation. For unknown reasons, the allocation pattern in self-play with large numbers of threads and parallel games causes a lot of memory fragmentation under glibc malloc that will eventually run your machine out of memory, but better mallocs handle it fine.
- CMake with a minimum version of 3.10.2 - for example
- Clone this repo:
git clone https://github.com/lightvector/KataGo.git
- Compile using CMake and make in the cpp directory:
cd KataGo/cppcmake . -DUSE_BACKEND=OPENCLorcmake . -DUSE_BACKEND=CUDAorcmake . -DUSE_BACKEND=EIGENdepending on which backend you want.- Specify also
-DUSE_TCMALLOC=1if using TCMalloc. - Compiling will also call git commands to embed the git hash into the compiled executable, specify also
-DNO_GIT_REVISION=1to disable it if this is causing issues for you. - Specify
-DUSE_AVX2=1to also compile Eigen with AVX2 and FMA support, which will make it incompatible with old CPUs but much faster. (If you want to go further, you can also add-DCMAKE_CXX_FLAGS='-march=native'which will specialize to precisely your machine's CPU, but the exe might not run on other machines at all).
- Specify also
make
- Done! You should now have a compiled
katagoexecutable in your working directory. - Pre-trained neural nets are available on the releases page or more from here.
- You will probably want to edit
configs/gtp_example.cfg(see "Tuning for Performance" above). - If using OpenCL, you will want to verify that KataGo is picking up the correct device when you run it (e.g. some systems may have both an Intel CPU OpenCL and GPU OpenCL, if KataGo appears to pick the wrong one, you can correct this by specifying
openclGpuToUseinconfigs/gtp_example.cfg).
- Requirements
- CMake with a minimum version of 3.10.2, GUI version strongly recommended (https://cmake.org/download/)
- Microsoft Visual Studio for C++. Version 15 (2017) has been tested and should work, other versions might work as well.
- If using the OpenCL backend, a modern GPU that supports OpenCL 1.2 or greater, or else something like this for CPU. But if using CPU, Eigen should be better.
- If using the CUDA backend, CUDA 10.2 and CUDNN 7.6.5 (https://developer.nvidia.com/cuda-toolkit) (https://developer.nvidia.com/cudnn) and a GPU capable of supporting them. I'm unsure how version compatibility works with CUDA, there's a good chance that later versions than these work just as well, but they have not been tested.
- If using the Eigen backend, Eigen3, version 3.3.x. (http://eigen.tuxfamily.org/index.php?title=Main_Page#Download).
- Boost. You can obtain prebuilt libraries for Windows at: https://www.boost.org/users/download/ -> "Prebuilt windows binaries" -> "1.70.0". For example, boost_1_70_0-msvc-14.1-64.exe if you're on 64-bit windows. Note that MSVC 14.1 libraries (2015) are directly-compatible with MSVC 15 (2017).
- zlib. The following package might work, https://www.nuget.org/packages/zlib-vc140-static-64/, or alternatively you can build it yourself via something like: https://github.com/kiyolee/zlib-win-build
- libzip (optional, needed only for self-play training) - for example https://github.com/kiyolee/libzip-win-build
- Download/clone this repo to some folder
KataGo. - Configure using CMake GUI and compile in MSVC:
- Select
KataGo/cppas the source code directory in CMake GUI. - Set the build directory to wherever you would like the built executable to be produced.
- Click "Configure". For the generator select your MSVC version, and also select "x64" for the optional platform if you're on 64-bit windows, don't use win32.
- If you get errors where CMake has not automatically found Boost, ZLib, etc, point it to the appropriate places according to the error messages:
BOOST_ROOT- point this to your boost installation directory.ZLIB_INCLUDE_DIR- point this to the directory containingzlib.hand other headersZLIB_LIBRARY- point this to thelibz.libresulting from building zlib. Note that "*_LIBRARY" expects to be pointed to the ".lib" file, whereas the ".dll" file is the file that needs to be included with KataGo at runtime.
- Also set
USE_BACKENDtoOPENCLorCUDA, orEIGENdepending on what backend you want to use. - Set any other options you want and re-run "Configure" again as needed after setting them. Such as:
NO_GIT_REVISIONif you don't have Git or if cmake is not finding it.NO_LIBZIPif you don't care about running self-play training and you don't have libzip.USE_AVX2if you want to compile with AVX2 and FMA instructions, which will fail on some CPUs but speed up Eigen greatly on CPUs that support them.
- Once running "Configure" looks good, run "Generate" and then open MSVC and build as normal in MSVC.
- Select
- Done! You should now have a compiled
katago.exeexecutable in your working directory. - Note: You may need to copy the ".dll" files corresponding to the various ".lib" files you compiled with into the directory containing katago.exe.
- Note: If you had to update or install CUDA or GPU drivers, you will likely need to reboot before they will work.
- Pre-trained neural nets are available on the releases page or more from here.
- You will probably want to edit
configs/gtp_example.cfg(see "Tuning for Performance" above). - If using OpenCL, you will want to verify that KataGo is picking up the correct device (e.g. some systems may have both an Intel CPU OpenCL and GPU OpenCL, if KataGo appears to pick the wrong one, you can correct this by specifying
openclGpuToUseinconfigs/gtp_example.cfg).
If you'd also like to run the full self-play loop and train your own neural nets using the code here, see Selfplay Training.
Many thanks to the various people who have contributed to this project! See CONTRIBUTORS for a list of contributors.
Except for several external libraries that have been included together in this repo under cpp/external/ as well as the single file cpp/core/sha2.cpp, which all have their own individual licenses, all code and other content in this repo is released for free use or modification under the license in the following file: LICENSE.
License aside, if you end up using any of the code in this repo to do any of your own cool new self-play or neural net training experiments, I (lightvector) would to love hear about it.