Chat-GPT Knowledge

Chat-GPT与网络安全
-
陈巍
生成式预训练语言模型 (Generative Pre-trained Transformer )

模型训练中用到了强化学习
-
褚杏娟、核子可乐 InfoQ
-
红山观察:OpenAI最新成果ChatGPT发布 开源成为资本竞赛新焦点
杨颖滢 易比一 红山开源
决策式到生成式
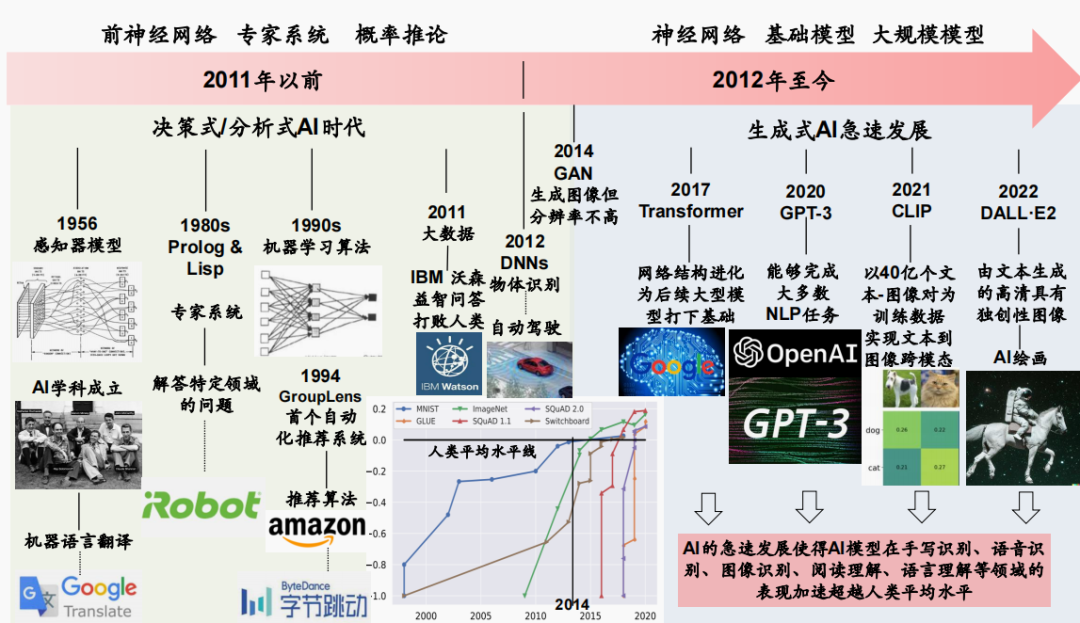
专用人工智能到通用人工智能
随后的GPT-3与GPT-3.5均停止了开源, Meta AI实验室对标OpenAI推出了1750亿参数的OPT模型(Open Pre-trained transformer),并将模型权重、代码及部署进行copyleft许可开源(所谓“copyleft许可”是最常见的开源许可,其条款试图限制商业化)。


好玩的数学
Chat-GPT对于一个无论如何都不是为数学量身定做的模型来说是相当令人印象深刻的。我认为,以目前的格式,它已经可以帮助数学家准备讲义甚至论文中更简单的部分。也许它最大的用处在于自动处理基金和工作申请的某些部分。
虎符智库小编 奇安信集团
Recorded Future 在报告中表示, 网络犯罪分子使用 ChatGPT 造成的“最紧迫和常见的威胁”主要包括网络钓鱼、恶意软件生成、社会工程。
ChatGPT同样是安全防护的福音,也可以用来帮助安全人员提高效率,提高恶意信息识别、抵御网络攻击的能力,这主要包括钓鱼检测、漏洞发现和安全事件响应。
(2)漏洞发现
ChatGPT 可用于帮助发现组织使用软件和系统中的新漏洞。网络安全行业已经面临控制大量安全漏洞的挑战。人工智能将会把安全漏洞数字推得更高,因为它可以更快、更智能地发现漏洞。
安全人员可以使用 ChatGPT 快速生成大量独特的输入,使网络安全专业人员能够识别以前未检测到和未知的漏洞。同时,还使用新获得的知识和信息来提高软件和系统的安全性,实施更有效的安全控制,或改进当前的安全措施和实践。
ChatGPT它与用户的专业水平相结合,可以使用户能够快速学习并有效地采取行动。就像应用程序的在线帮助可以解决问题一样,用户可以从ChatGPT获得特定漏洞的更多信息以及如何缓解办法。
未来随着,ChatGPT模型代码理解能力的提高,安全防护人员可以询问软件代码的副作用,将其作为开发伙伴,可以显著提升软件代码的安全水平。
随着ChatGPT人工智能模型的演进,有可能实现漏洞检测和修复的自动化和/或半自动化,以及基于风险的优先级。这对于面临资源限制的 IT 和安全团队来说将是非常有吸引力的应用。
James Pei 格上财富
ChatGPT的计算逻辑来自于一个名为transformer的算法,它来源于2017年的一篇科研论文《Attention is all your need》
刘禹良等 CSIG文档图像分析与识别专委会
原理
ChatGPT是一种基于认知计算和人工智能的语言模型,它使用了 Transformer 架构和Generative Pre-Training(GPT),即生成型预训练技术。GPT训练的模型是一种应用于自然语言处理(NLP)的模型,它通过使用多层Transformer来预测下一个单词的概率分布,以生成自然语言文本。这是通过在超大型文本语料库上训练学习到的语言模式来实现的。
从2018年拥有1.17亿参数的GPT-1到2020年拥有1750亿参数的GPT-3,OpenAI的语言模型智能化程度明显提升。随着模型的不断增大,生成模型的不断改进,以及自监督的不断完善,GPT的语言处理能力和生成能力得到了显著的提升。此后,2022年1月基于RLHF (Reinforcement Learning from Human Feedback)的InstructGPT的提出显著降低了有害、不真实和有偏差输出的概率。在2022年11月,基于Instruct GPT技术的ChatGPT模型正式发布,ChatGPT在Instruct GPT的基础上增加了聊天属性,并向公众开放了测试版本。
ChatGPT的成功离不开多类技术的积累,其中最为核心的是RLHF,此外还有SFT、IFT、CoT这些技术:
- Reinforcement Learning from Human Feedback (RLHF) RLHF方法是一种基于人类偏好的强化学习方法。它通过利用人们对对话代理回答的评价来改进对话代理的回答。RLHF方法可以根据人们的喜好对对话代理的回答进行排序,例如通过考虑人们喜欢的内容来选择文本摘要。这些评价的回答用来训练一个喜好模型,该模型将告诉强化学习系统如何评价回答的好坏。最后,通过强化学习训练对话代理来模拟这个喜好模型。整个训练过程包括对GPT-3进行监督微调,然后训练奖励模型,最后通过强化学习优化 SFT(监督下的微调模型)(第二步和第三步可以多次迭代循环)。SFT是(Supervised Fine-Tuning 模型)是一种预先训练的语言模型,经过对少量标签者提供的演示数据的细微调整,以学习一个监督策略(即 SFT 模型),可从选定的提示列表生成输出。
- ChatGPT采用基于**指令微调 (Instruction Fine-Tuning,IFT)**的技术来模拟人类的聊天行为。IFT是一种能够追踪、学习和复述聊天会话历史的技术,并将其应用于在实时会话中对自然语言进行建模和推断。该方法除了使用情感分析、文本分类、摘要等经典 NLP 任务来微调模型外,还在非常多样化的任务集上向基础模型示范各种书面指令及其输出,从而实现对基础模型的微调。由此,ChatGPT能够发挥较大的自由度,提供更多样化的自然回复,玩家们可以与机器人无缝对话,体验自然聊天的乐趣。IFT还能够帮助ChatGPT进行语法检查,避免出现重复或无意义的语句,从而提升会话体验。
- Chain-of-thought (CoT) 技术提示最早由谷歌在2022年1月提出来,是few-shot prompting (也被称为In Context Learning, ICL)的一种独特情形,它的目的是使大型语言模型能够更好地理解人类的语言请求。它通过在对话过程中不断提供上下文信息,来帮助模型理解语言请求的内容。这种技术可以使模型更准确地回答问题,并且可以帮助模型在处理复杂的对话任务时变得更加灵活。总的来说,CoT技术是为了改善大型语言模型的语言处理能力,使其能更好地理解人类语言请求。
根据OpenAI官方的文档,ChatGPT的构建大致包括如下三个步骤:
1)搜集对话数据,训练有监督的微调模型。人类标注员选择提示词并写下期望的输出回答,然后利用这些数据对一个预训练的语言模型进行微调,从而学习到一个有监督的微调模型(即SFT模型)。
2)搜集用于对比的数据,训练一个奖励模型(Reward Model)。这一步是为了模仿人类的偏好。标注员对SFT模型的大量输出进行投票,从而创建一个包含比较数据的新数据集。然后在此数据集上训练一个新模型,称为奖励模型(RM)。
3)搜集说明数据,使用PPO(Proximal Policy Optimization, 近端优化策略)强化学习来优化策略。利用奖励模型进一步微调并改进SFT模型,最终得到优化完毕的SFT模型。
总体而言,相较于以往的模型,除了海量的无标注语料数据之外,ChatGPT还具有更大的专门语料库(训练集一共有2300W+条对话记录,涵盖英语、中文等多种语言;共约七千万行,其中包括由大量真实用户生成的句子)、更强大的预训练模型(GPT-3.5)、更高的适应性和更强的自我学习能力。它具备连续对话、上下文理解、用户意图捕捉、以及敢于质疑的能力,同时还能够对用户的请求说不并给出理由。最重要的是,扩展升级ChatGPT纵使需要较高的成本,但技术上只需要通过不断更新数据、算法、模型和应用就能快速迭代更新其能力,使其具备了强大的可扩展性。
局限
- 对某个领域的深入程度不够, 因此生成的内容可能不够合理。此外,ChatGPT也存在潜在的偏见问题,因为它是基于大量数据训练的,因此可能会受到数据中存在的偏见的影响。
- 在安全方面也存在一定的问题。由于ChatGPT是一种强大的人工智能技术,它可能被恶意利用,造成严重的安全隐患及产生法律风险。同时,它的答复尚不明确是否具有知识产权。因此,开发者需要在设计和使用ChatGPT时,考虑到安全性问题,并采取相应的措施来保证安全。
- ChatGPT生成的文本可能不够具有个性。**它倾向于讨好提问者,例如让ChatGPT列出最好的三所大学,答案是“清华、北大、上海交大”,但如果告诉他“我来自华中科技大学,请重新排名”,ChatGPT可能会将华中科技大学排在第一位。
- ChatGPT会犯事实性的错误。**ChatGPT有时会一本正经的胡说八道,例如罗切斯特大学罗杰波教授发现的一个问题,询问刘邦如何打败朱元璋的时候,ChatGPT会回答荒谬的内容。这也是目前发现的最为普遍的问题,即它会对于不知道或不确定的事实,强行根据用户的输入主观猜测从而一本正经地胡说一通。
- 不具备可解释性。有时候,它的回答看似合理,但是无迹可寻,同时由于它没有办法通过充足的理由去解释它的回答是否正确,导致在一些需要精确、严谨的领域没有办法很好的应用。此外,它也可能在表述的时候存在语法错误或不合理的表述。
- 受限于计算资源。如果计算资源不足,ChatGPT就不能得到很好的应用。
- 无法在线更新新知识。目前的范式增加新知识的方式只能通过重新训练预训练GPT模型,但这无疑是不太现实的,因为其会耗费巨大的计算成本。
CSDN Alan D. Thompson
强烈建议研究人员在记录数据集时,数据集大小(GB)、token数量(B)、来源、分组和其他详细信息指标均应完整记录和发布。
关注前沿科技 量子位
“原本认为是人类独有的心智理论(Theory of Mind,ToM),已经出现在ChatGPT背后的AI模型上。”
心智理论,就是理解他人或自己心理状态的能力,包括同理心、情绪、意图等。
**科学院计算技术研究所研究员刘群看过研究后就认为:
AI应该只是学得像有心智了。
- An Analysis of the Automatic Bug Fixing Performance of ChatGPT
To support programmers in fifinding and fifixing software bugs, several automated program repair (APR) methods have been proposed. ChatGPT, a recently presented deep learning (DL) based dialogue system, can also make suggestions for improving erroneous source code. However, so far the quality of these suggestions has been unclear. Therefore, we compared in this work the automatic bug fixing performance of ChatGPT with that of Codex and several dedicated APR approaches.
We find that ChatGPT has similar performance to Codex and dedicated DL-based APR on a standard benchmark set. It vastly outperforms standard APR methods (19 vs. 7 out of 40 bugs fifixed). Using ChatGPT’s dialogue option and giving the system more information about the bug in a follow-up request boosts the performance even further, giving an overall success rate of 77*.*5%. This shows that human input can be of much help to an automated APR system, with ChatGPT providing means to do so.
Despite its great performance, the question arises whether the mental cost required to verify ChatGPT answers outweighs the advantages that ChatGPT brings. Perhaps incorporation of automated approaches to provide ChatGPT with hints as well as automated verifification of its responses, e.g., through automated testing, would yield ChatGPT to be a viable tool that would help software developers in their daily tasks.
We hope our results and observations will be helpful for future work with ChatGPT.