Основной источник - Том Уайт Hadoop: Подробное руководство. — СПб.: Питер, 2013. — 672 с.: ил. — (Серия «Бестселлеры O’Reilly»)
Hadoop - свободно распространяемый набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ обработки данных и хранения данных, работающих на кластерах из сотен и тысяч узлов.
Hadoop состоит из четырёх модулей:
- Hadoop Common - набор инфраструктурных программных библиотек и утилит, используемых для других модулей и родственных проектов
- HDFS - распределённая файловая система
- YARN - система для планирования заданий и управления кластером
- Hadoop MapReduce - платформа программирования и выполнения распределённых MapReduce-вычислений
MapReduce — это фреймворк для вычисления некоторых наборов распределенных задач с использованием большого количества компьютеров (называемых «узлами»), образующих кластер. Каждая фаза использует в качестве входных и выходных данных пары "ключ-значение".
Работа MapReduce состоит из двух шагов: Map (отображение) и Reduce(свертка).
На Map-шаге происходит предварительная обработка входных данных. Для этого один из компьютеров (называемый главным узлом — master node) получает входные данные задачи, разделяет их на части и передает другим компьютерам (рабочим узлам — worker node) для предварительной обработки.
На Reduce-шаге происходит свёртка предварительно обработанных данных. Главный узел получает ответы от рабочих узлов и на их основе формирует результат — решение задачи, которая изначально формулировалась.
Преимущество MapReduce заключается в том, что он позволяет распределенно производить операции предварительной обработки и свертки. Операции предварительной обработки работают независимо друг от друга и могут производиться параллельно (хотя на практике это ограничено источником входных данных и/или количеством используемых процессоров). Аналогично, множество рабочих узлов может осуществлять свертку — для этого необходимо только чтобы все результаты предварительной обработки с одним конкретным значением ключа обрабатывались одним рабочим узлом в один момент времени.
Задание (job) MR - еденица работы, которую хочет выполнить клиент. Состоит из входных данных, программы MR и конфигураций. Задание разбивается на задачи (tasks) отображения и свертки.
Узлы, управляющие процессом выполнения заданий, делятся на трекер заданий (jobtracker) и несколько трекеров задач (tasktrecker). Трекер заданий координирует все задачи, выполняемые системой и собирает отчеты с трекеров задач.
Входные данные заданий MR делятся на фрагменты фиксированной длины - сплиты (splits). Для каждого сплита применяется одна задача отображения. Задачи выполняются параллельно. Стандартный размер - 64 Мб.
Оптимизация локальности данных - по возможности задачи отображения выполняются на том узле, где хранится входная информация. После выполнения промежуточного этапа отображения данные сбрасываются на диск (HDFS), а затем передаются по сети при необходимости. Вывод задачи отображения хранится в локальной файловой системе узла для экономии места и времени (не реплицируется). Вывод свертки хранится в HDFS.
Помимо функций отображения и свертки можно задать промежуточную функцию - комбинирующую. Она выполняется для выходных данных отображения и подает свой вывод на вход функции свертки. Она может быть вызвана ноль, 1 или несколько раз (мы на это не влияем). Комбинирующую функцию нужно строить таким образом, чтобы вне зависимости от количества ее выполнений функция свертки давала одинаковый результат. (пример - локальное определение максмума в конце отображения для определения общего максимума на этапе свертки).
HDFS (Hadoop Distributed File System) — файловая система, предназначенная для хранения файлов больших размеров, поблочно распределённых между узлами вычислительного кластера. Все блоки в HDFS (кроме последнего блока файла) имеют одинаковый размер, и каждый блок может быть размещён на нескольких узлах, размер блока и коэффициент репликации (количество узлов, на которых должен быть размещён каждый блок) определяются в настройках на уровне файла. Благодаря репликации обеспечивается устойчивость распределённой системы к отказам отдельных узлов.
Особенности:
- Очень большие файлы - HDFS способна хранить петабайты данных
- Потоковый доступ к данным - в основу HDFS заложена концепция однократной записи и многократного чтения
- Обычное оборудование - HDFS не требует для своей работы особого оборудования высокой надежности
HDFS не предназначена для быстрого доступа к данным, так как она нацелена не на быстрый доступ, а на обеспечение высокой пропускной способности. Также она не предназначена для хранения большого количества мелких файлов (забивание памяти узла имен).
Файлы в HDFS могут быть записаны лишь однажды (модификация не поддерживается), а запись в файл в одно время может вести только один процесс. Организация файлов в пространстве имён — традиционная иерархическая: есть корневой каталог, поддерживается вложение каталогов, в одном каталоге могут располагаться и файлы, и другие каталоги.
Развёртывание экземпляра HDFS предусматривает наличие центрального узла имён (англ. name node), хранящего метаданные файловой системы и метаинформацию о распределении блоков, и серии узлов данных (англ. data node), непосредственно хранящих блоки файлов. Узел имён отвечает за обработку операций уровня файлов и каталогов — открытие и закрытие файлов, манипуляция с каталогами, узлы данных непосредственно отрабатывают операции по записи и чтению данных. Узел имён и узлы данных снабжаются веб-серверами, отображающими текущий статус узлов и позволяющими просматривать содержимое файловой системы. Административные функции доступны из интерфейса командной строки.
Secondary NameNode — 1 нода на кластер. Принято говорить, что «Secondary NameNode» — это одно из самых неудачных названий за всю историю программ. Действительно, Secondary NameNode не является репликой NameNode. Состояние файловой системы хранится непосредственно в файле fsimage и в лог файле edits, содержащим последние изменения файловой системы (похоже на лог транзакций в мире РСУБД). Работа Secondary NameNode заключается в периодическом мерже fsimage и edits — Secondary NameNode поддерживает размер edits в разумных пределах. Secondary NameNode необходима для быстрого ручного восстанавления NameNode в случае выхода NameNode из строя.
EdgeNode - точка доступа для внешний приложений (Hive, Pig, Oozie, etc.). Является пограничным интерфейсом между корпоративной сетью и кластером. Используется для запуска клиентский приложений и администрирования.
Основные команды HDFS
| Команда | Действие |
|---|---|
| hadoop fsck / -files /blocks | выводит список блоков, из которых состоит каждый файл в файловой системе |
| hadoop fs -copyFromLocal input/docs/quangle.txt /user/home/quangle.txt | копирование файла из локальной FS в HDFS |
| hadoop fs -mkdir books | создание директории books |
| hadoop fs -ls . | просмотр списка файлов |
| hadoop fs -du -s -h | просмотр списка файлов и каталогов и их размера |
| hadoop fs -rm -R books/ | удаление файлов (-R - удаление директории (рекурсивное удаление)) |
Подробнее - https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/FileSystemShell.html
Технология HDFS Federation - обеспечивает масштабирование кластера за счет добавления узлов имен, каждый из которых управляют частью пространства имен в файловой системе. (например отдельный узел имен для иерархии /user). Для работы с федерацией используется ViewFS. ViewFS - проект, предоставляющий способ управления несколькими пространствами имен HDFS. Это особенно полезно для кластеров, имеющих несколько неймнод.
В Hadoop 2.x+ используется поддержка высокой доступности (High Ability), которая заключается в использовании двух узлов имен в конфигурации "активный/резервный".
Целостность данных поддерживается за счет использования контрольных сумм при перемщении, записи и в фоновом режиме. При записи проверку можно отключить (например, для проверки поврежденного файла).
В Hadoop находятся ряд платформенных кодеков(gzip, bzip, snappy, LZO) для сжатия и восстановления данных. При необходимости можно их отключить и использовать кодеки Java (например, для отладки ошибок, связанных со сжатием), при помощи hadoop.native.lib=false. При необходимости можно задать сжатие данных в промежутке между этапами выполнения MR задания.
В Hadoop межпроцессорные взаимодействия между узлами системы реализуются с помощью механизма RPC (Remote Procedure Calls) - сериализация вызовов.
Apache Avro - система сериализации данных, работающая в Hadoop. Позволяет строить JSON схемы данных, и хранит сами данные в двоичном формате. Имеет поддрежку нескольких языков. Файл с данными содержит заголовок с метаданными, включая схему и маркер разделения. Файлы Avro поддерживают разбиение. Поддерживает эволюцию схем: схемы чтения могут отличаться от схемы записи, это позволяет добавлять/удалять поля.
SequenceFile - журнальный файл, хранящий данные типа ключ-значения в двоичном формате. Структура файла: заголовок, несколько записей, маркер, несколько записей, и т д. Запись состоит из значения длины записи, длины ключа, ключа и значения. Файл может сжиматься по зачениям или по блокам из нескольких записей сразу. MapFile - отсортированный объект SequenceFile (нарушение порядка при записи приводит к IOException).
В MapReduce существует усеченная сборка среды выполнения для тестирования на локальном компьютере. Особенность - выполнение только одной свертки (нет параллелизма). Устанавливается при помощи mapred.job.tracker=local, mapreduce.framework.name=local.
Apache Oozie - система управления операциями зависимых заданий. Состоит из ядра потока операций (workflow), запускающего задания различных типов (MR, Spark, Shell, Hive, etc.) и координатора, запускающего задания на основании заранее определенных расписаний и доступности данных. Работает в виде службы на кластере.
Workflow пишется на XML с использованием Hadoop Process Definition Language в виде ацикличного графа. ${wf.user()} - возвращает имя пользователя в worflow, это конструкция JSP Expression Language.
- Клиент с клиентской машины отправляет задание MapReduce.
- JobTracker принимает задание, получает входные сплиты из HDFS.
- Передача трекерам задач (TaskTracker) информации о задаче, выполнение на узлах трекеров задач с обращением к HDFS.
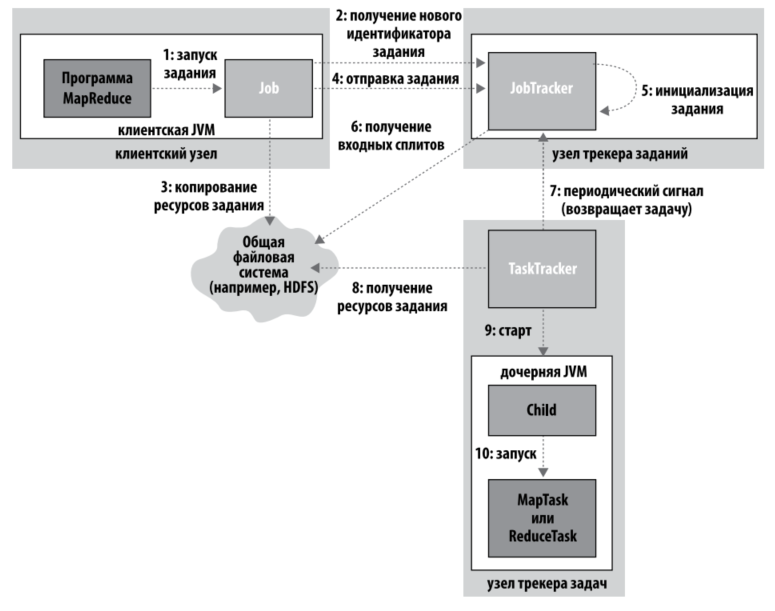
Обновление состояния Получение обратной связи о работе процесса. Каждая задача имеет состояние, состоящее из статуса, хода выполнения отображений и сверток, счетчика задания и сообщения или описания. Информация передается трекеру задач. Получение информации о прогрессе означает, что программа работает(сбой не произошел). Прогрессом считается: чтение, запись данных, назначение описания состояния, увеличение счетчика задания, вызов метода progress() объекта Reporter. Трекер заданий ежесекундно опрашивает трекер задач.
2010 год, "Yet Another Resource Negotiator" YARN решает проблемы масштабируемости. В MR 1 трекер заданий занимается как планированием заданий, так и отслеживанием прогресса (отслеживание, перезапуск упавших, учет счетчиков). YARN разделяет эти роли, поручая их двум независимым демонам: менеджер ресурсов и контроллер приложений. Контроллер приложений согласует использование ресурсов кластера с менеджером ресурсов; результаты согласования представляются в виде контейнеров, имеющих определенные ограничения по памяти, после чего процессы, зависящие от приложений, выполняются в этих контейнерах. За контейнерами наблюдают менеджеры узлов, работающие в узлах кластера; они следят за тем, чтобы приложение не использовало больше ресурсов, чем ему было выделено. Дополнительно в структуре присутствуют демон сервера истории заданий и службы обработчика тасовки.
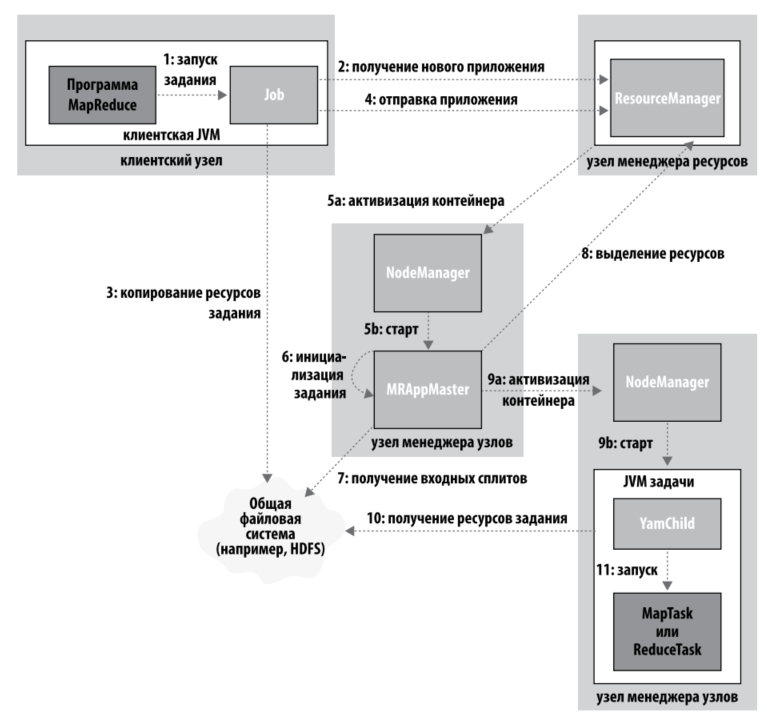
Этапы работы:
- Отправка задания MR с клиентской машин: полчение ResourceManager'ом задания, вычисление входных сплитов, копирование jar и конфигурации задания в HDFS
- Инициализация задания: менеджер ресурсов передает запрос планировщику, который выделяет контейнер, а менеджер ресурсов запускает процесс контроллера приложений (MRAppMaster) под управлением менеджера узлов. Контроллер приложений может запустить небольшое задание на той же VM Java, на которой работает он сам. Задание считается малым, если в нем менее 10 задач отображения, не более 1 задачи свертки, а объем данных меньше размера блока HDFS. В противном случае контроллер приложений обращается к менеджеру ресурсов контейнеры для задач отображения и свертки, с учетом локальности данных.
в YARN в отличие от MR1 управление ресурсами осуществляется более гранулированно. В MR1 трекеры задач имеют фиксированное количество слотов, в каждом может выполняться одна задача. в YARN приложения могут запросить блок памяти в диапазоне от минимального до максимального, кратно минимальному значению (по умолчанию от 1 до 10 гб с приращением 1 гб). 3. Выполнение задач. После того, как RM (ResourceManager) назначает задаче контейнер, контроллер приложений запускает контейнер на выполнение: для этого он связывается с менеджером узлов. Происходит локализация ресурсов, и происходит выполнение. Выполняется задача Java-приложением с главным классом YarnChild. Каждая задача работает в отдельной JVM.
- Обновление состояний. При работе задача передает информацию о своем прогрессе и состоянии своему контроллеру приложений, каждые 3 секунды. Клиент опрашивает контроллер приложений каждую секунду.
- Завершение заданий. Кроме периодических запросов к контроллеру приложений, клиент каждые пять секунд проверяет, не завершилось ли задание. Для этого он вызывает метод waitForCompletion() объекта Job. При завершении задания контроллер приложения и контейнеры задач удаляют свое рабочее состояние, после чего вызывается метод деинициализации объекта OutputCommitter. Информация о задании архивируется сервером истории заданий, где пользователи при желании смогут проанализировать ее.
Одно из важнейших достоинств Hadoop - способность выдерживать сбои, давая заданиям возможность завершиться. Различают 3 вида сбоев: сбой выполняемой задачи, сбой трекера задач и сбой трекера заданий. Сбой задачи: Наиболее частая причина - исключения и ошибки времени выполнения. В случае "зависания" - трекер задач отмечает, что он давно не получал обновлений информации о прогрессе, и переходит к пометке задачи как сбойной. По истечении срока mapred.task.timeout (по умолчанию 10 минут) дочерний процесс JVM будет автоматически уничтожен. Отключать тайм-аут не рекомендуется. Зависшие роцессы Streaming и Pipes накапливаются и снижают производительность системы, за исключением установки контроллера приложений LinuxTaskController или DefaukltTaskController, и в системе доступна команда setsid system.
Получив опопвещение о сбое трекер заданий заново планирует выполнение задачи, при чем по возможности на другом узле. Количество попыток задается конфигурациями mapred.map.max.attempts (по умолчанию 4). В случае отказа всех четырех попыток сбойным считается само задание.
Возможно установить параметр, при котором задание не будет считаться сбойным, даже если не отработал некоторый процент задач (mapred.max.map.failures.percent и mapred.max.reduce.failures.percent). Сбой трекера задач: Если на трекере происходит сбой, он перестает передавать сигналы трекеру заданий (10 минут, mapred.tasktracker.expiry.interval). В этом случае трекер заданий исключает этот трекер из пула, на котором планируется выполнение задач. Трекер заданий организует повторное выполнение задач. Трекер заданий может пометить трекер задач неисправным, если сбои на нем происходят значительно чаще остальных трекеров. Таким трекерам задач не назначаются задачи, он может начать работу при аннулировании числа ошибок (-1 в день). Сбой трекера заданий: Сбой трекеров заданий - самая серьезная категория сбоев. В Hadoop не существует механизма преодоления сбоев трекеров заданий, так что в этом случае все задания становятся сбойными. После перезапуска трекера заданий все задания, выполнявшиеся на моменто остановки, должны быть отправлены заново. Существует конфигурация автоматического перезапуска (mapred.jobtracker.restart.cover), но она работает недостаточно надежно и использовать ее не рекомендуется.
Сбой задачи Сбой выполняемой задачи сходен с классическим случаем. Информация об ошибках и исключениях передается контроллеру приложений, попытка выполнения помечается как сбойная. Аналогичным образом контроллер приложений узнает о зависании (mapreduce.task.timeout). Как и в классическом случае задача считается сбойной в случае 4 отказов (mapred.map.max.attempts)Возможно установить параметр, при котором задание не будет считаться сбойным, даже если не отработал некоторый процент задач (mapred.max.map.failures.percent и mapred.max.reduce.failures.percent). Сбой контроллера приложений По аналогии с классический моделью, дающей задачам несколько попыток успешного выполнения, приложения YARN тоже несколько раз проверяются на сбои. По умолчанию приложения помечаются сбойными в случае однократного сбоя (yarn.resourcemanager.am.max-retries). Контроллер приложений периодически отправлят сигналы менеджеру ресурсов; в случае сбоя менеджер ресурсов обнаруживает его и запускает новый экземпляр контроллера в новом контейнере (находящемся под управлением менеджера узлов). Контроллер приложений может восстановить состояние задач, уже запущенных сбойным приложением, но по умолчанию эта функция отключена - новый контроллер заново запустит задачи (yarn.app.mapreduce.am.job.recovery.enable). При обращении клиента к контроллеру приложений для отслеживания прогресса выполнения, в случае сбоя клиент сначала обратится к менеджеру ресурсов для получения адреса нового контроллера приложений. Сбой менеджера узлов Если сбой происходит на менеджере узлов, то он перестает отправлять периодические сигналы менеджеру ресурсов и исключается из пула доступных узлов последнего. Время промежутка - yarn.resourcemanager.nm.liveless-monitor.expiry-interval-ms (по умолчанию 600 000). Сбой менеджера ресурсов Сбой менеджера ресурсов приводит к серьезным последствиям. После сбоя запускается новый экземпляр менеджера ресурсов(вручную), который восстанавливает состояние из контрольной точки. Механизм хранения контрольной точки устанавливается в yarn.resourcemanager.store.class и по умолчанию работает с org.apache.hadoop.yarn.server.rosurcemanager.recovery.MemStore, что не является особо надежным. В новых версиях система хранения работает на базе ZooKeeper, что обеспечивает более надежное восстановление. /* Раздел не полный */
В ранних версиях Hadoop использовалась система FIFO. Впоследствии было добавлено свойство mapred.job.priority, но FIFO-планировщик не имел возможности вытеснения (высокоприоритетные задачи все равно ждут окончания низкоприоритетных, запущенных ранее). Многопользовательские планировщики: Fair Scheduler: Планировщик Fair Scheduler стремится выделить каждому пользователю справедливую долю кластерной мощности. Задания поещаются в пулы - по одному на пользователя. Пользователь, отправивший больше заданий, в среднем не получит больше ресурсов. Можно выставлять минимальные значения и веса для пулов. Планировщик поддерживает вытеснение. Capacity Scheduler: Кластер образуется из нескольких очередей (по аналогии с Fair Scheduler), которые могут составлять иерархию. В каждой очереди задания планироются по FIFO с приоритетами.
MapReduce гарантирует, что входные данные каждой задачи свертки отсортированы по ключу. Процесс выполнения сортировки при передачи на вход сверток называется shuffle, или тасовкой.
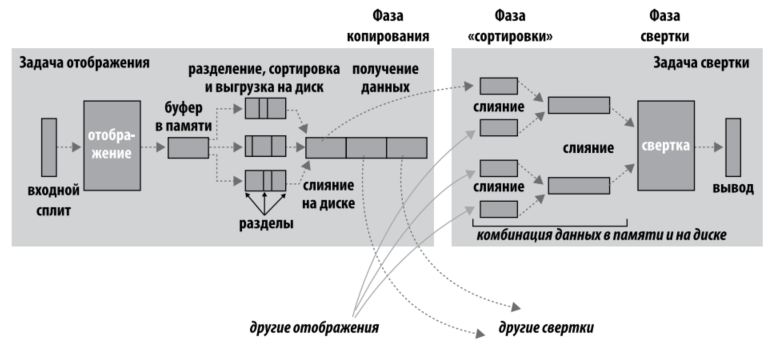
На стороне отображения имеется буфер (100 Мб по умолчанию), куда записываются выходные данные. После заполнения (80% по умолчанию) буфера происходит сброс данных на диск в файл. К этим файлам может применятся комбинирующая функция. После завершения вывода всех записей в файлы, эти файлы объединяются в один отсортированный файл. К выходным данным можно применять сжатие. Передача файлов к этапу свертки осуществляется по HTTP.
Свертка начинается с фазы копирования выходных файлов отображения с тех машин, на которых они были созданы. Эти данные загружаются параллельно (по умолчанию пять - mapred.reduce.parallel.copies). Как задачи свертки узнают, на каких машинах находятся данные отображения? Успешно завершенные задачи оповещают родительский трекер задач (контроллер приложений в MR 2). Таким образом, для конкретного задания трекер заданий (контроллер приложений) располагает информацией о соответствии между выходными данными отображения и хостами. Программнйы поток свертки периодически запрашивает у контроллера данные хстов, пока не получит их все. Хосты отображений не удаляют данные с диска сразу после их получения сверткой, так как во время свертки может произойти сбой. Вместо этого они ждут команды от трекера заданий (контроллера приложений), которая поступит после завершения задания.
Выходные данные отображений копируются в память JVM, если они достаточно малы (mapred.job.shuffle.input.buffer.percent), либо на диск. Когда буфер в памяти достигает порогового размера (mapred.job.shuffle.merge.percent) или достигает порогового числа выводов отображений (mpared.inmem.merge.threshold) происходит слияние данных и выгрузка результата на диск. Если комбинирующая функция задана, она выполняется во время слияния для сокращения объема данных, записываемых на диск.
Когда все выходные файлы отображения будут скопированы, задача свертки переходит в фазу сортировки (фазу слияния). В этой фазе происходит слияение выходных данных отображения с сохранением порядка сортировки. Слияние выполняется в несколько раундов, количество которых зависит от количества файлов и коэффициента слияния (по усолчанию 10, io.sort.factor). Например, для 50 файлов с коэффициентом 10 будет 5 раундов. Вместо выполнения последнего раунда, в котором эти 5 файлов будут слиты в один отсортированный файл, процесс слияния избегает лишнего обращения к диску, напрямую передавая данные функции свертки. Передача данных составляет последнюю фазу: фазу свертки. Данные для завершающего слияния могут храниться как в памяти, так и в сегментах на диске.
Количество файлов, подвергаемых слиянию в каждом раунде, не настолько тривиально, как в приведенном примере. Целью является слияние минимального количества файлов для достижения заданного коэффициента слияния к последнему раунду. Таким образом, для 40 файлов слияние не будет объединять по 10 файлов в 4 раунда, чтобы получить 4 файла. Вместо этого за первый раунд будут объединены только 4 файла, а в последующие три — по 10 файлов. 4 слитых файла и 6 (еще не слитых) составляют 10 файлов для последнего раунда. Это оптимизация, минимизирующая объем данных, записываемых на диск, потому что результаты слияния в последнем раунде всегда передаются напрямую свертке.
В фазе свертки функция свертки вызывается для каждого ключа в отсортированных выходных данных. Выходные данные этой фазы записываются непосредственно в выходную файловую систему, чаще всего в HDFS. В случае HDFS, поскольку трекер задач (или менеджер узлов) совмещен с узлом данных, первая реплика блока будет записана на локальный диск.
Общий принцип заключается в том, чтобы предоставить тасовке как можно больше памяти. Однако при этом также необходимо позаботиться и о том, чтобы у функций отображения и свертки тоже было достаточно памяти для работы. Вот почему следует писать функции отображения и свертки так, чтобы они использовали как можно меньше памяти — и уж конечно, они не должны использовать неограниченный объем памяти (например, при накоплении значений в ассоциативном массиве).
Объем памяти, выделяемой JVM, в которой работают задачи отображения и свертки, задается свойством mapred.child.java.opts. Постарайтесь сделать его как можно больше, чтобы максимизировать объем памяти узлов задач.
На стороне отображения лучшая производительность достигается предотвращением множественных выгрузок на диск; оптимальное количество — одна выгрузка.
Если вы можете оценить размер выходных данных отображений, задайте свойства io.sort.* так, чтобы свести к минимуму количество выгрузок. В частности, постарайтесь увеличить io.sort.mb, если это возможно. В MapReduce имеется счетчик для подсчета общего количества записей, выгруженных на диск в процессе задания. Он может помочь при настройке. Учтите, что в счетчик включаются выгрузки как на стороне отображения, так и на стороне свертки.
На стороне свертки наилучшая производительность достигается в том случае, если промежуточные данные находятся полностью в памяти. По умолчанию это не делается, потому что вся память резервируется для функции свертки. Но если функция свертки предъявляет малые требования к памяти, задайте mapred.inmem.merge.threshold значение 0, а mapred.job.reduce.input.buffer.percent значение 1.0. Возможно, это обеспечит прирост производительности.
Hadoop по умолчанию использует размер буфера 4 Кбайт. В общем случае этого мало, и размер буфера для кластера стоит увеличить (при помощи свойства io.file.buffer.size.
Из-за параллельного выполнения задач время выполнения задания зависит от медленных задач. Если задание состоит из сотен и тысяч задач, вероятность появления медленных задач становится более чем реальной.
Задачи могут выполняться медленно по разным причинам, включая аппаратную деградацию и неправильную конфигурацию ПО. Hadoop старается определить какая задача выполняется медленнее ожидаемого, и запускает другую эквивалентную задачу в качестве резервной. Этот метод называется спекулятивным выполнением задач.
Важно понять, что спекулятивное выполнение не сводится к запуску двух дубликатов более или менее одновременно, чтобы они могли конкурировать друг с другом. Такой подход был бы расточительной тратой ресурсов кластера. Спекулятивная задача запускается только после запуска всех задач, входящих в задание, и только для задач, которые проработали некоторое время (не меньше минуты), но в отношении прогресса в среднем отстали от других задач. Когда задача завершается успешно, все выполняемые дубликаты уничтожаются. Итак, если исходная задача завершается раньше спекулятивной, то уничтожается спекулятивная задача; если же первой завершится спекулятивная задача, то уничтожается исходная задача.
Спекулятивное выполнение — оптимизация, а не механизм повышения надежности выполнения заданий. Если в коде присутствуют ошибки, иногда приводящие к «зависанию» или замедлению выполнения задачи, не стоит рассчитывать на то, что спекулятивное выполнение поможет обойти эти проблемы; скорее всего, те же ошибки проявятся и в спекулятивной задаче.
Спекулятивное выполнение включено по умолчанию. Его можно включать или отключать независимо для задач отображения или задач свертки, на уровне кластера или на уровне задания (mapred.map.tasks.speculative.execution, mapred.reduce.tasks.speculative.execution).
Когда отключается спекулятивное выполнение? Его целью является сокращение времени выполнения заданий, но за это приходится расплачиваться эффективностью кластера. В занятом кластере спекулятивное выполнение сокращает общую пропускную способность. Существуют веские доводы в пользу отключения спекулятивного выполнения для задач свертки, поскольку каждый дубликат задач свертки должен получать те же выходные данные отображений, что и исходная задача, а это приводит к существенному повышению сетевого трафика в кластере.
Также отключение спекулятивного выполнения имеет смысл для задач, не обладающих свойством идемпотентности (возврат одинакового результата при повторном выполнении).
Hadoop MapReduce использует протокол закрепления (commit), гарантирующий, что задания и задачи либо завершаются успешно, либо корректно отрабатывают сбой. Поведение реализуется реализацией OutputCommitter, используемой для задания.
public abstract class OutputCommitter {
public abstract void setupJob(JobContext jobContext) throws IOException;
public void commitJob(JobContext jobContext) throws IOException { }
public void abortJob(JobContext jobContext, JobStatus.State state) throws IOException { }
public abstract void setupTask(TaskAttemptContext taskContext) throws IOException;
public abstract boolean needsTaskCommit(TaskAttemptContext taskContext) throws IOException;
public abstract void commitTask(TaskAttemptContext taskContext) throws IOException;
public abstract void abortTask(TaskAttemptContext taskContext) throws IOException;
}
Метод setupJob() вызывается перед запуском задания; обычно он используется для выполнения инициализации. Для FileOutputCommitter метод создает каталог выходных данных ${mapred.output.dir} и временное рабочее пространство для вывода задач ${mapred.output.dir}/_temporary.
Если задание завершается успешно, вызывается метод commitJob(), который в файловой реализации по умолчанию удаляет временное рабочее пространство и создает в каталоге выходных данных пустой скрытый файл-маркер с именем _SUCCESS, присутствие которого сообщает клиентам файловой системы об успешном завершении задания. Если задание не завершилось успешно, вызывается метод abortJob() с объектом состояния, указывающим, произошел ли в задании сбой или оно было уничтожено (пользователем, например). В реализации по умолчанию при этом удаляется временное рабочее пространство задания.
Операции на уровне задач выглядят аналогично. Метод setupTask() вызывается перед выполнением задачи; реализация по умолчанию не делает ничего. Фаза закрепления для задач не является обязательной; ее можно отключить, вернув false из needsTaskCommit(). В этом случае инфраструктура не выполняет для задачи протокол распределенного закрепления, и ни один из методов commitTask() и abortTask() не вызывается. FileOutputCommitter пропускает фазу закрепления, если задача не записала никакие выходные данные.
В случае успешного выполнения вызывается метод commitTask(), который в реализации по умолчанию перемещает временный каталог выходных данных задачи (в имени которого содержится идентификатор попытки задачи, чтобы предотвратить возможные конфликты между попытками) в итоговый выходной каталог ${mapred.output.dir}. В противном случае инфраструктура вызывает метод abortTask(), который удаляет временный каталог выходных данных задачи.
Инфраструктура гарантирует, что в случае нескольких попыток выполнения конкретной задачи закреплена будет только одна попытка; остальные попытки отменяются. Такая ситуация может возникнуть из-за того, что первая попытка по какой-то причине оказалась сбойной — тогда она отменяется, а закрепляется другая, успешная попытка. Также возможна ситуация, при которой две попытки выполняются параллельно как спекулятивные дубликаты; в этом случае попытка, завершившаяся первой, будет закреплена, а другая попытка отменится.
Обычным способом записи выходных данных задачами отображения и свертки является накопление пар «ключ-значение» с использованием OutputCollector. Некоторым приложениям требуется бˆольшая гибкость, чем модель пар «ключзначение», поэтому такие приложения записывают выходные файлы прямо из задач отображения или свертки в распределенную файловую систему — например, в HDFS.
Необходимо проследить за тем, чтобы множественные экземпляры одной задачи не пытались выполнять запись в один файл. Как было показано в предыдущем разделе, протокол OutputCommitter решает эту проблему. Если приложения записывают файлы побочных эффектов (side-effect files) в рабочие каталоги своих задач, то побочные файлы успешно завершенных задач будут автоматически переведены в выходной каталог, а побочные файлы сбойных задач удаляются.
Задача может определить свой рабочий каталог, прочитав значение свойства mapred.work.output.dir из своего файла конфигурации. Кроме того, программа MapReduce, использующая Java API, может вызвать статический метод getWorkOutputPath() класса FileOutputFormat для получения объекта Path, представляющего рабочий каталог. Инфраструктура создает рабочий каталог перед выполнением задачи, так что вам его создавать не обязательно.
Повторное использование JVM в настоящее время не поддерживается в MapReduce 2. При помощи mapred.job.reuse.jvm.num.tasks в MR 1 можно было задать максимальное количество задач, которые могут выполняться для одной JVM трекера задач. Это позволяет сократить время выполнения задачи за счет отсутствия создания новой JVM (около секунды). Оптимизация применяется в случае коротковременных задач, где секунда играет большое значение.
Большие наборы данных редко бывают идеальными. В них часто встречаются поврежденные записи. В них встречаются записи, хранимые в другом формате. В них часто встречаются пропущенные поля. В идеальном мире ваш код будет корректно обрабатывать все перечисленные ситуации. На практике часто бывает разумнее проигнорировать записи-нарушители. В зависимости от выполняемого анализа, если проблемы встречаются только в малом проценте записей, пропуск этих записей вряд ли значительно повлияет на результат. Но если задача, столкнувшись с некорректной записью, выдает исключение времени выполнения — происходит сбой. Трекер заданий пытается снова выполнить сбойные задачи (так как сбой может быть обусловлен аппаратным отказом или другой причиной, неподконтрольной для задачи), но в случае четырехкратного сбоя все задание помечается как сбойное.
При использовании TextInputFormat можно задать максимальную ожидаемую длину строки, чтобы в определенной степени защититься от некорректных данных.
Вы можете обнаружить некорректную запись и проигнорировать ее или же аварийно завершить задание с выдачей исключения. Также можно подсчитать общее количество некорректных записей в задании при помощи счетчиков, чтобы понять, насколько распространена проблема.
В отдельных случаях проблема оказывается неразрешимой из-за ошибки в сторонней библиотеке, которую не удается обойти в коде отображения или свертки. В таких случаях можно воспользоваться режимом автоматического пропуска некорректных записей Hadoop (В новой версии API этот режим не поддерживается!). В режиме пропуска (skipping mode) задачи передают информацию об обрабатываемых записях трекеру задач. При сбое задачи трекер задач пытается снова выполнить ее, пропуская записи, вызвавшие сбой. Из-за дополнительного сетевого трафика и необходимости хранения служебной информации о диапазонах некорректных записей режим пропуска включается для задачи только после двукратного сбоя.
Итак, для задачи, у которой стабильно происходит сбой на некорректной записи, трекер задач выполняет следующие попытки со следующими результатами:
- Сбой задачи.
- Сбой задачи.
- Включение режима пропуска. В задаче снова происходит сбой, но сбойная запись сохраняется трекером задач.
- Режим пропуска остается включенным. Задача пропускает некорректную запись, приведшую к сбою на предыдущей попытке, и успешно работает.
Режим пропуска отключен по умолчанию; он включается независимо для задач отображения и свертки при помощи класса SkipBadRecords. Следует помнить, что режим пропуска способен обнаруживать только одну некорректную запись на попытку выполнения задачи, поэтому этот механизм подходит только для обнаружения относительно редких некорректных записей (в количестве, скажем, нескольких на задачу). Возможно, стоит увеличить максимальное количество попыток (свойства mapred.map.max.attempts и mapred.reduce.max.attempts), чтобы предоставить режиму пропуска достаточно попыток для обнаружения и пропуска всех некорректных записей во входном сплите.
Некорректные записи, обнаруженные Hadoop, сохраняются в виде последовательных файлов в подкаталоге _logs/skip выходного каталога задания. Файлы можно просмотреть для диагностических целей после завершения задания (например, с использованием команды hadoop fs -text)
MapReduce реализует простую модель обработки данных: входные и выходные данные функций отображения и свертки представляют собой пары «ключ-значение». Рассмотрим возможности использования в ней данных разных форматов, от простого текста до структурированных двоичных объектов.
Общая схема отображений, сверток и комбинирующих функций: map: (K1, V1) → list(K2, V2) combine: (K2, list(V2)) → list(K2, V2) reduce: (K2, list(V2)) → list(K3, V3)
подробное описание сигнатур и типов данных смотрите в книге на с. 296
По умолчанию в Hadoop используется одна задача свертки, и это обстоятельство часто сбивает с толку новых пользователей. Почти во всех реальных задачах количество сверток следует увеличить; в противном случае задание будет работать очень медленно, так как все промежуточные данные будут проходить через одну задачу свертки. (Учтите, что при запуске под управлением локального исполнителя заданий поддерживается только нуль или одна задача свертки.)
Оптимальное количество сверток связано с общим количеством разрешенных слотов свертки в вашем кластере. Общее количество слотов вычисляется умножением количества узлов в кластере на количество слотов в одном узле (которое определяется значением свойства mapred.tasktracker.reduce.tasks.maximum).
На практике часто используется количество сверток, немногим меньшее общего количества слотов; в этом случае выполнение задач свертки образует одну «волну» (а несколько сбоев не приводят к увеличению общего времени выполнения задания). Если задачи свертки очень велики, можно увеличить количество сверток (например, для выполнения в две «волны»), чтобы задачи стали более детализированными, а сбои не оказывали значительного влияния на время выполнения задания.
Hadoop может обрабатывать разные типы форматов данных, от неструктурированных текстовых файлов до баз данных.
Как уже упоминалось, входной сплит представляет собой фрагмент входных данных, обрабатываемый одной задачей отображения. Каждое отображение обрабатывает один сплит. Сплит делится на записи, отображение поочередно обрабатывает каждую запись — пару «ключ/значение». Сплиты и записи определяются на логическом уровне: скажем, ничто не требует их привязки к файлам, хотя такое воплощение и является самым распространенным. В контексте базы данных сплит может соответствовать диапазону строк из таблицы, а запись — одной строке этого диапазона (именно это делает DBInputFormat, входной формат для чтения данных из реляционной базы данных). Входные сплиты представлены классом Java InputSplit (входит в пакет org.apache.hadoop.mapreduce).
С InputSplit связана длина в байтах и набор мест хранения данных, которые представляют собой обычные строки с именами хостов. Сплит не хранит входные данные; это всего лишь ссылка на них. Информация о местах хранения используется системой MapReduce для размещения задач отображения как можно ближе к данным сплита, а размер используется для упорядочения сплитов, чтобы самые большие обрабатывались в первую очередь для минимизации времени выполнения задания.
InputFormat отвечает за создание входных сплитов и разбиение их на записи. Прежде чем переходить к конкретным примерам InputFormat, давайте кратко рассмотрим использование этого класса в MapReduce. Он состоит из метода getSplits, который возвращает список сплитов, и метода CreateRecordReader. Клиент, запускающий задание, вычисляет сплиты вызовом getSplits() и передает их трекеру задач. Трекер использует информацию о местах хранения данных для планирования задач отображения, которые будут обрабатвыать их на трекерах задач. На трекере задач задача отображения передает сплит методу createRecordReader() объекта InputFormat, чтобы получить объект RecordReader для этого сплита. По сути, RecordReader представляет собой обычный итератор для перебора записей.
FileInputFormat — базовый класс для всех реализаций InputFormat, использующих файлы в качестве источника данных. Он предоставляет место для определения файлов, включаемых в качестве входных данных задания, и реализацию генерирования сплитов для входных файлов. Разбиение сплитов на записи выполняется субклассами.
Входные данные задания задаются набором путей, что позволяет чрезвычайно гибко ограничивать входные данные задания. Путь может представлять файл, каталог или при использовании метасимволов — набор файлов и каталогов. Путь, представляющий каталог, включает в себя все файлы этого каталога как входные данные для задания. Содержимое каталога, заданного в качестве входного пути, не обрабатывается рекурсивно. Более того, каталог должен содержать только файлы. Если в нем содержится подкаталог, то последний будет интерпретирован как файл, что приведет к ошибке. В таких случаях следует использовать файловый шаблон или фильтр, выбирающий только файлы из каталога. Также можно задать свойству mapred.input.dir.recursive значение true, чтобы входной каталог читался в рекурсивном режиме. FileInputFormat использует фильтр по умолчанию, который исключает скрытые файлы (с именами, начинающимися с точки или символа подчеркивания). Можно задавать собственные фильтры для файлов. Пути и фильтры также могут настраиваться свойствами конфигурации (mapred.input.dir).
FileInputFormat разбивает только большие файлы (то есть файлы, размер которых превышает размер блока HDFS). Размер сплита обычно совпадает с размером блока HDFS, для большинства приложений это нормально; однако этим значением можно управлять при помощи различных свойств Hadoop.
Минимальный размер сплита обычно составляет 1 байт, хотя у некоторых форматов устанавливается другая граница. Максимальный размер сплита по умолчанию равен максимальному значению, которое может быть представлено типом Java long. Значение действует только в том случае, если оно меньше размера блока. По умолчанию minimumSize < blockSize < maximumSize.
Hadoop лучше работает с небольшим количеством больших файлов, чем с множеством мелких. Одна из причин заключается в том, что FileInputFormat генерирует сплиты так, что каждый сплит занимает весь файл или его часть. Ситуацию несколько разряжает класс CombineFileInputFormat, спроектированный для эффективной работы с малыми файлами. Если FileInputFormat создает по одному сплиту на файл, CombineFileInputFormat упаковывает много файлов в один сплит, чтобы у каждой задачи отображения было больше данных для обработки. Важно то, что CombineFileInputFormat учитывает локальность узлов и сегментов при принятии решений о том, какие блоки должны размещаться в одном сплите, поэтому по скорости обработки входных данных не уступает типичному заданию MapReduce.
Конечно, сценария с множеством малых файлов следует по возможности избегать, потому для MapReduce критична скорость передачи данных дисков в кластере, а обработка множества малых файлов увеличивает количество операций позиционирования, необходимых для запуска задания. Кроме того, хранение большого количества малых файлов в HDFS неэффективно расходует память узла имен.
Класс CombineFileInputFormat хорошо работает не только с малыми файлами; при обработке больших файлов он тоже полезен. По сути, CombineFileInputFormat отделяет объем данных, потребляемых задачей отображения, от размера файлового блока в HDFS. Если ваши отображения способны обработать блок за считанные секунды, вы можете использовать CombineFileInputFormat с максимальным размером сплита, кратным числу блоков (для чего свойству mapred.max.split. size задается значение в байтах), чтобы каждая задача отображения обрабатывала более одного блока.
В некоторых приложениях лучше запретить разбиение файлов, так как это позволит одной задаче отображения полностью обработать каждый входной файл. Например, чтобы проверить, отсортированы ли все записи в файле, можно просто перебрать записи по порядку и убедиться в том, что каждая запись не меньше предыдущей.
Для обработки всего файла как записи используется WholeFileRecordReader. Он отвечает за получение объекта FileSplit и преобразование его в одну запись с пустым ключом и значением, состоящим из байтов файла. При этом разбиение файла запрещается.
Hadoop показывает выдающиеся результаты в обработке неструктурированного текста. В этом разделе рассматриваются разновидности InputFormat, предоставляемые Hadoop для обработки текста.
TextInputFormat — формат входных данных, используемый по умолчанию. Каждая запись представляет собой текстовую строку. Ключ (LongWritable) определяет смещение начала строки в файле (в байтах). Значение представляет собой содержимое строки, за исключением всех завершителей строк (например, символы новой строки или возврата курсора), упакованное в объект Text.
Разумеется, ключи не являются номерами строк. Этот вариант в общем случае не реализуем, потому что файл разбивается на сплиты по байтам, а не по границам строк. Сплиты обрабатываются независимо друг от друга. Строки подсчитываются по мере обработки, так что определить номер строки можно в сплите, но не в файле. Однако смещение каждой строки в файле известно каждому сплиту независимо от других сплитов, так как каждый сплит знает размер предшествующих сплитов и просто суммирует их со смещениями для определения глобального смещения в файле. Обычно такого смещения достаточно для приложений, в которых необходим уникальный идентификатор для каждой строки. Его комбинация с именем файла уникальна в пределах файловой системы. Конечно, если все строки имеют фиксированную длину, вычисление номера строки сводится к простому делению смещения на длину.
Связь между входными сплитами и блоками HDFS: Логические записи, определяемые FileInputFormat, редко аккуратно укладываются в блоки HDFS. Например, для TextInputFormat логические записи представляют собой строки, которые сплошь и рядом пересекают границы HDFS. На функционировании вашей программы это обстоятельство не отразится — строки не пропускаются, не распадаются и т. д. Однако это обстоятельство следует учитывать, потому что из него следует, что отображения, локальные по данным (то есть отображения, выполняемые на хосте, на котором хранятся их входные данные), будут выполнять удаленное чтение. Небольшие затраты ресурсов, связанные с этим, обычно несущественны.
Ключи TextInputFormat, являющиеся простыми смещениями в файле, обычно не слишком полезны. Часто каждая строка в файле содержит пару «ключ-значение», между которыми находится разделитель (например, символ табуляции). Именно такой вывод производит TextOutputFormat, используемая в Hadoop по умолчанию версия OutputFormat. Для правильной интерпретации таких файлов KeyValueTextInputFormat подойдет. Разделитель задается при помощи свойства mapreduce.input.keyvaluelinerecordreader.key.value.separator.
С форматами TextInputFormat и KeyValueTextInputFormat каждому отображению выделяется переменное количество строк исходных данных. Количество зависит от размера сплита и длины строк. Если вы хотите, чтобы отображениям выделялось фиксированное количество строк, используйте формат NLineInputFormat. Как и с TextInputFormat, ключи содержат смещения внутри файла в байтах, а значения — сами строки.
Под «N» в имени подразумевается количество строк входных данных, выделяемых каждому отображению При N=1 (по умолчанию) каждому отображению выделяется ровно одна строка входных данных. Значением N управляет свойство mapreduce.input.lineinputformat.linespermap.
Обычно выделение отображения для малого количества строк неэффективно. Пример возможного эффективного использования - компьютерные модели.
Парсеры XML обычно работают с целыми документами, и, если большой документ XML состоит из нескольких входных сплитов, с разбором их по отдельности возникнут сложности. Конечно, можно обработать весь документ XML (если он не слишком велик) в одном отображении, использовав приемы из раздела «Обработка всего файла как записи». Большие документы XML, состоящие из серии «записей» (фрагментов XML), можно разбить на записи, использовав простой поиск строк или регулярные выражения для определения начальных и конечных тегов. Это облегчает проблему при разбиении документа инфраструктурой, потому что следующий начальный тег записи легко находится простым сканированием от начала сплита — подобно тому, как TextInputFormat находит границы новых строк. Для этой цели в Hadoop включен класс StreamXmlRecordReader.
Технология Hadoop MapReduce не ограничена обработкой текстовых данных. В ней также поддерживаются и двоичные форматы.
В формате последовательных файлов Hadoop хранятся последовательности двоинчых пар «ключ-значение». Последовательные файлы хорошо подходят для данных MapReduce — они поддерживают разбиение (наличие точек синхронизации позволяет синхронизироваться с границами записей из произвольной позиции файла — например, от начала сплита), они поддерживают сжатие как часть формата, а также позволяют сохранять произвольные типы с использованием различных сред сериализации.
Чтобы использовать данные из последовательных файлов в качестве входных данных MapReduce, следует выбрать формат SequenceFileInputFormat. Ключи и значения определяются последовательным файлом, а вы должны позаботиться о соответствии входных типов отображений. SequenceFileInputFormat может читать не только последовательные файлы, но и объекты MapFile.
SequenceFileAsTextInputFormat — разновидность SequenceFileInputFormat, преобразующая ключи и значения последовательного файла в объекты Text. Преобразование выполняется вызовом toString() для ключей и значений. В этом формате последовательные файлы могут использоваться в качестве входных данных для Streaming.
SequenceFileAsBinaryInputFormat — разновидность SequenceFileInputFormat, получающая ключи и значения последовательного файла в виде неструктурированных двоичных объектов. Они инкапсулируются в объектах BytesWritable, а приложение может интерпретировать нижележащий байтовый массив так, как считает нужным. Это открывает возможность использования с MapReduce двоичных типов данных (упакованных в последовательные файлы), хотя существует и более элегантная альтернатива — подключение к механизму сериализации Hadoop.