cyq.data is not only a orm,but also a data access layer,it's very special and different from others,who use who love it.
Demo(入门教程):https://github.com/cyq1162/CYQ.Data.Demo
开篇介绍:http://www.cnblogs.com/cyq1162/p/5634414.html
更多文章:http://www.cnblogs.com/cyq1162/category/852300.html
QQ群:6033006
VIP培训课程,精通系列视频,300元/套,(共18集,每集1小时左右),可群里联系作者购买!
CYQ.Data 最近汇总了一下教程,放个人微信公众号里了,有需要的在公众号里输入cyq.data就可以看到了

注意事项:
1:MySQL 5.7.9版本需要把用命令行设置: 执行SET GLOBAL sql_mode = ''; 把sql_mode 改成非only_full_group_by模式。验证是否生效 SELECT @@GLOBAL.sql_mode 或 SELECT @@sql_mode
随着CYQ.Data 开始回归免费使用之后,发现用户的情绪越来越激动,为了保持这持续的激动性,让我有了开源的念头。
同时,由于框架经过这5-6年来的不断演进,以前发的早期教程已经太落后了,包括使用方式,及相关介绍,都容易引人误解。
为此,我打算重新写个系列来介绍最新的版本,让大伙从传统的ORM编程过渡到自动化框架型思维编程(自已造的词)。
于是:这个新系列的名称就叫:CYQ.Data 从入门到放弃ORM系列
1:它是一个ORM框架。
2:它是一个数据层组件。
3:它是一个工具集类库。
下面看一张图:

从上面的图可以看出,它已不仅仅是一个ORM,还附带一些带用功能。
因此:
写日志:你不再需要:Log4net.dll
操作Json:你不再需要newtonjson.dll
分布式缓存:你不再需要Memcached.ClientLibrary.dll
目前框架只有340K,后续版本将没有混淆工作,体积将更小一些。
看一张千篇一律的发展趋势图:

在开源**里搜.NET系的:ORM,数量有110左右,在CodeProject里搜.NET系的:ORM,数量有530左右。
经过大量的查看,很容易就发现,市场上的ORM都几乎一样,唯一不同的:
就是在自定义查询语法,每家都在玩自己的花样,而且必须玩的与众不同,不然大伙都一个样,显示不出优越感。
同时这种各式各样无厘头的查询语法糖,也浪费了不少开发人员的时间,因为学习的成本是要看一本书或一个从入门到精通系列。
综合看来,能跳出这个趋势的,木有!说明造ORM是有套路的,创新,是需要艺术细胞的。
曾经,我也有一个很简单又传统的ORM叫XQData:
是我2009年时造的,发现现在还躺在硬盘里,任性地就开源分享给各位还没造过ORM的小伙伴们当入门指南用了。
XQData源码(SVN下载)地址:http://code.taobao.org/svn/cyqopen/trunk/XQData
在早期的CYQ.Data版本里(具体多早不好说),和传统实体型ORM比起来,除了不拘一格,看起来有点潮,值的鼓励和关注之外,用起来的确没感觉爽在哪。
随着自动化框架思维的形成,经过多年的完善,如今,和实体型ORM的差距已经不在同一个层次上了。
先看实体型ORM的代码编写方式:实体继承自CYQ.Data.Orm.OrmBase
using (Users u = new Users()) { u.Name = "路过秋天"; u.TypeID = Request["typeid"]; //.... u.Insert(); }
看起来很简洁是不?的确是,只是它太固定化了,不够智能,一经写死,就是天造地设耦合的一对。
为什么我都推荐用MAction?因为它有自动化框架思维:
看以下代码:
using (MAction action = new MAction(TableNames.Users)) { action.Insert(true);//这中间是没有单个赋值过程的 }
1:代码少了,没了中间的赋值过程;
2:和属性和数据库字段无依赖了:不管你前端修改界面,还是修改数据库,后台代码都不作调整;
1:实体ORM:只能用分布式事务包含代码段,不能复用链接。
2:MAction:可以用本地事务,可以复用链接。
上面的MAction代码,还有一个TableNames.Users表名依赖,如果把它变成参数,你就会发现不一样的天空:
using (MAction action = new MAction(参数表名)) { action.Insert(true); }
就这么两行代码,你发现完全和数据库和界面解耦了。
1:因为它实现了数据层和UI层真正意义上的解耦。
2:因为它是基于自动化框架编程的思维的,不再有一个一个属性赋值的过程。
下面的方法只需要前端页面只需要传递一个表名(+对应的数据):

如果进一步,把表名配置在数据库里的Url菜单字段,那么就形成一个自动化的页面了:
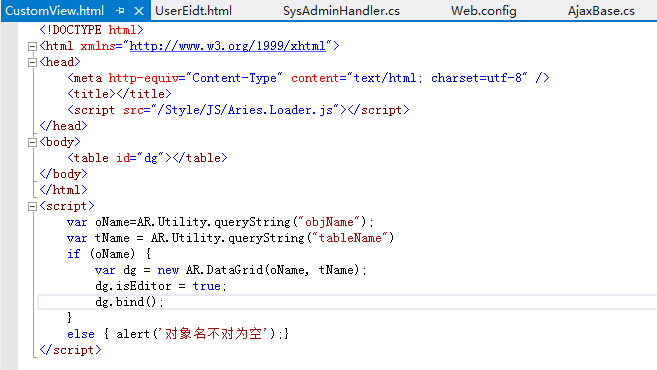
而这些自动自动化框架编程思维,都是实体ORM不具备的,实体ORM只能小打小闹的针对某个界面一堆代码一堆代码的敲。
假设,有个App项目,有Android版和IOS,它们都需要调用后台API,这时候,你怎么设计?
先不动,等着App产品经理把界面原型都定稿了,再针对App的界面需要哪些元素,和开发App开发工程师商量一下,再针对请求写方法?
毕竟你要知道读哪个表,查哪些数据,所以你只能被动?每新增一个页面或功能,你都要跑去后台写一堆业务逻辑代码,然后又进行联调?
是不是特累?
接口核心代码:
using (MAction action = new MAction(tableName)) { action.Select(pageIndex, pageSize,where).ToJson(); }
接下来你要设计的是:
1:给App定好客户端请求参数的格式:{key:'xx',pageindex:1,pagesize:10,wherekey:'xxxx'}
2:将表名映射放到数据库(Key,Value),App只传递Key当请求名称
3:根据实际业务,构造好where条件。
1:可以减少很多沟通成本。
2:API的设计是通用型的,减少大量的代码,后续维护简单可配置。
3:一开始就可以动工了,不需要等到App原型启动后再动手。
4:连表是否存在,长成什么样,都可以事先不管用,后期可数据库配置。
5:实现一套之后,换公司换项目换业务也可以用,因为你的设计与具体业务是解耦的。
试想换成实体ORM,你是不是要事先有数据库,生成一堆实体吧,然后具体业务不断New实例吧,思维的局限就只能被限制在具体的业务。
先看一张图:

曾经我也曾思考过语法糖,是否把Where这一块设计成:.Select(...).Where(...).Having(...).GroupBy(...).OrderBy(...)...
1:开发人员没有学习成本。
2:保持框架的青春创造力。
3:具备自动化框架思维。
1:框架自身复设计杂度增加。
2:使用者学习成本高,使用复杂度增加。
3:不适合自动化扩展:设计已成表达式,无法动态根据某Key和表去动态构造查询条件!只适合具体实例和业务,不适合自动化编程。
当然,在大多数的Where条件里,很多是根据主键或唯一键件的条件,为了进一步抽象及适应自动化编程,我设计出了自能化推导机制。
看以下两个代码:左边是构造相对完整的的where,右边的能自动推导出where。(内部有防SQL注入,所以不用担心where条件注入问题)。
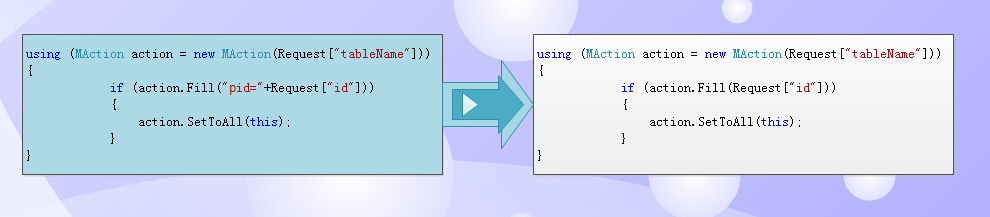
通过智能化推导,去掉了主键名参数(因为不同的表的主键表不一样),智能推导产生,可以让编程者主要关心传过来的值,而不用关注具体的主键名叫什么。
如果值的是是“1,2,3"这种按逗号分隔的多值,框架会自动推导转成 主键 in (1,2,3) 条件。
再看两组代码:左边依旧是相对完成where条件,右边是智能推导型编程。
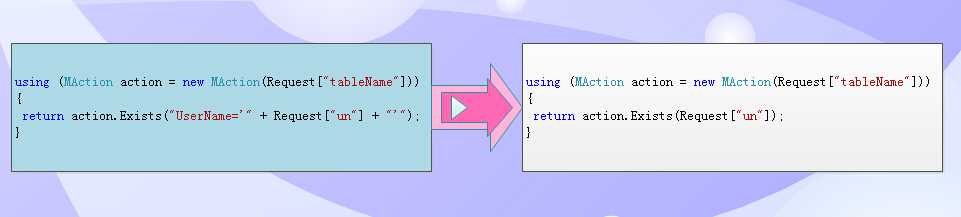
注意:同样是传值,但我们要的是UserName,不是主键,系统也能推导出来?
这时候系统会根据值的类型、主键、唯一键等值的类型综合分析,得到该值应该用主键或是唯一键去构造出where。
(PS:唯一键推导是昨天才完成的功能,所以只有最新版本才有。)
正因框架有智能推导功能,屏蔽字段差异,让使用者只需要关注传值即可。它也是让你实现自动化框架编程思维的重要功能。
看一张图:MDataTable:它能和各种数据类型直接产生批量式互相转换:

MDataTable 是框架的核心之一,上篇文章就有对它的专属介绍。
当然,Table的构建,往往基于行,所以再看一张图:MDataRow (它是单行数据的核心)
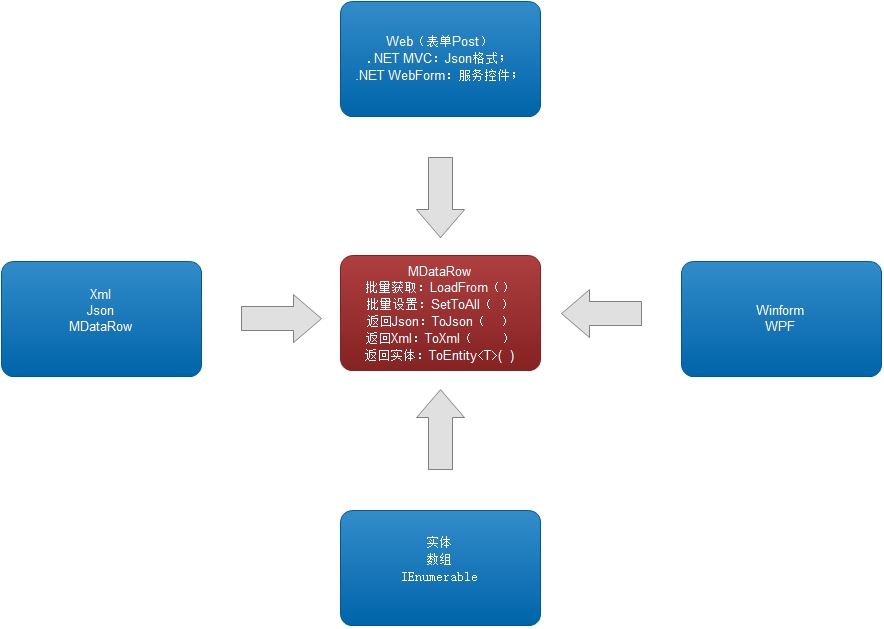
其实正因为MDataRow打通了单行的数据的批量来来去去,所以才造就了MDataTable的多行数据的批量处理。
事实上MDataRow是核心实现层,只是它比较低调。
在使用框架编程时,你会发现更多关心的是:数据的流向、及如何为抽象的参数构建配置系统。
在大部分的编程时间里,除了特定的字段意义需要具体关注,多数都是基于自动化编程思维,数据流向思维。
早期的系列:没有这种编程思维,难免看了介绍后会有种违各感。
而今的系统:自动化框架编程思维,也是用户忠诚度高喜欢上的原因,特别是免费之后。