Official implementation of EMNLP 2022 paper Generate, Discriminate, and Contrast: A Semi-Supervised Sentence Representation Learning Framework
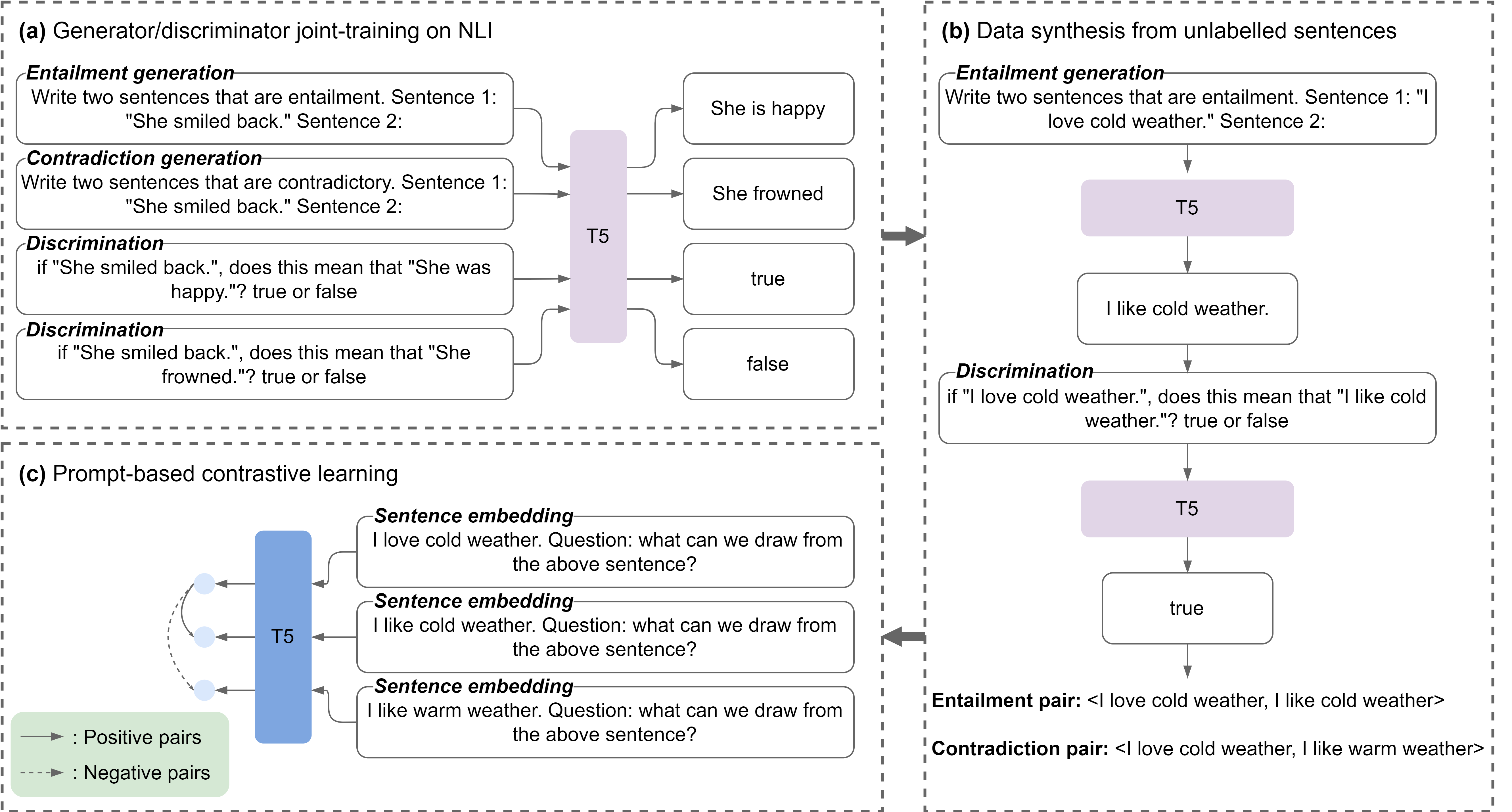
We propose a semi-supervised sentence embedding framework, GenSE, that effectively leverages large-scale unlabeled data. Our method include three parts:
- Generate: A generator/discriminator model is jointly trained to synthesize sentence pairs from open-domain unlabeled corpus.
- Discriminate: Noisy sentence pairs are filtered out by the discriminator to acquire high-quality positive and negative sentence pairs.
- Contrast: A prompt-based contrastive approach is presented for sentence representation learning with both annotated and synthesized data.

To run our code, please install all the dependency packages by using the following command:
pip install -r requirements.txtWe train a unified T5 model for data generation and discrimination. Details about data synthesis can be found in data_synthesis/README.md.
After data synthesis, we can train GenSE sentence embedding model follows gense_training/README.md
All of our pre-trained models are now available from huggingface hub:
| Model |
|---|
| mattymchen/nli-synthesizer-t5-base |
| mattymchen/gense-base |
| mattymchen/gense-base-plus |
We provide a simple package, which can be used to generate NLI triplets and compute sentence embeddings:
pip install gensefrom gense import Synthesizer
synthesizer = Synthesizer('mattymchen/nli-synthesizer-t5-base')
input_sents = [
'The task of judging the best was not easy.',
'A man plays the piano.'
]
# generate NLI triplets
triplets = synthesizer.generate_triplets(input_sents)
# filter triplets
filtered_triplets = synthesizer.filter_triplets(triplets)
print(filtered_triplets)from gense import GenSE
gense = GenSE('mattymchen/gense-base-plus')
example_sentences = [
'An animal is biting a persons finger.',
'A woman is reading.',
'A man is lifting weights in a garage.',
'A man plays the violin.',
'A man is eating food.',
'A man plays the piano.',
'A panda is climbing.',
'A man plays a guitar.',
'A woman is slicing a meat.',
'A woman is taking a picture.'
]
example_queries = [
'A man is playing music.',
'A woman is making a photo.'
]Encode sentence
print(gense.encode(example_sentences))Compute cosine similarity
similarities = gense.similarity(example_queries, example_sentences)
print(similarities)Semantic search
gense.build_index(example_sentences, use_faiss=True)
results = gense.search(example_queries)
for i, result in enumerate(results):
print("Retrieval results for query: {}".format(example_queries[i]))
for sentence, score in result:
print(" {} (cosine similarity: {:.4f})".format(sentence, score))Alternatively, you can also directly use GenSE with huggingface transformers.
from transformers import T5ForConditionalGeneration, AutoTokenizer
# load data synthesis model
synthesis_model = T5ForConditionalGeneration.from_pretrained('mattymchen/nli-synthesizer-t5-base')
synthesis_tokenizer = AutoTokenizer.from_pretrained('mattymchen/nli-synthesizer-t5-base')
# prepare inputs
input_sents = [
'Write two sentences that are entailment. Sentence 1: \"The task of judging the best was not easy.\"Sentence 2:',
'Write two sentences that are contradictory. Sentence 1: \"The task of judging the best was not easy.\"Sentence 2:',
'if \"The task of judging the best was not easy.\", does this mean that \" It was difficult to judge the best.\"? true or false',
'if \"The task of judging the best was not easy.\", does this mean that \" It was easy to judge the best.\"? true or false'
]
input_features = synthesis_tokenizer(input_sents, add_special_tokens=True, padding=True, return_tensors='pt')
# generation
outputs = synthesis_model.generate(**input_features, top_p=0.9)
# Outputs:
# It was difficult to judge the best.
# It was easy to judge the best.
# true
# false
print(synthesis_tokenizer.batch_decode(outputs, skip_special_tokens=True))import torch
from transformers import T5Model, AutoTokenizer
# load embedding model
embedding_model = T5Model.from_pretrained('mattymchen/gense-base-plus').eval()
embedding_tokenizer = AutoTokenizer.from_pretrained('mattymchen/gense-base-plus')
# prepare inputs
input_sents = [
'The task of judging the best was not easy. Question: what can we draw from the above sentence?',
]
input_features = embedding_tokenizer(input_sents, add_special_tokens=True, padding=True, return_tensors='pt')
decoder_start_token_id = embedding_model._get_decoder_start_token_id()
input_features['decoder_input_ids'] = torch.full([input_features['input_ids'].shape[0], 1], decoder_start_token_id)
# inference
with torch.no_grad():
outputs = embedding_model(**input_features, output_hidden_states=True, return_dict=True)
last_hidden = outputs.last_hidden_state
sent_embs = last_hidden[:, 0].cpu()
print(sent_embs)We run our unified data synthesis model on open domain unlabeled sentences to obtain synthetic NLI triplets for GenSE training.
The resulting synthetic dataset SyNLI contains around 61M NLI triplets, which can now be downloaded from huggingface hub:
from datasets import load_dataset
dataset = load_dataset("mattymchen/synli")Please cite our paper if you use GenSE in your work:
@inproceedings{chen2022gense,
title={Generate, Discriminate and Contrast: A Semi-Supervised Sentence Representation Learning Framework},
author={Chen, Yiming and Zhang, Yan and Wang, Bin and Liu, Zuozhu and Li, Haizhou},
booktitle={Empirical Methods in Natural Language Processing (EMNLP)},
year={2022}
}
Code is implemented based on SimCSE. We would like to thank the authors of SimCSE for making their code public.