In a traditional neural network layer or convolutional neural network layer, the output from the previous layer is the input for the next layer and follows that pattern until the prediction. The basic idea of the inception network is the inception block. It takes apart the individual layers and instead of passing it through 1 layer it takes the previous layer input and passes it to four different operations in parallel and then concatenates the outlets from all these different layers. Below is the figure of the inception block. Don’t worry about the picture you saw below, we will get into the details of it.
Let’s understand what is inception block and how it works. Google Net is made of 9 inception blocks. Before understanding inception blocks, I assume that you know about backpropagation concepts like scholastic gradient descent and CNN-related concepts like max-pooling, convolution, stride, and padding if not check out those concepts. Do note that, in the above image max-pooling is done using SAME pooling. you may get a doubt that what is SAME pooling? There are types of performing pooling like VALID pooling and SAME pooling.
In the above visualizations, the first one is VALID pooling where you don't apply any padding on the image. The third one is the SAME pooling. Here we apply padding to input (if needed) so that the input image gets fully covered by the filter and stride you specified. For stride 1, this will ensure that the output image size is the same as the input.
Now let’s see fig (a) and understand about inception block. In a traditional CNN architecture, the output of one layer is connected as an input of the Next Layer, but for the Inception block, each filter is applied separately to the previous layer output and finally, all the results are concatenated and sent as an input to the next layer. as we can see in fig (a), for 28x28x192 (height, width, channels) input, we applied 4 different filters 1x1, 3x3, 5x5, 3x3. Right now, you may have many doubts like why do we apply 1x1, 3x3, and 5x5 filters? And performing convolution using 1x1 will not give any changes, but still, why do we use a 1x1 filter?
In earlier architectures, they have fixed convolution size window, for example, in VGG16 the convolution filter is of size 3x3 and is fixed for all but here we use both 3x3 and 5x5 to address the different object sizes in the image. We apply a 1x1 filter to decrease the spectral dimension. Spectral dimension means band, for example, if an input size for an inception block is 28x28x192, then 192 is called a band or spectral dimension. If we reduce that spectral dimension using a 1x1 filter, we can save a lot of computational power. We also apply a 1x1 filter before applying 3x3 and 5x5 to save the computational resources. We will see how we will save computational power by using a 1x1 filter in detail.
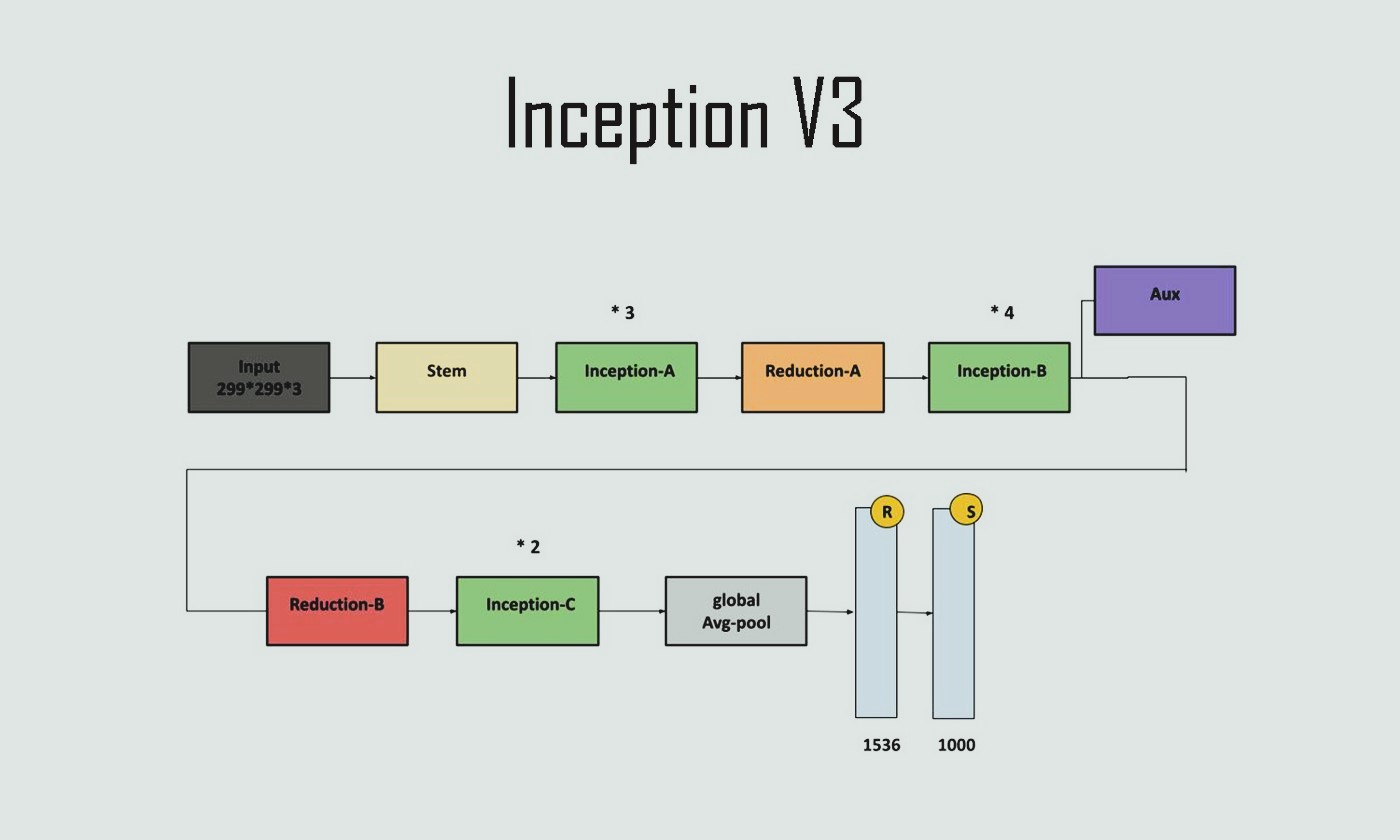
Inception V3 Architecture was published in the same paper as Inception V2 in 2015, and we can consider it as an improvement over the previous Inception Architectures.