In physics, the n-body problem is the problem of predicting the individual motions of a group of celestial objects interacting with each other gravitationally.
The attractional gravitational force is given by the equation:
 With every time step, positions of the bodies change w.r.t net force due to other bodies.
With every time step, positions of the bodies change w.r.t net force due to other bodies.
Brute force approach demands huge computaional power and the complexity is O(n^2).
The serial approach works good for small number of bodies but when we have a big number, it simply fails.
Thus we need a parallel approach to solve the problem taking advantage of the computaional resources we have.
 The image above represents approximately 10 billion bodies
The image above represents approximately 10 billion bodies
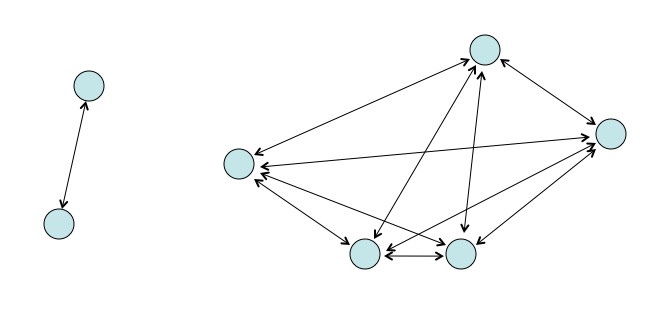
1. All Pairs
- We calculate all possible combinations of interactive forces between the bodies
- It is most accurate
- Computationally intensive
- Choose variable time step schemes to calculate interaction
- Not required in some cases
 .
.
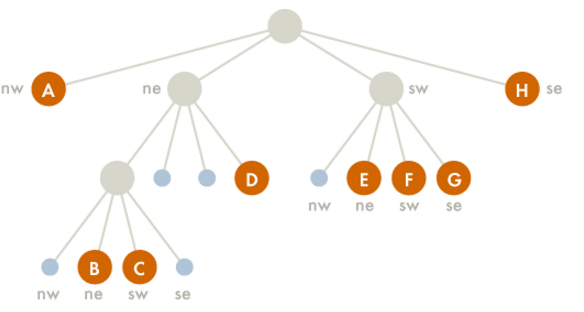
2. Barnes Hut Algorithm Barnes-Hut is an approximation technique used. The idea behind this is that for bodies which are farther away, instead of calculating all pairs interactive forces, force w.r.t. the center of mass is calculated. Barnes-Hut algorithm recursively divides the n bodies into groups by storing them in an octree (or a quad-tree in a 2D simulation). Each node in this tree represents a region of the three-dimensional space. The topmost node represents the whole space, and its eight children represent the eight octants of the space. The space is recursively subdivided into octants until each subdivision contains 0 or 1 bodies (some regions do not have bodies in all of their octants). There are two types of nodes in the octree: internal and external nodes. An external node has no children and is either empty or represents a single body. Each internal node represents the group of bodies beneath it, and stores the center of mass and the total mass of all its children bodies. To calculate the net force on a particular body, the nodes of the tree are traversed, starting from the root. If the center of mass of an internal node is sufficiently far from the body, the bodies contained in that part of the tree are treated as a single particle whose position and mass is respectively the center of mass and total mass of the internal node. If the internal node is sufficiently close to the body, the process is repeated for each of its children. Efficiency is O(n logn).
 .
.
 .
.
void compute()
{
// display_bodies();
double start, end, minSerial = 1e30;
for (int j = 0; j < 1; ++j)
{
start = CycleTimer::currentSeconds();
for (int i = 0; i < 10000; ++i)
{
updatePhysics(i * 100);
}
end = CycleTimer::currentSeconds();
minSerial = std::min(minSerial, end - start);
}
printf("Time Taken by Serial implementation: %f ms\n", (minSerial)*1000);
}
Calculate new positions at each time step.
void updatePhysics(float deltaT)
{
for( int i = 0; i < BODY_COUNT; i++ )
{
updateAcceleration(i);
updateVelocity(i, deltaT );
updatePosition(i, deltaT );
}
}
void compute()
{
double start, end, minParallel = 1e30;
for (int j = 0; j < 2; ++j)
{
start = CycleTimer::currentSeconds();
for (int i = 0; i < 10000; ++i)
{
updatePhysics(i * 100);
}
end = CycleTimer::currentSeconds();
minParallel = std::min(minParallel, end - start);
}
}
void updatePhysics(float deltaT)
{
#pragma omp parallel for num_threads(32)
for(int i = 0; i < BODY_COUNT; i++ )
{
updateAcceleration(i);
updateVelocity(i, deltaT );
updatePosition(i, deltaT );
}
}
Also calculation of net force with other bodies can also we parallelized.
void updateAcceleration(int bodyIndex )
{
Force3D netForce = { 0, 0, 0 };
#pragma omp parallel for
for( int i = 0; i < BODY_COUNT; i++ )
{
if( i == bodyIndex )
{
continue;
}
Force3D vectorForceToOther = {0, 0, 0};
Force scalarForceBetween = forceNewtonianGravity3D(
nBodyMass[bodyIndex],
nBodyMass[i],
nBodyPosition[bodyIndex],
nBodyPosition[i]);
direction(
nBodyPosition[bodyIndex],
nBodyPosition[i],
vectorForceToOther);
vectorForceToOther.x *= scalarForceBetween;
vectorForceToOther.y *= scalarForceBetween;
vectorForceToOther.z *= scalarForceBetween;
netForce.x += vectorForceToOther.x;
netForce.y += vectorForceToOther.y;
netForce.z += vectorForceToOther.z;
}
nBodyAcceleration[bodyIndex] = computeAccel3D(nBodyMass[bodyIndex], netForce);
}
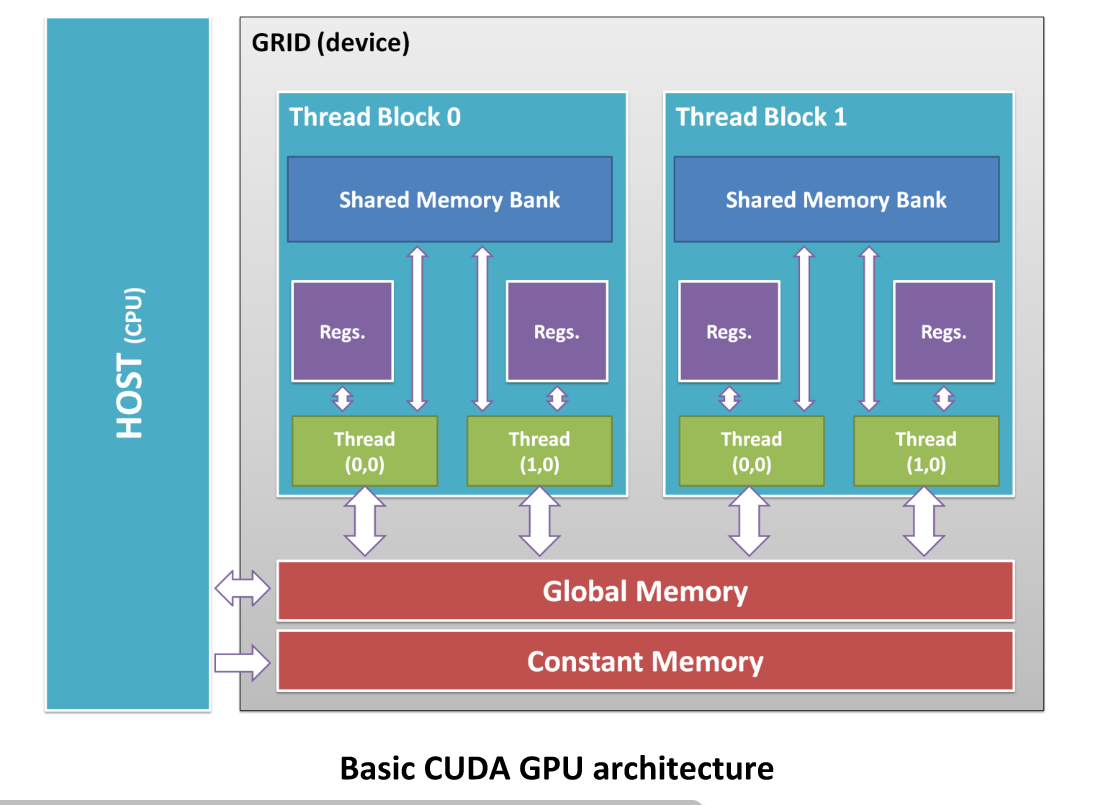
GPU architecture:
 .
.
void compute()
{
double start, end, min = 1e30;
int BYTES_SIZE_VECTOR = BODY_COUNT * sizeof(Vector3D);
int BYTES_SIZE_SCALAR = BODY_COUNT * sizeof(Scalar);
//Initializing attributes for the bodies in the GPU
for (int j = 0; j < 3; ++j)
{
start = CycleTimer::currentSeconds();
for (int i = 0; i < 10000; ++i)
{
updatePhysics<<<(BODY_COUNT/16) + 1, 16>>>(BODY_COUNT, (float)(i * 100), d_pos, d_vel, d_acc, d_mass);
}
end = CycleTimer::currentSeconds();
min = std::min(min, end - start);
}
}
The kernel function:
__global__
void updatePhysics(
int bodies,
float deltaT,
Position3D *d_pos,
Velocity3D *d_vel,
Acceleration3D *d_acc,
Mass *d_mass)
{
int i = blockIdx.x;
int j = threadIdx.x;
int body_id = (i * j) + j;
if(body_id > bodies)
return;
updateAcceleration(body_id, d_pos, d_acc, d_mass);
updateVelocity(body_id, deltaT, d_acc, d_vel);
updatePosition(body_id, deltaT, d_vel, d_pos);
}
 .
.
 .
.
 .
.
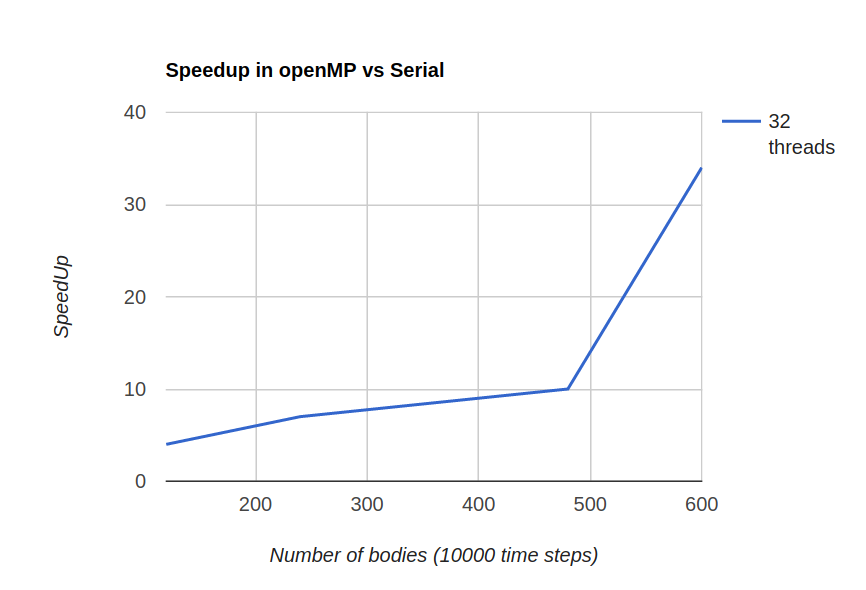
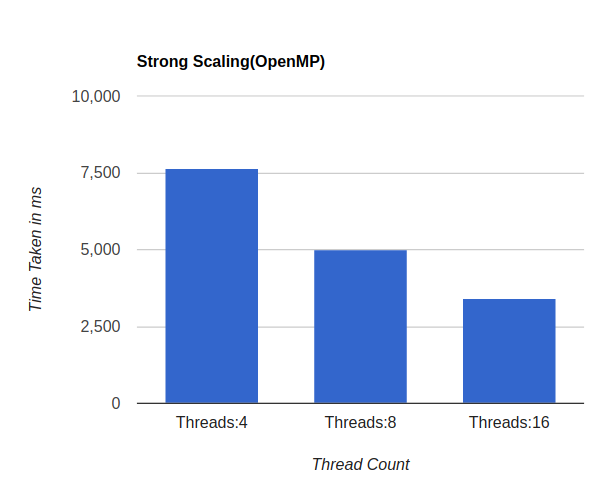
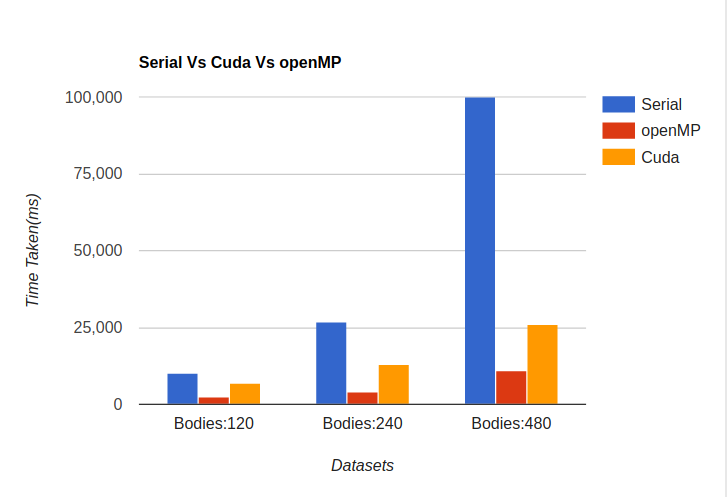
- openMP implementation turned out to be fastest
- CUDA implementation is also fast compared to serial but back and forth copy of data from GPU to CPU offsets the gain in computation
To run the Serial version:
$ g++ -o nbody_serial n_body.cpp
$ ./nbody_serialTo run the openMP version:
Pre-requisites: CUDA, openMP and openGL libraries should be present
g++ -o nbody_omp n_body_omp.cpp -fopenmp
$ ./nbody_ompTo run the CUDA version
$ nvcc -o nbody_cuda n_body_cuda.cu
$ ./nbody_cudaTo run the simulation
$ cd opengl-demo-nbody
$ make
$ ./n-body-sim