Lately, we have taken an interest in natural language processing (NLP). One technique that has gathered much traction the past years is Word2Vec (or a similar algorithm like GLoVe). These algorithms try to find vector representations of words that are predictive of their neighbouring words. We can then, either, analyse these vector representations directly, understand how words are used in a text, or use them as input for another machine learning algorithm.
In this project, we opted for the first option: To analyse the word vectors directly. We did this in two ways, first by inspecting the word vectors themselves, and then seeing what we get when we add and subtract word vectors from each other. The first step, however, was to train a Word2Vec model. To do this, we needed two things: a large collection of text, and a tool to train the model. We have recently watched a lot of Critical Role, a Dungeons & Dragons stream running for over 200 episodes, each lasting 3-5 hours. The transcript for the first 159 episodes + bonus content is available online. We thought this was a good choice, because of the large dataset, and that it could be interesting to see how the model performs on Dungeons and Dragons-language.
To train the model, we used the Python library Gensim, which provides a straightforward interface to fit word vectors. Then, once we had the word vectors, we converted the model to work with SpaCy, which we already were familiar with.
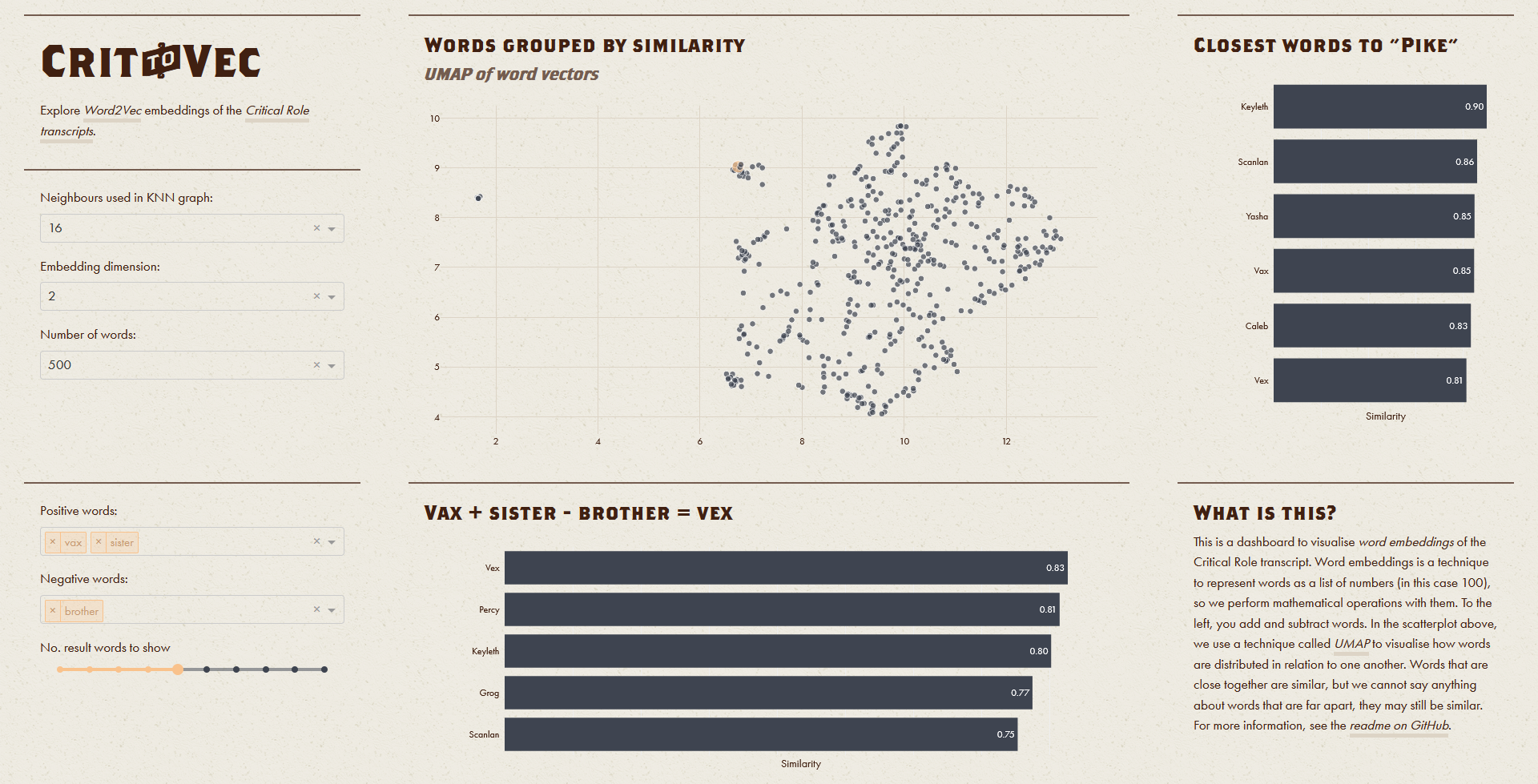
Once we had trained our Word2Vec model, we started analysing the word vectors. However, this is no easy task, as the word vectors were 100 dimensional, and there is no way to accurately depict a 100-dimensional dataset on a screen. We opted for UMAP, a manifold learning technique similar to t-SNE. UMAP tries to find a way to distribute the word-distribution on our screen, so the distance between each word is similar to the distance in the original 100-dimensional word vector space.
What UMAP tries to do is impossible — we cannot even show 3D data accurately on a screen. Imagine if we have the position of all major cities on earth. If we use UMAP on this dataset, then it will try to place one point on our screen for each city. The distance between the Tokyo point on our screen and London point on our screen should then (ideally) be as far apart as Tokyo and London are on our earth (adjusting for units of course). Making the distances of all cities the same on our screen as on earth is not possible. With our word vectors, we get the same problem, many times worse, since we try to represent a 100-dimensional word on our two-dimensional screen.
Because of this problem, we cannot directly trust the UMAP results. However, words that are close on our screen are also close in the word vector space, while words that are far apart may still be close.
The second task we set about to solve was word arithmetic. For example, if we compute "king" - "man" + "woman", we may expect to get "queen". What would this correspond to with the Critical Role transcript? Could we say that "Vax" - "brother" + "sister" = "Vex"? To answer this question, we first had to learn how word arithmetic generally is implemented. We decided to follow Gensim.
So, to compute "word sums", we looked up the vectors associated with all words in the sum. Then, we normalised them to have unit length, before we computed the arithmetic expression. Then, we used the cosine similarity between the resulting vector and all word vectors in the CR transcript (except those included in our arithmetic expression, since those are bound to be similar to this sum) to find the word most similar to the sum. You can see how we implemented this "word sum" functionality by looking at the find_nearest function in crit2vec.py.
The last step was to create a web app to display our findings. We made the app with Plotly Dash combined with Plotly Express and deployed in with Heroku. You can see this app here.