本文是学习the-super-tiny-compiler后的成果,在阅读本文前建议先去看看这个原始项目.
感谢@March-mitsuki为项目提供了TypeScript版本,具体可以参考
ts_version目录.
前段时间一直想写一个比较完备的 Markdown 编译器,但因为网上相关的文章较少,已有的开源项目已经很完善,就暂时搁置了。这两天发现了这个项目,它用短短 200 多行代码实现了一个超级 mini 的编译器,并且里面有完整的讲解和详细的注释,非常适合没有学习过编译原理的我学习,于是在经过一个晚上的学习和实现之后,就有了这篇文章。
- 虽说这个项目潇潇洒洒地只用了 200 多行代码实现,但对我们的 JavaScript 水平有一定的要求,所以如果你已经有了不错的 JS 基础,那么这个项目非常适合用来练手和提高。
- 如果你像我一样,之前没有接触和学习过编译原理,那么把这个项目作为起点也非常合适。
- 原项目纯英文的,如果你阅读英文些困难的话,或许这篇文章能帮助你理解内容。
- 本文只是对重要概念和核心代码的总结和解释,并没有原项目那样面面俱到的阐述每一句代码的含义。
- 前往原项目,先自主学习项目的教程和代码。
- 如果有地方不理解,回到这篇文章中看看能否找到答案。
- 最后如果你想跟着我写一遍完整的代码,可以到我的 B 站上观看视频。 // TODO 更新视频链接
首先,什么是编译器?
简单讲,编译器就是将“一种语言”翻译为“另一种语言”的程序。 -- 百度百科
上面百度百科给的解释已经简单易懂了,核心就是把一种语言翻译为另外一种语言。就像开头提到的,我打算写一个 Markdown 编译器,其实就是想把 Markdown 编译成/翻译成/转换成 HTML,这就是对编译器最简单的理解。
那么在这个项目中,我们要**实现把 LISP 语言的函数调用语句转换为 C 语言的函数调用语句**。
| Math | LISP | C |
|---|---|---|
| 2 + 1 | (add 2 1) | add(2, 1) |
| 5 - 3 | (subtract 5 3) | subtract(5, 3) |
| 1 + (4 - 3) | (add 1 (subtract 4 3)) | add(1, subtract(4, 3)) |
听起来很简单对不对,接下来再简单梳理一下具体的实现步骤~
想要完成编译,可以把它简单拆分为三大步:
- 词法/语法分析 (Parsing)
- 转换 (Transformation)
- 代码生成 (Code Generation)
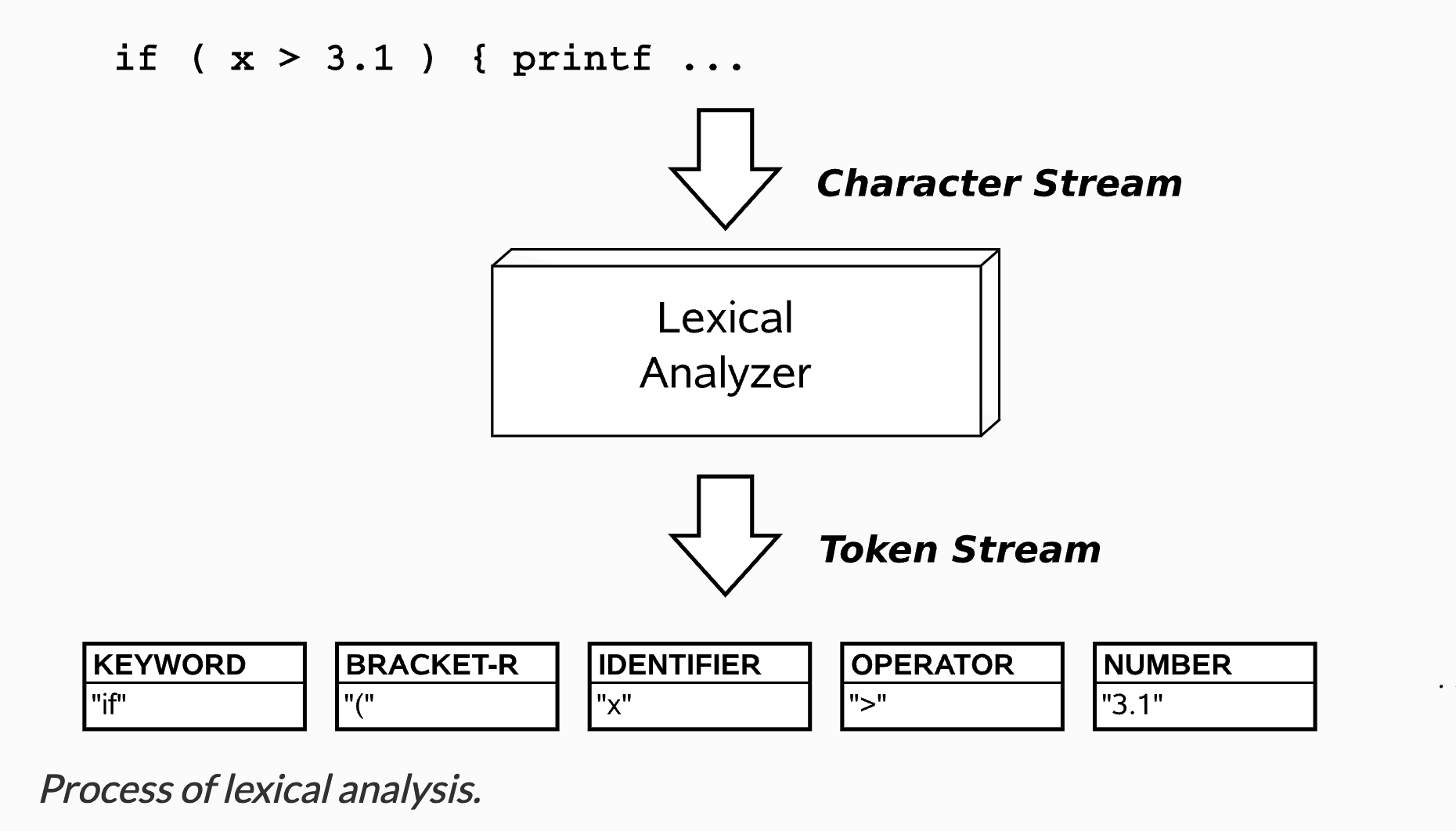
词法分析的目标就是把源代码拆分成一个个词法单元(token),把这些拆分好的token放到一个tokens数组中。
每一个token都是一个简单的对象,里面储存了这个对象的一些基本信息,比如说一个数字可以被标示为{type: 'NumberLiteral', value: 100}。
这里放一张插图帮助大家理解~
再来举个例子,实操一下:
(add 3 (subtract 4 1))经过词法分析,会输出结果:
[
{ type: 'paren', value: '(' },
{ type: 'name', value: 'add' },
{ type: 'number', value: '3' },
{ type: 'paren', value: '(' },
{ type: 'name', value: 'subtract' },
{ type: 'number', value: '4' },
{ type: 'number', value: '1' },
{ type: 'paren', value: ')' },
{ type: 'paren', value: ')' },
];语法分析会在词法分析后进行,它会基于词法分析的结果,也就是根据tokens数组,构建出每一个token之间的关系,最终将这些token全部组合成一个大的对象,通过这个对象就可以还原出原本语法的所有内容,一般管这个对象叫做**抽象语法树(Abstract Syntax Tree)**简称AST。
继续上面的例子,经过语法分析后,会输出结果:
{
type: 'Program',
body: [{
type: 'CallExpression',
name: 'add',
params: [{
type: 'NumberLiteral',
value: '3',
}, {
type: 'CallExpression',
name: 'subtract',
params: [{
type: 'NumberLiteral',
value: '4',
}, {
type: 'NumberLiteral',
value: '1',
}]
}]
}]
}通过这个对象(AST),我们已经可以推导出原本程序的语法,这就是 AST 的作用。
第二部就是转换,对上一步得到的 AST 进行转换。在进行转换时,可以对任意节点进行属性的添加/替换/删除操作,目的是通过转换 AST,能更方便地把它翻译成另一种语言.
为了能对每一个节点都进行转换,就必须要进行遍历(Traversal)。对于 AST 这棵树,我们在遍历的时候采用**深度优先(depth-first)**的模式。
遍历到每一个节点后需要对每个节点进行转换,这里会用到一种设计模式:访问者模式,简单来说就是把操作元素的方法单独拿出来封装成一个visitor类,但是不用担心,如果你没有了解过这种设计模式,继续往下看,也不会有什么影响。
假设我们有两个类型的节点NumberLiteral和StringLiteral,那么想要对这两个节点进行转换,就可以定义这样一个visitor:
const vositor = {
NumberLiteral: {
enter(node, parent) {
// do something
},
exit(node, parent) {
// do something
},
},
StringLiteral: {
enter(node, parent) {
// do something
},
exit(node, parent) {
// do something
},
},
};这样的好处是当我进入某个节点时,只需要调用visitor上对应节点的enter方法就可以完成转换,离开时调用对应节点的exit即可。
最后一步就是根据上一步转换得到的新 AST 来生成出目标语言的代码。
这个步骤非常简单,等下就会看到啦~
下面就正式开始吧!!
tokenizer函数,它接受一个字符串,返回一个tokens数组。
词法解析的原理就是遍历字符串中所有的字符,如果某个字符或多个字符符合一个词法,就将它添加到tokens中。所以最外面一层一定是遍历。
function tokenizer(input) {
let current = 0;
while (current < input.length) {
const char = input[current];
// 在这里就要定义一些词法的规则了
}
}在我们这个简单的项目中,词法规则也非常少,一共只有 6 个,分别是:
- 开括号
( - 闭括号
) - 空格 -> 可以直接跳过
- 数字 -> 数字可能不止一位,需要向后查找完整的数字
- 字符串 -> 在两个双引号之间,需要去掉双引号
- 函数名 -> 需要向后查找,获得完整名称
其中开括号和闭括号非常简单,遇到后直接向tokens中添加对应的token对象即可:
// 写在上文while循环内部
if (char === '(') {
tokens.push({type: 'paren', value: '('});
current++;
continue;
}这里稍微有难度的是数字和字符串,这里简单说明一下:
// 写在上文while循环内部
// 对于数字,还用字符串的方式储存
const NUMBERS = /[0-9]/;
if (NUMBERS.test(char)) {
let value = '';
// 向后继续查找,看看是不是数字
while (NUMBERS.test(char)) {
value += char;
char = input[++current]; // 先自增,再返回值
}
tokens.push({type: 'number', value});
continue;
}
// 处理字符串也很类似,只是需要考虑双引号的问题
if (char === '"') {
let value = '';
char = input[++current]; // 跳过第一个双引号
while (char !== '"') {
value += char;
char = input[++current];
}
char = input[++current]; // 跳过第二个双引号
tokens.push({type: 'string', value});
continue;
}剩下的几个词法的实现也都比较简单,大家可以看代码学习,最终运行tokenizer函数就会得到已经经过词法分析的tokens数组。
parser函数接受tokens数组,返回一个 AST 对象。
这里面的第一个问题就是AST 对象比较复杂,会出现层层嵌套的关系,所以不可避免的就要使用递归了。
最终我们想达到的效果大概是这样:
function parser(tokens) {
let current = 0;
function walk() {
let token = tokens[current];
// walk函数会遍历每一个token,并且返回对应的AST节点
}
// AST的外壳
let ast = {
type: 'Program',
body: [],
};
// 遍历每一个语句
while (current < tokens.length) {
ast.body.push(walk());
}
return ast;
}现在整体框架有了,核心任务就是去实现这个 walk 函数了。
还是从简单的问题入手,处理最简单的number 和string节点:
// 写在walk函数内部
if (token.type === 'number') {
current++;
return {
type: 'NumberLiteral',
value: token.value;
}
}
// string同理处理完简单的后,就要开始复杂一些的操作了。下面要将表达式的调用(Call Expression)转换为 AST,因为表达式内部要接收参数,而参数也可以是另一个表达式,所以这里就要开始递归了。
// 写在walk内部
// 表达式一定以(开始,)结束
if (token.type === 'paren' && token.value === '(') {
token = tokens[++current]; // 跳过(
// AST节点的结构
let node = {
type: 'CallExpression',
name: token.value,
params: [],
};
token = tokens[++current]; // 跳过函数名token
// 下面是核心,开始递归
// 如果没遇到),说明后面的token就是参数,表达式还没有结束
while (token.value !== ')') {
node.params.push(walk()); // 递归
token = tokens[current]; // 经过递归,current已经发生变化,这里更新一下token
}
current++; // 跳过 )
}好啦,到这里parser也完成了,现在我们已经把一段字符串转化成了 AST。
现在已经得到了 AST,接下来要做的就是遍历每一个节点。
简单想一下,对于NumberLiteral这样的节点,很好遍历,因为它没有子节点。但是对于Program和CallExpression来说,他们都有一个数组用来存放子节点,所以想要完全遍历,就要去遍历这个数组。
有了思路,我们来看一下代码的结构:
function traverser(ast, visitor) {
// 遍历Array
function traverseArray(array, parent) {
array.forEach((child) => traverseNode(child, parent));
}
// 遍历Node
function traverseNode(node, parent) {
// 1. 进行转换 Transformation -> 调用visitor里面的函数
// 2. 对于Program和CallExpression,调用traverseArray
}
// 开始遍历
traverseNode(ast, null);
}现在结构应该很清晰了,在traverseNode函数里面要干两件事情,一是进行转换(Transformation),其实就是调用visitor里面对应的函数,二是继续深层遍历数组。
function traverseNode(node, parent) {
// 从visitor中拿到对应type的方法
const method = visitor[node.type];
// 如果enter方法存在,就调用,完成转换
if (method && method.enter) {
method.enter(node, parent);
}
// 继续遍历数组
switch (node.type) {
case 'Program':
traverseArray(node.body, node);
break;
case 'CallExpression':
traverseArray(node.params, node);
break;
case 'NumberLiteral':
case 'StringLiteral':
break;
default:
throw new TypeError(node.type);
}
}现在两项任务都完成了,只是visitor里面的转换方法还没有定义,所以下一步就是定义转换的方法。
在写转换器之前,一定要先搞清楚究竟要怎么转换。我们看一下项目例子中的转换:
// 转换前
{
"type": "Program",
"body": [
{
"type": "CallExpression",
"name": "add",
"params": [
{
"type": "NumberLiteral",
"value": "10"
},
{
"type": "CallExpression",
"name": "subtract",
"params": [
{
"type": "NumberLiteral",
"value": "20"
},
{
"type": "NumberLiteral",
"value": "100"
}
]
}
]
}
]
}// 转换后
{
"type": "Program",
"body": [
{
"type": "ExpressionStatement",
"expression": {
"type": "CallExpression",
"callee": {
"type": "Identifier",
"name": "add"
},
"arguments": [
{
"type": "NumberLiteral",
"value": "10"
},
{
"type": "CallExpression",
"callee": {
"type": "Identifier",
"name": "subtract"
},
"arguments": [
{
"type": "NumberLiteral",
"value": "20"
},
{
"type": "NumberLiteral",
"value": "100"
}
]
}
]
}
}
]
}简单来看主要有这么几个变化:
- 在最外层的 CallExpression外面包裹了一层 ExpressionStatement
- params属性变成了 arguments
- CallExpression 内多了一个 callee 对象
这些转换都是为了最终编译成其他语言做准备,要想完成这些转换,就需要借助visitor里面的方法了。
下面我们试着写一下transformer函数的大体结构:
function transformer(ast) {
// 不在旧的AST上做转换,这里直接创建一个新的AST
const newAst = {
type: 'Program',
body: [],
};
// 这里有一个小trick,因为在traversal函数中
// 我们只把旧的AST传给了enter方法,所以想要修改newAst就比较困难
// 这里将newAst.body的引用赋值到旧AST的一个字段上,方便获取和修改
ast._context = newAst.body;
// 开始遍历
traverse(ast, visitor);
return newAst;
}大体结构就是这样,但是核心的visitor还是没有实现,下面我们来实现一下:
const visitor = {
// 因为CallExpression有嵌套,最复杂,我们先实现一下它
CallExpression: {
enter(node, parent) {
// 创建一个新节点
const expression = {
type: 'CallExpression',
callee: {
type: 'Identifier',
name: node.name,
},
arguments: [],
};
// 同样为了方便修改newAst,把expression.arguments的引用放到node._context上一份
node._context = expression.arguments;
// 判断是否为最外层的CallExpressoin,如果是,包裹ExpressionStatement
if (parent.type !== 'CallExpression') {
expression = {
type: 'ExpressionStatement',
expression: expression,
};
}
// 把处理好的expression添加到newAst中
parent._context.push(expression);
},
},
// Number和String就很简单了,这里只实现NumberLiteral
NumberLiteral: {
enter(node, parent) {
parent._context.push({
type: 'NumberLiteral',
value: node.value,
});
},
},
};到此为止,新的 AST 树也已经生成好了,终于来到最后一步,生成代码!
根据新的 AST 树,不难生成出最终的代码,核心逻辑就是根据node.type生成不同的字符串,其中可能需要一些递归,最后把这些字符串拼接起来,就是最终的代码。
代码很简单,详细的解释在原文中有,但下面的代码也足够清晰了:
function codeGeneratior(node) {
switch (node.type) {
// 最简单的情况就是函数名,数字,字符串,这些直接返回就可以
case 'Identifier':
// callee中的name属性
return node.name;
case 'NumberLiteral':
return node.value;
case 'StringLiteral':
// 字符串需要用双引号包裹
return '"' + node.value + '"';
// 复杂一些的Program, ExpressionStatement, CallExpression都需要递归
// 但也没有那么复杂
case 'Program':
// 可能有多个语句,换行输出
return node.body.map((statement) => codeGenerator(statement)).join('\n');
case 'ExpressionStatement':
// C语言,分号结尾
return codeGenerator(node.expression) + ';';
case 'CallExpression':
// 表达式,参数用逗号隔开
return (
codeGenerator(node.callee) +
'(' +
node.arguments.map(codeGenerator).join(', ') +
')'
);
}
}其实写到这我们的超级迷你编译器已经完成了,它已经能把 LISP 的函数调用语法转换为 C 语言的语法了。
还记得我们写了多少个函数不?下面通过一个简单的测试用例,回顾一下整个过程:
// 这里封装成compiler
function compiler(input) {
const tokens = tokenizer(input); // 第一步,对字符串进行词法解析,得到tokens
const ast = parser(tokens); // 第二步,把tokens转换成AST
const newAst = transformer(ast); // 第三步,对AST进行转换,得到新的AST
const result = codeGenerator(newAst); // 第四步,根据新的AST生成转换后的字符串
return result;
}
// TEST
console.log(compiler('(add 10 (subtract 20 100)) (connect "Hello" "World")'));
// add(10, subtract(20, 100));
// connect("Hello", "World");~~完结撒花啦~~