KMeansPlusPlus-Software-Project-TAU-part-2
K-Means++ Project - Software Project at TAU (0368-2161)
This project, developed as part of the Software Project course at Tel Aviv University by Moria Nachmany and Lior Erenreich, implements the k-means clustering algorithm using the k-means++ initialization method. It provides both Python and C implementations for efficient computation of large datasets.
For part 1 of this project visit here.
Introduction
K-means clustering is a popular unsupervised learning algorithm used for partitioning data into K distinct clusters based on their feature similarity. The k-means++ initialization method is an enhancement to the original k-means algorithm that improves the quality of the initial centroids' selection, leading to better clustering results.
This project aims to provide a flexible and efficient implementation of the k-means++ algorithm using both Python and C programming languages. It includes a Python script for executing the algorithm and a C code file for the core implementation.
Project Structure
The project directory contains the following files:
-
Instructions - Part 2 - kmeans++.pdf: This file contains the assignment instructions and guidelines for implementing the k-means++ algorithm. -
kmeans.c: This file contains the C implementation of the k-means++ algorithm. It includes functions for calculating norms, updating centroids, and memory management. -
kmeans_pp.py: This Python script acts as a wrapper for the C implementation. It provides functions for merging tables, converting data to a one-dimensional array, executing the k-means algorithm, and reading command-line arguments. -
setup.py: This file is not provided but typically used for packaging the project as a Python library or module. -
elbow_method.py: This Python script demonstrates the usage of the scikit-learn library to perform k-means clustering on the Iris dataset. It uses the elbow method to select the optimal number of clusters and generates a plot showing the average dispersion for different values of K.
Setup and Running
To set up and run the KMeansPlusPlus-Software-Project-TAU-part-2 project, follow these steps:
-
Ensure that you have Python 3.x installed on your system.
-
Clone the project repository from GitHub:
git clone https://github.com/LiorErenreich/KMeansPlusPlus-Software-Project-TAU-part-2 -
Navigate to the project directory:
cd KMeansPlusPlus-Software-Project-TAU-part-2 -
Execute the
kmeans_pp.pyscript with the desired command-line arguments to run the k-means++ algorithm. For example:python kmeans_pp.py --clusters 3 --max_iter 100 --input data.csv --output result.csv--clusters: Specify the number of clusters (K) for the k-means algorithm.--max_iter: Set the maximum number of iterations for the algorithm.--input: Provide the input data file in CSV format.--output: Specify the output file to store the clustering results.
-
The script will execute the k-means++ algorithm using the provided parameters and input data. The resulting clusters and centroids will be saved in the specified output file.
Algorithm Working and Implementation
The k-means++ algorithm enhances the original k-means algorithm by improving the initialization of centroids. It ensures that the initial centroids are well-distributed and diverse, which leads to better convergence and clustering results.
The provided code implements the k-means++ algorithm in the following components:
kmeans_pp.py
The kmeans_pp.py script serves as the main entry point for executing the k-means++ algorithm. It is responsible for handling command-line arguments, reading input data, calling the C implementation, and storing the clustering results.
The script performs the following steps:
- Reads the command-line arguments to obtain the number of clusters, maximum iterations, input data file, and output file.
- Loads the input data from the provided file.
- Calls the C implementation by invoking the
cmainfunction inkmeans.c. - Receives the resulting clusters and centroids from the C implementation.
- Stores the clustering results in the specified output file.
kmeans.c
Explanation can be found in part 1.
elbow_method.py
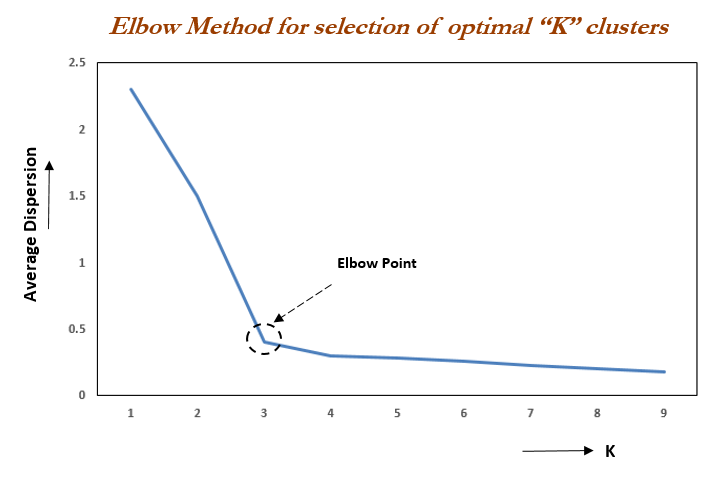
The elbow_method.py script implements the elbow method, which is a technique for determining the optimal number of clusters (K) in a k-means algorithm. It uses the average dispersion values calculated for different values of K and plots them on a graph. The "elbow point" in the graph indicates the optimal value of K where the incremental gain in clustering quality diminishes significantly.
The script performs the following steps:
- Loads the input data or generates sample data (in this case, the Iris dataset is used).
- Iterates over different values of K, performing k-means clustering for each value.
- Calculates the average dispersion for each value of K.
- Plots the average dispersion values against the corresponding K values.
- Identifies the "elbow point" on the graph, indicating the optimal K value.
Please refer to the assignment instructions, individual file contents, and the explanations in this README file for more detailed information on how to use and further extend this project.