This repository contains the code for UNETR: Transformers for 3D Medical Image Segmentation [1]. UNETR is the first 3D segmentation network that uses a pure vision transformer as its encoder without relying on CNNs for feature extraction.
The code presents a volumetric (3D) multi-organ segmentation application using the BTCV challenge dataset.

Dependencies can be installed using:
pip install -r requirements.txtA UNETR network with standard hyper-parameters for the task of multi-organ semantic segmentation (BTCV dataset) can be defined as follows:
model = UNETR(
in_channels=1,
out_channels=14,
img_size=(96, 96, 96),
feature_size=16,
hidden_size=768,
mlp_dim=3072,
num_heads=12,
pos_embed='perceptron',
norm_name='instance',
conv_block=True,
res_block=True,
dropout_rate=0.0)The above UNETR model is used for CT images (1-channel input) and for 14-class segmentation outputs. The network expects
resampled input images with size (96, 96, 96) which will be converted into non-overlapping patches of size (16, 16, 16).
The position embedding is performed using a perceptron layer. The ViT encoder follows standard hyper-parameters as introduced in [2].
The decoder uses convolutional and residual blocks as well as instance normalization. More details can be found in [1].
Using the default values for hyper-parameters, the following command can be used to initiate training using PyTorch native AMP package:
python main.py
--feature_size=32
--batch_size=1
--logdir=unetr_test
--fold=0
--optim_lr=1e-4
--lrschedule=warmup_cosine
--infer_overlap=0.5
--save_checkpoint
--data_dir=/dataset/dataset0/Note that you need to provide the location of your dataset directory by using --data_dir.
To initiate distributed multi-gpu training, --distributed needs to be added to the training command.
To disable AMP, --noamp needs to be added to the training command.
If UNETR is used in distributed multi-gpu training, we recommend increasing the learning rate (i.e. --optim_lr)
according to the number of GPUs. For instance, --optim_lr=4e-4 is recommended for training with 4 GPUs.
We provide state-of-the-art pre-trained checkpoints and TorchScript models of UNETR using BTCV dataset.
For using the pre-trained checkpoint, please download the weights from the following directory:
https://drive.google.com/file/d/1kR5QuRAuooYcTNLMnMj80Z9IgSs8jtLO/view?usp=sharing
Once downloaded, please place the checkpoint in the following directory or use --pretrained_dir to provide the address of where the model is placed:
./pretrained_models
The following command initiates finetuning using the pretrained checkpoint:
python main.py
--batch_size=1
--logdir=unetr_pretrained
--fold=0
--optim_lr=1e-4
--lrschedule=warmup_cosine
--infer_overlap=0.5
--save_checkpoint
--data_dir=/dataset/dataset0/
--pretrained_dir='./pretrained_models/'
--pretrained_model_name='UNETR_model_best_acc.pth'
--resume_ckptFor using the pre-trained TorchScript model, please download the model from the following directory:
https://drive.google.com/file/d/1_YbUE0abQFJUR4Luwict6BB8S77yUaWN/view?usp=sharing
Once downloaded, please place the TorchScript model in the following directory or use --pretrained_dir to provide the address of where the model is placed:
./pretrained_models
The following command initiates finetuning using the TorchScript model:
python main.py
--batch_size=1
--logdir=unetr_pretrained
--fold=0
--optim_lr=1e-4
--lrschedule=warmup_cosine
--infer_overlap=0.5
--save_checkpoint
--data_dir=/dataset/dataset0/
--pretrained_dir='./pretrained_models/'
--noamp
--pretrained_model_name='UNETR_model_best_acc.pt'
--resume_jitNote that finetuning from the provided TorchScript model does not support AMP.
You can use the state-of-the-art pre-trained TorchScript model or checkpoint of UNETR to test it on your own data.
Once the pretrained weights are downloaded, using the links above, please place the TorchScript model in the following directory or
use --pretrained_dir to provide the address of where the model is placed:
./pretrained_models
The following command runs inference using the provided checkpoint:
python test.py
--infer_overlap=0.5
--data_dir=/dataset/dataset0/
--pretrained_dir='./pretrained_models/'
--saved_checkpoint=ckptNote that --infer_overlap determines the overlap between the sliding window patches. A higher value typically results in more accurate segmentation outputs but with the cost of longer inference time.
If you would like to use the pretrained TorchScript model, --saved_checkpoint=torchscript should be used.
A tutorial for the task of multi-organ segmentation using BTCV dataset can be found in the following:
Additionally, a tutorial which leverages PyTorch Lightning can be found in the following:
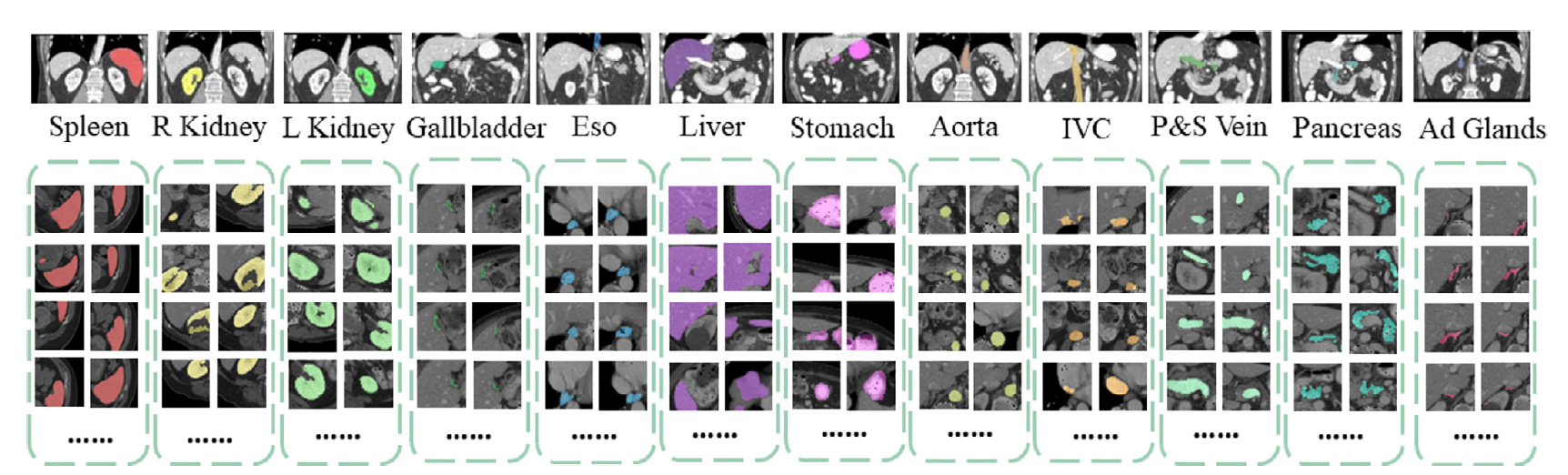
The training data is from the BTCV challenge dataset.
Under Institutional Review Board (IRB) supervision, 50 abdomen CT scans of were randomly selected from a combination of an ongoing colorectal cancer chemotherapy trial, and a retrospective ventral hernia study. The 50 scans were captured during portal venous contrast phase with variable volume sizes (512 x 512 x 85 - 512 x 512 x 198) and field of views (approx. 280 x 280 x 280 mm3 - 500 x 500 x 650 mm3). The in-plane resolution varies from 0.54 x 0.54 mm2 to 0.98 x 0.98 mm2, while the slice thickness ranges from 2.5 mm to 5.0 mm.
- Target: 13 abdominal organs including 1. Spleen 2. Right Kidney 3. Left Kideny 4.Gallbladder 5.Esophagus 6. Liver 7. Stomach 8.Aorta 9. IVC 10. Portal and Splenic Veins 11. Pancreas 12.Right adrenal gland 13.Left adrenal gland.
- Task: Segmentation
- Modality: CT
- Size: 30 3D volumes (24 Training + 6 Testing)
We provide the json file that is used to train our models in the following link:
https://drive.google.com/file/d/1t4fIQQkONv7ArTSZe4Nucwkk1KfdUDvW/view?usp=sharing
Once the json file is downloaded, please place it in the same folder as the dataset.
If you find this repository useful, please consider citing UNETR paper:
@inproceedings{hatamizadeh2022unetr,
title={Unetr: Transformers for 3d medical image segmentation},
author={Hatamizadeh, Ali and Tang, Yucheng and Nath, Vishwesh and Yang, Dong and Myronenko, Andriy and Landman, Bennett and Roth, Holger R and Xu, Daguang},
booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
pages={574--584},
year={2022}
}
[1] Hatamizadeh, Ali, et al. "UNETR: Transformers for 3D Medical Image Segmentation", 2021. https://arxiv.org/abs/2103.10504.
[2] Dosovitskiy, Alexey, et al. "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale ", 2020. https://arxiv.org/abs/2010.11929.