Java实操避坑指南 SpringBoot/MySQL/Redis常见错误详解,业务代码-整合框架-存储-缓存常见错误详解,全面讲解各类问题,找坑-分析-填坑-总结,助你养成良好编程习惯和解决问题的思维方法。
官方视频地址:Java实操避坑指南(业务代码-整合框架-存储-缓存常见错误详解)
笔记纯属个人根据视频总结,源码部分原封不动上传,若侵权请联系我删除。
介绍制作这门课程的初衷、我对这门课程的定位以及愿景,课程中包含了哪些内容,能够帮助你什么,以及怎样去学习这门课程,才能更好的消化吸收。
空指针问题和各种常见的异常(并发修改、类型转换)几乎是所有 Java 初学者最头疼的问题,本章将会教会你怎么避免这些问题、如何使用 Optional 规避空指针问题,以及正确的使用 try catch 捕获异常。
对应代码:src/main/java/com/imooc/java/escape/WhatIsNpe.java
笔记:空指针出现的五种情况
- 第一种情况: 调用了空对象的实例方法
- 第二种情况: 访问了空对象的属性
- 第三种情况: 当数组是一个空对象的时候, 取它的长度
- 第四种情况: null 当做 Throwable 的值
- 第五种情况: 方法的返回值是 null, 调用方直接去使用
public static void main(String[] args) {
// 第一种情况: 调用了空对象的实例方法
// User user = null;
// user.print();
// 第二种情况: 访问了空对象的属性
// User user = null;
// System.out.println(user.name);
// 第三种情况: 当数组是一个空对象的时候, 取它的长度
// User user = new User();
// System.out.println(user.address.length);
// 第四种情况: null 当做 Throwable 的值
// CustomException exception = null;
// throw exception;
// 第五种情况: 方法的返回值是 null, 调用方直接去使用
User user = new User();
System.out.println(user.readBook().contains("MySQL"));
}对应代码:src/main/java/com/imooc/java/escape/UnboxingNpe.java
笔记:自动拆箱和自动装箱编译后可以看到都是调用了对应的方法,所以有可能出现空指针
public class UnboxingNpe {
private static int add(int x, int y) {
return x + y;
}
private static boolean compare(long x, long y) {
return x >= y;
}
public static void main(String[] args) {
// 1. 变量赋值自动拆箱出现的空指针
// javac UnboxingNpe.java
// javap -c UnboxingNpe.class
Long count = null;
long count_ = count;
// 2. 方法传参时自动拆箱引发的空指针
// Integer left = null;
// Integer right = null;
// System.out.println(add(left, right));
// 3. 用于大小比较的场景
// Long left = 10L;
// Long right = null;
// System.out.println(compare(left, right));
}
}对应代码:src/main/java/com/imooc/java/escape/BasicUsageNpe.java
public class BasicUsageNpe {
private static boolean stringEquals(String x, String y) {
return x.equals(y);
}
public static class User {
private String name;
}
public static void main(String[] args) {
// 1. 字符串使用 equals 可能会报空指针错误
// System.out.println(stringEquals("xyz", null));
// System.out.println(stringEquals(null, "xyz"));
// 2. 对象数组 new 出来, 但是元素没有初始化
// User[] users = new User[10];
// for (int i = 0; i != 10; ++i) {
// users[i] = new User();
// users[i].name = "imooc-" + i;
// }
// 3. List 对象 addAll 传递 null 会抛出空指针
List<User> users = new ArrayList<User>();
User user = null;
List<User> users_ = null;
users.add(user);
users.addAll(users_);
}
}对应代码:src/main/java/com/imooc/java/escape/OptionalUsage.java
public class OptionalUsage {
private static void badUsageOptional() {
Optional<User> optional = Optional.ofNullable(null);
User user = optional.orElse(null); // good
user = optional.isPresent() ? optional.get() : null; // bad
}
public static class User {
private String name;
public String getName() {
return name;
}
}
private static void isUserEqualNull() {
User user = null;
if (user != null) {
System.out.println("User is not null");
} else {
System.out.println("User is null");
}
Optional<User> optional = Optional.empty();
if (optional.isPresent()) {
System.out.println("User is not null");
} else {
System.out.println("User is null");
}
}
private static User anoymos() {
return new User();
}
public static void main(String[] args) {
// 没有意义的使用方法
isUserEqualNull();
User user = null;
Optional<User> optionalUser = Optional.ofNullable(user);
// 存在即返回, 空则提供默认值
optionalUser.orElse(new User());
// 存在即返回, 空则由函数去产生
optionalUser.orElseGet(() -> anoymos());
// 存在即返回, 否则抛出异常
optionalUser.orElseThrow(RuntimeException::new);
// 存在才去做相应的处理
optionalUser.ifPresent(u -> System.out.println(u.getName()));
// map 可以对 Optional 中的对象执行某种操作, 且会返回一个 Optional 对象
optionalUser.map(u -> u.getName()).orElse("anymos");
// map 是可以无限级联操作的
optionalUser.map(u -> u.getName()).map(name -> name.length()).orElse(0);
}
}对应代码:src/main/java/com/imooc/java/escape/ExceptionProcess.java
对应代码:src/main/java/com/imooc/java/escape/GeneralException.java
public class GeneralException {
public static class User {
....
}
public static class Manager extends User {}
public static class Worker extends User {}
private static final Map<String, StaffType> typeIndex = new HashMap<>(
StaffType.values().length
);
static {
for (StaffType value : StaffType.values()) {
typeIndex.put(value.name(), value);
}
}
private static void concurrentModificationException(ArrayList<User> users) {
// 直接使用 for 循环会触发并发修改异常
// for (User user : users) {
// if (user.getName().equals("imooc")) {
// users.remove(user);
// }
// }
// 使用迭代器则没有问题
Iterator<User> iter = users.iterator();
while (iter.hasNext()) {
User user = iter.next();
if (user.getName().equals("imooc")) {
iter.remove();
}
}
}
private static StaffType enumFind(String type) {
// return StaffType.valueOf(type);
// 1. 最普通、最简单的实现
// try {
// return StaffType.valueOf(type);
// } catch (IllegalArgumentException ex) {
// return null;
// }
// 2. 改进的实现, 但是效率不高
// for (StaffType value : StaffType.values()) {
// if (value.name().equals(type)) {
// return value;
// }
// }
// return null;
// 3. 静态 Map 索引, 只有一次循环枚举的过程
// return typeIndex.get(type);
// 4. 使用 Google Guava Enums, 需要相关的依赖
return Enums.getIfPresent(StaffType.class, type).orNull();
}
public static void main(String[] args) {
// 1. 并发修改异常
// ArrayList<User> users = new ArrayList<User>(
// Arrays.asList(new User("qinyi"), new User("imooc"))
// );
// concurrentModificationException(users);
// 2. 类型转换异常
// User user1 = new Manager();
// User user2 = new Worker();
// Manager m1 = (Manager) user1;
// Manager m2 = (Manager) user2;
// System.out.println(user2.getClass().getName());
// System.out.println(user2 instanceof Manager);
// 3. 枚举查找异常
System.out.println(enumFind("RD"));
System.out.println(enumFind("abc"));
}
}同2-6对应代码:src/main/java/com/imooc/java/escape/GeneralException.java
对应代码:src/main/java/com/imooc/java/escape/try_with_resources/*
笔记:针对需要释放的资源可以使用java7 引入的 try with resources 实现自动的资源关闭,自己可以实现AutoCloseable接口中的close()方法同样可以使用 try with resources 实现自动的资源关闭。
/**
* <h2>传统的方式实现对资源的关闭</h2>
* */
private String traditionalTryCatch() throws IOException {
// 1. 单一资源的关闭
// String line = null;
// BufferedReader br = new BufferedReader(new FileReader(""));
// try {
// line = br.readLine();
// } finally {
// br.close();
// }
// return line;
// 2. 多个资源的关闭
// 第一个资源
InputStream in = new FileInputStream("");
try {
// 第二个资源
OutputStream out = new FileOutputStream("");
try {
byte[] buf = new byte[100];
int n;
while ((n = in.read(buf)) >= 0)
out.write(buf, 0, n);
} finally {
out.close();
}
} finally {
in.close();
}
return null;
}
/**
* <h2>java7 引入的 try with resources 实现自动的资源关闭</h2>
* */
private String newTryWithResources() throws IOException {
// 1. 单个资源的使用与关闭
// try (BufferedReader br = new BufferedReader(new FileReader(""))) {
// return br.readLine();
// }
// 2. 多个资源的使用与关闭
try (FileInputStream in = new FileInputStream("");
FileOutputStream out = new FileOutputStream("")
) {
byte[] buffer = new byte[100];
int n = 0;
while ((n = in.read(buffer)) != -1) {
out.write(buffer, 0, n);
}
}
return null;
}无论什么业务开发,都离不开计算和集合数据结构的使用,频繁的使用带来频繁的出错显然是不能接受的,本章会让你看到最常见的错误以及解决办法;初学者常常会混淆接口和抽象类,尤其是 Java8 增加了默认和静态方法以后,这种情况就更加严重了,本章会教你怎样正确的使用和理解它们。
对应代码:src/main/java/com/imooc/java/escape/NumberAndTime.java
笔记:BigDecimal计算时,需要使用对应的方法进行计算,BigDecimal最重要的是精度,不能用简单的加减乘除符号进行计算。
同3-1对应代码:src/main/java/com/imooc/java/escape/NumberAndTime.java
笔记:
- BigDecimal 做除法时出现除不尽的情况,可以采用舍去方式,比如常见的BigDecimal.ROUND_HALF_UP四舍五入方式。
- 精度问题导致比较结果和预期的不一致,比较两个精度不一样的BigDecimal类型,必须使用compareTo方法。
- SimpleDateFormat 可以解析大于/等于它定义的时间精度,否则会抛出异常。
同3-1对应代码:src/main/java/com/imooc/java/escape/NumberAndTime.java
笔记:SimpleDateFormat不安全的原因就是它继承的是DateFormat,然而DateFormat中维护的Calendar并不是线程安全的,所以在多线程的情况下还是会被多个线程共享。
对应代码:src/main/java/com/imooc/java/escape/ForeachOptimize.java
同3-4对应代码:src/main/java/com/imooc/java/escape/ForeachOptimize.java
对应代码:src/main/java/com/imooc/java/escape/EqualOrElse.java
笔记:集合存储,一定要实现equals和hashcode方法,集合元素索引与 equals 方法相关。
对应代码:src/main/java/com/imooc/java/escape/lombok_/*
笔记:
- lombok针对单字母驼峰形式会全部变为小写,比如iPhone序列化和反序列化后是iphone。
- 针对于存在集成关系的类做比较,如果存在继承关系,默认对比的是子类的属性,需要通过@EqualsAndHashCode(callSuper = true)注解进行处理。
对应代码:src/main/java/com/imooc/java/escape/abstract_interface/*
笔记:类是对客观事物发抽象,共同属性使用抽象类进行抽象,独立的属性使用接口实现。举例:对于一个员工(Worker),起床、上下班可以用抽象类表示,而工作内容写代码,测试,兴趣爱好等则用接口,毕竟并不是所有Worker都用写代码和有兴趣爱好。
同3-8对应代码:src/main/java/com/imooc/java/escape/abstract_interface/*
笔记:java8允许接口有默认方法和静态方法,实现类可以不实现默认方法,若实现了则使用子类实现,静态方法则可以把一些工具方法直接写在接口里。
对应代码:src/main/java/com/imooc/java/escape/function_interface_lambda/*
笔记:lambda表达式一定对应的是函数式接口,函数式接口表示有且仅有一个抽象方法的接口。
同3-10对应代码:src/main/java/com/imooc/java/escape/function_interface_lambda/*
笔记:针对于复杂的迭代过程形成中间状态,没有手动迭代一次效率高,因为stream每一次迭代都是调用函数形成新流,比如下方例子:
/**
* <h2>Stream 和 lambda 可能导致计算低效</h2>
* */
private static void badUseLambda() {
List<String> names = Arrays.asList("qinyi", "imooc");
int longestNameSize =
names.stream()
.filter(s -> s.startsWith("q"))
.mapToInt(String::length)
.max()
.getAsInt();
int longest = 0;
for (String str : names) {
if (str.startsWith("q")) {
int len = str.length();
longest = Math.max(len, longest);
}
}
System.out.println(longest);
}泛型和反射都属于 Java 语言的高级特性,初学者容易引发各种异常和问题,本章带你剖析、理解并学会使用这些高级特性;虽然编译器会对我们的代码做优化,但是并不一定每次都是合理的,所以,我们不能依赖编译器的优化,本章也会带你解析这个问题。
对应代码:src/main/java/com/imooc/java/escape/serialization/*
笔记:建议所有实体类都实现Serializable接口,没得任何问题。
同4-1对应代码:src/main/java/com/imooc/java/escape/serialization/*
对应代码:src/main/java/com/imooc/java/escape/Genericity.java
对应代码:src/main/java/com/imooc/java/escape/Genericity.java
对应代码:src/main/java/com/imooc/java/escape/DoNotUseRawType.java
笔记:泛型最好指定类型,不要使用原始类型,比如List data = new ArrayList();,若实在不知道是什么类型,写成List data = new ArrayList();也可以。
对应代码:src/main/java/com/imooc/java/escape/reflect/*
笔记:
-
方法的参数是基本类型,反射获取 Method 参数类型必须一致。
-
调用的方法属于对象的父类, getDeclaredMethod 会抛出异常
-
可以通过递归寻找父类方法实现:
private static Method getMethod(Class<?> target, String methodName, Class<?>[] argTypes) { Method method = null; try { method = target.getDeclaredMethod(methodName, argTypes); method.setAccessible(true); } catch (NoSuchMethodException ex) { System.out.println("can not get method: " + methodName + " from " + target.getName()); } if (method == null && target != Object.class) { return getMethod(target.getSuperclass(), methodName, argTypes); } return method; }
同4-6对应代码:src/main/java/com/imooc/java/escape/reflect/*
对应代码:src/main/java/com/imooc/java/escape/StringContact.java
笔记:简单的+号拼接字符串编译后会自动优化StringBuilder进行拼接,但是若在循环中使用拼接则不会自动优化。
private static void implicitUseStringBuilder(String[] values) {
String result = "";
// 这样编译后并不会做任何优化,会每次都new StringBuilder()
for (int i = 0; i < values.length; ++i) {
result += values[i];
}
System.out.println(result);
}
private static void explicitUseStringBuilder(String[] values) {
// 自己定义StringBuilder则会优化
StringBuilder result = new StringBuilder();
for (int i = 0; i < values.length; ++i) {
result.append(values[i]);
}
System.out.println(result.toString());
}对应代码:src/main/java/com/imooc/java/escape/clone/*
对应代码:src/main/java/com/imooc/java/escape/clone/*
笔记:
- Java 中 Object 中的 clone 方法默认是浅拷贝,针对引用类型执行的是同一个地址;
- 实现深拷贝的三种方式:
- 第一种方式:直接通过 new 对象创建新的对象,通过 new 出来的对象肯定是在内存中重新开辟一块空间存储所以可以实现深拷贝;
- 第二种方式:通过调用父类clone再进行重新复制,虽然调用父类 Native 修饰的 clone 方法比第一种方式速度快,此步骤如果继承类中有多个引用类型克隆相对麻烦;
- 第三种方式:通过序列化和反序列化使用流进行深拷贝(注意类都要实现 Serializable 接口),因为保存在流中的数据相当于新的,若要实现对象深拷贝,推荐使用此方式。
关于线程安全、多线程等等诸如此类的问题,可谓是难倒了一大批 Java 初学者,之所以会这样,是因为没有思路、没有方法去攻破这一类知识点,本章将带着你领略线程安全、多线程的魅力,让你学会正确、合理的使用它们。
对应代码:src/main/java/com/imooc/java/escape/synchronized_/*
对应代码:src/main/java/com/imooc/java/escape/Atomic_.java
笔记:使用原子类AtomicInteger进行加减实现线程安全。CAS原理:比较并替换,但是并不能解决ABA问题。
对应代码:src/main/java/com/imooc/java/escape/blocking_queue/*
笔记:队列空则等,队列满则等。
| 方式 | 有返回值,抛出异常 | 有返回值,不抛出异常 | 没有返回值,阻塞等待 | 有返回值,超时等待 |
|---|---|---|---|---|
| 添加 | add() | offer() | put() | offer()) |
| 移除 | remove() | poll() | take() | pull() |
| 检测队首元素 | element() | peek() | - | - |
对应代码:src/main/java/com/imooc/java/escape/copy_on_write/*
笔记:Copy-On-Write:复制并写入,并发读不需要加锁,提高了程序的并发度,但是会引发内存占用问题,并且只能保证最终一致性并不能保证瞬时一致性,若对于立马修改的值就要查询到就不能使用copy-on-write,适合场景是读多写少的并发场景,如白名单、黑名单。
对应代码:src/main/java/com/imooc/java/escape/threadpool/*
笔记:线程池七大参数:
-
corePoolSize(核心线程数):创建线程池后不会立即创建核心线程,当有任务到达时才触发核心线程的创建;核心线程会一直存活,即使没有任务需要执行;当线程数小于核心线程数时,即使有线程空闲,线程池也会优先创建新线程处理。(设置allowCoreThreadTimeout=true(默认false)时,核心线程会超时摧毁)
-
maximumPoolSize(最大线程数):当线程数>=corePoolSize且任务队列已满时线程池会创建新线程来处理任务;当线程数=maximumPoolSize,且任务队列已满时,线程池会根据配置的拒绝策略处理任务。
-
keepAliveTime(线程空闲时间):当线程空闲时间达到keepAliveTime时,线程会摧毁,直到线程数量=corePoolSize。(如果allowCoreThreadTimeout=true,则会直到线程数量=0)
-
unit(keepAliveTime的计量单位)
-
workQueue (工作队列):新任务被提交且核心线程数满后,会进入到此工作队列中,任务调度从队列中取出任务。
- SynchronousQueue(直接提交队列):没有容量的容器,每一个插入的操作都要等待相应的删除操作,不保存任务,它总是马上将任务提交给线程执行,如果没有空闲的线程则会尝试创建新的线程,如果线程数量已经达到最大值,则执行拒绝策略,使用次队列通常需要设置很大的maximumPoolSize;
- ArrayBlockingQueue:基于数组的有界阻塞队列,按FIFO排序;
- LinkedBlockingQuene:基于链表的无界阻塞队列(其实最大容量为Interger.MAX),按照FIFO排序,若任务创建和处理速度差异很大,无界队列会快速膨胀导致系统资源耗尽;
- PriorityBlockingQueue:是一个特殊的无界队列,创建此队列时可以传入Comparator对任务进行优先级处理。
-
threadFactory(创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等)
-
handler(拒绝策略):所有拒绝策略实现RejectedExecutionHandler接口,读者可根据实际情况扩展该接口实现自己的拒绝策略 。
- AbortPolicy策略:该策略会直接抛出异常 ;
- CallerRunsPolicy策略:只要线程池未关闭,该策略直接在调用者线程中运行当前被放弃任务 ;
- DiscardOledestPolicy策略:丢弃最老的一个请求,也就是丢弃一个即将被执行的任务,并尝试再提交当前任务 ;
- DiscardPolicy策略:该策略丢弃无法处理的任务,不做任何处理 。
同5-5对应代码:src/main/java/com/imooc/java/escape/threadpool/*
笔记:JDK自带的四个线程池
- newFixedThreadPool (固定大小线程池,核心线程池与最大线程池一致,队列大小为Integer.MAX_VALUE):每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小;线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
- newCachedThreadPool(可缓存线程池):核心线程数为0 ,最大线程数Integer.MAX_VALUE ,队列为SynchronousQueue(直接提交队列);如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲( 60 秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务;此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说 JVM )能够创建的最大线程大小。
- newScheduledThreadPool (创建一个定长线程池,支持定时及周期性任务执行):核心线程数为传入值,最大线程数为Integer.MAX_VALUE,采用优先级队列DelayedWorkQueue;适用场景:调用第三方返回中间状态,可用此状态先轮训查询状态。
- newSingleThreadExecutor (单线程化的线程池):核心线程数与最大线程数都为1,队列大小为Integer.MAX_VALUE;只有一个线程在工作,也就是相当于单线程串行执行所有任务;如这个唯一的线程因为异常结束,那么会有一个新的线程来替代它;此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
对应代码:src/main/java/com/imooc/java/escape/threadpool/ExecutorsUtil.java
笔记:通过继承ThreadPoolExecutor类进行自定义线程池。
对应代码:src/main/java/com/imooc/java/escape/thread_local/*
笔记:ThreadLocal 不支持继承;ThreadLocal使用场景:每个线程需要自己独立的实例切该实例需要在多个地方方法中被使用。
同5-8对应代码:src/main/java/com/imooc/java/escape/thread_local/*
笔记:在线程池中使用 ThreadLocal使用完需要及时清理现场。
/**
* <h1>在线程池中使用 ThreadLocal</h1>
* */
public class ThreadLocalValueHolder {
private static final ThreadLocal<Integer> holder = ThreadLocal.withInitial(
() -> 0
);
public static int getValue() {
return holder.get();
}
public static void remove() {
holder.remove();
}
public static void increment() {
holder.set(holder.get() + 1);
}
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(3);
for (int i = 0; i != 15; ++i) {
executor.execute(
() -> {
try {
long threadId = Thread.currentThread().getId();
int before = getValue();
increment();
int after = getValue();
// System.out.println("before: " + before + ", after: " + after);
System.out.println("threadId: " + threadId +
", before: " + before + ", after: " + after);
} finally {
remove();
}
}
);
}
executor.shutdown();
}
}对于初学 Spring 的同学来说,能够用好 Spring 是一件不容易的事,关于 Bean 的名称、自动注入、容器与上下文的理解、Scope、循环依赖、事务等等问题是层出不穷,本章将会带着你读懂 Spring 的特性,理解并用好 Spring。
笔记:spring bean生成策略,若首字母是大写,并且第二个字母也是大写,就直接不变进行命名,否则就是取首字母小写进行命名,如ABcService,生成的bean名字就是ABcService,若是AbcService,则生成的是abcService,生成源码如下:
public static String decapitalize(String name) {
if (name == null || name.length() == 0) {
return name;
}
// 若是是第一个字母大写,第二个字母还是大写,直接返回bean名字
if (name.length() > 1 && Character.isUpperCase(name.charAt(1)) &&
Character.isUpperCase(name.charAt(0))){
return name;
}
char chars[] = name.toCharArray();
// 否则直接把第一个字母变小写返回
chars[0] = Character.toLowerCase(chars[0]);
return new String(chars);
}笔记:通过@Autowired要注入的bean一定要是springioc容器管理的,不能自己new出来,否则无法注入,并且要通过@ComponseScan注解进行扫描加了注解的所有包,默认是扫描启动类及其子包。
笔记:保存并获取应用上下文ApplicationContext三种方式,通过启动时保存应用上下文到ApplicationContextStore,1、实现ApplicationContextAware接口setApplicationContext()方法,2、实现ApplicationListener接口的onApplicationEvent()方法,3、实现ApplicationContextInitializer接口的initialize()方法进行保存上下文,然后用于后期使用。
/**
* <h1>保存应用上下文</h1>
* */
@Slf4j
public class ApplicationContextStore {
private static ApplicationContext applicationContext;
public static void setApplicationContext(ApplicationContext applicationContext) {
log.info("Coming In ApplicationContextStore!");
ApplicationContextStore.applicationContext = applicationContext;
}
public static ApplicationContext getApplicationContext() {
return ApplicationContextStore.applicationContext;
}
}笔记:默认获取容器里的是单例bean,若需要重复获取是全新的bean,则需要改成原型模式,用注解@Scope(BeanDefinition.SCOPE_PROTOTYPE)
笔记:注解区分。
@Autowired:属于spring框架,默认使用类型(byType)进行自动注入。
@Qualifier:结合@Autowired注解使用,自动注入策略由类型(byType)变为名字(byName)自动注入,相结合可以根据名字和类型注入。
@Resource:J2EE自带注解, JSR-250规范,默认按照名字(byName)进行自动注入,其次按照类型搜索。
@Primary:注释在bean上,存在多个相同的bean,用于标记首选。
@PostConstruct:相当于init-method,使用在方法上,当Bean初始化时执行。
@PreDestroy:相当于destory-method,使用在方法上,当Bean销毁时执行。
笔记:
-
spring对于单例的bean使用注解方式可以自动解决循环依赖,内部使用的三级缓存自动进行处理。
-
三级缓存以及作用:
-
一级缓存(singletonObjects):用于存放完全初始化好的bean。
-
二级缓存(earlySingletonObjects):存放原始的bean对象(尚未填充属性),用于解决循环依赖。
-
三级缓存(singletonFactories):存放bean的工厂对象,用于解决循环依赖。
源码:
@Nullable protected Object getSingleton(String beanName, boolean allowEarlyReference) { Object singletonObject = this.singletonObjects.get(beanName); if (singletonObject == null && this.isSingletonCurrentlyInCreation(beanName)) { synchronized(this.singletonObjects) { singletonObject = this.earlySingletonObjects.get(beanName); if (singletonObject == null && allowEarlyReference) { ObjectFactory<?> singletonFactory = (ObjectFactory)this.singletonFactories.get(beanName); if (singletonFactory != null) { singletonObject = singletonFactory.getObject(); this.earlySingletonObjects.put(beanName, singletonObject); this.singletonFactories.remove(beanName); } } } } return singletonObject; }
-
-
自动注入的三种方式:
-
注解注入,也称为Field注入
// Field @Autowired private QinyiJavaService javaService;
-
Setter方式注入
private QinyiJavaService javaService; @Autowired public void setQinyiJavaService(QinyiJavaService javaService) { this.javaService = javaService; }
-
构造方法注入(不能自动解决循环依赖)
private final QinyiJavaService javaService; @Autowired public ImoocCourseService(QinyiJavaService javaService) { this.javaService = javaService; }
-
笔记:
使用beanPostProcessor实现一个视频解码器:对应代码:src/main/java/com/imooc/spring/escape/bean_post_processor/*
@Slf4j
@Service
public class DecoderManager implements BeanPostProcessor {
private static final Map<VideoType, IDecoder> videoTypeIndex = new HashMap<>(
VideoType.values().length
);
public String decode(VideoType type, String data) {
String result = null;
switch (type) {
case AVI:
result = videoTypeIndex.get(VideoType.AVI).decode(data);
break;
case WMV:
result = videoTypeIndex.get(VideoType.WMV).decode(data);
break;
default:
log.info("error");
}
return result;
}
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName)
throws BeansException {
if (!(bean instanceof IDecoder)) {
return bean;
}
IDecoder decoder = (IDecoder) bean;
VideoType type = decoder.type();
if (videoTypeIndex.containsKey(type)) {
throw new IllegalStateException("重复注册");
}
log.info("Load Decoder {} for video type {}", decoder.getClass(),
type.getDesc());
videoTypeIndex.put(type, decoder);
return null;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName)
throws BeansException {
if (!(bean instanceof IDecoder)) {
return bean;
}
log.info("BeanPostProcessor after init: {}", bean.getClass());
return null;
}
}笔记:
SpringBean的生命周期:

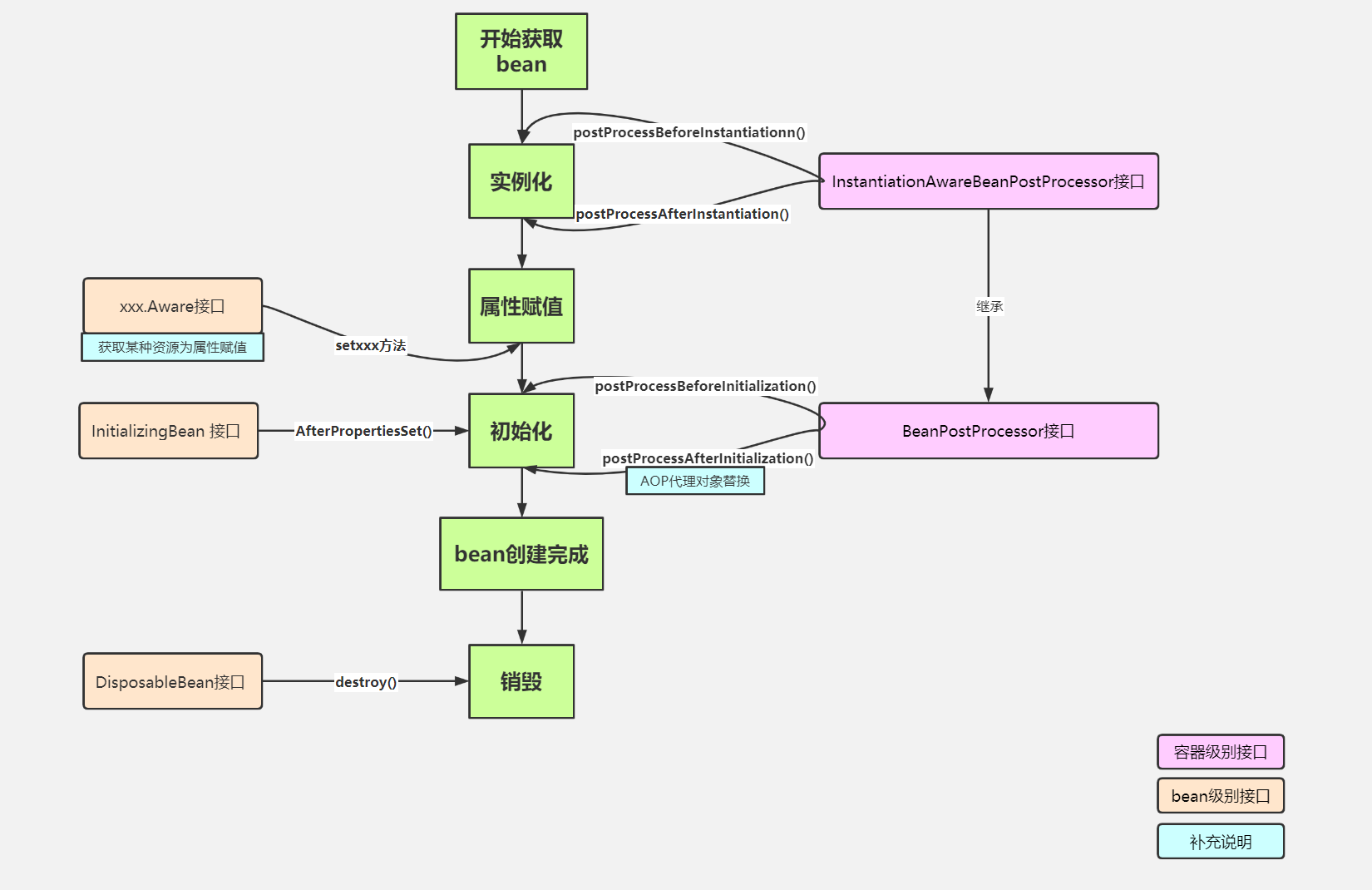
笔记:对应代码:src/main/java/com/imooc/spring/escape/transaction_lost/*
都标记了@Transactional注解,是否能回滚?
-
主动捕获了异常, 事务不能回滚;
-
不是 运行时异常(unchecked) 异常, 事务不能回滚
-
主动抛出运行时(unchecked )异常,可以回滚
-
主动指定回滚异常@Transactional(rollbackFor = {CustomException.class}),可以回滚
-
未标记注解的方法调用标记注解的方法,不能回滚
-
注解标记在不是public方法上,不能回滚
相信你一定遇到过响应码、序列化与反序列化方面的问题,且可能还分不清拦截器和过滤器有什么区别、如何去使用,以及流在读取过程中出现的方法互斥问题,本章将带着你理解这些特性,规避常见的错误用法。
对应代码:src/main/java/com/imooc/spring/escape/http_status_code/*
笔记:全局统一异常处理:
/**
* <h1>全局统一异常处理</h1>
* */
@RestControllerAdvice
public class GlobalExceptionAdvice {
@ExceptionHandler(value = CustomException.class)
public ResponseEntity<GeneralResponse<String>> handleCustomException(
HttpServletRequest request, CustomException ex
) {
GeneralResponse<String> result = new GeneralResponse<>(0, "");
result.setData(ex.getMessage());
return new ResponseEntity<>(result, HttpStatus.BAD_REQUEST);
}
}对应代码:src/main/java/com/imooc/spring/escape/date_se_de/*
笔记:
如果自定义一个时间反序列化器:
@Slf4j
public class DateJacksonConverter extends JsonDeserializer<Date> {
private static final String[] pattern = new String[] {
"yyyy-MM-dd HH:mm:ss", "yyyy/MM/dd"
};
@Override
public Date deserialize(JsonParser jsonParser, DeserializationContext context)
throws IOException, JsonProcessingException {
Date targetDate = null;
String originDate = jsonParser.getText();
if (StringUtils.isNotEmpty(originDate)) {
try {
long longDate = Long.parseLong(originDate.trim());
targetDate = new Date(longDate);
} catch (NumberFormatException pe) {
try {
targetDate = DateUtils.parseDate(
originDate, DateJacksonConverter.pattern
);
} catch (ParseException ex) {
log.error("parse error: {}", ex.getMessage());
throw new IOException("parse error");
}
}
}
return targetDate;
}
@Override
public Class<?> handledType() {
return Date.class;
}
}
//配置:
@Configuration
public class DateConverterConfig {
@Bean
public DateJacksonConverter dateJacksonConverter() {
return new DateJacksonConverter();
}
@Bean
public Jackson2ObjectMapperFactoryBean jackson2ObjectMapperFactoryBean(
@Autowired DateJacksonConverter dateJacksonConverter) {
Jackson2ObjectMapperFactoryBean jackson2ObjectMapperFactoryBean =
new Jackson2ObjectMapperFactoryBean();
jackson2ObjectMapperFactoryBean.setDeserializers(dateJacksonConverter);
return jackson2ObjectMapperFactoryBean;
}
}
//标记注解使用
@JsonDeserialize(using = DateJacksonConverter.class)
private Date birthday;对应代码:src/main/java/com/imooc/spring/escape/filter_and_interceptor/*
笔记:
日志使用过滤器:
@Slf4j
@WebFilter(urlPatterns = "/*", filterName = "LogFilter")
public class LogFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
long start = System.currentTimeMillis();
chain.doFilter(request, response);
log.info("LogFilter Print Log: {} -> {}",
((HttpServletRequest) request).getRequestURI(),
System.currentTimeMillis() - start);
}
@Override
public void destroy() {
}
}日志使用拦截器:
@Slf4j
@Component
public class LogInterceptor implements HandlerInterceptor {
long start = System.currentTimeMillis();
@Override
public boolean preHandle(HttpServletRequest request,
HttpServletResponse response, Object handler)
throws Exception {
start = System.currentTimeMillis();
HandlerMethod handlerMethod = (HandlerMethod) handler;
log.info("LogInterceptor: {}", ((HandlerMethod) handler).getBean()
.getClass().getName());
log.info("LogInterceptor: {}", handlerMethod.getMethod().getName());
return true;
}
@Override
public void postHandle(HttpServletRequest request,
HttpServletResponse response, Object handler,
ModelAndView modelAndView) throws Exception {
log.info("LogInterceptor Print Log: {} -> {}",
request.getRequestURI(),
System.currentTimeMillis() - start);
}
@Override
public void afterCompletion(HttpServletRequest request,
HttpServletResponse response, Object handler,
Exception ex) throws Exception {
}
}
//多线程使用:
@Slf4j
@Component
public class UpdateLogInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request,
HttpServletResponse response,
Object handler) throws Exception {
request.setAttribute("startTime", System.currentTimeMillis());
return true;
}
@Override
public void postHandle(HttpServletRequest request,
HttpServletResponse response, Object handler,
ModelAndView modelAndView) throws Exception {
log.info("UpdateLogInterceptor Print Log: {} -> {}",
request.getRequestURI(),
System.currentTimeMillis() - (long) request.getAttribute("startTime"));
}
@Override
public void afterCompletion(HttpServletRequest request,
HttpServletResponse response,
Object handler, Exception ex) throws Exception {
}
}配置拦截器:
@Component
@Configuration
public class WebInterceptorAdapter implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new LogInterceptor()).addPathPatterns("/**").order(0);
}
}对应代码:src/main/java/com/imooc/spring/escape/http_request_response/*
笔记:
-
Request的getInputStream()和getReader()都只能使用一次
-
Request的getInputStream()、getReader()、getParameter()方法互斥,也就是使用了其中一个,再使用另外两个,是获取不到数据的。
-
Response和Request几乎是一样的。
-
解决方法:可以使用HttpServletRequestWrapper+Filter使用重复读取
SpringBoot 依赖于配置,但是你搞清楚配置优先级的问题了吗?定时任务和异步任务写起来很简单,但是出现了问题如何去排查解决呢?默认的 Jackson工具你又了解多少呢?本章将带着你正确的使用这些特性和知识点。
笔记:
-
内部加载文件顺序:
springboot启动会扫描以下位置的application.properties或者application.yml文件作为Spring boot的默认配置文件
–file:./config/
–file:./
–classpath:/config/
–classpath:/
优先级由高到底,高优先级的配置会覆盖低优先级的配置;如果所有的文件配置了一样的信息,会进行覆盖,但是加载的时候会进行互补配置。
-
外部加载配置文件顺序(扩展):
SpringBoot也可以从以下位置加载配置; 优先级从高到低;高优先级的配置覆盖低优先级的配置,所有的配置会形成互补配置 1.命令行参数 (加载时优先加载) 所有的配置都可以在命令行上进行指定 java -jar spring-boot-02-config-02-0.0.1-SNAPSHOT.jar --server.port=8087 --server.context-path=/abc 多个配置用空格分开; --配置项=值 2.来自java:comp/env的JNDI属性 3.Java系统属性(System.getProperties()) 4.操作系统环境变量 5.RandomValuePropertySource配置的random.*属性值 由jar包外向jar包内进行寻找 优先加载带profile 6.jar包外部的application-{profile}.properties或application.yml(带spring.profile)配置文件。 7.jar包内部的application-{profile}.properties或application.yml(带spring.profile)配置文件。 再加载不带profile 8.jar包外部的application.properties或application.yml(不带spring.profile)配置文件。 9.jar包内部的application.properties或application.yml(不带spring.profile)配置文件。 10.@Configuration注解类上的@PropertySource 11.通过SpringApplication.setDefaultProperties指定的默认属性
对应代码:src/main/java/com/imooc/spring/escape/scheduled_task/*
笔记:使用注解@EnableScheduling和@Scheduled,多个定时任务不能同时执行大多数原因是使用springboot默认线程池是1,需要修改任务线程数即可。
spring:
task:
scheduling:
pool:
size: 5自定义配置类方式配置:
@Configuration
public class ScheduleConfig {
@Bean
public TaskScheduler taskScheduler() {
ThreadPoolTaskScheduler taskScheduler = new ThreadPoolTaskScheduler();
taskScheduler.setPoolSize(5);
return taskScheduler;
}
}对应代码:src/main/java/com/imooc/spring/escape/async_task/*
笔记:使用注解@EnableAsync和@Async进行开启异步任务。
-
修改定时任务配置:
spring: task: execution: thread-name-prefix: imooc-qinyi-task- pool: core-size: 2 max-size: 8
-
通过配置类方法配置:
@Slf4j @Configuration public class AsyncTaskConfig implements AsyncConfigurer { @Override public Executor getAsyncExecutor() { ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); executor.setThreadNamePrefix("imooc-qinyi-task-"); executor.setCorePoolSize(2); executor.setMaxPoolSize(8); executor.setKeepAliveSeconds(5); executor.setQueueCapacity(100); executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy()); executor.setWaitForTasksToCompleteOnShutdown(true); executor.setAwaitTerminationSeconds(60); executor.initialize(); return executor; } @Override public AsyncUncaughtExceptionHandler getAsyncUncaughtExceptionHandler() { return new AsyncUncaughtExceptionHandler() { @Override public void handleUncaughtException(Throwable ex, Method method, Object... params) { // 发送报警邮件, 短信等等 log.error("Async Task Has Some Error: {}, {}, {}", ex.getMessage(), method.getDeclaringClass().getName() + "." + method.getName(), Arrays.toString(params)); } }; } }
对应代码:src/main/java/com/imooc/spring/escape/use_jackson/*
笔记:
因为ObjectMapper是线程安全的,初始化比较耗时,配置ObjectMapper容器管理,减少每次new对象的时间,更加轻量
@Configuration
public class ObjectMapperConfig {
@Bean
@Primary
public ObjectMapper objectMapper() {
ObjectMapper mapper = new ObjectMapper();
// 忽略 json 字符串中不识别的字段
mapper.configure(
DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES,
false
);
return mapper;
}
}笔记:常用jackson注解,@JsonInclude(JsonInclude.Include.NON_NULL)、@JsonIgnoreProperties({"couponCode", "status"})、@JsonIgnore、@JsonProperty("user")、@JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "hh:mm:ss")等。
初学者一定要能够理解并正确的使用数据类型、索引和事务,这是数据库最基本的特性,之后逐步进阶到慢查询优化、学会分库分表等等,本章跟着我一起学习、理解这些知识点吧。
笔记:NULL类型在MySQL中存储是不好的,尽量用空串或者0去替代。因为NULL占用的空间并不是没有。
笔记:索引不是越多越好,联合索引只会匹配前缀,所以一定要注意。
笔记:只有命中索引才会走行锁,否则会上升为表级锁。
笔记:垂直拆分和水平拆分,通过两个Hash函数进行分库分表,能够均匀的落到每个数据库。
键值对类型的缓存看起来非常简单,但是,如何选择合适的数据结构并不是一件简单的事;在使用的过程中,还要考虑性能、内存优化、数据持久化、缓存的穿透和雪崩等等问题,这听起来就更加不容易了。不过,本章将会带着你逐个理解、攻破这些问题和知识点。
笔记:Redis内存耗尽,只允许读不允许写。
笔记:可以在配置文件中配置淘汰机制。
noeviction:禁止驱逐数据。默认配置都是这个。当内存使用达到阀值的时候,所有引起申请内存的命令都会报错。
volatile-lru:从设置了过期时间的数据集中挑选最近最少使用的数据淘汰。
volatile-ttl:从已设置了过期时间的数据集中挑选即将要过期的数据淘汰。
volatile-random:从已设置了过期时间的数据集中任意选择数据淘汰。
allkeys-lru:从数据集中挑选最近最少使用的数据淘汰。
allkeys-random:从数据集中任意选择数据淘汰。笔记:可以使用redis pipeline进行批量操作,但是注意这个需要客户端支持,并且不是原子性操作。
笔记:Redis持久化分为RDB和AOF,可以综合利用两种方式,让意外之丢失1s数据。
笔记:
-
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:
- 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
-
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
解决方案:
- 设置热点数据永远不过期。
- 加互斥锁,缓存中不存在数据需要拿到锁之后才能去数据库查询。
-
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
- 设置热点数据永远不过期。
java-escape 是 Java 语言基础相关的源代码,依赖于 JDK1.8 和 Maven
spring-escape 是 Spring、SpringMVC、SpringBoot 框架相关的源代码,依赖于 JDK1.8 和 Maven
MySQL 章节中使用到的数据表及 SQL 语句