基于神经网络的通用股票预测模型
A general stock prediction model based on neural networks
- 20230522
- 经过长时间的训练,分析和学习,我深深感觉到单纯使用lstm和transformer进行价格的预测是相当的困难。我下面的更新方向将向三个方向进行:一是开发一种新的模型以更加适配金融预测的特点; 二是继续完成NLP方向的情感分析,做到分析大众和专业机构的恐慌程度; 三是彻底重写一个新的预测程序,从预测价格转变为预测走势,降低预测的难度,提高预测的准确度。有能力或者有想法的朋友,欢迎给我提意见。
- After a long time of training, analysis and learning, I deeply feel that it is quite difficult to use lstm and transformer alone to predict prices. My update direction below will go in three directions: one is to develop a new model to better adapt to the characteristics of financial forecasting; the second is to continue to complete the sentiment analysis in the NLP direction, so as to analyze the panic degree of the public and professional institutions; the third is to completely rewrite a new prediction program, from predicting prices to predicting trends, reducing the difficulty of prediction and improving the accuracy of prediction. Friends with ability or ideas are welcome to give me advice.
- 20230508
- 增加支持时间区间训练及预测,predict_days参数为正数时,使用区间模型,为负数时,使用单点模型
- Add support for time interval training and prediction. When the predict_days parameter is a positive number, the interval model is used. When it is a negative number, the single point model is used.
- 20230506
- 按照原始论文,重新构建了transformer模型,使得训练速度提高20倍
- According to the original paper, the transformer model is reconstructed, which makes the training speed 20 times faster
- 20230502
- 增加使用yfinance接口下载数据,如果是**大陆用户,需要使用代理,或者使用其他接口
- Add the use of yfinance interface to download data. If you are a user in mainland China, you need to use a proxy or other interface.
- 20230501
- 支持可变维度的输入,可变长度的输入,最大输入维度需要在init.py中设置
- Support variable dimension input, variable length input, and the maximum input dimension needs to be set in init.py
- 修改删除nan数据整行的模式为将nan数据替换为-0.0
- Modify the mode of deleting the whole row of nan data to replace the nan data with -0.0
- 增加transformer模型的mask机制,以支持可变长度的输入
- Add the mask mechanism of the transformer model to support variable length input
- 修改很多数据处理及数据接口相关代码,目前默认是akshare接口,如果需要使用tushare,请自行修改代码, 且考虑删除对于tushare的支持,后期如需要使用tushare,请自行回退至上一个版本
- Modify a lot of data processing and data interface related code, the default is akshare interface, if you need to use tushare, please modify the code by yourself, and consider deleting the support for tushare. If you need to use tushare later, please roll back to the previous version by yourself.
- 修正了在akshare接口下,预测数据的bug
- Corrected the bug of predicting data under the akshare interface
- 20230428
- 增加新的数据接口,解决原接口速度慢,很多数据还需要付费的问题
- Add a new data interface to solve the problem of slow speed of the original interface and many data still need to be paid for.
- 增加了对于复权数据的支持,注意在tushare数据源中,复权数据是需要更高的权限的(付费)
- Added support for adjusted data. Note that in the tushare data source, adjusted data requires higher permissions (paid).
- 复权数据有其自身的优点和缺点,请自行选择不复权,前复权,后复权
- Adjusted data has its own advantages and disadvantages. Please choose unadjusted, pre-adjusted, and post-adjusted.
- 20230416
- 已尝试修复之前发现的bug,目前没有复发的问题,如果有问题,请及时反馈
- The bug found previously has been tried to be fixed, and there is no problem that has been reoccurred. If there is a problem, please feedback as soon as possible.
- 增加针对文字进行情感分析的模型,支持中文,目前仅有数据处理及训练的代码,尚未合并到预测功能中,有兴趣的朋友可以自行尝试,欢迎提出建议
- Add a model for sentiment analysis of text, supporting Chinese, with only data processing and training code at present, not yet merged into the prediction function. Friends who are interested can try it on their own, welcome to make suggestions.
- NLP的模型,由于版权和其他问题,我没有提供数据,或数据下载的方式,请自行寻找数据源,或者使用自己的数据源,需要的格式为csv文件,包含label和text两列,label为0或1,text为文本内容,如果有兴趣,可以自行尝试,欢迎提出建议。
- Due to copyright and other issues, I did not provide data or data download methods for the NLP model. Please find your own data source, or use your own data source. The required format is a csv file with two columns, label and text. The label is 0 or 1, and the text is the text content. If you are interested, you can try it on your own, welcome to make suggestions.
- 20230413
- 目前发现的bug: Bugs found so far:
- predict模式会倒是load data失败 (尝试修复)
- predict mode will fail to load data (try to fix)
- 长时间训练,有概率导致multiprocess.queue异常 (原因未知,请有能力的朋友帮我一起debug)
- long training time may cause multiprocess.queue exception (cause unknown, please help me debug if you are capable)
- 20230412
- 修复重大bug:计算输入维度时,少计算了初始的8个维度,更新了这个版本后,之前训练的模型将不能使用,需要重新训练;如果还需要使用之前的模型,请手工修改init.py中的INPUT_DIMENSION为20(最小为4,且不能小于输出维度OUTPUT_DIMENSION),并检查common.py中的add_target函数中的相关内容.
- Fix major bug: when calculating the input dimension, 8 dimensions were less calculated. After updating this version, the previously trained models will no longer be available and need to be retrained. If you still need to use the previous model, please manually modify INPUT_DIMENSION in init.py to 20 (minimum 4, and cannot be less than OUTPUT_DIMENSION), and check the related content in the add_target function in common.py.
- 20230402
- 修改dataset读取方式,使用data queue以及buffer,减少IO次数,提高训练速度
- Modify the dataset reading method to use data queue and buffer to reduce the number of IO operations and improve training speed.
- 将全局变量移动到init.py中,方便修改
- Move global variables to init.py for easy modification.
- 20230328
- 修改预处理数据文件格式,增加ts_code和date两个字段,方便后续使用
- Modify the format of the preprocessed data file, add two fields ts_code and date, for future use.
- 修改lstm和transformer模型,以支持混合长度输入
- Modify the lstm and transformer models to support mixed length input.
- 在transformer模型,增加了 decoder层,期望增加预测精度
- Added a decoder layer in the transformer model, hoping to increase the prediction accuracy.
- 20230327
- 修改了部分运行逻辑,配合load pkl预处理文件,极大的提高了训练速度
- Modified some running logic and used preprocessed pkl files to greatly improve training speed.
- 修正了一个影响极大的关于数据流方向的bug
- Corrected a bug that had a great impact on the direction of data flow.
- 尝试使用新的模型
- Tried a new model.
- 增加了一个新的指标,用于评估模型的好坏
- Added a new index to evaluate the quality of the model.
- 20230325
- 增加数据预处理功能,并能将预处理好的queue保存为pkl文件,减少IO损耗
- Add data preprocessing function and save the preprocessed queue as a pkl file to reduce IO loss.
- 修改不必要的代码
- Modify unnecessary code.
- 简化逻辑,减少时间负责度,方向是以空间换时间
- Simplify the logic and reduce the time burden. The direction is to trade space for time.
- 增加常见的指标,增加预测精度
- Add common indicators to increase prediction accuracy.
- 20230322
- 增加输出内容控制,可以自行定义输出的内容和数量
- Add output content control, you can define the content and quantity of the output yourself.
- 修改读取数据源为本地csv文件
- Modify the data source to local csv files.
- 修改IO逻辑,使用多线程读取指定文件夹下的csv文件,并存储到内存中,反复训练,减少IO次数
- Modify the IO logic to use multiple threads to read the csv files in the specified folder and store them in memory, repeatedly train, and reduce the number of IO operations.
- 修改lstm, transformer模型
- Modify the lstm and transformer models.
- 增加下载数据功能,请使用自己的api token
- Add download data function, please use your own api token.
-
- 使用getdata.py下载数据,或者使用自己的数据源,将数据放在stock_daily目录下
- Use getdata.py to download data, or use your own data source, and put the data in the stock_daily directory.
-
- 使用data_preprocess.py预处理数据,生成pkl文件,放在pkl_handle目录下(可选)
- Use data_preprocess.py to preprocess data and generate pkl files in the pkl_handle directory (optional).
-
- 调整train.py和init.py中的参数,先使用predict..py训练模型,生成模型文件,再使用predict.py进行预测,生成预测结果或测试比照图
- Adjust the parameters in train.py and init.py, first use predict..py to train the model, generate the model file, and then use predict.py to predict, generate the prediction results or test comparison chart.
-
- --model: 模型名称,目前支持lstm和transformer
- --model: model name, currently supports lstm and transformer
-
- --mode: 模式,目前支持train,test和predict
- --mode: mode, currently supports train, test and predict
-
- --pkl: 是否使用pkl文件,目前支持1和0
- --pkl: whether to use pkl files, currently supports 1 and 0
-
- --pkl_queue: 是否使用pkl队列模式,以增加训练速度,目前支持1和0
- --pkl_queue: whether to use pkl queue mode to increase training speed, currently supports 1 and 0
-
- --test_code: 测试代码,目前支持股票代码
- --test_code: test code, currently supports stock code
-
- --test_gpu: 是否使用gpu测试,目前支持1和0
- --test_gpu: whether to use gpu test, currently supports 1 and 0
-
- --predict_days: 预测天数,目前支持数字
- --predict_days: number of days to predict, currently supports numbers
-
- TRAIN_WEIGHT: 训练权重,目前支持小于等于1的数字
- TRAIN_WEIGHT: training weight, currently supports numbers less than or equal to 1
-
- SEQ_LEN: 序列长度,目前支持数字
- SEQ_LEN: sequence length, currently supports numbers
-
- BATCH_SIZE: 批量大小,目前支持数字
- BATCH_SIZE: batch size, currently supports numbers
-
- EPOCH: 训练轮数,目前支持数字
- EPOCH: number of training rounds, currently supports numbers
-
- LEARNING_RATE: 学习率,目前支持小于等于1的数字
- LEARNING_RATE: learning rate, currently supports numbers less than or equal to 1
-
- WEIGHT_DECAY: 权重衰减,目前支持小于等于1的数字
- WEIGHT_DECAY: weight decay, currently supports numbers less than or equal to 1
-
- SAVE_NUM_ITER: 保存模型间隔,目前支持数字
- SAVE_NUM_ITER: interval to save model, currently supports numbers
-
- SAVE_NUM_EPOCH: 保存模型间隔,目前支持数字
- SAVE_NUM_EPOCH: interval to save model, currently supports numbers
-
- SAVE_INTERVAL: 保存模型时间间隔(秒),目前支持数字
- SAVE_INTERVAL: interval to save model (seconds), currently supports numbers
-
- OUTPUT_DIMENSION: 输出维度,目前支持数字
-
OUTPUT_DIMENSION: output dimension, currently supports numbers -
- INPUT_DIMENSION: 输入维度,目前支持数字
-
INPUT_DIMENSION: input dimension, currently supports numbers -
- NUM_WORKERS: 线程数,目前支持数字
-
NUM_WORKERS: number of threads, currently supports numbers -
- PKL: 是否使用pkl文件,目前支持True和False
-
PKL: whether to use pkl files, currently supports True and False -
- BUFFER_SIZE: 缓冲区大小,目前支持数字
-
BUFFER_SIZE: buffer size, currently supports numbers -
- symbol: 股票代码,目前支持股票代码或Generic.Data表示全部已下载的数据
-
symbol: stock code, currently supports stock code or Generic.Data representing all downloaded data -
- name_list: 需要预测的内容名称
-
name_list: the name of the content to be predicted -
- use_list: 需要预测的内容开关,1表示使用,0表示不使用
-
use_list: switch for content to be predicted, 1 means use, 0 means not use
基本思路及创意来自于:MiaoChenglin125 由于原作者貌似已经放弃更新,我将继续按照现有掌握的新的模型和技术,继续迭代这个程序
The basic idea and creativity come from: MiaoChenglin125.
As the original author seems to have abandoned the updates, I will continue to iterate this program based on the new models and technologies that I have mastered.
-
- 20230501更新后,默认使用akshare获取数据,不再需要tushare的api token及以下流程,如由于特殊要求,必须使用tushare获取数据,请参考以下流程
- After the update on 20230501, the data is obtained by default using akshare, and the tushare api token and the following process are no longer required. If you must use tushare to obtain data due to special requirements, please refer to the following process.
-
- 在tushare 网站注册,并按要求获取足够的积分(到2023年3月为止,只需要修改下用户信息,就足够积分了,以后不能确定)
- Register on tushare website and obtain enough points as required (as of March 2023, only modifying user information is sufficient to obtain enough points, but it may not be guaranteed in the future).
-
- 在tushare 页面可以查看自己的api token
- You can view your api token on tushare.
-
- 在本项目根目录建立一个api.txt,并将获得的api token写入这个文件
- Create an api.txt file in the root directory of this project and write the api token you obtained into this file.
-
- 使用本项目getdata.py,即可自动下载日数据
- Use the getdata.py of this project to automatically download the daily data.
股票行情是引导交易市场变化的一大重要因素,若能够掌握股票行情的走势,则对于个人和企业的投资都有巨大的帮助。然而,股票走势会受到多方因素的影响,因此难以从影响因素入手定量地进行衡量。但如今,借助于机器学习,可以通过搭建网络,学习一定规模的股票数据,通过网络训练,获取一个能够较为准确地预测股票行情的模型,很大程度地帮助我们掌握股票的走势。本项目便搭建了**LSTM(长短期记忆网络)**成功地预测了股票的走势。
Stock market trends are an important factor in guiding changes in the trading market. If we can master the trend of stock market trends, it would be of great help for personal and enterprise investments. However, stock market trends are influenced by multiple factors, making it difficult to measure them quantitatively from the perspective of influencing factors. Fortunately, with the help of machine learning, we can build a network, learn a certain scale of stock data, and obtain a model that can predict stock market trends more accurately through network training, which greatly helps us to master the trend of stocks. This project uses LSTM (Long Short-Term Memory Network) to successfully predict stock trends.
首先在数据集方面,我们选择上证000001号,**平安股票(编号SZ_000001)数据集采用2016.01.01-2019.12.31股票数据,数据内容包括当天日期,开盘价,收盘价,最高价,最低价,交易量,换手率。数据集按照0.1比例分割产生测试集。训练过程以第T-99到T天数据作为训练输入,预测第T+1天该股票开盘价。(此处特别感谢Tushare提供的股票日数据集,欢迎大家多多支持)
First, in terms of the dataset, we chose the dataset of China Ping An stock (SZ_000001), which is the Shanghai Stock Exchange 000001 index. The stock data covers the period from January 1, 2016, to December 31, 2019, including the date, opening price, closing price, highest price, lowest price, trading volume, and turnover rate. The dataset is split into a test set and a training set in a 9:1 ratio. The training process takes data from T-99 to T days as input and predicts the opening price of the stock on day T+1. (Special thanks to Tushare for providing the daily stock dataset, and we encourage everyone to support them.)
在训练模型及结果方面,我们首先采用了LSTM(长短期记忆网络),它相比传统的神经网络能够保持上下文信息,更有利于股票预测模型基于原先的行情,预测未来的行情。LSTM网络帮助我们得到了很好的拟合结果,loss很快趋于0。之后,我们又采用比LSTM模型更新提出的Transformer Encoder部分进行测试。但发现,结果并没有LSTM优越,曲线拟合的误差较大,并且loss的下降较慢。因此本项目,重点介绍LSTM模型预测股票行情的实现思路。
In terms of training models and results, we first used LSTM (Long Short-Term Memory Network). Compared with traditional neural networks, LSTM can maintain context information, which is more conducive to predicting future market trends based on past trends. The LSTM network helped us achieve a good fitting result, and the loss quickly tended to 0. Then, we tested the Transformer Encoder part proposed by more updated models than LSTM. However, we found that the results were not superior to LSTM, and the fitting error was large, and the loss decreased slowly. Therefore, this project focuses on introducing the implementation of the LSTM model to predict stock market trends.
时间序列模型:时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征。这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺序的,同样大小的值改变顺序后输入模型产生的结果是不同的。
Time series model: Time series prediction analysis is to use the characteristics of the event time in the past period of time to predict the characteristics of the event in the future period of time. This is a relatively complex prediction modeling problem. Unlike the prediction of regression analysis models, time series models are dependent on the order of the occurrence of events. The same size of the value changes the order of input into the model to produce different results.
RNN:递归神经网络RNN每一次隐含层的计算结果都与当前输入以及上一次的隐含层结果相关。通过这种方法,RNN的计算结果便具备了记忆之前几次结果的特点。其中,x为输入层,o为输出层,s为隐含层,而t指第几次的计算,V,W,U为权重,第t次隐含层状态如下公式所示:
RNN (Recurrent Neural Network): The calculation result of each hidden layer of the recurrent neural network (RNN) is related to the current input and the previous hidden layer result. Through this method, the calculation result of RNN has the characteristic of memorizing the previous results. In the following formula, x is the input layer, o is the output layer, s is the hidden layer, and t indicates the calculation time, while V, W, U are weights. The formula for the t-th hidden layer state is as follows:
$$
St = f(UXt + WSt-1) (1)
$$

可见,通过RNN模型想要当前隐含层状态与前n次相关,需要增大计算量,复杂度呈指数级增长。然而采用LSTM网络可解决这一问题。
As we can see, if we want the current hidden layer state to be related to the previous n states through the RNN model, it requires a significant increase in computation, and the complexity grows exponentially. However, this problem can be solved by using the LSTM network.
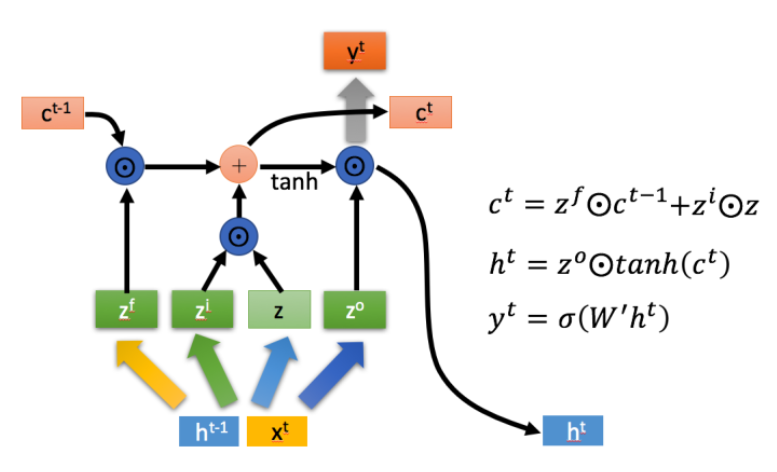
LSTM(长短期记忆网络)LSTM (Long Short-Term Memory Network):
LSTM是一种特殊的RNN,它主要是Eileen解决长序列训练过程中的梯度消失和梯度爆炸问题。相比RNN,LSTM更能够在长的序列中又更好的表现。
LSTM is a special RNN, which is mainly used to solve the problem of gradient disappearance and gradient explosion in the training process of long sequences. Compared with RNN, LSTM can perform better in long sequences.

LSTM拥有两个传输状态: 在 (cell state),
(hidden state),其中
的改变往往很慢,而
在不同的节点下会有很大的区别。
LSTM has two transmission states: in (cell state),
(hidden state),where the change of
is often slow, while the hidden state
can vary greatly at different nodes.
- 首先,使用LSTM的当前输入
和上一个状态传递下来的
得到四个状态:
,
,
,
,前三者为拼接向量乘以权重矩阵后使用sigmoid函数得到0-1之间的值作为门控状态,后者为通过tanh函数得到(-1)-1之间的值。
First, using the current input and the previous state
passed down by LSTM, four states are obtained:
,
,
,
,, where the first three are gate states obtained by using sigmoid function on the concatenated vector multiplied by the weight matrix, and the last one is obtained by using the tanh function to get values between -1 and 1.

-
LSTM内部有三个阶段:忘记阶段、选择记忆阶段、输出阶段 LSTM has three stages: the forget stage, the select memory stage, and the output stage.
-
**忘记阶段:**通过计算
来作为门控,控制上一个状态的
需要遗忘的内容。
-
**Forget stage: **By computing
-
**选择记忆阶段:**对输入
进行表示。
-
**Select memory stage: **Select memory for input
-
**输出阶段:**决定当前状态输出的内容,通过
进行放缩。
-
**Output stage: **Decide the content of the current state output, controlled by
-

1、数据集准备
1. Data set preparation
-
数据集分割:数据集按照0.1比例分割产生测试集。训练过程以第T-99到T天数据作为训练输入,预测第T+1天该股票开盘价。
-
Data Set Splitting: The data set is split into training and testing sets in a 0.1 ratio, with the testing set being 10% of the data. During training, the input for predicting the opening price of the stock on day T+1 is the stock market data from day T-99 to day T. Therefore, the training set comprises data from the first day to day T-99, and the testing set comprises data from day T to the end of the data set. This methodology ensures that the LSTM model is effectively trained on historical stock market data to make predictions for future stock market trends.
-
对数据进行标准化:训练集与测试集都需要按列除以极差。在训练完成后需要进行逆处理来获得结果。
-
Data normalization: Both the training set and the testing set need to be divided by the range of values along each column. After training is complete, the results need to be processed in reverse to obtain the results.
2、模型搭建
2. Model construction
使用pytorch框架搭建LSTM模型,torch.nn.LSTM()当中包含的参数设置:
When building an LSTM model using the PyTorch framework with the torch.nn.LSTM() module:
-
输入特征的维数: input_size=dimension(dimension=8)
-
The dimensionality of input features: input_size=dimension(dimension=8)
-
LSTM中隐层的维度: hidden_size=128
-
The dimension of the hidden layer in LSTM: hidden_size=128
-
循环神经网络的层数:num_layers=3
-
The number of layers of the recurrent neural network: num_layers=3
-
batch_first: TRUE
-
偏置:bias默认使用
-
Bias: bias is used by default
全连接层参数设置:
The parameter settings for the fully connected layer include:
-
第一层:in_features=128, out_featrues=16
-
The first layer: in_features=128, out_featrues=16
-
第二层:in_features=16, out_features=1 (映射到一个值)
-
The second layer: in_features=16, out_features=1 (mapped to a value)
3、模型训练
3. Model training
-
经过调试,确定学习率lr=0.00001
-
After debugging, a learning rate of lr=0.00001 was determined.
-
优化函数:批量梯度下降(SGD)
-
Optimization function: Stochastic Gradient Descent (SGD)
-
批大小batch_size=4
-
Batch size:batch_size=4
-
训练代数epoch=100
-
Train epochs: epoch=100
-
损失函数:MSELoss均方损失函数,最终训练模型得到MSELoss下降为0.8左右。
-
Loss function: MSELoss mean square loss function, the final training model obtained MSELoss down to about 0.8.
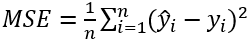

4、模型预测
4. Model prediction
测试集使用已训练的模型进行验证,与真实数据不叫得到平均绝对百分比误差(MAPELoss)为0.04,可以得到测试集的准确率为96%。
The trained model was used to validate the test set, and the average absolute percentage error (MAPELoss) was obtained as 0.04, indicating a testing accuracy of 96% compared to the ground truth data.

5、模型成果
5. Model results
下图是对整体数据集最后一百天的K线展示:当日开盘价低于收盘价则为红色,当日开盘价高于收盘价为绿色。图中还现实了当日交易量以及均线等信息。
The following figure shows the K-line display for the last hundred days of the entire dataset: red indicates that the opening price is lower than the closing price, while green indicates that the opening price is higher than the closing price. The figure also displays daily trading volume and moving average information.

LSTM模型进行预测的测试集结果与真实结果对比图,可见LSTM模型预测的结果和现实股票的走势十分接近,因此具有很大的参考价值。
The following figure shows the comparison between the test results predicted by the LSTM model and the real results. It can be seen that the predicted results of the LSTM model are very close to the actual trend of the stock, indicating that it has great reference value.

LSTM模型训练过程中MSELoss的变化,可以看到随着训练代数的增加,此模型的MSELoss逐渐趋于0。
The change of MSELoss during the training process of the LSTM model can be seen, and it can be observed that with the increase of training iterations, the MSELoss of the model gradually approaches 0.

本项目使用机器学习方法解决了股票市场预测的问题。项目采用开源股票数据中心的上证000001号,**平安股票(编号SZ_000001),使用更加适合进行长时间序列预测的LSTM(长短期记忆神经网络)进行训练,通过对训练集序列的训练,在测试集上预测开盘价,最终得到准确率为96%的LSTM股票预测模型,较为精准地实现解决了股票市场预测的问题。
This project uses machine learning methods to solve the problem of stock market prediction. The project uses the Shanghai Stock Exchange 000001, China Ping An stock (code SZ_000001) from an open-source stock data center and trains it using LSTM (Long Short-Term Memory Neural Network) which is more suitable for long-term sequence prediction. By training on the training set sequence and predicting the opening price on the test set, we obtained an LSTM stock prediction model with an accuracy rate of 96%, which effectively solves the problem of stock market prediction with high precision.
在项目开展过程当中,也采用过比LSTM更加新提出的Transformer模型,但对测试集的预测效果并不好,后期分析认为可能是由于在一般Transformer模型中由encoder和对应的decoder层,但在本项目的模型中使用了全连接层代替decoder,所以导致效果不佳。在后序的研究中,可以进一步改进,或许可以得到比LSTM更加优化的结果。
During the project, we also tried using the Transformer model, which is more recently proposed than LSTM. However, the prediction performance on the test set was not good. Further analysis revealed that this might be due to the fact that in the general Transformer model, there are encoder and corresponding decoder layers, but in our model, we used fully connected layers instead of the decoder. Therefore, the performance was not as good as expected. In future research, we can further improve the model or explore other approaches to potentially obtain better results than LSTM.