1 数据结构中各种东西的数量很很重要!!!可以考虑在在数据结构中定义一下
2 Java hashtable的contains用来查找是否存在value,和containsValue类似
查找key使用containskey方法,
3 hashtable查询的的时间复杂度为O(1)可以使用put和get方法存储查询数据。List类使用add和get。
4 new HashMap<String, Hashtable<String,Double>>(); 定义的这个数据结构中,如果每次都hashMap.put(string, new hashtable<>)的话会覆盖掉之前的hashtable,所以最好先定义hashtable,存储完成后再放入map中,或者hashtable先get 出value再put进入新value。
5
new HashMap<String, List<Tuple>>()
private class Tuple {
private int DID;
private int position;
public Tuple(int DID, int position) {
this.DID = DID;
this.position = position;
}
}6 Java 中string被创建后值不会改变,如果想要如加上其他一段string需要新建一个string object再指向新建的object。java中无论传值还是传引用,都是先复制,再对复制品操作。
7 java方法参数存放在栈中,方法调用完后栈中的内存被清除。栈中除了int等基本变量,需要指针的都仅仅存放指针,如main方法中:
8 The java.lang library has a method "Thread.dumpStack" that prints a list of the methods on the stack (but it doesn’t print their local variables). This method can be convenient for debugging--for instance, when you’re trying to figure out which method called another method with illegal parameters.
9 子类中的方法不能被父类object动态调用:
10 "instanceof" operator can tell you whether an object is of a specific class. For s instanceof TailList
This instanceof operation will return false if s is null or doesn’t reference a TailList. It returns true if s references a TailList object--even if it’s a subclass of TailList.
11 regression测试,全路径测试,边界测试,数据结构完整性测试,结果测试,assertion(默认da即不执行,相对于java代码行也不执行),模块测试,stubs桩测试(模拟未完成代码)
12 Java中只能继承一个类,可以继承多个interface
13 泛型:
14 methods可以被overrided, fields 可以被shadowed(不同于overrided, shadowed后强制转换成父类后变为父类的fields)
15 final可以阻止方法或者类被extend,可以加快程序速度
16 hashcode举例: a mod b = (a % b + b) % b
17 拆装箱:
装箱是原始类型转换为包装类型,拆箱反之;如int和Integer。
- 进行 = 赋值操作(装箱或拆箱)
- 进行+,-,*,/混合运算 (拆箱)
- 进行>,<,==比较运算(拆箱)
- 调用equals进行比较(装箱)
- ArrayList,HashMap等集合类 添加基础类型数据时(装箱)
以float和Float为例,装箱就是调用Float的valueOf方法new一个Float并赋值,拆箱就是调用Float对象的floatValue方法并赋值返回给float。
public void testAutoBox2() {
//1
int a = 100;
Integer b = 100;
System.out.println(a == b);
//2
Integer c = 100;
Integer d = 100;
System.out.println(c == d);
//3
c = 200;
d = 200;
System.out.println(c == d);
}第1段代码,基础类型a与包装类b进行==比较,这时b会拆箱,直接比较值,所以会打印 true
第2段代码,二个包装类型,都被赋值了100,所以根据我们之前的解析,这时会进行装箱,调用Integer的valueOf方法,生成2个Integer对象,引用类型==比较,直接比较对象指针,这里我们先给出结论,最后会分析原因,打印 true;
跟上面第2段代码类似,只不过赋值变成了200,直接说结论,打印 false;
Integer类valueOf方法是用IntegerCache做一个cache,cache的range是可以配置的,默认Integer cache 的下限是-128,上限默认127,可以配置,所以到这里就清楚了,我们上面当赋值100给Integer时,刚好在这个range内,所以从cache中取对应的Integer并返回,所以二次返回的是同一个对象,所以==比较是相等的,当赋值200给Integer时,不在cache 的范围内,所以会new Integer并返回,当然==比较的结果是不相等的。
18 String 等
简单的来说:String 类中使用 final 关键字修饰字符数组来保存字符串,private final char value[],所以 String 对象是不可变的。在 Java 9 之后,String 类的实现改用 byte 数组存储字符串 private final byte[] value; 而 StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串char[]value 但是没有用 final 关键字修饰,所以这两种对象都是可变的。每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。
String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
相同情况下使用 StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
对于三者使用的总结:
-
操作少量的数据: 适用 String
-
单线程操作字符串缓冲区下操作大量数据: 适用 StringBuilder
-
多线程操作字符串缓冲区下操作大量数据: 适用 StringBuffer
-
String:
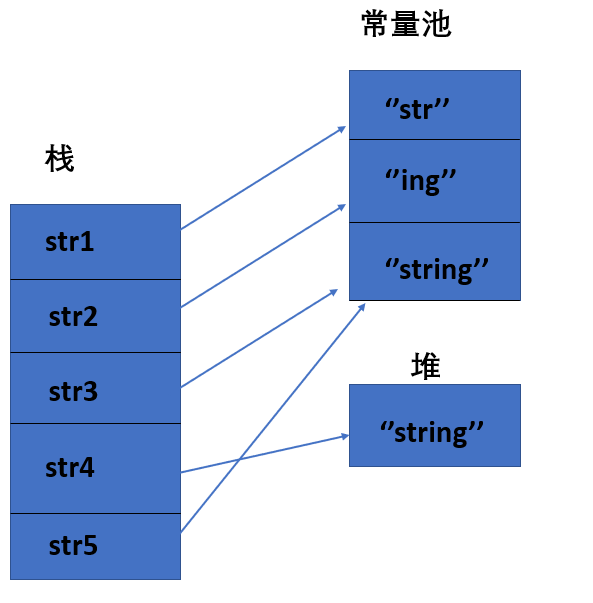
- 直接使用双引号声明出来的 String 对象会直接存储在常量池中。
- 如果不是用双引号声明的 String 对象,可以使用 String 提供的 intern 方String.intern() 是一个 Native 方法,它的作用是:如果运行时常量池中已经包含一个等于此 String 对象内容的字符串,则返回常量池中该字符串的引用;如果没有,则在常量池中创建与此 String 内容相同的字符串,并返回常量池中创建的字符串的引用。
String str1 = "str"; String str2 = "ing"; String str3 = "str" + "ing";//常量池中的对象 String str4 = str1 + str2; //在堆上创建的新的对象 String str5 = "string";//常量池中的对象 System.out.println(str3 == str4);//false System.out.println(str3 == str5);//true System.out.println(str4 == str5);//falseString s1 = new String("abc");// 堆内存的地值值 String s2 = "abc"; System.out.println(s1 == s2);// 输出false,因为一个是堆内存,一个是常量池的内存,故两者是不同的。 System.out.println(s1.equals(s2));// 输出true先有字符串"abc"放入常量池,然后 new 了一份字符串"abc"放入Java堆(字符串常量"abc"在编译期就已经确定放入常量池,而 Java 堆上的"abc"是在运行期初始化阶段才确定),然后 Java 栈的 s1 指向Java堆上的"abc"。
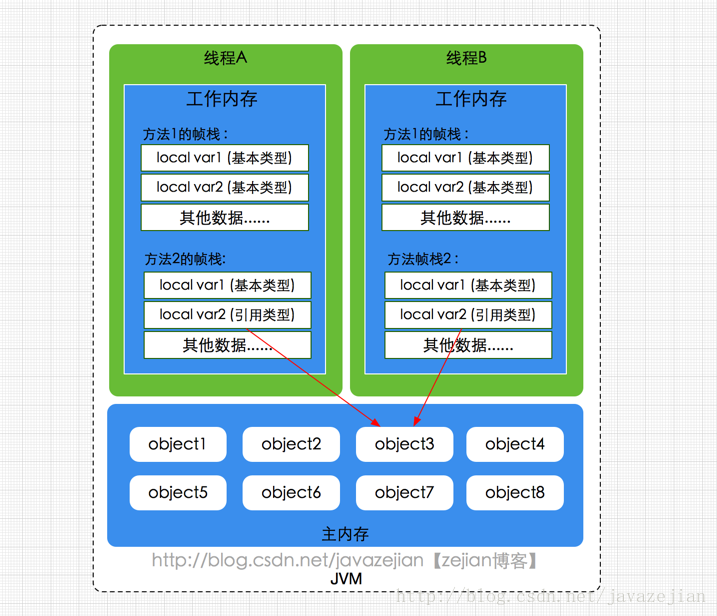
java内存模型,描述了一组规则和规范来定义程序中各个变量的访问方式。主内存就是共享内存↓

线程私有的:
- 程序计数器可以看作是当前线程所执行的字节码的行号指示器。字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完成。
- 虚拟机栈是由一个个栈帧组成,而每个栈帧中都拥有:局部变量表、操作数栈、动态链接、方法出口信息。局部变量表主要存放了编译器可知的各种数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)。
- 本地方法栈,和虚拟机栈所发挥的作用非常相似,区别是: 虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
线程共享的:
- 堆此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。
- 方法区用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据
- 运行时常量池是方法区的一部分。Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有常量池信息(用于存放编译期生成的各种字面量和符号引用)也受内存限制
-
- 直接内存 (非运行时数据区的一部分)直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用。而且也可能导致 OutOfMemoryError 错误出现。JDK1.4中新加入的 NIO(New Input/Output) 类,引入了一种基于通道(Channel) 与缓存区(Buffer) 的 I/O 方式,它可以直接使用Native函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样就能在一些场景中显著提高性能,因为避免了在 Java 堆和 Native 堆之间来回复制数据。
- 下图中工作内存即为栈
在 Hotspot 虚拟机中,对象在内存中的布局可以分为 3 块区域:对象头、实例数据和对齐填充。
Hotspot 虚拟机的对象头包括两部分信息,第一部分用于存储对象自身的运行时数据(哈希码、GC 分代年龄、锁状态标志等等),另一部分是类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是那个类的实例。
实例数据部分是对象真正存储的有效信息,也是在程序中所定义的各种类型的字段内容。
对齐填充部分不是必然存在的,也没有什么特别的含义,仅仅起占位作用。 因为 Hotspot 虚拟机的自动内存管理系统要求对象起始地址必须是 8 字节的整数倍,换句话说就是对象的大小必须是 8 字节的整数倍。而对象头部分正好是 8 字节的倍数(1 倍或 2 倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。

class Fruit {
static int x = 10;
static BigWaterMelon bigWaterMelon_1 = new BigWaterMelon(x);
int y = 20;
BigWaterMelon bigWaterMelon_2 = new BigWaterMelon(y);
public static void main(String[] args) {
final Fruit fruit = new Fruit();
int z = 30;
BigWaterMelon bigWaterMelon_3 = new BigWaterMelon(z);
new Thread() {
@Override
public void run() {
int k = 100;
setWeight(k);
}
void setWeight(int waterMelonWeight) {
fruit.bigWaterMelon_2.weight = waterMelonWeight; //运行后上图weight变为100
}
}.start();
}
}
class BigWaterMelon {
public BigWaterMelon(int weight) {
this.weight = weight;
}
public int weight;
}root_是程序可以直接访问的任何对象引用(从栈和方法区中直接引用),而无需通过另一个对象。 如果某个对象是_root(不是垃圾)引用的,或者是另一个活动对象中的字段引用的,则该对象是活动的,并且不应进行垃圾回收。mark-sweep垃圾收集器分两个单独的阶段运行。 _mark_阶段从每个根目录开始执行DFS,并标记所有活动对象。 _sweep_阶段扫描内存中的所有对象。 每个未标记为活动的对象都是垃圾,并且其内存被回收。一般在创建新object发现没有内存时垃圾回收才回启动。为了防止内存碎片化使用导致没有大量连续内存,sweep-compacting garbage collector可以转移内存位置,活动的放到一端,不活动清除。copying garbage collection methods 将内存分为新旧两个space,将非垃圾从old space复制到new space,old space中认为是垃圾但无需额外sweep处理。
In the Oracle JVM, a reference isn’t a pointer. A reference is a handle. A handle is a pointer to a pointer:
JVM divides objects into an old generation and a young generation, old generation 使用compacting mark-and-sweep collector,因为它对速度不敏感,但是long last. young generation分为Eden和两个_survivor_spaces_(copying garbage collector).
minor collections, which happen frequently but only affect the young generation. major collections, which happen much less often but cover all the objects in memory. 对于old object 引用 new object, minor collection无法发现,但是这种情况很少所以JVM专门建立了table来保存。
上图所示的 eden 区、s0("From") 区、s1("To") 区都属于新生代,tentired 区属于老年代。大部分情况,对象都会首先在 Eden 区域分配,大多数情况下,对象在新生代中 eden 区分配。(大对象如字符串数组等直接进入老年代,为了避免为大对象分配内存时由于分配担保机制带来的复制而降低效率。分配担保机制即eden区放不开,所以放到old区。)当 eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC。在一次新生代垃圾回收后,如果对象还存活,则会进入 s1("To"),并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 -XX:MaxTenuringThreshold 来设置。(Hotspot遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了survivor区的一半时,取这个年龄和MaxTenuringThreshold中更小的一个值,作为新的晋升年龄阈值。)经过这次minor GC后,Eden区和"From"区已经被清空。这个时候,"From"和"To"会交换他们的角色,也就是新的"To"就是上次GC前的“From”,新的"From"就是上次GC前的"To"。不管怎样,都会保证名为To的Survivor区域是空的。Minor GC会一直重复这样的过程,直到“To”区被填满,"To"区被填满之后,会将所有对象移动到老年代中。
即使在可达性分析法中不可达的对象,也并非是“非死不可”的,这时候它们暂时处于“缓刑阶段”,要真正宣告一个对象死亡,至少要经历两次标记过程;可达性分析法中不可达的对象被第一次标记并且进行一次筛选,筛选的条件是此对象是否有必要执行 finalize 方法。当对象没有覆盖 finalize 方法,或 finalize 方法已经被虚拟机调用过时,虚拟机将这两种情况视为没有必要执行。被判定为需要执行的对象将会被放在一个队列中进行第二次标记,除非这个对象与引用链上的任何一个对象建立关联,否则就会被真的回收。
运行时常量池主要回收的是废弃的常量。那么,我们如何判断一个常量是废弃常量呢?假如在常量池中存在字符串 "abc",如果当前没有任何 String 对象引用该字符串常量的话,就说明常量 "abc" 就是废弃常量,如果这时发生内存回收的话而且有必要的话,"abc" 就会被系统清理出常量池。
回收类:
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
- 加载该类的 ClassLoader 已经被回收。
- 该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
| 引用类型 | 被垃圾回收时间 | 用途 | 生存时间 |
|---|---|---|---|
| 强引用 | 从来不会 | 对象的一般状态 | JVM停止运行时终止 |
| 软引用 | 在内存不足时 | 对象缓存 | 内存不足时终止 |
| 弱引用 | 在垃圾回收时 | 对象缓存 | gc运行后终止 |
| 虚引用 | Unknown | Unknown | Unknown |
1.强引用(StrongReference)
以前我们使用的大部分引用实际上都是强引用,这是使用最普遍的引用。如果一个对象具有强引用,那就类似于必不可少的生活用品,垃圾回收器绝不会回收它。当内存空间不足,Java 虚拟机宁愿抛出 OutOfMemoryError 错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
2.软引用(SoftReference)
如果一个对象只具有软引用,那就类似于可有可无的生活用品。如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。
软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收,JAVA 虚拟机就会把这个软引用加入到与之关联的引用队列中。如WeakHashMap 垃圾回收后被清理。
3.弱引用(WeakReference)
如果一个对象只具有弱引用,那就类似于可有可无的生活用品。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。
4.虚引用(PhantomReference)
"虚引用"顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。
虚引用主要用来跟踪对象被垃圾回收的活动他的get方法总是回收null。
虚引用与软引用和弱引用的一个区别在于: 虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动如finalize里。
特别注意,在程序设计中一般很少使用弱引用与虚引用,使用软引用的情况较多,这是因为软引用可以加速 JVM 对垃圾内存的回收速度,可以维护系统的运行安全,防止内存溢出(OutOfMemory)等问题的产生。
-XX:+PrintCommandLineFlagsjvm参数可查看默认设置收集器类型
-XX:+PrintGCDetails亦可通过打印的GC日志的新生代、老年代名称判断
java -XX:+PrintCommandLineFlags -version
| 收集器 | 串行、并行or并发 | 新生代/老年代 | 算法 | 目标 | 适用场景 |
|---|---|---|---|---|---|
| Serial | 串行 | 新生代 | 复制算法 | 响应速度优先 | 单CPU环境下的Client模式 |
| Serial Old | 串行 | 老年代 | 标记-整理 | 响应速度优先 | 单CPU环境下的Client模式、CMS的后备预案 |
| ParNew | 并行 | 新生代 | 复制算法 | 响应速度优先 | 多CPU环境时在Server模式下与CMS配合 |
| Parallel Scavenge | 并行 | 新生代 | 复制算法 | 吞吐量优先 | 在后台运算而不需要太多交互的任务 |
| Parallel Old | 并行 | 老年代 | 标记-整理 | 吞吐量优先 | 在后台运算而不需要太多交互的任务 |
| CMS | 并发 | 老年代 | 标记-清除 | 响应速度优先 | 集中在互联网站或B/S系统服务端上的Java应用 |
| G1 | 并发 | both | 标记-整理+复制算法 | 响应速度优先 | 面向服务端应用,将来替换CMS |
它在进行垃圾收集时,必须暂停其他所有的工作线程,直至Serial收集器收集结束为止,新生代复制算法。HotSpot虚拟机运行在Client模式下的默认的新生代收集器。它也有着优于其他收集器的地方:简单而高效(与其他收集器的单线程相比),对于限定单个CPU的环境来说,Serial收集器由于没有线程交互的开销,专心做垃圾收集自然可以获得更高的单线程收集效率。

ParNew收集器除了使用多线程收集外,其他与Serial收集器相比并无太多创新之处,但它却是许多运行在Server模式下的虚拟机中首选的新生代收集器,其中有一个与性能无关的重要原因是,除了Serial收集器外,目前只有它能和CMS收集器(Concurrent Mark Sweep)配合工作

Parallel Scavenge收集器也是一个并行的多线程新生代收集器,它也使用复制算法。Parallel Scavenge收集器的特点是它的关注点与其他收集器不同,CMS等收集器的关注点是尽可能缩短垃圾收集时用户线程的停顿时间,而Parallel Scavenge收集器的目标是达到一个可控制的吞吐量(代码时间/代码时间+垃圾回收时间)
Parallel Scavenge收集器除了会显而易见地提供可以精确控制吞吐量的参数,还提供了一个参数**-XX:+UseAdaptiveSizePolicy**,这是一个开关参数,打开参数后,就不需要手工指定新生代的大小(-Xmn)、Eden和Survivor区的比例(-XX:SurvivorRatio)、晋升老年代对象年龄(-XX:PretenureSizeThreshold)等细节参数了,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量,这种方式称为GC自适应的调节策略(GC Ergonomics)。自适应调节策略也是Parallel Scavenge收集器与ParNew收集器的一个重要区别。
Serial Old 是 Serial收集器的老年代版本,它同样是一个单线程收集器,使用**“标记-整理”(Mark-Compact)**算法
Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程和**“标记-整理”算法,在注重吞吐量以及CPU资源敏感**的场合,都可以优先考虑Parallel Scavenge加Parallel Old收集器。

CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器,它非常符合那些集中在互联网站或者B/S系统的服务端上的Java应用,这些应用都非常重视服务的响应速度。从名字上(“Mark Sweep”)就可以看出它是基于**“标记-清除”**算法实现的。
CMS收集器工作的整个流程分为以下4个步骤:
- 初始标记(CMS initial mark):仅仅只是标记一下GC Roots能直接关联到的对象,速度很快,需要“Stop The World”可以多线程。
- 并发标记(CMS concurrent mark):进行GC Roots Tracing的过程,在整个过程中耗时最长。
- 重新标记(CMS remark):为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短。此阶段也需要“Stop The World”。
- 并发清除(CMS concurrent sweep)
由于整个过程中耗时最长的并发标记和并发清除过程收集器线程都可以与用户线程一起工作,所以,从总体上来说,CMS收集器的内存回收过程是与用户线程一起并发执行的。

CMS收集器也被称为并发低停顿收集器。
缺点:
- 对CPU资源非常敏感 其实,面向并发设计的程序都对CPU资源比较敏感。在并发阶段,它虽然不会导致用户线程停顿,但会因为占用了一部分线程(或者说CPU资源)而导致应用程序变慢,总吞吐量会降低。CMS默认启动的回收线程数是(CPU数量+3)/4,也就是当CPU在4个以上时,并发回收时垃圾收集线程不少于25%的CPU资源,并且随着CPU数量的增加而下降。但是当CPU不足4个时(比如2个),CMS对用户程序的影响就可能变得很大,如果本来CPU负载就比较大,还要分出一半的运算能力去执行收集器线程,就可能导致用户程序的执行速度忽然降低了50%,其实也让人无法接受。
- 无法处理浮动垃圾(Floating Garbage) 可能出现“Concurrent Mode Failure”失败而导致另一次Full GC的产生。由于CMS并发清理阶段用户线程还在运行着,伴随程序运行自然就还会有新的垃圾不断产生。这一部分垃圾出现在标记过程之后,CMS无法再当次收集中处理掉它们,只好留待下一次GC时再清理掉。这一部分垃圾就被称为“浮动垃圾”。也是由于在垃圾收集阶段用户线程还需要运行,那也就还需要预留有足够的内存空间给用户线程使用,因此CMS收集器不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,需要预留一部分空间提供并发收集时的程序运作使用。
- 标记-清除算法导致的空间碎片 CMS是一款基于“标记-清除”算法实现的收集器,这意味着收集结束时会有大量空间碎片产生。空间碎片过多时,将会给大对象分配带来很大麻烦,往往出现老年代空间剩余,但无法找到足够大连续空间来分配当前对象。
在G1之前的其他收集器进行收集的范围都是整个新生代或者老生代,而G1不再是这样。G1在使用时,Java堆的内存布局与其他收集器有很大区别,它将整个Java堆划分为多个大小相等的独立区域(Region),虽然还保留新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,而都是一部分Region(不需要连续)的集合。
- 并行与并发 G1 能充分利用多CPU、多核环境下的硬件优势,使用多个CPU来缩短“Stop The World”停顿时间,部分其他收集器原本需要停顿Java线程执行的GC动作,G1收集器仍然可以通过并发的方式让Java程序继续执行。
- 分代收集 宏观上不宰有代之分,而是划分为多个区域,每个区域微观上可能会有分代。与其他收集器一样,分代概念在G1中依然得以保留。虽然G1可以不需要其他收集器配合就能独立管理整个GC堆,但它能够采用不同方式去处理新创建的对象和已存活一段时间、熬过多次GC的旧对象来获取更好的收集效果。
- 空间整合 G1从整体来看是基于**“标记-整理”算法实现的收集器,从局部(两个Region之间)上来看是基于“复制”**算法实现的。这意味着G1运行期间不会产生内存空间碎片,收集后能提供规整的可用内存。此特性有利于程序长时间运行,分配大对象时不会因为无法找到连续内存空间而提前触发下一次GC。
- 可预测的停顿 这是G1相对CMS的一大优势,降低停顿时间是G1和CMS共同的关注点,但G1除了降低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内,消耗在GC上的时间不得超过N毫秒,这几乎已经是实时Java(RTSJ)的垃圾收集器的特征了。
G1收集器之所以能建立可预测的停顿时间模型,是因为它可以有计划地避免在整个Java堆中进行全区域的垃圾收集。G1跟踪各个Region里面的垃圾堆积的价值大小(回收所获得的空间大小以及回收所需时间的经验值),在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的Region(这也就是Garbage-First名称的来由)。这种使用Region划分内存空间以及有优先级的区域回收方式,保证了G1收集器在有限的时间内可以获取尽可能高的收集效率。
G1把Java堆分为多个Region,就是“化整为零”。但是Region不可能是孤立的,一个对象分配在某个Region中,可以与整个Java堆任意的对象发生引用关系。在做可达性分析确定对象是否存活的时候,需要扫描整个Java堆才能保证准确性,这显然是对GC效率的极大伤害。
为了避免全堆扫描的发生,虚拟机为G1中每个Region维护了一个与之对应的Remembered Set。虚拟机发现程序在对Reference类型的数据进行写操作时,会产生一个Write Barrier暂时中断写操作,检查Reference引用的对象是否处于不同的Region之中(在分代的例子中就是检查是否老年代中的对象引用了新生代中的对象),如果是,便通过CardTable把相关引用信息记录到被引用对象所属的Region的Remembered Set之中。当进行内存回收时,在GC根节点的枚举范围中加入Remembered Set即可保证不对全堆扫描也不会有遗漏。
**Card Table的结构是一个连续的byte[]数组,扫描Card Table的时间比扫描整个老年代的代价要小很多!G1也参照了这个思路,不过采用了一种新的数据结构 Remembered Set 简称Rset。**RSet记录了其他Region中的对象引用本Region中对象的关系,属于points-into结构(谁引用了我的对象)。而Card Table则是一种points-out(我引用了谁的对象)的结构,每个Card 覆盖一定范围的Heap(一般为512Bytes)。G1的RSet是在Card Table的基础上实现的:每个Region会记录下别的Region有指向自己的指针,并标记这些指针分别在哪些Card的范围内。 这个RSet其实是一个Hash Table,Key是别的Region的起始地址,Value是一个集合,里面的元素是Card Table的Index。每个Region都有一个对应的Rset。
流程:
当Eden空间被占满之后,就会触发YGC。在G1中YGC依然采用复制存活对象到survivor空间的方式,当对象的存活年龄满足晋升条件时,把对象提升到old generation regions(老年代)。
G1控制YGC开销的手段是动态改变young region的个数,YGC的过程中依然会STW(stop the world 应用停顿),并采用多线程并发复制对象,减少GC停顿时间。
全局:
-
初始标记(Initial Marking) Initial Mark初始标记是一个STW事件,其完成工作是标记GC ROOTS 直接可达的对象。并将它们的字段压入扫描栈(marking stack)中等到后续扫描。使用外部的bitmap来记录mark信息,而不使用对象头的mark word里的mark bit。因为 STW,所以通常YGC的时候借用YGC的STW顺便启动Initial Mark,也就是启动全局并发标记,全局并发标记与YGC在逻辑上独立。
根区域扫描是从Survior区的对象出发,标记被引用到老年代中的对象,并把它们的字段在压入扫描栈(marking stack)中等到后续扫描。与Initial Mark不一样的是,Root Region Scanning不需要STW与应用程序是并发运行。Root Region Scanning必须在YGC开始前完成。
-
并发标记(Concurrent Marking) 不需要STW。不断从扫描栈取出引用递归扫描整个堆里的对象。每扫描到一个对象就会对其标记,并将其字段压入扫描栈。重复扫描过程直到扫描栈清空。过程中还会扫描SATB write barrier所记录下的引用。Concurrent Marking 可以被YGC中断
-
最终标记(Final Marking) 为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程的Remembered Set Logs里面,最终标记阶段需要把Remembered Set Logs的数据合并到Remembered Set中,这阶段需要停顿线程,但是可并行执行。
-
筛选回收(Live Data Counting and Evacuation) 首先对各个Region中的回收价值和成本进行排序,根据用户所期望的GC 停顿是时间来制定回收计划。此阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分Region,时间是用户可控制的,而且停顿用户线程将大幅度提高收集效率。

着色指针
着色指针是一种将信息存储在指针(或使用Java术语引用)中的技术。因为在64位平台上(ZGC仅支持64位平台),指针可以处理更多的内存,因此可以使用一些位来存储状态。 ZGC将限制最大支持4Tb堆(42-bits),那么会剩下22位可用,它目前使用了4位: finalizable, remap, mark0和mark1。 我们稍后解释它们的用途。
着色指针的一个问题是,当您需要取消着色时,它需要额外的工作(因为需要屏蔽信息位)。 像SPARC这样的平台有内置硬件支持指针屏蔽所以不是问题,而对于x86平台来说,ZGC团队使用了简洁的多重映射技巧。
多重映射
要了解多重映射的工作原理,我们需要简要解释虚拟内存和物理内存之间的区别。 物理内存是系统可用的实际内存,通常是安装的DRAM芯片的容量。 虚拟内存是抽象的,这意味着应用程序对(通常是隔离的)物理内存有自己的视图。 操作系统负责维护虚拟内存和物理内存范围之间的映射,它通过使用页表和处理器的内存管理单元(MMU)和转换查找缓冲器(TLB)来实现这一点,后者转换应用程序请求的地址。
多重映射涉及将不同范围的虚拟内存映射到同一物理内存。 由于设计中只有一个remap,mark0和mark1在任何时间点都可以为1,因此可以使用三个映射来完成此操作。 ZGC源代码中有一个很好的图表可以说明这一点。
读屏障是每当应用程序线程从堆加载引用时运行的代码片段(即访问对象上的非原生字段non-primitive field):
void printName( Person person ) {
String name = person.name; // 这里触发读屏障
// 因为需要从heap读取引用
//
System.out.println(name); // 这里没有直接触发读屏障
}
在上面的代码中,String name = person.name 访问了堆上的person引用,然后将引用加载到本地的name变量。此时触发读屏障。 Systemt.out那行不会直接触发读屏障,因为没有来自堆的引用加载(name是局部变量,因此没有从堆加载引用)。 但是System和out,或者println内部可能会触发其他读屏障。
标记
这与其他GC使用的写屏障形成对比,例如G1。读屏障的工作是检查引用的状态,并在将引用(或者甚至是不同的引用)返回给应用程序之前执行一些工作。 在ZGC中,它通过测试加载的引用来执行此任务,以查看是否设置了某些位。 如果通过了测试,则不执行任何其他工作,如果失败,则在将引用返回给应用程序之前执行某些特定于阶段的任务。
GC循环的第一部分是标记。标记包括查找和标记运行中的应用程序可以访问的所有堆对象,换句话说,查找不是垃圾的对象。
ZGC的标记分为三个阶段。 第一阶段是STW,其中GC roots被标记为活对象。 GC roots类似于局部变量,通过它可以访问堆上其他对象。 如果一个对象不能通过遍历从roots开始的对象图来访问,那么应用程序也就无法访问它,则该对象被认为是垃圾。从roots访问的对象集合称为Live集。GC roots标记步骤非常短,因为roots的总数通常比较小。

该阶段完成后,应用程序恢复执行,ZGC开始下一阶段,该阶段同时遍历对象图并标记所有可访问的对象。 在此阶段期间,读屏障针使用掩码测试所有已加载的引用,该掩码确定它们是否已标记或尚未标记,如果尚未标记引用,则将其添加到队列以进行标记。
在遍历完成之后,有一个最终的,时间很短的的Stop The World阶段,这个阶段处理一些边缘情况(我们现在将它忽略),该阶段完成之后标记阶段就完成了。
重定位
GC循环的下一个主要部分是重定位。重定位涉及移动活动对象以释放部分堆内存。 为什么要移动对象而不是填补空隙? 有些GC实际是这样做的,但是它导致了一个不幸的后果,即分配内存变得更加昂贵,因为当需要分配内存时,内存分配器需要找到可以放置对象的空闲空间。 相比之下,如果可以释放大块内存,那么分配内存就很简单,只需要将指针递增新对象所需的内存大小即可。
ZGC将堆分成许多页面,在此阶段开始时,它同时选择一组需要重定位活动对象的页面。选择重定位集后,会出现一个Stop The World暂停,其中ZGC重定位该集合中root对象,并将他们的引用映射到新位置。与之前的Stop The World步骤一样,此处涉及的暂停时间仅取决于root的数量以及重定位集的大小与对象的总活动集的比率,这通常相当小。所以不像很多收集器那样,暂停时间随堆增加而增加。
移动root后,下一阶段是并发重定位。 在此阶段,GC线程遍历重定位集并重新定位其包含的页中所有对象。 如果应用程序线程试图在GC重新定位对象之前加载它们,那么应用程序线程也可以重定位该对象,这可以通过读屏障(在从堆加载引用时触发)实现,如流程图如下所示:

在调优之前,我们需要记住下面的原则:
多数的 Java 应用不需要在服务器上进行 GC 优化; 多数导致 GC 问题的 Java 应用,都不是因为我们参数设置错误,而是代码问题; 在应用上线之前,先考虑将机器的 JVM 参数设置到最优(最适合); 减少创建对象的数量; 减少使用全局变量和大对象; GC 优化是到最后不得已才采用的手段; 在实际使用中,分析 GC 情况优化代码比优化 GC 参数要多得多。
目的是将转移到老年代的对象数量降低到最小; 减少 GC 的执行时间。
**策略 1:**将新对象预留在新生代,由于 Full GC 的成本远高于 Minor GC,因此尽可能将对象分配在新生代是明智的做法,实际项目中根据 GC 日志分析新生代空间大小分配是否合理,适当通过“-Xmn”命令调节新生代大小,最大限度降低新对象直接进入老年代的情况。
**策略 2:**大对象进入老年代,虽然大部分情况下,将对象分配在新生代是合理的。但是对于大对象这种做法却值得商榷,大对象如果首次在新生代分配可能会出现空间不足导致很多年龄不够的小对象被分配的老年代,破坏新生代的对象结构,可能会出现频繁的 full gc。因此,对于大对象,可以设置直接进入老年代(当然短命的大对象对于垃圾回收来说简直就是噩梦)。-XX:PretenureSizeThreshold 可以设置直接进入老年代的对象大小。
**策略 3:**合理设置进入老年代对象的年龄,-XX:MaxTenuringThreshold 设置对象进入老年代的年龄大小,减少老年代的内存占用,降低 full gc 发生的频率。
**策略 4:**设置稳定的堆大小,堆大小设置有两个参数:-Xms 初始化堆大小,-Xmx 最大堆大小。
**策略5:**注意: 如果满足下面的指标,则一般不需要进行 GC 优化:
MinorGC 执行时间不到50ms; Minor GC 执行不频繁,约10秒一次; Full GC 执行时间不到1s; Full GC 执行频率不算频繁,不低于10分钟1次。
虚拟机遇到一条 new 指令时,首先将去检查这个指令的参数是否能在常量池中定位到这个类的符号引用,并且检查这个符号引用代表的类是否已被加载过、解析和初始化过。如果没有,那必须先执行相应的类加载过程
在类加载检查通过后,接下来虚拟机将为新生对象分配内存。对象所需的内存大小在类加载完成后便可确定,为对象分配空间的任务等同于把一块确定大小的内存从 Java 堆中划分出来。分配方式有 “指针碰撞” 和 “空闲列表” 两种,选择那种分配方式由 Java 堆是否规整决定,而 Java 堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决定。

在创建对象的时候有一个很重要的问题,就是线程安全,因为在实际开发过程中,创建对象是很频繁的事情,作为虚拟机来说,必须要保证线程是安全的,通常来讲,虚拟机采用两种方式来保证线程安全:
- CAS+失败重试: CAS 是乐观锁的一种实现方式。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。虚拟机采用 CAS 配上失败重试的方式保证更新操作的原子性。
- TLAB: 为每一个线程预先在 Eden 区分配一块儿内存,JVM 在给线程中的对象分配内存时,首先在 TLAB 分配,当对象大于 TLAB 中的剩余内存或 TLAB 的内存已用尽时,再采用上述的 CAS 进行内存分配
内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),这一步操作保证了对象的实例字段在 Java 代码中可以不赋初始值就直接使用,程序能访问到这些字段的数据类型所对应的零值。
初始化零值完成之后,虚拟机要对对象进行必要的设置,例如这个对象是那个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的 GC 分代年龄等信息。 这些信息存放在对象头中。 另外,根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。
在上面工作都完成之后,从虚拟机的视角来看,一个新的对象已经产生了,但从 Java 程序的视角来看,对象创建才刚开始,
方法还没有执行,所有的字段都还为零。所以一般来说,执行 new 指令之后会接着执行方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象才算完全产生出来。
在代码编译后,就会生成JVM(Java虚拟机)能够识别的二进制字节流文件(*.class)。而JVM把Class文件中的类描述数据从文件加载到内存,并对数据进行校验、转换解析、初始化,使这些数据最终成为可以被JVM直接使用的Java类型,这个说来简单但实际复杂的过程叫做JVM的类加载机制。
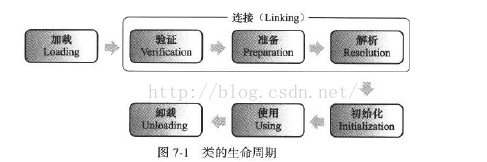
Class文件中的“类”从加载到JVM内存中,到卸载出内存过程有七个生命周期阶段。类加载机制包括了前五个阶段。其中,加载、验证、准备、初始化、卸载的****开始顺序****是确定的,注意,只是按顺序开始,进行与结束的顺序并不一定。解析阶段可能在初始化之后开始。
另外,类加载无需等到程序中“首次使用”的时候才开始,JVM预先加载某些类也是被允许的。
加载:
我们平常说的加载大多不是指的类加载机制,只是类加载机制中的第一步加载。在这个阶段,JVM主要完成三件事:
1、通过一个类的全限定名(包名与类名)来获取定义此类的二进制字节流(Class文件)。而获取的方式,可以通过jar包、war包、网络中获取、JSP文件生成等方式。
2、将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。这里只是转化了数据结构,并未合并数据。(方法区就是用来存放已被加载的类信息,常量,静态变量,编译后的代码的运行时内存区域)
3、在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。这个Class对象并没有规定是在Java堆内存中,它比较特殊,虽为对象,但存放在方法区中。
连接:
类的加载过程后生成了类的java.lang.Class对象,接着会进入连接阶段,连接阶段负责将类的二进制数据合并入JRE(Java运行时环境)中。类的连接大致分三个阶段。
1、验证:验证被加载后的类是否有正确的结构,类数据是否会符合虚拟机的要求,确保不会危害虚拟机安全。
2、准备:为类的静态变量(static filed)在方法区分配内存,并赋默认初值(0值或null值)。如static int a = 100;
静态变量a就会在准备阶段被赋默认值0。
对于一般的成员变量是在类实例化时候,随对象一起分配在堆内存中。
另外,静态常量(static final filed)会在准备阶段赋程序设定的初值,如static final int a = 666; 静态常量a就会在准备阶段被直接赋值为666,对于静态变量,这个操作是在初始化阶段进行的。
3、解析:将类的二进制数据中的符号引用换为直接引用。
符号引用:符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可。符号引用与虚拟机实现的内存布局无关,引用的目标并不一定已经加载到了内存中。 直接引用:直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄。直接引用是与虚拟机实现的内存布局相关的,同一个符号引用在不同虚拟机实例上翻译出来的直接引用一般不会相同。如果有了直接引用,那说明引用的目标必定已经存在于内存之中了。
4、类初始化是类加载的最后一步,除了加载阶段,用户可以通过自定义的类加载器参与,其他阶段都完全由虚拟机主导和控制。到了初始化阶段才真正执行Java代码。
类的初始化的主要工作是为静态变量赋程序设定的初值。
如static int a = 100;在准备阶段,a被赋默认值0,在初始化阶段就会被赋值为100。
Java虚拟机规范中严格规定了有且只有五种情况必须对类进行初始化:
1、使用new字节码指令创建类的实例,或者使用getstatic、putstatic读取或设置一个静态字段的值(放入常量池中的常量除外),或者调用一个静态方法的时候,对应类必须进行过初始化。
2、通过java.lang.reflect包的方法对类进行反射调用的时候,如果类没有进行过初始化,则要首先进行初始化。
3、当初始化一个类的时候,如果发现其父类没有进行过初始化,则首先触发父类初始化。
4、当虚拟机启动时,用户需要指定一个主类(包含main()方法的类),虚拟机会首先初始化这个类。
5、使用jdk1.7的动态语言支持时,如果一个java.lang.invoke.MethodHandle实例最后的解析结果REF_getStatic、REF_putStatic、RE_invokeStatic的方法句柄,并且这个方法句柄对应的类没有进行初始化,则需要先触发其初始化
从Java虚拟机的角度来说,只存在两种不同的类加载器:一种是启动类加载器(Bootstrap ClassLoader),这个类加载器使用C++语言实现(HotSpot虚拟机中),是虚拟机自身的一部分;另一种就是所有其他的类加载器,这些类加载器都有Java语言实现,独立于虚拟机外部,并且全部继承自java.lang.ClassLoader。
从开发者的角度,类加载器可以细分为:
- 启动(Bootstrap)类加载器:负责将 Java_Home/lib下面的类库加载到内存中(比如rt.jar)。由于引导类加载器涉及到虚拟机本地实现细节,开发者无法直接获取到启动类加载器的引用,所以不允许直接通过引用进行操作。
- 标准扩展(Extension)类加载器:是由 Sun 的 ExtClassLoader(sun.misc.Launcher$ExtClassLoader)实现的。它负责将Java_Home /lib/ext或者由系统变量 java.ext.dir指定位置中的类库加载到内存中。开发者可以直接使用标准扩展类加载器。
- 应用程序(Application)类加载器:是由 Sun 的 AppClassLoader(sun.misc.Launcher$AppClassLoader)实现的。它负责将系统类路径(CLASSPATH)中指定的类库加载到内存中。开发者可以直接使用系统类加载器。由于这个类加载器是ClassLoader中的getSystemClassLoader()方法的返回值,因此一般称为系统(System)加载器。
除此之外,还有自定义的类加载器,它们之间的层次关系被称为类加载器的双亲委派模型。该模型要求除了顶层的启动类加载器外,其余的类加载器都应该有自己的父类加载器,而这种父子关系一般通过组合(Composition)关系来实现,而不是通过继承(Inheritance)。
每一个类都有一个对应它的类加载器。系统中的 ClassLoder 在协同工作的时候会默认使用 双亲委派模型 。即在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载。加载的时候,首先会把该请求委派该父类加载器的 loadClass() 处理,因此所有的请求最终都应该传送到顶层的启动类加载器 BootstrapClassLoader 中。当父类加载器无法处理时,才由自己来处理。当父类加载器为null时,会使用启动类加载器 BootstrapClassLoader 作为父类加载器。
AppClassLoader的父类加载器为ExtClassLoader ExtClassLoader的父类加载器为null,null并不代表ExtClassLoader没有父类加载器,而是 BootstrapClassLoader 。
双亲委派模型保证了Java程序的稳定运行,可以避免类的重复加载(JVM 区分不同类的方式不仅仅根据类名,相同的类文件被不同的类加载器加载产生的是两个不同的类),也保证了 Java 的核心 API 不被篡改。如果没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 java.lang.Object 类的话,那么程序运行的时候,系统就会出现多个不同的 Object 类,这样也更安全。
除了 BootstrapClassLoader 其他类加载器均由 Java 实现且全部继承自java.lang.ClassLoader。如果我们要自定义自己的类加载器,很明显需要继承 ClassLoader。
栈溢出排查解决思路(错误)
- 查找关键报错信息,确定是StackOverflowError还是OutOfMemoryError
- 如果是StackOverflowError,检查代码是否递归调用方法等
- 如果是OutOfMemoryError,检查是否有死循环创建线程等,通过-Xss降低的每个线程栈大小的容量
方法区溢出原因(错误)
- 使用CGLib生成了大量的代理类,导致方法区被撑爆
- 在Java7之前,频繁的错误使用String.intern方法
- 大量jsp和动态产生jsp
- 应用长时间运行,没有重启
方法区溢出排查解决思路
- 检查是否永久代空间设置得过小
- 检查代码是否频繁错误得使用String.intern方法
- 检查是否跟jsp有关。
- 检查是否使用CGLib生成了大量的代理类
- 重启大法,重启JVM
直接内存溢出原因
- 本机直接内存(元空间)的分配虽然不会受到Java 堆大小的限制,但是受到本机总内存大小限制。
- 直接内存由 -XX:MaxDirectMemorySize 指定,如果不指定,则默认与Java堆最大值(-Xmx指定)一样。
- NIO程序中,使用ByteBuffer.allocteDirect(capability)分配的是直接内存,可能导致直接内存溢出。
直接内存溢出解决方法
- 检查代码是否恰当
- 检查JVM参数-Xmx,-XX:MaxDirectMemorySize 是否合理。
GC overhead limit exceeded
- 这个是JDK6新加的错误类型,一般都是堆太小导致的。
- Sun 官方对此的定义:超过98%的时间用来做GC并且回收了不到2%的堆内存时会抛出此异常。
解决方案
- 检查项目中是否有大量的死循环或有使用大内存的代码,优化代码。
- 检查JVM参数-Xmx -Xms是否合理
- dump内存,检查是否存在内存泄露,如果没有,加大内存。
不能创建新native线程
- 创建线程超过了系统承载极限
- 单个进程创建过多线程,如linux中非root用户规定单个进程最多创建1024个线程,况且linux中还有其他线程
元空间
- 主要存放虚拟机加载的类信息,常量池,静态变量,即时编译的代码
- 比如用反射元空间生成静态类过多。
Memory Leak是指程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光。 在Java中,内存泄漏就是存在一些被分配的对象,这些对象有下面两个特点: 1)首先,这些对象是可达的,即在有向图中,存在通路可以与其相连; 2)其次,这些对象是无用的,即程序以后不会再使用这些对象。 如果对象满足这两个条件,这些对象就可以判定为Java中的内存泄漏,这些对象不会被GC所回收,然而它却占用内存。 内存泄露会最终会导致内存溢出。 相同点:都会导致应用程序运行出现问题,性能下降或挂起。 不同点:1) 内存泄露是导致内存溢出的原因之一,内存泄露积累起来将导致内存溢出。2) 内存泄露可以通过完善代码来避免,内存溢出可以通过调整配置来减少发生频率,但无法彻底避免。
静态变量的生命周期和应用程序一致,他们所引用的所有的对象Object也不能被释放:
Static Vector v = new Vector(10);
for (int i = 0; i < 100; i++) {
Object o = new Object();
v.add(o);
o = null;
}数据库连接(dataSourse.getConnection()*),网络连接(socket*)和io*连接,除非其显式的调用了其close()*** 方法将其连接关闭,否则是不会自动被GC回收的。
内部类的引用是比较容易遗忘的一种,而且一旦没释放可能导致一系列的后继类对象没有释放。
一、继承Thread类创建线程类
(1)定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。
(2)创建Thread子类的实例,即创建了线程对象。
(3)调用线程对象的start()方法来启动该线程。
package com.thread;
public class FirstThreadTest extends Thread{
int i = 0;
//重写run方法,run方法的方法体就是现场执行体
public void run()
{
for(;i<100;i++){
System.out.println(getName()+" "+i);
}
}
public static void main(String[] args)
{
for(int i = 0;i< 100;i++)
{
System.out.println(Thread.currentThread().getName()+" : "+i);
if(i==20)
{
new FirstThreadTest().start();
new FirstThreadTest().start();
}
}
}
}j上述代码中Thread.currentThread()方法返回当前正在执行的线程对象。GetName()方法返回调用该方法的线程的名字。
二、通过Runnable接口创建线程类
(1)定义runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
(2)创建 Runnable实现类的实例,并依此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
(3)调用线程对象的start()方法来启动该线程。
package com.thread;
public class RunnableThreadTest implements Runnable
{
private int i;
public void run()
{
for(i = 0;i <100;i++)
{
System.out.println(Thread.currentThread().getName()+" "+i);
}
}
public static void main(String[] args)
{
for(int i = 0;i < 100;i++)
{
System.out.println(Thread.currentThread().getName()+" "+i);
if(i==20)
{
RunnableThreadTest rtt = new RunnableThreadTest();
new Thread(rtt,"新线程1").start();
new Thread(rtt,"新线程2").start();
}
}
}
三、通过Callable和Future创建线程
(1)创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。
(2)创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。
(3)使用FutureTask对象作为Thread对象的target创建并启动新线程。
(4)调用FutureTask对象的get()方法来获得子线程执行结束后的返回值
package com.thread;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class CallableThreadTest implements Callable<Integer>
{
public static void main(String[] args)
{
CallableThreadTest ctt = new CallableThreadTest();
FutureTask<Integer> ft = new FutureTask<>(ctt);
for(int i = 0;i < 100;i++)
{
System.out.println(Thread.currentThread().getName()+" 的循环变量i的值"+i);
if(i==20)
{
new Thread(ft,"有返回值的线程").start();
}
}
try
{
System.out.println("子线程的返回值:"+ft.get());
} catch (InterruptedException e)
{
e.printStackTrace();
} catch (ExecutionException e)
{
e.printStackTrace();
}
}
@Override
public Integer call() throws Exception
{
int i = 0;
for(;i<100;i++)
{
System.out.println(Thread.currentThread().getName()+" "+i);
}
return i;
}
}
4 使用线程池
- 初始状态 实现Runnable接口和继承Thread可以得到一个线程类,new一个实例出来,线程就进入了初始状态。
2.1. 就绪状态 就绪状态只是说你资格运行,调度程序没有挑选到你,你就永远是就绪状态。 调用线程的start()方法,此线程进入就绪状态。 当前线程sleep()方法结束,其他线程join()结束,等待用户输入完毕,某个线程拿到对象锁,这些线程也将进入就绪状态。 当前线程时间片用完了,调用当前线程的yield()方法,当前线程进入就绪状态。 锁池里的线程拿到对象锁后,进入就绪状态。 2.2. 运行中状态 线程调度程序从可运行池中选择一个线程作为当前线程时线程所处的状态。这也是线程进入运行状态的唯一一种方式。
- 阻塞状态 阻塞状态是线程阻塞在进入synchronized关键字修饰的方法或代码块(获取锁)时的状态。
- 等待 处于这种状态的线程不会被分配CPU执行时间,它们要等待被显式地唤醒,否则会处于无限期等待的状态。
- 超时等待 处于这种状态的线程不会被分配CPU执行时间,不过无须无限期等待被其他线程显示地唤醒,在达到一定时间后它们会自动唤醒。
- 终止状态 当线程的run()方法完成时,或者主线程的main()方法完成时,我们就认为它终止了。这个线程对象也许是活的,但是,它已经不是一个单独执行的线程。线程一旦终止了,就不能复生。 在一个终止的线程上调用start()方法,会抛出java.lang.IllegalThreadStateException异常。
现在linux是大多基于抢占式,CPU给每个任务一定的服务时间,当时间片轮转的时候,需要把当前状态保存下来,同时加载下一个任务,这个过程叫做上下文切换。时间片轮转的方式,使得多个任务利用一个CPU执行成为可能,但是保存现场和加载现场,也带来了性能消耗。 那线程上下文切换的次数和时间以及性能消耗如何看呢?
上下文切换的性能消耗在哪里呢? context switch过高,会导致CPU像个搬运工,频繁在寄存器和运行队列直接奔波 ,更多的时间花在了线程切换,而不是真正工作的线程上。直接的消耗包括CPU寄存器需要保存和加载,系统调度器的代码需要执行。间接消耗在于多核cache之间的共享数据。
引起上下文切换的原因有哪些? 对于抢占式操作系统而言, 大体有几种: 1、当前任务的时间片用完之后,系统CPU正常调度下一个任务; 2、当前任务碰到IO阻塞,调度线程将挂起此任务,继续下一个任务; 3、多个任务抢占锁资源,当前任务没有抢到,被调度器挂起,继续下一个任务; 4、用户代码挂起当前任务,让出CPU时间; 5、硬件中断;
监测Linux的应用的时候,当CPU的利用率非常高,但是系统的性能却上不去的时候,不妨监控一下线程/进程的切换,看看是不是context switching导致的overhead过高。 常用命令: pidstat vmstat
公平锁/非公平锁
公平锁是指多个线程按照申请锁的顺序来获取锁。
非公平锁是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁。有可能,会造成优先级反转或者饥饿现象。
对于Java ReentrantLock而言,通过构造函数指定该锁是否是公平锁,默认是非公平锁。非公平锁的优点在于吞吐量比公平锁大。
对于Synchronized而言,也是一种非公平锁。由于其并不像ReentrantLock是通过AQS的来实现线程调度,所以并没有任何办法使其变成公平锁
可重入锁
可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁。
对于Java ReentrantLock而言, 他的名字就可以看出是一个可重入锁,其名字是Re entrant Lock重新进入锁。
对于Synchronized而言,也是一个可重入锁。可重入锁的一个好处是可一定程度避免死锁。
独享锁/共享锁
独享锁是指该锁一次只能被一个线程所持有。 共享锁是指该锁可被多个线程所持有。
对于Java ReentrantLock而言,其是独享锁。但是对于Lock的另一个实现类ReadWriteLock,其读锁是共享锁,其写锁是独享锁。
读锁的共享锁可保证并发读是非常高效的,读写,写读 ,写写的过程是互斥的。
独享锁与共享锁也是通过AQS来实现的,通过实现不同的方法,来实现独享或者共享。
对于Synchronized而言,当然是独享锁。
互斥锁/读写锁
上面讲的独享锁/共享锁就是一种广义的说法,互斥锁/读写锁就是具体的实现。
互斥锁在Java中的具体实现就是ReentrantLock
读写锁在Java中的具体实现就是ReadWriteLock
乐观锁/悲观锁
乐观锁与悲观锁不是指具体的什么类型的锁,而是指看待并发同步的角度。 悲观锁认为对于同一个数据的并发操作,一定是会发生修改的,哪怕没有修改,也会认为修改。因此对于同一个数据的并发操作,悲观锁采取加锁的形式。悲观的认为,不加锁的并发操作一定会出问题。 乐观锁则认为对于同一个数据的并发操作,是不会发生修改的。在更新数据的时候,会采用尝试更新,不断重新的方式更新数据。乐观的认为,不加锁的并发操作是没有事情的。
从上面的描述我们可以看出,悲观锁适合写操作非常多的场景,乐观锁适合读操作非常多的场景,不加锁会带来大量的性能提升。 悲观锁在Java中的使用,就是利用各种锁。 乐观锁在Java中的使用,是无锁编程,常常采用的是CAS算法,典型的例子就是原子类,通过CAS自旋实现原子操作的更新。
分段锁
分段锁其实是一种锁的设计,并不是具体的一种锁,对于ConcurrentHashMap而言,其并发的实现就是通过分段锁的形式来实现高效的并发操作。
我们以ConcurrentHashMap来说一下分段锁的含义以及设计**,ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap(JDK7与JDK8中HashMap的实现)的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表;同时又是一个ReentrantLock(Segment继承了ReentrantLock)。
当需要put元素的时候,并不是对整个hashmap进行加锁,而是先通过hashcode来知道他要放在那一个分段中,然后对这个分段进行加锁,所以当多线程put的时候,只要不是放在一个分段中,就实现了真正的并行的插入。
但是,在统计size的时候,可就是获取hashmap全局信息的时候,就需要获取所有的分段锁才能统计。
分段锁的设计目的是细化锁的粒度,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作。
偏向锁/轻量级锁/重量级锁
这三种锁是指锁的状态,并且是针对Synchronized。在Java 5通过引入锁升级的机制来实现高效Synchronized。这三种锁的状态是通过对象监视器在对象头中的字段来表明的。
偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁。降低获取锁的代价。
轻量级锁是指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。
重量级锁是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让其他申请的线程进入阻塞,性能降低。
自旋锁
在Java中,自旋锁是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU。
多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
- 互斥条件:该资源任意一个时刻只由一个线程占用。
- 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:线程已获得的资源在末使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
破坏互斥条件
这个条件我们没有办法破坏,因为我们用锁本来就是想让他们互斥的(临界资源需要互斥访问)。
破坏请求与保持条件
一次性申请所有的资源。
破坏不剥夺条件
占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
破坏循环等待条件
靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
- 两者最主要的区别在于:sleep 方法没有释放锁,而 wait 方法释放了锁 。
- 两者都可以暂停线程的执行。
- Wait 通常被用于线程间交互/通信,sleep 通常被用于暂停执行。
- wait() 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 notify() 或者 notifyAll() 方法。sleep() 方法执行完成后,线程会自动苏醒。或者可以使用 wait(long timeout)超时后线程会自动苏醒。
synchronized关键字解决的是多个线程之间访问资源的同步性,synchronized关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。synchronized 关键字加到 static 静态方法和 synchronized(class)代码块上都是是给 Class 类上锁。synchronized 关键字加到实例方法上是给对象实例上锁
-
修饰实例方法: 作用于当前对象实例加锁,进入同步代码前要获得当前对象实例的锁
-
修饰静态方法: 也就是给当前类加锁,会作用于类的所有对象实例,因为静态成员不属于任何一个实例对象,是类成员( static 表明这是该类的一个静态资源,不管new了多少个对象,只有一份)。所以如果一个线程 A 调用一个实例对象的非静态 synchronized 方法,而线程 B 需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁。
-
修饰代码块: 指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。
volatile修饰的成员变量在每次被线程访问时,都强迫从主存(共享内存)中重读该成员变量的值。而且,当成员变量发生变化时,强迫线程将变化值回写到主存(共享内存)如果对声明了volatile的变量进行写操作,JVM就会向处理器发送一条Lock前缀的指令,将这个变量所在缓存行的数据写回到系统内存。但是,就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题。所以,在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
Java 虚拟机中的同步(Synchronization)基于进入和退出管程(Monitor)对象实现, 无论是显式同步(有明确的 monitorenter 和 monitorexit 指令,即同步代码块)还是隐式同步都是如此。在 Java 语言中,同步用的最多的地方可能是被 synchronized 修饰的同步方法。同步方法 并不是由 monitorenter 和 monitorexit 指令来实现同步的,而是由方法调用指令读取运行时常量池中方法的 ACC_SYNCHRONIZED 标志来隐式实现的,关于这点,稍后详细分析。下面先来了解一个概念Java对象头,这对深入理解synchronized实现原理非常关键。
在JVM中,对象在内存中的布局分为三块区域:对象头、实例数据和对齐填充。如下:
实例变量:存放类的属性数据信息,包括父类的属性信息,如果是数组的实例部分还包括数组的长度,这部分内存按4字节对齐。
填充数据:由于虚拟机要求对象起始地址必须是8字节的整数倍。填充数据不是必须存在的,仅仅是为了字节对齐,这点了解即可。
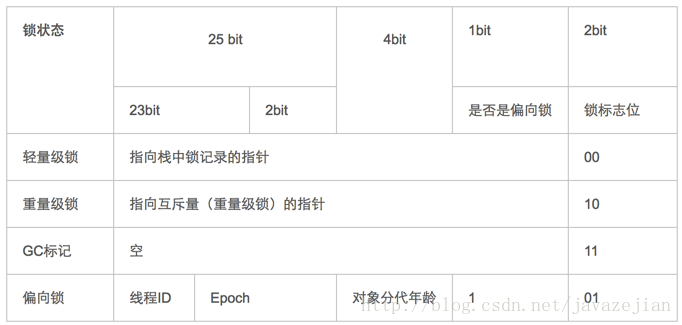
而对于顶部,则是Java头对象,它实现synchronized的锁对象的基础,这点我们重点分析它,一般而言,synchronized使用的锁对象是存储在Java对象头里的,jvm中采用2个字来存储对象头(如果对象是数组则会分配3个字,多出来的1个字记录的是数组长度),其主要结构是由Mark Word 和 Class Metadata Address 组成,其结构说明如下表:
虚拟机位数 头对象结构 说明 32/64bit Mark Word 存储对象的hashCode、锁信息或分代年龄或GC标志等信息 32/64bit Class Metadata Address 类型指针指向对象的类元数据,JVM通过这个指针确定该对象是哪个类的实例。
其中Mark Word在默认情况下存储着对象的HashCode、分代年龄、锁标记位等以下是32位JVM的Mark Word默认存储结构
| 锁状态 | 25bit | 4bit | 1bit是否是偏向锁 | 2bit 锁标志位 |
|---|---|---|---|---|
| 无锁状态 | 对象HashCode | 对象分代年龄 | 0 | 01 |
由于对象头的信息是与对象自身定义的数据没有关系的额外存储成本,因此考虑到JVM的空间效率,Mark Word 被设计成为一个非固定的数据结构,以便存储更多有效的数据,它会根据对象本身的状态复用自己的存储空间,如32位JVM下,除了上述列出的Mark Word默认存储结构外,还有如下可能变化的结构:
简单来讲:对象加锁后,对象头上的mark word指向一个monitor对象。monitor中count为0,没有锁,所以当前线程获得锁成为owner,另一个线程到达后发现owner有了,所以加入到entrylist阻塞队列,进入阻塞状态。直到当前线程结束锁定后重置markword然后才会唤醒另一个线程。另外如当前线程调用wait方法就会首先进入waitlist。
其中轻量级锁和偏向锁是Java 6 对 synchronized 锁进行优化后新增加的,稍后我们会简要分析。这里我们主要分析一下重量级锁也就是通常说synchronized的对象锁,锁标识位为10,其中指针指向的是monitor对象(也称为管程或监视器锁)的起始地址。每个对象都存在着一个 monitor 与之关联,对象与其 monitor 之间的关系有存在多种实现方式,如monitor可以与对象一起创建销毁或当线程试图获取对象锁时自动生成,但当一个 monitor 被某个线程持有后,它便处于锁定状态。在Java虚拟机(HotSpot)中,monitor是由ObjectMonitor实现的,其主要数据结构如下(位于HotSpot虚拟机源码ObjectMonitor.hpp文件,C++实现的)
ObjectMonitor() {
_header = NULL;
_count = 0; //记录个数
_waiters = 0,
_recursions = 0;
_object = NULL;
_owner = NULL;
_WaitSet = NULL; //处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; //处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
ObjectMonitor中有两个队列,_WaitSet 和 _EntryList,用来保存ObjectWaiter对象列表( 每个等待锁的线程都会被封装成ObjectWaiter对象),_owner指向持有ObjectMonitor对象的线程,当多个线程同时访问一段同步代码时,首先会进入 _EntryList 集合,当线程获取到对象的monitor 后进入 _Owner 区域并把monitor中的owner变量设置为当前线程同时monitor中的计数器count加1,若线程调用 wait() 方法,将释放当前持有的monitor,owner变量恢复为null,count自减1,同时该线程进入 WaitSet集合中等待被唤醒。若当前线程执行完毕也将释放monitor(锁)并复位变量的值,以便其他线程进入获取monitor(锁)。如下图所示:
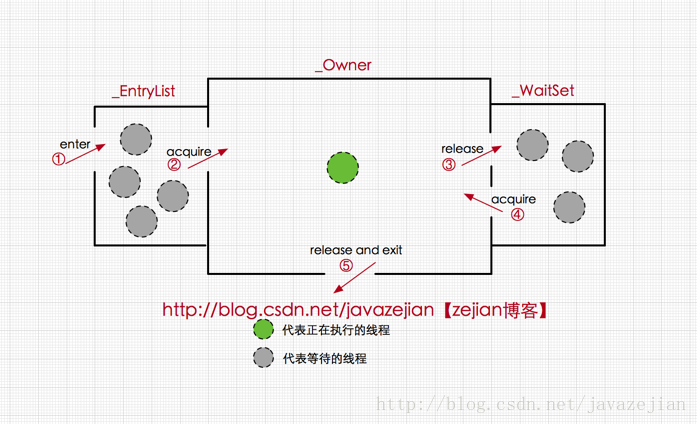
由此看来,monitor对象存在于每个Java对象的对象头中(存储的指针的指向),synchronized锁便是通过这种方式获取锁的,也是为什么Java中任意对象可以作为锁的原因,同时也是notify/notifyAll/wait等方法存在于顶级对象Object中的原因(关于这点稍后还会进行分析),ok~,有了上述知识基础后,下面我们将进一步分析synchronized在字节码层面的具体语义实现。
从字节码中可知同步语句块的实现使用的是monitorenter 和 monitorexit 指令,其中monitorenter指令指向同步代码块的开始位置,monitorexit指令则指明同步代码块的结束位置,当执行monitorenter指令时,当前线程将试图获取 objectref(即对象锁) 所对应的 monitor 的持有权,当 objectref 的 monitor 的进入计数器为 0,那线程可以成功取得 monitor,并将计数器值设置为 1,取锁成功。如果当前线程已经拥有 objectref 的 monitor 的持有权,那它可以重入这个 monitor (关于重入性稍后会分析),重入时计数器的值也会加 1。倘若其他线程已经拥有 objectref 的 monitor 的所有权,那当前线程将被阻塞,直到正在执行线程执行完毕,即monitorexit指令被执行,执行线程将释放 monitor(锁)并设置计数器值为0 ,其他线程将有机会持有 monitor 。值得注意的是编译器将会确保无论方法通过何种方式完成,方法中调用过的每条 monitorenter 指令都有执行其对应 monitorexit 指令,而无论这个方法是正常结束还是异常结束。为了保证在方法异常完成时 monitorenter 和 monitorexit 指令依然可以正确配对执行,编译器会自动产生一个异常处理器,这个异常处理器声明可处理所有的异常,它的目的就是用来执行 monitorexit 指令。从字节码中也可以看出多了一个monitorexit指令,它就是异常结束时被执行的释放monitor 的指令。
方法级的同步是隐式,即无需通过字节码指令来控制的,它实现在方法调用和返回操作之中。JVM可以从方法常量池中的方法表结构(method_info Structure) 中的 ACC_SYNCHRONIZED 访问标志区分一个方法是否同步方法。当方法调用时,调用指令将会 检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先持有monitor(虚拟机规范中用的是管程一词), 然后再执行方法,最后再方法完成(无论是正常完成还是非正常完成)时释放monitor。在方法执行期间,执行线程持有了monitor,其他任何线程都无法再获得同一个monitor。如果一个同步方法执行期间抛 出了异常,并且在方法内部无法处理此异常,那这个同步方法所持有的monitor将在异常抛到同步方法之外时自动释放。 从字节码中可以看出,synchronized修饰的方法并没有monitorenter指令和monitorexit指令,取得代之的确实是ACC_SYNCHRONIZED标识,该标识指明了该方法是一个同步方法,JVM通过该ACC_SYNCHRONIZED访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。这便是synchronized锁在同步代码块和同步方法上实现的基本原理。同时我们还必须注意到的是在Java早期版本中,synchronized属于重量级锁,效率低下,因为监视器锁(monitor)是依赖于底层的操作系统的Mutex Lock来实现的,而操作系统实现线程之间的切换时需要从用户态转换到核心态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,这也是为什么早期的synchronized效率低的原因。庆幸的是在Java 6之后Java官方对从JVM层面对synchronized较大优化,所以现在的synchronized锁效率也优化得很不错了,Java 6之后,为了减少获得锁和释放锁所带来的性能消耗,引入了轻量级锁和偏向锁,接下来我们将简单了解一下Java官方在JVM层面对synchronized锁的优化。
synchronized的可重入性 从互斥锁的设计上来说,当一个线程试图操作一个由其他线程持有的对象锁的临界资源时,将会处于阻塞状态,但当一个线程再次请求自己持有对象锁的临界资源时,这种情况属于重入锁,请求将会成功,在java中synchronized是基于原子性的内部锁机制,是可重入的,因此在一个线程调用synchronized方法的同时在其方法体内部调用该对象另一个synchronized方法,也就是说一个线程得到一个对象锁后再次请求该对象锁,是允许的,这就是synchronized的可重入性。如下:
线程中断: 正如中断二字所表达的意义,在线程运行(run方法)中间打断它,在Java中,提供了以下3个有关线程中断的方法:
//中断线程(实例方法)
public void Thread.interrupt();
//判断线程是否被中断(实例方法)
public boolean Thread.isInterrupted();
//判断是否被中断并清除当前中断状态(静态方法)
public static boolean Thread.interrupted();
当一个线程处于被阻塞状态或者试图执行一个阻塞操作时,使用Thread.interrupt()方式中断该线程,注意此时将会抛出一个InterruptedException的异常,同时中断状态将会被复位(由中断状态改为非中断状态)。
事实上线程的中断操作对于正在等待获取的锁对象的synchronized方法或者代码块并不起作用,也就是对于synchronized来说,如果一个线程在等待锁,那么结果只有两种,要么它获得这把锁继续执行,要么它就保存等待,即使调用中断线程的方法,也不会生效。
锁的状态总共有四种,无锁状态、偏向锁、轻量级锁和重量级锁。随着锁的竞争,锁可以从偏向锁升级到轻量级锁,再升级的重量级锁,但是锁的升级是单向的,也就是说只能从低到高升级,不会出现锁的降级,关于重量级锁,前面我们已详细分析过,下面我们将介绍偏向锁和轻量级锁以及JVM的其他优化手段,这里并不打算深入到每个锁的实现和转换过程更多地是阐述Java虚拟机所提供的每个锁的核心优化**,毕竟涉及到具体过程比较繁琐,如需了解详细过程可以查阅《深入理解Java虚拟机原理》。
偏向锁 偏向锁是Java 6之后加入的新锁,它是一种针对加锁操作的优化手段,经过研究发现,在大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,因此为了减少同一线程获取锁(会涉及到一些CAS操作,耗时)的代价而引入偏向锁。偏向锁的核心**是,如果一个线程获得了锁,那么锁就进入偏向模式,此时Mark Word 的结构也变为偏向锁结构,当这个线程再次请求锁时,无需再做任何同步操作,即检查线程ID是否是自己,是就直接获取锁的过程,这样就省去了大量有关锁申请的操作,从而也就提供程序的性能。所以,对于没有锁竞争的场合,偏向锁有很好的优化效果,毕竟极有可能连续多次是同一个线程申请相同的锁。但是对于锁竞争比较激烈的场合,偏向锁就失效了,因为这样场合极有可能每次申请锁的线程都是不相同的,因此这种场合下不应该使用偏向锁,否则会得不偿失,需要注意的是,偏向锁失败后,并不会立即膨胀为重量级锁,而是先升级为轻量级锁。下面我们接着了解轻量级锁。偏向锁是默认的,但是需要程序运行一段时间后才生效,并且调用hashcode后偏向锁就会失效。
轻量级锁 倘若偏向锁失败,虚拟机并不会立即升级为重量级锁,它还会尝试使用一种称为轻量级锁的优化手段(1.6之后加入的),此时Mark Word 的结构也变为轻量级锁的结构。轻量级锁能够提升程序性能的依据是“对绝大部分的锁,在整个同步周期内都不存在竞争”,注意这是经验数据。需要了解的是,轻量级锁所适应的场景是线程交替执行同步块的场合,如果存在同一时间访问同一锁的场合,就会导致轻量级锁膨胀为重量级锁(默认)。栈帧产生锁记录对象,包含锁住对象指针和锁记录(可以存储加锁的markword),交换对象锁记录和对象的对象头,对象头中最后两位变成00,即表示轻量级锁,可见上面对象头的图。交换过程用cas实现
锁膨胀
自旋锁 轻量级锁失败后,虚拟机为了避免线程真实地在操作系统层面挂起,还会进行一项称为自旋锁的优化手段。这是基于在大多数情况下,线程持有锁的时间都不会太长,如果直接挂起操作系统层面的线程可能会得不偿失,毕竟操作系统实现线程之间的切换时需要从用户态转换到核心态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,因此自旋锁会假设在不久将来,当前的线程可以获得锁,因此虚拟机会让当前想要获取锁的线程做几个空循环(这也是称为自旋的原因),一般不会太久,可能是50个循环或100循环,在经过若干次循环后,如果得到锁,就顺利进入临界区。如果还不能获得锁,那就会将线程在操作系统层面挂起,这就是自旋锁的优化方式,这种方式确实也是可以提升效率的。最后没办法也就只能升级为重量级锁了。
锁消除 消除锁是虚拟机另外一种锁的优化,这种优化更彻底,Java虚拟机在JIT编译时(可以简单理解为当某段代码即将第一次被执行时进行编译,又称即时编译),通过对运行上下文的扫描,去除不可能存在共享资源竞争的锁,通过这种方式消除没有必要的锁,可以节省毫无意义的请求锁时间。
所谓等待唤醒机制本篇主要指的是notify/notifyAll和wait方法,在使用这3个方法时,必须处于synchronized代码块或者synchronized方法中,否则就会抛出IllegalMonitorStateException异常,这是因为调用这几个方法前必须拿到当前对象的监视器monitor对象,也就是说notify/notifyAll和wait方法依赖于monitor对象,在前面的分析中,我们知道monitor 存在于对象头的Mark Word 中(存储monitor引用指针),而synchronized关键字可以获取 monitor ,这也就是为什么notify/notifyAll和wait方法必须在synchronized代码块或者synchronized方法调用的原因。 需要特别理解的一点是,与sleep方法不同的是wait方法调用完成后,线程将被暂停,但wait方法将会释放当前持有的监视器锁(monitor),直到有线程调用notify/notifyAll方法后方能继续执行,而sleep方法只让线程休眠并不释放锁。同时notify/notifyAll方法调用后,并不会马上释放监视器锁,而是在相应的synchronized(){}/synchronized方法执行结束后才自动释放锁。
与synchronized相比:
可中断
可以设置超时时间
可设置为公平锁
支持多个条件变量 condition
ReentrantLock是显式锁,即锁的持有和释放都必须由我们手动编写。官方在concurrent并发包中加入了Lock接口,该接口中提供了lock()方法和unLock()方法对显式加锁和显式释放锁操作进行支持,简单了解一下代码编写,如下:
Lock lock = new ReentrantLock();
lock.lock();
try{
//临界区......
}finally{
lock.unlock();
}正如代码所显示(ReentrantLock是Lock的实现类,稍后分析),当前线程使用lock()方法与unlock()对临界区进行包围,其他线程由于无法持有锁将无法进入临界区直到当前线程释放锁,注意unlock()操作必须在finally代码块中,这样可以确保即使临界区执行抛出异常,线程最终也能正常释放锁,Lock接口还提供了锁以下相关方法:
//可中断获取锁,与lock()不同之处在于可响应中断操作,即在获
//取锁的过程中可中断,注意synchronized在获取锁时是不可中断的
void lockInterruptibly() throws InterruptedException;
//尝试非阻塞获取锁,调用该方法后立即返回结果,如果能够获取则返回true,否则返回false
boolean tryLock();
//根据传入的时间段获取锁,在指定时间内没有获取锁则返回false,如果在指定时间内当前线程未被中并断获取到锁则返回true
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
//获取等待通知组件,该组件与当前锁绑定,当前线程只有获得了锁
//才能调用该组件的wait()方法,而调用后,当前线程将释放锁。
Condition newCondition();AbstractQueuedSynchronizer又称为队列同步器(后面简称AQS),它是用来构建锁或其他同步组件的基础框架,内部通过一个int类型的成员变量state来控制同步状态,当state=0时,则说明没有任何线程占有共享资源的锁,当state=1时,则说明有线程目前正在使用共享变量,其他线程必须加入同步队列进行等待CAS机制改变state。AQS内部通过内部类Node构成FIFO的同步队列来完成线程获取锁的排队工作,同时利用内部类ConditionObject构建等待队列,当Condition调用wait()方法后,线程将会加入等待队列中,而当Condition调用signal()方法后,线程将从等待队列转移动同步队列中进行锁竞争。注意这里涉及到两种队列,一种的同步队列,当线程请求锁而等待的后将加入同步队列等待,而另一种则是等待队列(可有多个),通过Condition调用await()方法释放锁后,将加入等待队列。关于Condition的等待队列我们后面再分析,这里我们先来看看AQS中的同步队列模型,如下
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer{
//指向同步队列队头
private transient volatile Node head;
//指向同步的队尾
private transient volatile Node tail;
//同步状态,0代表锁未被占用,1代表锁已被占用
private volatile int state;
//省略其他代码......
}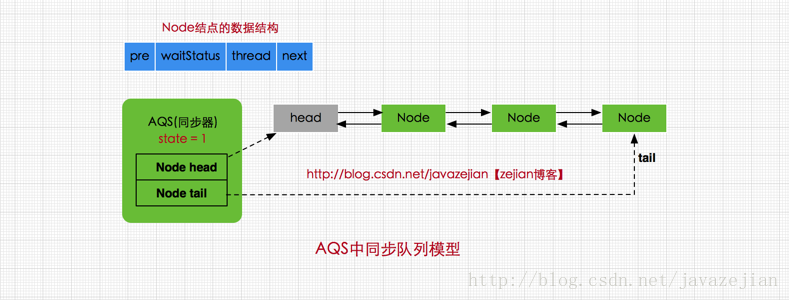
head和tail分别是AQS中的变量,其中head指向同步队列的头部,注意head为空结点,不存储信息。而tail则是同步队列的队尾,同步队列采用的是双向链表的结构这样可方便队列进行结点增删操作。state变量则是代表同步状态,执行当线程调用lock方法进行加锁后,如果此时state的值为0,则说明当前线程可以获取到锁(在本篇文章中,锁和同步状态代表同一个意思),同时将state设置为1,表示获取成功。如果state已为1,也就是当前锁已被其他线程持有,那么当前执行线程将被封装为Node结点加入同步队列等待。其中Node结点是对每一个访问同步代码的线程的封装,从图中的Node的数据结构也可看出,其包含了需要同步的线程本身以及线程的状态,如是否被阻塞,是否等待唤醒,是否已经被取消等。每个Node结点内部关联其前继结点prev和后继结点next,这样可以方便线程释放锁后快速唤醒下一个在等待的线程,Node是AQS的内部类,其数据结构如下:
static final class Node {
//共享模式
static final Node SHARED = new Node();
//独占模式
static final Node EXCLUSIVE = null;
//标识线程已处于结束状态
static final int CANCELLED = 1;
//等待被唤醒状态
static final int SIGNAL = -1;
//条件状态,
static final int CONDITION = -2;
//在共享模式中使用表示获得的同步状态会被传播
static final int PROPAGATE = -3;
//等待状态,存在CANCELLED、SIGNAL、CONDITION、PROPAGATE 4种
volatile int waitStatus;
//同步队列中前驱结点
volatile Node prev;
//同步队列中后继结点
volatile Node next;
//请求锁的线程
volatile Thread thread;
//等待队列中的后继结点,这个与Condition有关,稍后会分析
Node nextWaiter;
//判断是否为共享模式
final boolean isShared() {
return nextWaiter == SHARED;
}
//获取前驱结点
final Node predecessor() throws NullPointerException {
Node p = prev;
if (p == null)
throw new NullPointerException();
else
return p;
}
//.....
}其中SHARED和EXCLUSIVE常量分别代表共享模式和独占模式,所谓共享模式是一个锁允许多条线程同时操作,如信号量Semaphore采用的就是基于AQS的共享模式实现的,而独占模式则是同一个时间段只能有一个线程对共享资源进行操作,多余的请求线程需要排队等待,如ReentranLock。变量waitStatus则表示当前被封装成Node结点的等待状态,共有4种取值CANCELLED、SIGNAL、CONDITION、PROPAGATE。
CANCELLED:值为1,在同步队列中等待的线程等待超时或被中断,需要从同步队列中取消该Node的结点,其结点的waitStatus为CANCELLED,即结束状态,进入该状态后的结点将不会再变化。
SIGNAL:值为-1,被标识为该等待唤醒状态的后继结点,当其前继结点的线程释放了同步锁或被取消,将会通知该后继结点的线程执行。说白了,就是处于唤醒状态,只要前继结点释放锁,就会通知标识为SIGNAL状态的后继结点的线程执行。
CONDITION:值为-2,与Condition相关,该标识的结点处于等待队列中,结点的线程等待在Condition上,当其他线程调用了Condition的signal()方法后,CONDITION状态的结点将从等待队列转移到同步队列中,等待获取同步锁。
PROPAGATE:值为-3,与共享模式相关,在共享模式中,该状态标识结点的线程处于可运行状态。
0状态:值为0,代表初始化状态。
pre和next,分别指向当前Node结点的前驱结点和后继结点,thread变量存储的请求锁的线程。nextWaiter,与Condition相关,代表等待队列中的后继结点,关于这点这里暂不深入,后续会有更详细的分析,嗯,到此我们对Node结点的数据结构也就比较清晰了。总之呢,AQS作为基础组件,对于锁的实现存在两种不同的模式,即共享模式(如Semaphore)和独占模式(如ReetrantLock),无论是共享模式还是独占模式的实现类,其内部都是基于AQS实现的,也都维持着一个虚拟的同步队列,当请求锁的线程超过现有模式的限制时,会将线程包装成Node结点并将线程当前必要的信息存储到node结点中,然后加入同步队列等会获取锁,而这系列操作都有AQS协助我们完成,这也是作为基础组件的原因,无论是Semaphore还是ReetrantLock,其内部绝大多数方法都是间接调用AQS完成的,下面是AQS整体类图结构
ReentrantLock与AQS的关系:
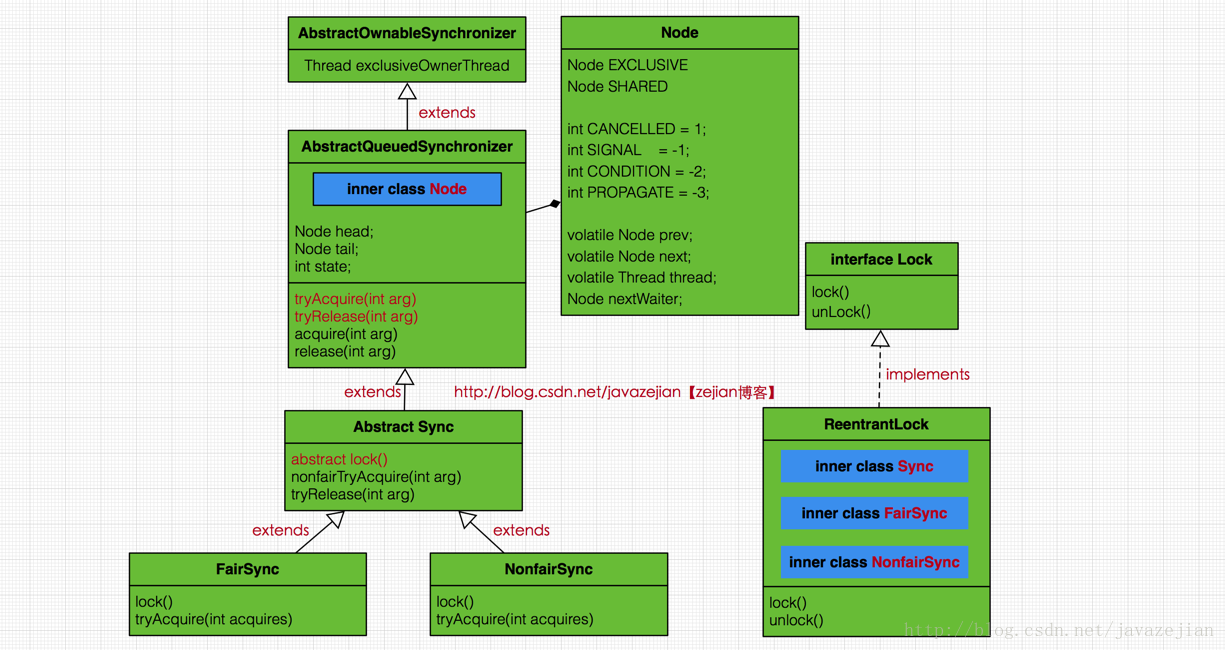
ReentrantLock内部存在3个实现类,分别是Sync、NonfairSync、FairSync,其中Sync继承自AQS实现了解锁tryRelease()方法,而NonfairSync(非公平锁)、 FairSync(公平锁)则继承自Sync,实现了获取锁的tryAcquire()方法,ReentrantLock的所有方法调用都通过间接调用AQS和Sync类及其子类来完成的。从上述类图可以看出AQS是一个抽象类,但请注意其源码中并没一个抽象的方法,这是因为AQS只是作为一个基础组件,并不希望直接作为直接操作类对外输出,而更倾向于作为基础组件,为真正的实现类提供基础设施,如构建同步队列,控制同步状态等,事实上,从设计模式角度来看,AQS采用的模板模式的方式构建的,其内部除了提供并发操作核心方法以及同步队列操作外,还提供了一些模板方法让子类自己实现,如加锁操作以及解锁操作,为什么这么做?这是因为AQS作为基础组件,封装的是核心并发操作,但是实现上分为两种模式,即共享模式与独占模式,而这两种模式的加锁与解锁实现方式是不一样的,但AQS只关注内部公共方法实现并不关心外部不同模式的实现,所以提供了模板方法给子类使用,也就是说实现独占锁,如ReentrantLock需要自己实现tryAcquire()方法和tryRelease()方法,而实现共享模式的Semaphore,则需要实现tryAcquireShared()方法和tryReleaseShared()方法,这样做的好处是显而易见的,无论是共享模式还是独占模式,其基础的实现都是同一套组件(AQS),只不过是加锁解锁的逻辑不同罢了,更重要的是如果我们需要自定义锁的话,也变得非常简单,只需要选择不同的模式实现不同的加锁和解锁的模板方法即可.
ThreadLocal 可以做到线程隔离,这样来作为一个线程中的全局变量。它相当于一个key,每个thread中有一个名为threadlocals的map,其中的key就是定义的threadlocal。它extend了weakreference来避免线程结束后依然长久存活。
保证可见性:对一些全局变量,在A线程中修改后,B线程不一定会感知到,加上volatile则会感知
不保证原子性:线程业务不可以分割,要么执行要么失败。volatile操作将变量从主存读取到栈中,操作后再返回,操作如果太快,不同的线程可能会覆盖彼此的操作
禁止指令重排:每个指令间插入一条内存屏障禁止指令前后重排序优化,并且强制弹出CPU缓存数据,保证可以读取最新数据
-
编译器优化的重排
编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
-
指令并行的重排
现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性(即后一个执行的语句无需依赖前面执行的语句的结果),处理器可以改变语句对应的机器指令的执行顺序
-
内存系统的重排
由于处理器使用缓存和读写缓存冲区,这使得加载(load)和存储(store)操作看上去可能是在乱序执行,因为三级缓存的存在,导致内存与缓存的数据同步存在时间差。
-
volatile关键字是线程同步的轻量级实现,所以volatile性能肯定比synchronized关键字要好。但是volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块。synchronized关键字在JavaSE1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的偏向锁和轻量级锁以及其它各种优化之后执行效率有了显著提升,实际开发中使用synchronized关键字还是更多一些。
-
多线程访问volatile关键字不会发生阻塞,而synchronized关键字可能会发生阻塞
-
volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证。
-
volatile关键字用于解决变量在多个线程之间的可见性,而synchronized关键字解决的是多个线程之间访问资源的同步性。
在 Java 并发领域,我们解决并发安全问题最粗暴的方式就是使用 synchronized 关键字了,但它是一种独占形式的锁,属于悲观锁机制,性能会大打折扣。volatile 貌似也是一个不错的选择,但 volatile 只能保持变量的可见性,并不保证变量的原子性操作。
CAS 全称是 compare and swap,即比较并交换,它是一种原子操作,相当于CPU的原子指令,同时 CAS 是一种乐观机制。java.util.concurrent 包很多功能都是建立在 CAS 之上,如 ReenterLock 内部的 AQS,各种原子类,其底层都用 CAS来实现原子操作。
CAS 的**很简单:三个参数,一个当前内存值 V、旧的预期值 A、即将更新的值 B,当且仅当预期值 A 和内存值 V 相同时,将内存值修改为 B 并返回 true,否则什么都不做,并返回 false。
原子类用到了 sun.misc.Unsafe 类,它可以提供硬件级别的原子操作,它可以获取某个属性在内存中的位置,也可以修改对象的字段值,只不过该类对一般开发而言,很少会用到,其底层是用 C/C++ 实现的,所以它的方式都是被 native 关键字修饰过的。可以看得出 AtomicInteger 类存储的值是在 value 字段中,并且获取了 Unsafe 实例,在静态代码块中,还获取了 value 字段在内存中的偏移量 valueOffset。
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));// 自旋
return var5;
}var5 通过 this.getIntVolatile(var1, var2)方法获取,是个 native 方法,其目的是获取 var1对象 在 var2 偏移量的值,其中 var1 就是 AtomicInteger, var2 是 valueOffset 值。那么 CAS 核心重点来了,compareAndSwapInt 就是实现 CAS 的核心方法,其原理是如果 var1 中的 value 值和 var5 相等,就证明没有其他线程改变过这个变量,那么就把 value 值更新为 var5 + var4,其中 var4 是更新的增量值;反之如果没有更新,那么 CAS 就一直采用自旋的方式继续进行操作(其实就是个 while 循环),这一步也是一个原子操作。
- 设定 AtomicInteger 的 value 原始值为 A,从 Java 内存模型得知,线程 1 和线程 2 各自持有一份 value 的副本,值都是 A。
- 线程 1 通过
getIntVolatile(var1, var2)拿到 value 值 A,这时线程 1 被挂起。 - 线程 2 也通过
getIntVolatile(var1, var2)方法获取到 value 值 A,并执行compareAndSwapInt方法比较内存值也为 A,成功修改内存值为 B。 - 这时线程 1 恢复执行
compareAndSwapInt方法比较,发现自己手里的值 A 和内存的值 B 不一致,说明该值已经被其它线程提前修改过了。 - 线程 1 重新执行
getIntVolatile(var1, var2)再次获取 value 值,因为变量 value 被 volatile 修饰,所以其它线程对它的修改,线程 A 总是能够看到,线程A继续执行compareAndSwapInt进行比较替换,直到成功。
ABA:
例如线程 1 从内存位置 V 取出 A,这时候线程 2 也从内存位置 V 取出 A,此时线程 1 处于挂起状态,线程 2 将位置 V 的值改成 B,最后再改成 A,这时候线程 1 再执行,发现位置 V 的值没有变化,尽管线程 1 也更改成功了,但是不代表这个过程就是没有问题的。
举例分析:
现有一个用单向链表实现的栈,栈顶元素为 A,A.next 为 B,期望用 CAS 将栈顶替换成 B。
有线程 1 获取了元素 A,此时线程 1 被挂起,线程 2 也获取了元素 A,并将 A、B 出栈,再 push D、C、A,这时线程 1 恢复执行 CAS,因为此时栈顶元素依然为 A,线程 1 执行成功,栈顶元素变成了 B,但 B.next 为 null,这就会导致 C、D 被丢掉了。
这个例子充分说明了 CAS 的 ABA 问退带来的隐患,通常,我们的乐观锁实现中都会带一个 version 字段来记录更改的版本,避免并发操作带来的问题。在 Java 中,AtomicStampedReference 也实现了这个处理方式。
自旋:
从源码可以知道所说的自旋无非就是操作结果失败后继续循环操作,这种操作也称之为自旋锁,是一种乐观锁机制,一般来说都会给一个限定的自选次数,防止进入死循环。
自旋锁的优点是不需要休眠当前线程,因为自旋锁使用者一般保持锁时间非常短,因此选择自旋而不是休眠当前线程是提高并发性能的关键点,这是因为减少了很多不必要的线程上下文切换开销。
但是,如果 CAS 一直操作不成功,会造成长时间原地自旋,会给 CPU 带来非常大的执行开销。 CAS也只能保证一个共享变量的原子性.
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
| 方法\处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入方法 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除方法 | remove() | poll() | take() | poll(time,unit) |
| 检查方法 | element() | peek() | 不可用 | 不可用 |
- 抛出异常:是指当阻塞队列满时候,再往队列里插入元素,会抛出 IllegalStateException("Queue full") 异常。当队列为空时,从队列里获取元素时会抛出 NoSuchElementException 异常 。
- 返回特殊值:插入方法会返回是否成功,成功则返回 true。移除方法,则是从队列里拿出一个元素,如果没有则返回 null
- 一直阻塞:当阻塞队列满时,如果生产者线程往队列里 put 元素,队列会一直阻塞生产者线程,直到拿到数据,或者响应中断退出。当队列空时,消费者线程试图从队列里 take 元素,队列也会阻塞消费者线程,直到队列可用。
- 超时退出:当阻塞队列满时,队列会阻塞生产者线程一段时间,如果超过一定的时间,生产者线程就会退出。
包括:
-
ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。ArrayBlockingQueue 是一个用数组实现的有界阻塞队列。此队列按照先进先出(FIFO)的原则对元素进行排序。默认情况下不保证访问者公平的访问队列,所谓公平访问队列是指阻塞的所有生产者线程或消费者线程,当队列可用时,可以按照阻塞的先后顺序访问队列,即先阻塞的生产者线程,可以先往队列里插入元素,先阻塞的消费者线程,可以先从队列里获取元素。通常情况下为了保证公平性会降低吞吐量。访问者的公平性是使用可重入锁实现的.
-
LinkedBlockingQueue :一个由链表结构组成的有界阻塞队列。此队列的默认和最大长度为 Integer.MAX_VALUE。此队列按照先进先出的原则对元素进行排序。
-
PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列。默认情况下元素采取自然顺序排列,也可以通过比较器 comparator 来指定元素的排序规则。元素按照升序排列。
-
DelayQueue:一个使用优先级队列实现的无界阻塞队列。队列使用 PriorityQueue 来实现。队列中的元素必须实现 Delayed 接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。我们可以将 DelayQueue 运用在以下应用场景:
-
- 缓存系统的设计:可以用 DelayQueue 保存缓存元素的有效期,使用一个线程循环查询 DelayQueue,一旦能从 DelayQueue 中获取元素时,表示缓存有效期到了。
- 定时任务调度。使用 DelayQueue 保存当天将会执行的任务和执行时间,一旦从 DelayQueue 中获取到任务就开始执行,从比如 TimerQueue 就是使用 DelayQueue 实现的。
队列中的 Delayed 必须实现 compareTo 来指定元素的顺序。比如让延时时间最长的放在队列的末尾。延时队列的实现很简单,当消费者从队列里获取元素时,如果元素没有达到延时时间,就阻塞当前线程。
-
SynchronousQueue:一个不存储元素的阻塞队列。每一个 put 操作必须等待一个 take 操作,否则不能继续添加元素。SynchronousQueue 可以看成是一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。队列本身并不存储任何元素,非常适合于传递性场景, 比如在一个线程中使用的数据,传递给另外一个线程使用,SynchronousQueue 的吞吐量高于 LinkedBlockingQueue 和 ArrayBlockingQueue。
-
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。相对于其他阻塞队列,LinkedTransferQueue 多了 tryTransfer 和 transfer 方法。transfer 方法。如果当前有消费者正在等待接收元素(消费者使用 take() 方法或带时间限制的 poll() 方法时),transfer 方法可以把生产者传入的元素立刻 transfer(传输)给消费者。如果没有消费者在等待接收元素,transfer 方法会将元素存放在队列的 tail 节点,并等到该元素被消费者消费了才返回。永乐自旋来实现。tryTransfer 方法用来试探下生产者传入的元素是否能直接传给消费者。如果没有消费者等待接收元素,则返回 false。和 transfer 方法的区别是 tryTransfer 方法无论消费者是否接收,方法立即返回。而 transfer 方法是必须等到消费者消费了才返回。
-
LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。所谓双向队列指的你可以从队列的两端插入和移出元素。双端队列因为多了一个操作队列的入口,在多线程同时入队时,也就减少了一半的竞争。相比其他的阻塞队列,LinkedBlockingDeque 多了 addFirst,addLast,offerFirst,offerLast,peekFirst,peekLast 等方法,以 First 单词结尾的方法,表示插入,获取(peek)或移除双端队列的第一个元素。以 Last 单词结尾的方法,表示插入,获取或移除双端队列的最后一个元素。另外插入方法 add 等同于 addLast,移除方法 remove 等效于 removeFirst。但是 take 方法却等同于 takeFirst,不知道是不是 Jdk 的 bug,使用时还是用带有 First 和 Last 后缀的方法更清楚。
如果队列是空的,消费者会一直等待,当生产者添加元素时候,消费者是如何知道当前队列有元素的呢?如果让你来设计阻塞队列你会如何设计,让生产者和消费者能够高效率的进行通讯呢?让我们先来看看 JDK 是如何实现的。
使用通知模式实现。所谓通知模式,就是当生产者往满的队列里添加元素时会阻塞住生产者,当消费者消费了一个队列中的元素后,会通知生产者当前队列可用。通过查看 JDK 源码发现 ArrayBlockingQueue 使用了 Condition 来实现,代码如下
private final Condition notFull;
private final Condition notEmpty;
public ArrayBlockingQueue(int capacity, boolean fair) {
// 省略其他代码
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
insert(e);
} finally {
lock.unlock();
}
}
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return extract();
} finally {
lock.unlock();
}
}
private void insert(E x) {
items[putIndex] = x;
putIndex = inc(putIndex);
++count;
notEmpty.signal();
}当我们往队列里插入一个元素时,如果队列不可用,阻塞生产者主要通过 LockSupport.park(this);
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}继续进入源码,发现调用 setBlocker 先保存下将要阻塞的线程,然后调用 unsafe.park 阻塞当前线程。
public static void park(Object blocker) {
Thread t = Thread.currentThread();
setBlocker(t, blocker);
unsafe.park(false, 0L);
setBlocker(t, null);
}unsafe.park 是个 native 方法: public native void park(boolean isAbsolute, long time);
park 这个方法会阻塞当前线程,只有以下四种情况中的一种发生时,该方法才会返回。
- 与 park 对应的 unpark 执行或已经执行时。注意:已经执行是指 unpark 先执行,然后再执行的 park。
- 线程被中断时。
- 如果参数中的 time 不是零,等待了指定的毫秒数时。
- 发生异常现象时。这些异常事先无法确定。
park 在不同的操作系统使用不同的方式实现,在 linux 下是使用的是系统方法 pthread_cond_wait 实现。
线程池提供了一种限制和管理资源(包括执行一个任务)。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控
- 它帮我们管理线程,避免增加创建线程和销毁线程的资源损耗。因为线程其实也是一个对象,创建一个对象,需要经过类加载过程,销毁一个对象,需要走GC垃圾回收流程,都是需要资源开销的。
Executors.newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。 newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。 newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。 newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
| 线程池类型 | 核心线程数 | 最大线程数 | 非核心线程空闲时间 | 工作队列 |
|---|---|---|---|---|
| newFixedThreadPool | specific | specific | 0 | LinkedBlockingQueue |
| newSingleThreadExecutor | 1 | 1 | 0 | LinkedBlockingQueue |
| newCachedThreadPool | 0 | Integer.MAX_VALUE | 60s | SynchronousQueue |
| newScheduledThreadPool | specific | Integer.MAX_VALUE | 0 | DelayedWorkQueue |
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
corePoolSize: 线程池核心线程数最大值
maximumPoolSize: 线程池最大线程数大小,如果是cpu密集,核数+1;IO密集表示cpu不会用的太多,所以选择 核数/(1-阻塞系数0.8或0.9)
keepAliveTime: 线程池中非核心线程空闲的存活时间大小,即计时空闲的线程池,到时间后如果线程池数量大于corePoolSize就销毁空闲的线程池
unit: 线程空闲存活时间单位
workQueue: 存放任务的阻塞队列
threadFactory: 用于设置创建线程的工厂,可以给创建的线程设置有意义的名字,可方便排查问题。
handler: 线城池的饱和策略事件,主要有四种类型。提交一个任务,线程池里存活的核心线程数小于线程数corePoolSize时,线程池会创建一个核心线程去处理提交的任务。
如果线程池核心线程数已满,即线程数已经等于corePoolSize,一个新提交的任务,会被放进任务队列workQueuer如排队等待执行。
当线程池里面存活的线程数已经等于corePoolSize了,并且任务队列workQueue也满,判断线程数是否达到maximumPoolSize,即最大线程数是否已满,如果没到达,创建一个非核心线程执行刚提交的任务。如果当前的线程数达到了maximumPoolSize,还有新的任务过来的话,直接采用拒绝策略处理
四种拒绝策略:
- AbortPolicy(抛出一个异常,默认的)
- DiscardPolicy(直接丢弃任务,不抛出异常)
- DiscardOldestPolicy(丢弃队列里等待最久的任务,将当前这个任务继续提交给线程池)
- CallerRunsPolicy(交给线程池调用所在的线程进行处理)
ArrayBlockingQueue(有界队列)是一个用数组实现的有界阻塞队列,按FIFO排序量。
LinkedBlockingQueue(可设置容量队列)基于链表结构的阻塞队列,按FIFO排序任务,容量可以选择进行设置,不设置的话,将是一个无边界的阻塞队列,最大长度为Integer.MAX_VALUE,吞吐量通常要高于ArrayBlockingQuene;newFixedThreadPool线程池使用了这个队列
DelayQueue(延迟队列)是一个任务定时周期的延迟执行的队列。根据指定的执行时间从小到大排序,否则根据插入到队列的先后排序。newScheduledThreadPool线程池使用了这个队列。
PriorityBlockingQueue(优先级队列)是具有优先级的无界阻塞队列;
SynchronousQueue(同步队列)一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQuene,newCachedThreadPool线程池使用了这个队列。
JVM 的方法调用指令有五个,分别是:
invokestatic:调用静态方法;
invokespecial:调用实例构造器方法、私有方法和父类方法;
invokevirtual:调用虚方法;
invokeinterface:调用接口方法,运行时确定具体实现;
invokedynamic:运行时动态解析所引用的方法,然后再执行,用于支持动态类型语言。
其中,invokestatic 和 invokespecial 用于静态绑定,invokevirtual 和 invokeinterface 用于动态绑定。可以看出,动态绑定主要应用于虚方法和接口方法。
静态绑定在编译期就已经确定,这是因为静态方法、构造器方法、私有方法和父类方法可以唯一确定。这些方法的符号引用在类加载的解析阶段就会解析成直接引用。因此这些方法也被称为非虚方法,与之相对的便是虚方法。
虚方法的方法调用与方法实现的关联(也就是分派)有两种,一种是在编译期确定,被称为静态分派,比如方法的重载;一种是在运行时确定,被称为动态分派,比如方法的覆盖。对象方法基本上都是虚方法。
这里需要特别说明的是,final 方法由于不能被覆盖,可以唯一确定,因此 Java 语言规范规定 final 方法属于非虚方法,但仍然使用 invokevirtual 指令调用。静态绑定、动态绑定的概念和虚方法、非虚方法的概念是两个不同的概念。
虚拟机栈中会存放当前方法调用的栈帧,在栈帧中,存储着局部变量表、操作栈、动态连接 、返回地址和其他附加信息。多态的实现过程,就是方法调用动态分派的过程,通过栈帧的信息去找到被调用方法的具体实现,然后使用这个具体实现的直接引用完成方法调用。
以 invokevirtual 指令为例,在执行时,大致可以分为以下几步:
- 先从操作栈中找到对象的实际类型 class;
- 找到 class 中与被调用方法签名相同的方法,如果有访问权限就返回这个方法的直接引用,如果没有访问权限就报错 java.lang.IllegalAccessError ;
- 如果第 2 步找不到相符的方法,就去搜索 class 的父类,按照继承关系自下而上依次执行第 2 步的操作;
- 如果第 3 步找不到相符的方法,就报错 java.lang.AbstractMethodError ;
可以看到,如果子类覆盖了父类的方法,则在多态调用中,动态绑定过程会首先确定实际类型是子类,从而先搜索到子类中的方法。这个过程便是方法覆盖的本质。
实际上,商用虚拟机为了保证性能,通常会使用虚方法表和接口方法表,而不是每次都执行一遍上面的步骤。以虚方法表为例,虚方法表在类加载的解析阶段填充完成,其中存储了所有方法的直接引用。也就是说,动态分派在填充虚方法表的时候就已经完成了。
在子类的虚方法表中,如果子类覆盖了父类的某个方法,则这个方法的直接引用指向子类的实现;而子类没有覆盖的那些方法,比如 Object 的方法,直接引用指向父类或 Object 的实现。
我们使用分布式锁有两个场景:
- 效率:使用分布式锁可以避免不同节点重复相同的工作,这些工作会浪费资源。比如用户付了钱之后有可能不同节点会发出多封短信。
- 正确性:加分布式锁同样可以避免破坏正确性的发生,如果两个节点在同一条数据上面操作,比如多个节点机器对同一个订单操作不同的流程有可能会导致该笔订单最后状态出现错误,造成损失。
当我们确定了在不同节点上需要分布式锁,那么我们需要了解分布式锁到底应该有哪些特点:
- 互斥性:和我们本地锁一样互斥性是最基本,但是分布式锁需要保证在不同节点的不同线程的互斥。
- 可重入性:同一个节点上的同一个线程如果获取了锁之后那么也可以再次获取这个锁。
- 锁超时:和本地锁一样支持锁超时,防止死锁。
- 高效,高可用:加锁和解锁需要高效,同时也需要保证高可用防止分布式锁失效,可以增加降级。
- 支持阻塞和非阻塞:和ReentrantLock一样支持lock和trylock以及tryLock(long timeOut)。
- 支持公平锁和非公平锁(可选):公平锁的意思是按照请求加锁的顺序获得锁,非公平锁就相反是无序的。这个一般来说实现的比较少。
Java 中的 BIO、NIO和 AIO 理解为是 Java 语言对操作系统的各种 IO 模型的封装。程序员在使用这些 API 的时候,不需要关心操作系统层面的知识,也不需要根据不同操作系统编写不同的代码。只需要使用Java的API就可以了。
-
同步 :两个同步任务相互依赖,并且一个任务必须以依赖于另一任务的某种方式执行。 比如在
A->B事件模型中,你需要先完成 A 才能执行B。 再换句话说,同步调用种被调用者未处理完请求之前,调用不返回,调用者会一直等待结果的返回。 -
异步: 两个异步的任务完全独立的,一方的执行不需要等待另外一方的执行。再换句话说,异步调用种一调用就返回结果不需要等待结果返回,当结果返回的时候通过回调函数或者其他方式拿着结果再做相关事情,
-
阻塞: 阻塞就是发起一个请求,调用者一直等待请求结果返回,也就是当前线程会被挂起,无法从事其他任务,只有当条件就绪才能继续。
-
非阻塞: 非阻塞就是发起一个请求,调用者不用一直等着结果返回,可以先去干其他事情。
采用 BIO 通信模型 的服务端,通常由一个独立的 Acceptor 线程负责监听客户端的连接。我们一般通过在while(true) 循环中服务端会调用 accept() 方法等待接收客户端的连接的方式监听请求,请求一旦接收到一个连接请求,就可以建立通信套接字在这个通信套接字上进行读写操作,此时不能再接收其他客户端连接请求,只能等待同当前连接的客户端的操作执行完成, 不过可以通过多线程来支持多个客户端的连接,如上图所示。
如果要让 BIO 通信模型 能够同时处理多个客户端请求,就必须使用多线程(主要原因是socket.accept()、socket.read()、socket.write() 涉及的三个主要函数都是同步阻塞的),也就是说它在接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理,处理完成之后,通过输出流返回应答给客户端,线程销毁。这就是典型的 一请求一应答通信模型 。我们可以设想一下如果这个连接不做任何事情的话就会造成不必要的线程开销,不过可以通过 线程池机制 改善,线程池还可以让线程的创建和回收成本相对较低。使用FixedThreadPool 可以有效的控制了线程的最大数量,保证了系统有限的资源的控制,实现了N(客户端请求数量):M(处理客户端请求的线程数量)的伪异步I/O模型(N 可以远远大于 M),下面一节"伪异步 BIO"中会详细介绍到。我们再设想一下当客户端并发访问量增加后这种模型会出现什么问题?
在 Java 虚拟机中,线程是宝贵的资源,线程的创建和销毁成本很高,除此之外,线程的切换成本也是很高的。尤其在 Linux 这样的操作系统中,线程本质上就是一个进程,创建和销毁线程都是重量级的系统函数。如果并发访问量增加会导致线程数急剧膨胀可能会导致线程堆栈溢出、创建新线程失败等问题,最终导致进程宕机或者僵死,不能对外提供服务。
为了解决同步阻塞I/O面临的一个链路需要一个线程处理的问题,后来有人对它的线程模型进行了优化一一一后端通过一个线程池来处理多个客户端的请求接入,形成客户端个数M:线程池最大线程数N的比例关系,其中M可以远远大于N.通过线程池可以灵活地调配线程资源,设置线程的最大值,防止由于海量并发接入导致线程耗尽。
采用线程池和任务队列可以实现一种叫做伪异步的 I/O 通信框架,它的模型图如上图所示。当有新的客户端接入时,将客户端的 Socket 封装成一个Task(该任务实现java.lang.Runnable接口)投递到后端的线程池中进行处理,JDK 的线程池维护一个消息队列和 N 个活跃线程,对消息队列中的任务进行处理。由于线程池可以设置消息队列的大小和最大线程数,因此,它的资源占用是可控的,无论多少个客户端并发访问,都不会导致资源的耗尽和宕机。
伪异步I/O通信框架采用了线程池实现,因此避免了为每个请求都创建一个独立线程造成的线程资源耗尽问题。不过因为它的底层仍然是同步阻塞的BIO模型,因此无法从根本上解决问题。
NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了 NIO 框架,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。
NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。 NIO提供了与传统BIO模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发。
IO流是阻塞的,NIO流是不阻塞的。
Java NIO使我们可以进行非阻塞IO操作。比如说,单线程中从通道读取数据到buffer,同时可以继续做别的事情,当数据读取到buffer中后,线程再继续处理数据。写数据也是一样的。另外,非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。
Java IO的各种流是阻塞的。这意味着,当一个线程调用 read() 或 write() 时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了
IO 面向流(Stream oriented),而 NIO 面向缓冲区(Buffer oriented)。
Buffer是一个对象,它包含一些要写入或者要读出的数据。在NIO类库中加入Buffer对象,体现了新库与原I/O的一个重要区别。在面向流的I/O中·可以将数据直接写入或者将数据直接读到 Stream 对象中。虽然 Stream 中也有 Buffer 开头的扩展类,但只是流的包装类,还是从流读到缓冲区,而 NIO 却是直接读到 Buffer 中进行操作。
在NIO厍中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的; 在写入数据时,写入到缓冲区中。任何时候访问NIO中的数据,都是通过缓冲区进行操作。
最常用的缓冲区是 ByteBuffer,一个 ByteBuffer 提供了一组功能用于操作 byte 数组。除了ByteBuffer,还有其他的一些缓冲区,事实上,每一种Java基本类型(除了Boolean类型)都对应有一种缓冲区。
NIO 通过Channel(通道) 进行读写。
通道是双向的,可读也可写,而流的读写是单向的。无论读写,通道只能和Buffer交互。因为 Buffer,通道可以异步地读写。
NIO有选择器,而IO没有。
选择器用于使用单个线程处理多个通道。因此,它需要较少的线程来处理这些通道。线程之间的切换对于操作系统来说是昂贵的。 因此,为了提高系统效率选择器是有用的。
通常来说NIO中的所有IO都是从 Channel(通道) 开始的。
- 从通道进行数据读取 :创建一个缓冲区,然后请求通道读取数据。
- 从通道进行数据写入 :创建一个缓冲区,填充数据,并要求通道写入数据。
1 java.util.Stack 包括 push(), pop(), isEmpty()等
2 ArrayList动态数组: add(E e)、add(int index, E element)添加元素ArrayList 提供了 remove(int index)、remove(Object o)、removeRange(int fromIndex, int toIndex)、removeAll() 四个方法进行元素的删除。set(int index, E element):用指定的元素替代此列表中指定位置上的元素。ArrayList 提供了 get(int index)
以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为10。
int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍左右(oldCapacity为偶数就是1.5倍,否则是1.5倍左右)! 奇偶不同,比如 :10+10/2 = 15, 33+33/2=49。如果是奇数的话会丢掉小数.
需要线程安全可以用vector,或者或者copyonwiritlist(): 加锁后再复制一个新的array然后改变引用到这个新的上。
3 hashmap:
头尾插法:
先说扩容:1.7扩容,对原来的链表从第一个节点开始取,这里以a->b->c->null为例子,不管1.7,1.8取节点都是从头开始取往后遍历,这个是不会变的,那么1.7的操作是,取出a,做rehash,头插到新数组,这时新数组为a->null,接下来取b头插到新数组,假设abc都rehash后还是同样的index,那么变成b->a->null,取c变成c->b->a->null。
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度,n-1相当于一个mask),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
**所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。**JDK1.8之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)并且表长度大于默认64时时,将链表转化为红黑树,以减少搜索时间。
当put时,如果发现目前的bucket占用程度已经超过了Load Factor所希望的比例0.75,那么就会发生resize。在resize的过程,简单的说就是把bucket扩充为2倍,之后重新计算index,把节点再放到新的bucket中。resize的注释是这样描述的:当超过限制的时候会resize,然而又因为我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。例如我们从16扩展为32时,具体的变化如下所示:
因此元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:

因此,我们在扩充HashMap的时候,不需要重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648到2147483647,前后加起来大概40亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ (n - 1) & hash”。(n代表数组长度)。这也就解释了 HashMap 的长度为什么是2的幂次方。我们首先可能会想到采用%取余的操作来实现。但是,重点来了:“取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;)。” 并且 采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是2的幂次方。
cocurrenthashmap:
- 底层数据结构: JDK1.7的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
- 实现线程安全的方式(重要): ① 在JDK1.7的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;在JDK1.8之前,ConcurrentHashMap加的是分段锁,也就是Segment锁,每个Segment含有整个table的一部分,这样不同分段之间的并发操作就互不影响。JDK1.8对此做了进一步的改进,它取消了Segment字段,直接在table元素上加锁,实现对每一行进行加锁,进一步减小了并发冲突的概率② Hashtable(同一把锁) :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
4 hashmap 和hashtable和hashset
- 线程是否安全: HashMap 是非线程安全的,HashTable 是线程安全的;HashTable 内部的方法基本都经过
synchronized修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap 吧!); - 效率: 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
- 对Null key 和Null value的支持: HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛出 NullPointerException。
- 初始容量大小和每次扩充容量大小的不同 : ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小(HashMap 中的
tableSizeFor()方法保证,下面给出了源代码)。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。 - 底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 clone() 、writeObject()、readObject()是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。
当你把对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。
在很多应用场景中,读操作可能会远远大于写操作。由于读操作根本不会修改原有的数据,因此对于每次读取都进行加锁其实是一种资源浪费。我们应该允许多个线程同时访问 List 的内部数据,毕竟读取操作是安全的。这和 ReentrantReadWriteLock 读写锁的**非常类似,也就是读读共享、写写互斥、读写互斥、写读互斥。JDK 中提供了 CopyOnWriteArrayList 类比相比于在读写锁的**又更进一步。为了将读取的性能发挥到极致,CopyOnWriteArrayList 读取是完全不用加锁的,并且更厉害的是:写入也不会阻塞读取操作。只有写入和写入之间需要进行同步等待。这样一来,读操作的性能就会大幅度提升。
CopyOnWriteArrayList 类的所有可变操作(add,set 等等)都是通过创建底层数组的新副本来实现的。当 List 需要被修改的时候,我并不修改原有内容,而是对原有数据进行一次复制,将修改的内容写入副本。写完之后,再将修改完的副本替换原来的数据,这样就可以保证写操作不会影响读操作了。从 CopyOnWriteArrayList 的名字就能看出CopyOnWriteArrayList 是满足CopyOnWrite 的 ArrayList,所谓CopyOnWrite 也就是说:在计算机,如果你想要对一块内存进行修改时,我们不在原有内存块中进行写操作,而是将内存拷贝一份,在新的内存中进行写操作,写完之后呢,就将指向原来内存指针指向新的内存,原来的内存就可以被回收掉了。
CopyOnWriteArrayList 写入操作 add() 方法在添加集合的时候加了ReentrantLock,保证了同步,避免了多线程写的时候会 copy 出多个副本出来。
另外
Java 提供的线程安全的 Queue 可以分为阻塞队列和非阻塞队列,其中阻塞队列的典型例子是 BlockingQueue,非阻塞队列的典型例子是 ConcurrentLinkedQueue,在实际应用中要根据实际需要选用阻塞队列或者非阻塞队列。 **阻塞队列可以通过加锁来实现,非阻塞队列可以通过 CAS 操作实现。**从名字可以看出,ConcurrentLinkedQueue这个队列使用链表作为其数据结构.ConcurrentLinkedQueue 应该算是在高并发环境中性能最好的队列了。主要使用 CAS 非阻塞算法来实现线程安全就好了。
1.实现简单,增删节点不需要像b+树、b树一样调整结构
2.耗内存(分层结构导致重复存储节点)
3.支持范围查询
4.并发操作的局部性更小,而树形结构的插入删除可能涉及整棵树的其他部分

树的层次遍历:
import java.util.LinkedList;
public class LevelOrder
{
public void levelIterator(BiTree root)
{
if(root == null)
{
return ;
}
LinkedList<BiTree> queue = new LinkedList<BiTree>();
BiTree current = null;
queue.offer(root);//将根节点入队
while(!queue.isEmpty())
{
current = queue.poll();//出队队头元素并访问
System.out.print(current.val +"-->");
if(current.left != null)//如果当前节点的左节点不为空入队
{
queue.offer(current.left);
}
if(current.right != null)//如果当前节点的右节点不为空,把右节点入队
{
queue.offer(current.right);
}
}
}
}
sibing tree:
class SibTreeNode { | class SibTree {
Object item; | SibTreeNode root;
SibTreeNode parent; | int size;
SibTreeNode firstChild; | }
SibTreeNode nextSibling; |
} |完全二叉树:若设二叉树的深度为k,除第k层外,其他各层(1~(k-1)层)的节点数都达到最大值,且第k层所有的节点都连续集中在最左边,这样的树就是完全二叉树。
二叉搜索树左子树一定小于根,右子树一定大于根。对一个二叉搜索树直接进行中序遍历,立马可以得到节点的前驱和后继节点,但是这样的方法时间复杂度为O(N)
若一个节点有左子树,那么该节点的前驱节点是其左子树中val值最大的节点(也就是左子树中所谓的rightMostNode)。若一个节点没有左子树,那么判断该节点和其父节点的关系 ,若该节点是其父节点的右边孩子,那么该节点的前驱结点即为其父节点。 若该节点是其父节点的左边孩子,那么需要沿着其父亲节点一直向树的顶端寻找,直到找到一个节点P,P节点是其父节点Q的右边孩子),那么Q就是该节点的后继节点。
若一个节点有右子树,那么该节点的后继节点是其右子树中val值最小的节点(也就是右子树中所谓的leftMostNode)。若一个节点没有右子树,那么判断该节点和其父节点的关系,若该节点是其父节点的左边孩子,那么该节点的后继结点即为其父节点,若该节点是其父节点的右边孩子,那么需要沿着其父亲节点一直向树的顶端寻找,直到找到一个节点P,P节点是其父节点Q的左边孩子,那么Q就是该节点的后继节点。
BST的插入过程非常简单,很类似与二叉树搜索树的查找过程。当需要插入一个新结点时,从根节点开始,迭代或者递归向下移动,直到遇到一个空的指针NIL,需要插入的值即被存储在该结点位置。
结点的删除可归结为三种情况: 如果结点z没有孩子节点,那么只需简单地将其删除,并修改父节点,用NIL来替换z;

如果结点z只有一个孩子,那么将这个孩子节点提升到z的位置,并修改z的父节点,用z的孩子替换z;
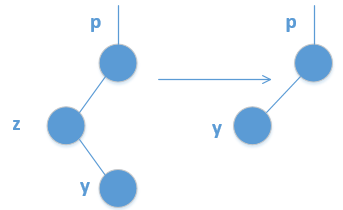
如果结点z有2个孩子,那么查找z的后继y,此外后继一定在z的右子树中,然后让y替换z。
每个节点最多有四个字节点和三个数据项,名字中 2,3,4 的数字含义是指一个节点可能含有的子节点的个数。非叶节点的子节点数总是比它含有的数据项多1。find(), insert(), and remove() operations are in O(h) and hence in O(log n) (h is in O(log n)).
插入操作中,如果没遇到3-key节点就按顺序插入,如果遇到3-key节点将其中间key弹出到上一层,即弹入parent中,将原本的节点进行分裂,如上图树插入60后变为:
删除操作中,删除的数如果是leaf,可以直接删除。如果是内部节点,就find后继与他替换,替换后删除要删除的数。
删除上图40节点(这里用XX表示),即寻找比40大的那个数删除。在find的过程中,对于50节点,If the parent is the root and contains only one key, and the sibling contains only one key, then the current 1-key node, its 1-key sibling, and the 1-key root are fused into one 3-key node that serves as the new root. The height of the tree decreases by one.
接下来对于43,这种1-key节点,向邻居借key旋转:
接下来对于42,没有临近节点超过1-key,就借parent一个key:
Finally, remove 42 from the leaf and replace "xx" with 42.
应用如下三条规则可以将2-3-4树转化为红黑树:一、把2-3-4树中的每个2-节点转化为红-黑树的黑色节点。二、把每个3-节点转化为一个子节点和一个父节点,子节点有两个自己的子节点:W和X或X和Y。父节点有另一个子节点:Y或W。哪个节点变成子节点或父节点都无所谓。子节点涂成红色,父节点涂成黑色。三、把每个4-节点转化为一个父节点和两个子节点。第一个子节点有它自己的子节点W和X;第二个子节点拥有子节点Y和Z。和前面一样,子节点涂成红色,父节点涂成黑色。
Splay Tree 也是一种二叉查找树,满足二叉查找树的性质。但是它可以通过splay伸展操作(一系列的旋转)维持平衡。
Splay方法如下:
基本rotation:
X is the right child of a left child (or the left child of a right child):
X is the left child of a left child (or the right child of a right child):
X’s parent P is the root: 前两种情况重复运行总会使X到达root或者第三那种情况。
对于基础操作:
Entry find(Object k)操作在找到节点X后(或者停在节点X)splay X让X成为root。理由是便于以后find()以及维持balanced。
Entry min/max() 找到后 splay至root。
Entry insert() 的新节点splay至root。
Entry remove() 首先,用在二叉查找树中查找元素的方法找到x的位置。如果x没有孩子或只有一个孩子,那么直接将x删去,并通过Splay操作,将x节点的父节点调整到伸展树的根节点处。否则,则向下查找x的后继y,用y替代x的位置,最后执行Splay(y,S),将y调整为伸展树的根:
如没有找到要remove的节点,splay最后find的位置。
Entry join() 将两个伸展树S1与S2合并成为一个伸展树。其中S1的所有元素都小于S2的所有元素。首先,我们找到伸展树S1 中最大的一个元素x,再通过Splay(x,S1)将x 调整到伸展树S1 的根。然后再将S2 作为x 节点的右子树。这样,就得到了新的伸展树S。
Entry split() 以x 为界,将伸展树S 分离为两棵伸展树S1 和S2,其中S1中所有元素都小于x,S2中的所有元素都大于x。首先执行Find(x,S),将元素x 调整为伸展树的根节点,则x 的左子树就是S1,而右子树为S2。
红黑树也是平衡二叉树:1.节点是红色或黑色。 2.根节点是黑色。 3.每个叶子节点都是黑色的空节点(NIL节点)。 4. 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点) 5. 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
插入:
插入结点I为红色,除了情景2,所有插入操作都是在叶子结点进行的
1 树为空:把插入结点作为根结点,并把结点设置为黑色。
2 插入结点的Key已存在,value不存在:更新当前结点的值为插入结点的值
3 插入结点的父结点为黑结点:直接插入
4 插入结点的父结点为红结点:
4.1 叔叔结点存在并且为红结点:将P和S设置为黑色-将PP设置为红色-把PP设置为当前插入结点。
这里如果PP的父结点是黑色,那么无需再做任何处理;但如果PP的父结点是红色,根据性质4,此时红黑树已不平衡了,所以还需要把PP当作新的插入结点,继续做插入操作自平衡处理,直到平衡为止。如果PP刚好为根结点时,那么根据性质2,我们必须把PP重新设为黑色。
4.2 叔叔结点不存在或为黑结点,并且插入结点的父亲结点是祖父结点的左子结点:
4.3 叔叔结点不存在或为黑结点,并且插入结点的父亲结点是祖父结点的右子结点:
删除:
红黑树的删除操作包括两部分工作:一查找目标结点;而删除后自平衡。查找目标结点可以复用查找操作,当不存在目标结点时,忽略本次操作;当存在目标结点时,删除后做自平衡处理。
二叉搜索树删除原理在这里依旧适用:
若删除结点无子结点,直接删除 若删除结点只有一个子结点,用子结点替换删除结点 若删除结点有两个子结点,用后继结点(大于删除结点的最小结点)替换删除结点(由于任意一个节点的前驱或者后继都必定至多只有一个非空子节点,因而删除这样的节点就可以按照前两种情形进行处理)
删除后需要自平衡:
1 如果当前待删除节点是红色的,它被删除之后对当前树的特性不会造成任何破坏影响。把替换节点的颜色变为删除结点的颜色
2 而如果被删除的节点是黑色的,这就需要进行进一步的调整来保证后续的树结构满足要求。
2.1 替换结点R(其实是和原本的R交换后的I,将需要被删除的节点)是其父结点的左子结点:
替换结点的兄弟结点是红结点
替换结点的兄弟结点是黑结点,替换结点的兄弟结点的右子结点是红结点,左子结点任意颜色
替换结点的兄弟结点是黑结点,替换结点的兄弟结点的右子结点为黑结点,左子结点为红结点
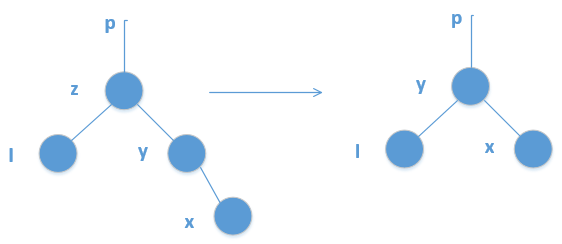
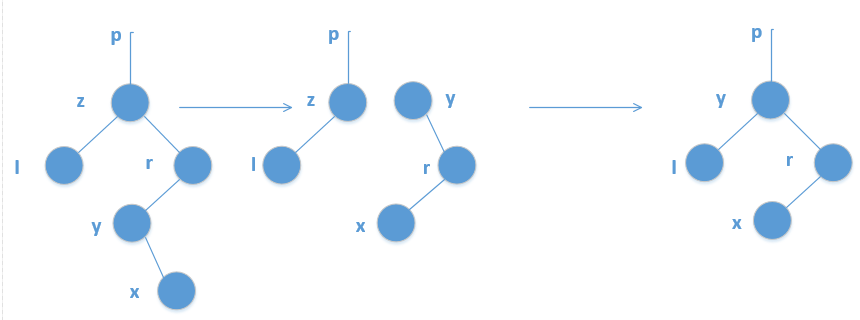
替换结点的兄弟结点是黑结点,替换结点的兄弟结点的子结点都为黑结点(下图意思为用P和R交换然后P作为R判断自平衡情况来向上迭代,如果遇到红色节点就将其设为黑色,否则向上迭代)
之所以把S设为红色,是因为R会被删除,S设为红色可以保证R被删除后P为root的这颗小树可以平衡,但是R删除后,R的路线会导致整体的大树还是不平衡,所以需要向上跌倒寻找全局平衡的方法。
- 平衡二叉树节点最多有两个子树,而 B 树每个节点可以有多个子树,M 阶 B 树表示该树每个节点最多有 M 个子树
- 平衡二叉树每个节点只有一个数据和两个指向孩子的指针,而 B 树每个中间节点有 k-1 个关键字(可以理解为数据)和 k 个子树( **k 介于阶数 M 和 M/2 之间,M/2 向上取整)
- B 树的所有叶子节点都在同一层,并且叶子节点只有关键字,指向孩子的指针为 null
B 树的节点数据大小也是按照左小右大,子树与节点的大小比较决定了子树指针所处位置。
- 若根结点不是终端结点,则至少有2棵子树
- 除根节点以外的所有非叶结点至少有 M/2 棵子树,至多有 M 个子树(关键字数为子树减一)
- 所有的叶子结点都位于同一层
b+:
-
节点的子树数和关键字数相同(B 树是关键字数比子树数少一)
-
节点的关键字表示的是子树中的最大数,在子树中同样含有这个数据
-
叶子节点包含了全部数据,同时符合左小右大的顺序,叶子节点用指针连在一起
-
层级更低,IO 次数更少
-
每次都需要查询到叶子节点,查询性能稳定
-
叶子节点形成有序链表,范围查询方便

- 根节点不包含字符,除根节点外每一个节点都只包含一个字符
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串
- 每个节点的所有子节点包含的字符都不相同
1 Kruskal’s Algorithm for Finding Mimumum Spanning Trees
G = (V, E) 是无向图. A spanning_tree T = (V, F) of G 是包含了和G相同的V个顶点的图, 但是只有V-1条边。a minimum_spanning_tree T就是所有边加起来最小的那棵树(挑选一棵树,而不是一个森林),具体如下:
[1] Create a new graph T with the same vertices as G, but no edges (yet). [2] Make a list of all the edges in G. [3] Sort the edges by weight, from least to greatest. [4] Iterate through the edges in sorted order. For each edge (u, w): If u and w are not connected by a path in T, add (u, w) to T.
2 Dijkstra算法
- 初始时,S只包含起点s;U包含除s外的其他顶点,且U中顶点的距离为”起点s到该顶点的距离”[例如,U中顶点v的距离为(s,v)的长度,然后s和v不相邻,则v的距离为∞]。
- 从U中选出”距离最短的顶点k”,并将顶点k加入到S中;同时,从U中移除顶点k。
- 更新U中各个顶点到起点s的距离。之所以更新U中顶点的距离,是由于上一步中确定了k是求出最短路径的顶点,从而可以利用k来更新其它顶点的距离;例如,(s,v)的距离可能大于(s,k)+(k,v)的距离。
- 重复步骤(2)和(3),直到遍历完所有顶点。
从U中选出”距离最短的顶点k”这个过程可用最小堆优化成logn
选择排序、快速排序、希尔排序、堆排序不是稳定的排序算法,而冒泡排序、插入排序、归并排序和基数排序(不是比较排序,性能有时更优)是稳定的排序算法,在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
Insertion sort is very simple and runs in O(n^2) time. We employ a list S, and maintain the invariant that S is sorted. If S is a linked list, then it takes Theta(n) worst-case time to find the right position to insert each item. If S is an array, we can find the right position in O(log n) time by binary search, but it takes Theta(n) worst-case time to shift the larger items over to make room for the new item.
Start with an empty list S and the unsorted list I of n input items.
for (each item x in I) {
insert x into the list S, positioned so that S remains in sorted order.
}
O(n^2) time
Start with an empty list S and the unsorted list I of n input items.
for (i = 0; i < n; i++) {
Let x be the item in I having smallest key.
Remove x from I.
Append x to the end of S.
}
Heapsort is a selection sort in which I is a heap. 堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆
Start with an empty list S and an unsorted list I of n input items.
toss all the items in I onto a heap h (ignoring the heap-order property).
h.bottomUpHeap(); // Enforces the heap-order property
for (i = 0; i < n; i++) {
x = h.removeMin();
Append x to the end of S.
}
3和5交换,将3去除后bottomup->5和7交换后将5去除掉,然后bottomup,以此类推。
Heapsort is O(nlogn)-time for sorting arrays, and Mergesort can sort linked lists in O(nlogn)-time.
希尔排序是将待排序的数组元素 按下标的一定增量分组 ,分成多个子序列,然后对各个子序列进行直接插入排序算法排序;然后依次缩减增量再进行排序,直到增量为1时,进行最后一次直接插入排序,排序结束。
希尔排序耗时的操作有:比较 + 后移赋值。
时间复杂度情况如下:(n指待排序序列长度) **1) 最好情况:**序列是正序排列,在这种情况下,需要进行的比较操作需(n-1)次。后移赋值操作为0次。即O(n) **2) 最坏情况:**O(nlog2n)。 **3) 渐进时间复杂度(平均时间复杂度):**O(nlog2n)
Let Q1 and Q2 be two sorted queues. Let Q be an empty queue.
while (neither Q1 nor Q2 is empty) {
item1 = Q1.front(); ## front即最小或者做大的数
item2 = Q2.front();
move the smaller of item1 and item2 from its present queue to end of Q.
}
concatenate the remaining non-empty queue (Q1 or Q2) to the end of Q.
从下向上排序: Each level involves O(n) operations, and there are O(log n) levels. O(n log n) time in all.
O(nlogn)
Start with the unsorted list I of n input items.
Choose a pivot item v from I.
Partition I into two unsorted lists I1 and I2.
- I1 contains all items whose keys are smaller than v’s key.
- I2 contains all items whose keys are larger than v’s.
- Items with the same key as v can go into either list or go with v as a Iv list.
- The pivot v, however, does not go into either list.
Sort I1 recursively, yielding the sorted list S1.
Sort I2 recursively, yielding the sorted list S2.
Concatenate S1, v, and S2 together, yielding a sorted list S.
下图中间非常不平衡,会耗费O(n^2), 左图完美平衡。
如上图右边所示,对于a[low] - a[high]的数组的实践中:
首先随机挑选一个pivot v, 将其与a[high]交换。
然后初始化 i 和 j, i is initially "low - 1", and j is initially "high", 让它们能夹住数组。
然后我们规定要完成:i和i左边 ≤ v,i和i右边≥ v;
(1)让i和j向中间走,遇到不符合上述规定时停下来,交换i和j的代表的item,然后继续走知道i和j相遇,最后将v和i的item交换。
(2)之后对v左右的两个array再重复(1)的操作
(3)将最终结果拼接(或许不用)得到排序后的数组
public static void quicksort(Comparable[] a, int low, int high) {
// If there’s fewer than two items, do nothing.
if (low < high) {
int pivotIndex = random number from low to high;
Comparable pivot = a[pivotIndex];
a[pivotIndex] = a[high]; // Swap pivot with last item
a[high] = pivot;
int i = low - 1;
int j = high;
do {
do { i++; } while (a[i].compareTo(pivot) < 0);
do { j--; } while ((a[j].compareTo(pivot) > 0) && (j > low));
if (i < j) {
swap a[i] and a[j];
}
} while (i < j);
a[high] = a[i];
a[i] = pivot; // Put pivot in the middle where it belongs
quicksort(a, low, i - 1); // Recursively sort left list
quicksort(a, i + 1, high); // Recursively sort right list
}
}for (i = 0; i < x.length; i++) {
counts[x[i].key]++;
}
/* 把所有小于这个key的数的数量累加就是这个key应该在的position,所以count数组的idex即为等待排序的key,count数组的值就是等待排序的key的位置。*/
total = 0;
for (j = 0; j < counts.length; j++) {
c = counts[j];
counts[j] = total;
total = total + c;
}for (i = 0; i < x.length; i++) {
y[counts[x[i].key]] = x[i];
counts[x[i].key]++;
} // 这里++是因为count中记录的index是初始index,如果是多个key,应该用++逐个后移并查集是一种树结构,用数组存放。每个数组的值存放的是它的parent。如果为根,存放的是这个树的size的负值。
假设0-9,首先将数组全部初始化为-1,相当于每个数都是一颗树:
对于左图三棵树,相应地就由右图表示:
合并两棵树:
public void union(int root1, int root2) {
if (array[root2] < array[root1]) { // root2 has larger tree
array[root2] += array[root1]; // update # of items in root2’s tree
array[root1] = root2; // make root2 parent of root1
} else { // root1 has equal or larger tree
array[root1] += array[root2]; // update # of items in root1’s tree
array[root2] = root1; // make root1 parent of root2
}
}find(): find(x)用于查找x所在的树的root,并将途径的所有叶子节点和内部节点直接设为root的child,方便下一次查找。
public int find(int x) {
if (array[x] < 0) {
return x; // x is the root of the tree; return it
} else { // Find out who the root is; compress path by making the root x’s parent
array[x] = find(array[x]);
return array[x]; // Return the root
}
}Here’s the quickselect algorithm for finding the item at index j in a sorted array - that is, having the (j + 1)th smallest key.
Start with an unsorted list I of n input items.
Choose a pivot item v from I.
Partition I into three unsorted lists I1, Iv, and I2.
- I1 contains all items whose keys are smaller than v’s key.
- I2 contains all items whose keys are larger than v’s.
- Iv contains the pivot v.
- Items with the same key as v can go into any of the three lists.
(In list-based quickselect, they go into Iv; in array-based quickselect,
they go into I1 and I2, just like in array-based quicksort.)
if (j < |I1|) {
Recursively find the item with index j in I1; return it.
} else if (j < |I1| + |Iv|) {
Return the pivot v.
} else { // j >= |I1| + |Iv|.
Recursively find the item with index j - |I1| - |Iv| in I2; return it.
}
在二维平面上的n个点中,找出最接近的一对点:
已知集合S中有n个点,使用分治法的**就是将S进行拆分,分为2部分求最近点对。算法每次选择一条垂线L,将S拆分左右两部分为SL和SR,( L一般取点集S中所有点的中间点的x坐标来划分,这样可以保证SL和SR中的点数目各为n/2 否则以其他方式划分S,有可能导致SL和SR中点数目一个为1,一个为n-1,不利于算法效率,要尽量保持树的平衡性 )
递归进行,找出两部分距离最近的点:
对于横跨两个部分的点,肯定都处于红线内区域,并且对于每一个单独的点,与它相连的点也肯定处于灰色区域:
如果灰色区域的某个位置有点,画一个半径为$\sigma$的圆与灰色相交的部分必然没有点(如果有的话距离就小于之前得到的最小的距离了,所以不可能有点)所以灰色块内只会有很少的几个点(不超过6),计算起来时间复杂度为O(1)
实践中自上而下选点,选点后只需关注对面的下半部分即可,上半部分对面选点时会关注。
实践中分别根据点对应的xy轴坐标值排序,并用指针相连,这样可以快速找到并且标记对方:
所以总的时间复杂度为
从S中选第k小的数 Select(S; k) :
1 把S划分成size为5的子集
2 找到这些子集的中间点,放到集合B中
3 m := Select(B; S/10)
4 扫描S,小于m的放在S1,大于放在S2
如果S1大于等于k,return Select(S1; k).
如果S1等于k-1,return m
如果S1小于k-1Return Select(S2; k - S1 - 1).
至少1/4小于m,1/4大于m,所以S1S2最多为3n/4大小:
T(n) = T(n/5) + T(3n/4) + O(n)
在海量数据中找出出现频率最好的前k个数:通常比较好的方案是分治+Trie树/hash+小顶堆(就是上面提到的最小堆),即先将数据集按照Hash方法分解成多个小数据集,然后使用Trie树或者Hash统计每个小数据集中的query词频,之后用小顶堆求出每个数据集中出现频率最高的前K个数,最后在所有top K中求出最终的top K。
top K问题很适合采用MapReduce框架解决,用户只需编写一个Map函数和两个Reduce 函数,然后提交到Hadoop(采用Mapchain和Reducechain)上即可解决该问题。具体而言,就是首先根据数据值或者把数据hash(MD5)后的值按照范围划分到不同的机器上,最好可以让数据划分后一次读入内存,这样不同的机器负责处理不同的数值范围,实际上就是Map。得到结果后,各个机器只需拿出各自出现次数最多的前N个数据,然后汇总,选出所有的数据中出现次数最多的前N个数据,这实际上就是Reduce过程。对于Map函数,采用Hash算法,将Hash值相同的数据交给同一个Reduce task;对于第一个Reduce函数,采用HashMap统计出每个词出现的频率,对于第二个Reduce 函数,统计所有Reduce task,输出数据中的top K即可。
去除重复数据采用bitmap方法也可以