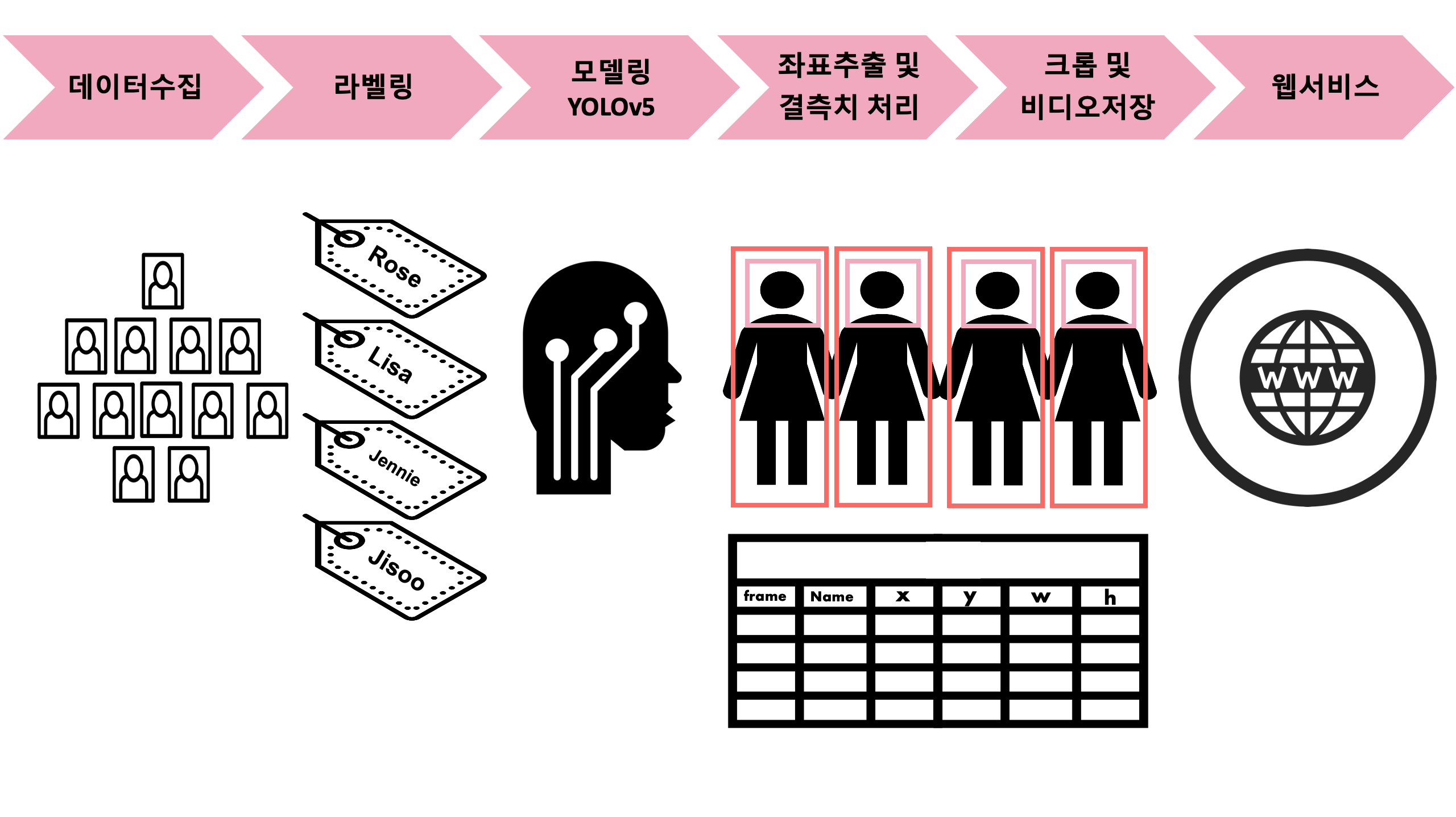
- 각 멤버에 대한 얼굴을 인식하기 위해서는 멤버의 사진이 필요
- HOW? Selenium → /data-collecting/capture.py
- 처음에는 "스테이시" 여자아이돌 그룹으로 셀레니엄을 사용해 이미지 크롤링하여 데이터를 수집.
- 그러나 신입 그룹이라 데이터의 양이 너무 적었으며 멤버간 얼굴 특징이 뚜렷하지 않아 예측률을 높이는 데 한계
- 그룹을 "블랙핑크"로 변경.
- 셀레니엄으로 크롤링한 사진에는 화보, 기사사진, 광고사진, 무대사진 등 다양한 사진이 존재.
- 예측할 영상과 가장 유사한 데이터를 사용해야 좋을 결과가 나오리라 판단.
- 무대 직캠 영상을 15프레임마다 캡처해 이미지 데이터를 수집. (capture.py)
if(int(vidcap.get(1)) % 15 == 0):
cv2.imwrite("save image path" % count, image)
- 멤버 라벨링 : 로제(0), 리사(1), 제니(2), 지수(3)
- HOW? Labelimg-master


⚙️ 1차 라벨링
- 얼굴이 확실하게 구분 가능한 경우에만 라벨링
- 동선/옷차림 등의 조건을 고려하지 않고도 구분 가능한 경우
- 머리카락으로 얼굴이 가려져있거나 뒤돌아 있는 경우에는 라벨링 제외
- 라벨링 사이즈: 헤어스타일이 나오게 라벨링(두상 ~ 어깨 선 정도까지)
- 낮은 화질(360p)의 데이터도 구비
- 총 2160장
⚙️ 2차 라벨링
- 라벨링 사이즈: 얼굴 딱 맞는 사이즈
- 눈코입이 보이는 옆모습 포함하기 (다양한 각도의 얼굴이 있으면 좋다.)
- 화질이 낮은 데이터(360p)를 포함하여 학습 시 성능이 낮아 질수도 있을거라는 멘토님의 의견을 수렴하여 360p 데이터는 제외하고 1080p 데이터만 학습
- 총 1316장
- 기존 연구들과 다르게 '속도' 중심. 빠르다!
- 기존 연구들이 '정확도'를 중요하게 생각했으나, 실시간 반영 문제가 발생하여 이를 극복하고자 함
- You Only Look Once
- Multi-task 문제를 하나의 회귀 문제로 재정의
- 이미지 전체에 대해서 '하나의 신경망'이 '한번의 계산'으로 'bounding box', 'class probabilty' 예측
- bounding box: object detection 대상에 빨간 박스
- class probability: 분류 및 예측하고자하는 대상의 종류와 확률
- 이미지 전체에 대해서 '하나의 신경망'이 '한번의 계산'으로 'bounding box', 'class probabilty' 예측
- 기존 방식들보다 background error가 적다.
- 기존 'Sliding Window', 'Region proposal' 방식과 다르게, 훈련과 테스트 단계에서 이미지 전체를 인식.
- 기존 방식의 단점: Background Error(아무 물체가 없는 배경에 반점, 노이즈 등이 있으면 물체로 인식)
- 물체의 일반적인 부분을 학습하기에 다른 모델에 비해 보지 못한 새로운 이미지에 대해 더 robust함
- 단점
- 다른 모델들에 비해 정확도가 떨어진다.


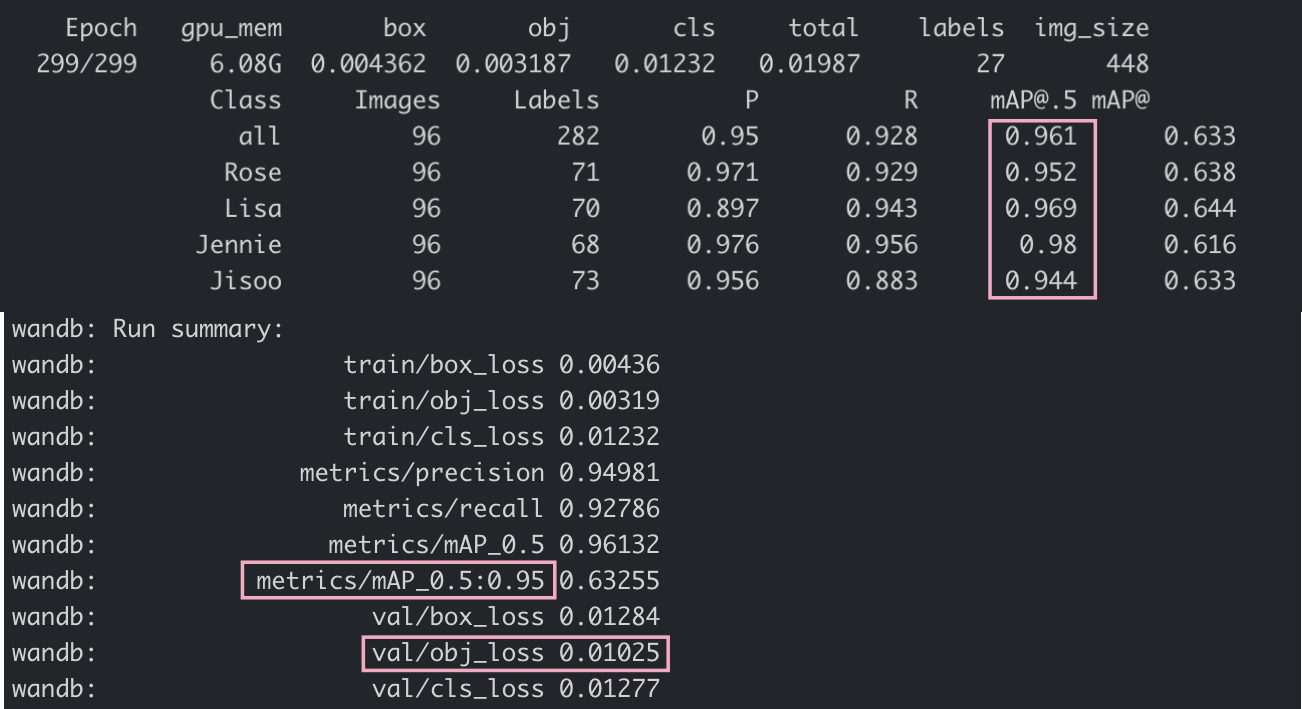
| Model | size (pixels) | mAPval 0.5:0.95 | mAPtest 0.5:0.95 | mAPval 0.5 | Speed V100 (ms) | params (M) | FLOPS 640 (B) | |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s6 | 1280 | 43.3 | 43.3 | 61.9 | 4.3 | 12.7 | 17.4 | |
| YOLOv5m6 | 1280 | 50.5 | 50.5 | 68.7 | 8.4 | 35.9 | 52.4 | |
| YOLOv5l6 | 1280 | 53.4 | 53.4 | 71.1 | 12.3 | 77.2 | 117.7 | |
| YOLOv5x6 | 1280 | 54.4 | 54.4 | 72.0 | 22.4 | 141.8 | 222.9 | |
| YOLOv5x6 TTA | 1280 | 55.0 | 55.0 | 72.0 | 70.8 | - | - |


- Layer
- 24 Convolution layers: 이미지 특징 추출
- 2 Fully-connected layers: 클래스 확률, bounding box 좌표 예측
- '1 x 1 reduction layer' + '3 x 3 convolution layer' GoogLeNet의 네트워크에서 인셉션 구조 대신 사용
- 최종 output(prediction tensors): 7 x 7 x 30
-
Convolution/Fully-connected layer
- ImageNet 데이터셋으로 YOLO 앞단의 20개 Convolution layer를 사전 훈련
- 사전 훈련된 20개의 Convolution layer 뒤에 4개의 Convolution layer 및 2개의 Fully-connected layer를 추가
-
Activation function
- 모든 계층에 leaky ReLU
- 마지막 계층: linear activation function
-
학습시 보완점
- confidence score=0, imbalance issue
- 이미지 전체를 보고 판단하는 방식이라, 대부분의 그리드 셀 내에는 객체가 없다.
- 이를 보완하기 위해서, 객체가 존재하지 않는 bounding box의 confidence loss에 대한 가중치 감소
- localization loss, classification loss의 가중치 조절
- localization loss 가중치 증가
- 객체가 없는 그리드 셀의 confidence loss보다 객체가 존재하는 그리드 셀의 confidence loss 가중치 증가
- bounding box size issue
- 물체의 크기에 따라 bounding box size가 다르게 계산됨
- 작은 bounding box는 큰 박스에 비해서 위치 변화에 민감
- scaling 으로 해결
- bounding box에 Square root 취해주기
- 높이와 너비가 커짐에 따라 그 증가율이 감소해 loss에 대한 가중치를 감소시키는 효과가 있다.
- confidence score=0, imbalance issue
- 작은 객체들이 몰려있는 경우 검출이 잘 안된다.
- 훈련단계에서 학습하지 못한 박스의 종횡비(aspect ratio)는 잘 예측 안된다.

-
한계점 및 주의사항
- 사람의 얼굴이 뭉개지는 등의 문제로 인식 자체가 안되는 경우가 있다.
- 연예인들의 공연영상마다 의상이 달라서 전체 사이즈(사람 크기)로 학습이 어렵다.
- 포지션 등의 보완 방법이 있으나, 이는 이미 무대를 알고 있어야 한다는 한계점이 있다.
-
학습 시 한계 및 팁
- image agumentation이 큰 효과를 보지 못했다.
- low quality
- blur..
- 보다 고화질의 얼굴 이미지가 학습이 더 잘되었다.
- image agumentation이 큰 효과를 보지 못했다.
-
예측 시 한계 및 팁
- input image size = predict image size 맞춰준다.
- threshold 값을 조절해서 backgound 인식을 낮춰줄 필요가 있다.
- /modeling/detect.py
- YOLOv5모델은 프레임마다 라벨링의 좌표를 각각의 txt파일로 저장
- csv파일로 저장하기 위해 detect.py 파일 내 txt파일로 저장하는 부분인 --save-txt부분을 변경
- 각각의 txt파일을 하나의 csv파일로 저장
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(save_path+'loc_test.csv','a') as f:
csvWriter = csv.writer(f)
csvWriter.writerow([frame, int(cls), xywh[0], xywh[1], xywh[2], xywh[3]])
- /video-crop/blackpick_csv_seperate.ipynb
- 결측치가 존재.
- 뒤돌아 있거나 옆모습
- 다른 멤버한테 겹쳐 가려지는 경우
- 앞 뒤 프레임 중간에 값이 빠져 있는 경우

- 선형증가로 null값 채우고 이동평균값 구해서 튀는값 줄이기 : moving_avg_frame 함수
#선형 증가값 적용
for k in range(zero_len):
df.iloc[idx+k, 2] = x[0] + div_val_x*(k+1)
df.iloc[idx+k, 3] = y[0] + div_val_y*(k+1)
df.iloc[idx+k, 4] = w[0] + div_val_w*(k+1)
df.iloc[idx+k, 5] = h[0] + div_val_h*(k+1)
- /video-crop/blackpink_videocrop.ipynb
- 각각의 멤버의 좌표값이 저장된 csv파일을 통해 가로200 * 세로630 사이즈의 크롭된 사진(이미지)를 생성.
- VideoWriter의 writer 메소드를 사용해 각각의 사진(이미지)을 mp4동영상(비디오)으로 출력.
final_w = 200 # output video width
final_h = 630 # output video height
fourcc = cv2.VideoWriter_fourcc(*'DIVX')
output_video = cv2.VideoWriter("output.mp4", fourcc, fps, (final_w,final_h))
success, frame = input_video.read()
count = 0
while success:
mem = df.iloc[count]
x = int(np.ceil(mem[2] * width)) - 80
y = int(np.ceil(mem[3] * height)) - 70
- 원인 : 좌표에서 목표 범위 만큼 더하고 뺄 경우 기존 영상의 범위를 나가는 경우가 발생하여 writer 메소드 실행시 불포함하고 영상으로 저장
- 해결 : 좌표 + 목표 영상크기가 범위 밖일 경우 영상 범위에서 목표크기로 추출할 수 있는 가장 끝값으로 출력하는 알고리즘 추가
if x + final_w > width:
x = width - 1 - final_w
if y + final_h >= height:
y = height - 1 - final_h
├── app
│ ├── library
│ │ └── helpers.py
│ ├── pages
│ │ ├── home.md
│ │ ├── profile.md
│ │ └── readme.md
│ └── preprocessing.py
├── static
│ ├── css
│ ├── images
│ ├── js
│ └── videos
└── templates
├── include
├── base.html
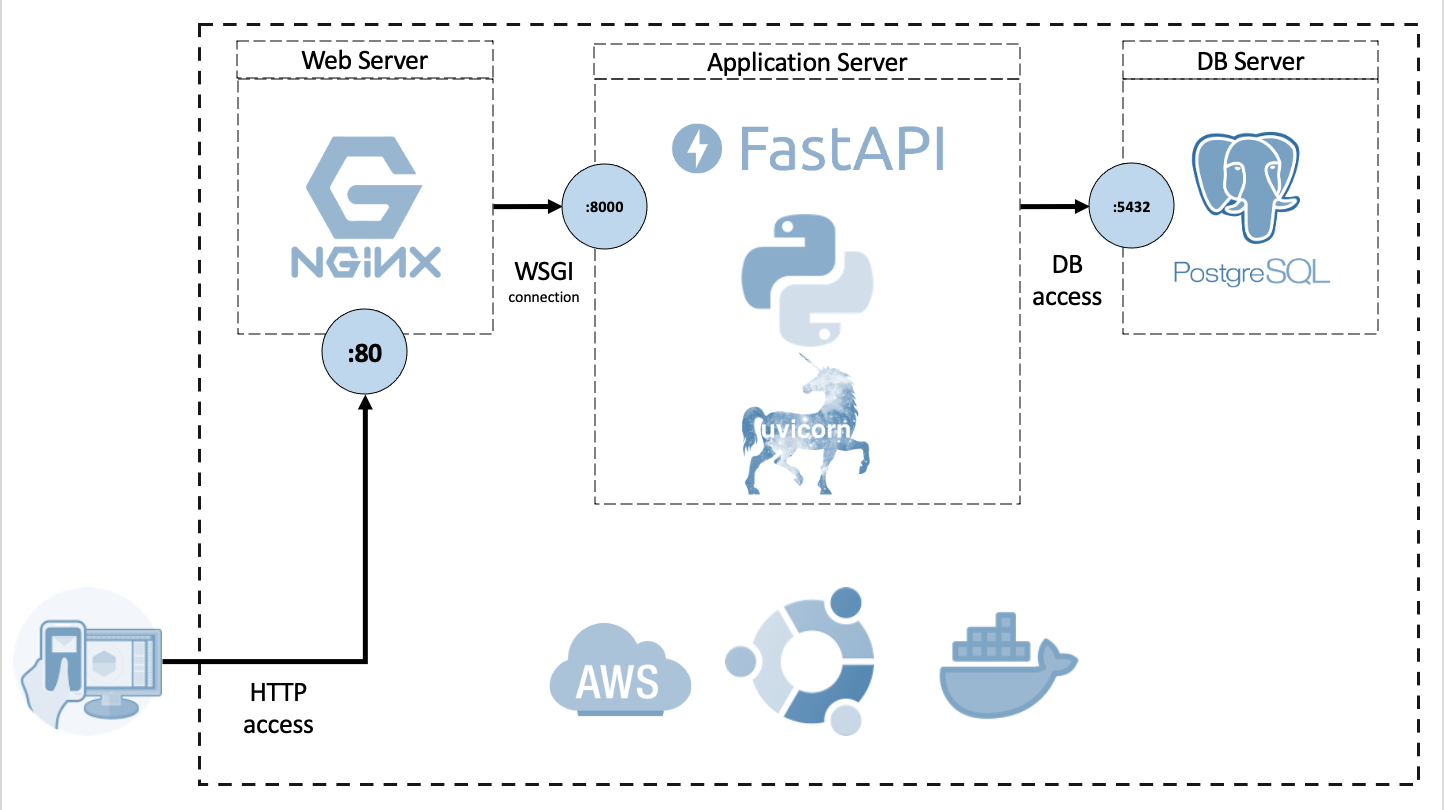
└── page.html- 파이썬 웹 프레임 워크
- 빠름. 빠른코드작성. 적은버그. 직관적. 쉬움. 짧음.
✔️ 방법1. 프론트적으로 구현하여 서비스 제공

if (videos.b.media.readyState === 4) {
videos.b.currentTime(
videos.a.currentTime()
);
}
requestAnimationFrame(sync);
}
[] 방법2. OpenCV, csv를 로드하여 서비스 제공
[] 방법3. 웹 소켓으로 서비스 제공
[] 방법4. YOLOv5 모델을 태워 서비스 제공
- 브라우저 별 코덱 필요 : H.264 변환
- 버튼 onClick 이벤트 후 비디오 로드되어 파일의 크기에 따라 로딩 속도 달라
- 동영상 파일의 크기 vs 영상의 화질
- 영상의 화질도 좋으면서 빠르게 로드할수 있는 방법
- 모델을 태워 결과를 보여주는 갤러리 기능 추가
- 이미지로 갤러리가 가능하면 동영상도 도전
- 팬들의 참여를 통해 데이터 수집 및 라벨링 기능 구현
- 채팅 기능 추가
- 딥러닝 프로젝트의 범위를 미리 정하지 않으면 min-max의 범위가 넒어짐.
- 라벨링 시 실제 성능 향상을 위해서 타겟 레이블 별 최소 1500장의 사진이 필요했으나 무대 영상이 적고, 학습 시 충족시킬 좋은 화질 데이터 구하는데 한계
- 영상처리할때 컴퓨팅 파워에 의존적인 부분이 있어서 많은 시도를 하기엔 한계.
- 데이터 변경, 다양한 모델링 학습 및 추론, 모델의 하이퍼파라미터 변경 등 성능에 영향을 미치는 변수는 많으나 프로젝트 기간 내 확인할 수 없어 아쉬움. 각 단계별 성능 향상을 위한 경험론적 노하우 필요.
- 영상에서 각 프레임별 예측을 진행하는 것이라 정확도가 95%여도 체감상 오류가 몇번 나오면 유저가 느끼는 신뢰도가 급격히 하락함.