Background

Due to the ill-defined nature of term data science, there are several different flavors of data science jobs such as data scientist, machine learning engineer, and data analyst. All three of these types of jobs overlap substantially, but utilize different tools and may attract different kinds of people.
- Main question of interest: Can these flavors of data scientist jobs be depicted from their descriptions?
- Using clustering algorithms and natural language processing, this question can be addressed
The Data:
Using selenium and beautiful soup, two popular python packages for web scraping and web automation, 3150 jobs were scraped from Linkedin.com. The search looked at jobs that resulted from looking up 'Data Science' and searched 6 states: CA, CO, FL, NY, and UT. This search term yielded the largest number of jobs from the search terms tested. Here is an example row of the data:
| Job_Title | Company | Location | Number_of_Applicants | Description |
|---|---|---|---|---|
| Data Acquisition Developer | ABB | Broomfield, CO, US | Be among the first 25 applicants | Join ABB and work in a team that is dedicated ... |
Data cleaning pipeline:

-
Words that should not help differentiate the jobs from each other were identified (e.g. equal, disability)
- These were words that were included in just about every job
-
Cleaning descriptions
- Remove punctuation using NLTK's RegexpTokenizer
- Remove stop words (including NLTK's default stop words and my identified stop words)
- Lemmatize each word using NLTK's WordNetLemmatizer
- Reduces similar words (both semanticly and grammaticly related words) to a single word
Words with only punctuation removed

Words after cleaning pipeline

- Transform the words into counts using SKLearn's count vectorizer and the tfidf vectorizer
-
Some models require an unstandardized count of each word
-
Other models require a count standardized by how often that word occurs in the corpus
-
Removed words that occured in less than 15% of documents
-
Also removed words that occured in more than 75% of documents
-
Only kept 5000 of the most frequent words
-
Top 10 words and their frequencies

Visualizing the descriptions after vectorizing in two dimensions

- Was hoping to identify a certain number of clusters
- Clusters don't seem to be clear in only two dimensions
Perhaps k-means clustering can help identify the proper number of clusters to choose
-
Modeled the data using K-Means clustering with a varying number of clusters
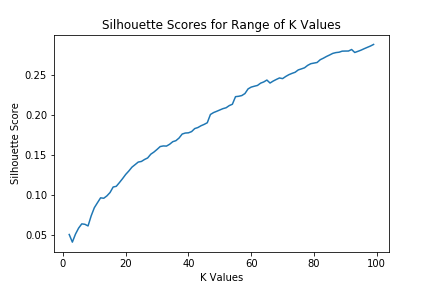
-
Hoped to see a clear peak of this graph, but it appears that the model just keeps getting better and better as number of clusters increases
-
Point of this project would be lost if too many clusters were extracted

Given this data, I changed my approach from trying to numerically figure out what the best number of clusters. Instead, I decided to run several models and choose the number of clusters and type of model that seems to yield the most useful clusters.
Most representative jobs in each of the 7 clusters in a k-means model
K-means is a hard clustering technique that determines what documents most likely belong to each cluster. The following table represents words in the descriptions that best represent the cluster of jobs. In more techinical terms, these were the words that were closest to each of the 7 cluster centers in euclidean space.
| LDS jobs | Research jobs | Machine learning jobs | Data analysis jobs | Senior level jobs | Software engineer jobs | Marketing jobs |
|---|---|---|---|---|---|---|
| ancestry | research | learn | product | system | system | marketing |
| record | analysis | machine | model | position | software | analytics |
| million | program | model | company | education | engineer | insight |
| applicable | project | scientist | insight | computer | cloud | model |
| look | position | ai | statistical | demonstrate | service | product |
| create | support | deep | scientist | level | product | analysis |
| law | skill | aws | analysis | least | design | strategy |
- These jobs match fairly well with my hypothesized clusters, but there seem to be some random clusters that were difficult to classify as well.
- I started looking for 3 or so clusters representing jobs that are heavy in machine learning, more research/data analysis positions, and database heavy jobs. The k-means model kept returning random clusters that didn't make much sense to me so I decided to model the data using latent dirichlet allocation - a soft clustering technique that allows descriptions to load on to multiple clusters and gives the probability that each document should be classified in each cluster.
- Using the gensim and pyLDAvis libraries in python also allows for some great visualizations of LDA clustering
LDA Clustering
In reality, each of these jobs are part one topic and part another topic; jobs rarely are clearly defined as one type of job. A soft clustering technique such as LDA may be more appropriate for this type of data.
 Using 7 clusters yielded topics that were almost all on top of each other. Additionally, the topics didn't seem to have clearly defined terms. Perhaps only using three clusters would be better.
Using 7 clusters yielded topics that were almost all on top of each other. Additionally, the topics didn't seem to have clearly defined terms. Perhaps only using three clusters would be better.
Using 3 clusters produced topics that were farther apart but the words that represented the topics didn't seem to have a very cohesive connection.



Conclusion
-
NLP is hard and stopword modification can help produce better clustering
- Feature engineering is the name of the game
-
K-means clustering produced better clusters than did LDA
- LDS jobs
- Research jobs
- Machine learning jobs
- Data analysis jobs
- Senior level jobs
- Software engineer jobs
- Marketing jobs
-
Using clustering scores can be helpful but making sense out of this data was essential
-
Python can produce some amazing visuals with not much code
-
Word stemming rather than - or in addition to - lemmatization may be more appropriate
-
Limitations and future directions
- Only searched for data science
- Would like to isolate skills and cluster based on skills only
- Much of the descriptions are about the company; not about the job
- Would like to cluster jobs by state