标签(空格分隔): 量化交易
《量化交易之路》代码学习
总结一下,书中最重要的内容,主要分为以下这么几个部分。
在这一部分中,主要高速我们这么几件事情:
1. 什么时候买入股票,什么时候卖出股票。(择时)
2. 买入股票时,应该怎么给股票报价;卖出股票时,应该怎么给股票报价。(定价)
3. 假如我有本金X元,买次买股票,应该花多少钱呢?(仓位控制)
这一部分,书中主要介绍了《海龟交易法则》中的两种策略:
1. 趋势跟踪
2. 均值回归
趋势跟踪:
基本思路:认为股票在一段时间内的上涨,意味着它在之后也会上涨。
1. 当第x天收盘后,如果当天的收盘价,高于前k天(不含第x天)的最高价,那么在第x+1天买入。
2. 当第x天收盘后,如果当天的收盘价,低于前k天(不含第x天)的最低价,那么在第x+1天卖出。
特点:
1.导致胜率较低。
2.每次的盈利高于每次的亏损
均值回归:
基本思路:认为股票的上涨和下跌是暂时的,股票的票价是围绕一个价值上下波动的
1. 将历史数据分为以某个时间点分为两部分,前半部分作为训练集,后半部分作为回测集。
2. 计算训练集收盘价的均值mean,和标准差std。我们以mean+std作为卖出的价格节点,mean-std作为买入的价格节点。
4. 当价格低于mean-std时,我们就买入股票,并保持持有,直到价格高于mean+std;
5. 当价格高于mean+std时,我们就卖出股票,保持空仓,直到价格再一次低于mean-std。
特点:
1.属于统计套利模型,大机构高频交易可能更加适合。
这里定价模型采用的是相对简单的方式:
1.当我在第x天确认,在第x+1天需要买入/卖出时。
2.我的价格选择为第x天的最高价high,与第x天的最低价low的平均值,即p=(high+low)/2
保证存活是最重要的!
相比于择时策略是让我们赚更多的钱,仓位控制是让我们在可能亏得时候不至于亏太多。
具体而言,仓位控制,采用的是在股票交易领域修正后的凯利公式:
f=Pwin-【Ploss/(收益期望/亏损期望)】
计算出来的f,就是仓位比例,比如我有100w本金,f算出来是0.1,那么我每次买,就应该只买10w。
关于如何计算Pwin,Ploss以及收益期望,亏损期望,会在下一章补上。
不是所有股票都有投资价值的,选股的目的就是从股票中挑选出有价值的股票,来进行投资。
这个其实和代码关系不大,更重要的是策略。
那么对于策略而言,书中介绍的其实就两种:
1. 基于趋势。
2. 基于最低最高值。
基于趋势选股:
1. 当拿到股票的历史数据后,我用直线去拟合这部分数据。
2. 若拟合直线的斜率为正,表示它的总趋势是上涨,值得买入;相反,则不值得入手。
基于最低最高值选股:
1. 如果在历史数据中,它的股价一直在某个价格以上,那么值得买入。
裁判系统,是通过总结回测结果中失败的交易的模式,得到什么时候应该阻止买入信号生效的系统。
其实裁判可以看做是择时的补充,择时告诉我们什么时候该买,裁判告诉我们什么时候不该买。
传统上,我们可能需要通过手工编写策略,来完成裁判系统。
但是,现在,我们可以通过机器学习的方法,得到交易失败的一般模式,并提取该模式的特点,来进行交易的拦截。
想象一下,足球场上,有的裁判是看是否越位,有的裁判是看你是否撞人,不同的裁判看得特征点不同。
那么,在这里也是一样,不同的裁判通过不同的特征,去寻找交易失败(即这次交易亏损)的原因。
-
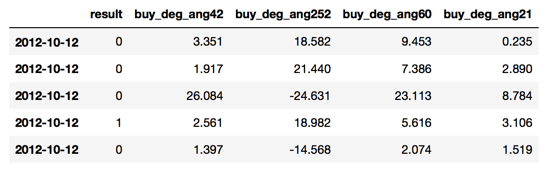
1)在这里,我们选择每次买入时,往回看21,42,69,252天的拟合角度。
其中,result=1表示此次交易成功,result=0表示此次交易亏损。
-
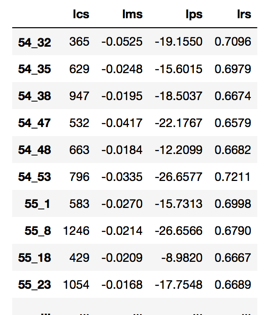
2)然后,我们使用GMM聚类,将这些数据聚成40~84个。(相当于要跑GMM 44次)
54_32表示它是将所有数据分成54类中的第32个簇 lcs:簇中样本总数, lrs:簇中样本失败率, lps:交易获利比例综合, lms:每笔交易的平均获利。
-
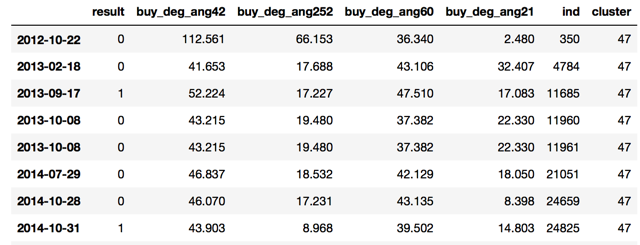
3)选择出这些所有类别中,亏损交易所占比例(失败率)最多的那一个簇,查看它的角度特征。(这里发现是第62_47号簇)
-
4)对该簇失败率这么高进行宏观分析,如若发现该簇的21角度平均值远高于总体的21日角度均值,而60日角度均值远低于总体的60日角度均值。我们就可以解释说,这些交易是因为在过去3个月股票下跌的时候,因为短时快速拉升而选择买入,终将自己套牢而亏损。
-
5)我们发现了亏损的原因,那么如何来使用这个原因来减少亏损呢?现在,我们知道了哪个簇里面的交易不能执行,那么,我们只需要查看新进来的交易是否属于这个簇就好。
-
6)这里,我们认定说对于将数据分为62个簇,并且其中的第47号簇不能要。我们就对新进来的数据,对他进行分类,看他数据62个簇中的哪一个,如果属于47号簇,那就不能要。
-
7)这个时候,ml的**促使我们思考,只选择亏损最大的簇作为丢失好吗?在簇评价中,我们使用ics,irs,ips和ims进行评价,其中ics是数量,可以不用在意。那么,剩下三个参数,是否存在一个最优组合,选出一些需要被剔除的簇,使得剩下的交易收益最高?
-
8)我们对irs,ips和ims使用grid-search方法,使用(拦截交易个数/总交易个数)*(拦截交易的失败率-拦截交易的成功率)作为评分,得到了新的参数,irs,ips和ims。
-
9)那么,任何满足irs,ips和ims条件的簇,都需要被剔除,不再执行。这样,新进来的交易也需要来判断,是否属于这些簇,从而决定是否被拦截。
####3.2 提升 有时候发现,这些裁判带来的提升并不是特别高,那么,可以考虑从以下几个方面来加强:
1. 寻找更多的特征,构造更多的裁判
2. 让裁判之间进行更复杂的综合裁决,让裁判之间配合
3. 为每个裁判赋予不同的权重,进行综合裁决
4. 用更多的数据来提升裁判的效用。
5. 添加边裁。
这部分其实是介绍了一些金融学上面的知识,用于度量股票的一些走势。 比如:
- 1)策略收益:(股票卖出总价-股票买入总价)/(股票买入总价)*100%
- 2)策略年化收益:(一年的交易天数/策略执行天数)*策略收益
- 3)平均获利期望:一个统计周期内,执行策略产生盈利的所有交易的平均收益。每次收益按照百分比算,比如只盈利的两次,第一次盈利10%,第二次30%,那么平均收益就是20%。
- 4)平均亏损期望:同理。
还有一些专业的金融量:
-
1)夏普比率:每承担一份风险,可以获得多少超额报仇;这个值越大,说明获得的超额报酬越高,策略越好。
-
2)信息比率:表示单位主动风险带来的超额收益,大信息比率的策略比小的好
-
3)策略波动:该值越高,表示风险越大
-
4)阿尔法:表示交易者从市场获取的与市场走势无关的交易回报
-
5)贝塔:量化了交易风险。
另外,记住,一般的量化交易策略的有效期,大概在2~7个月,所以要不停开发不停尝试。 而且,能够从别人那里看到的策略一般都是失效了的,所以还要修炼内容,开发自己的策略啊。