Apache Spark is one of the hottest new trends in the technology domain. It is the framework with probably the highest potential to realize the fruit of the marriage between Big Data and Machine Learning. It runs fast (up to 100x faster than traditional Hadoop MapReduce due to in-memory operation, offers robust, distributed, fault-tolerant data objects (called RDD), and integrates beautifully with the world of machine learning and graph analytics through supplementary packages like Mlib and GraphX.

- SparkContext and RDD basiscs
- SparkContext workers lazy evaluations
- RDD chaining executions
- Word count example with RDD
- Partitioning and Gloming
- Dataframe basics
- Dataframe simple operations
- Dataframe row and column objects
- Dataframe groupBy and aggregrate
- Dataframe SQL operations
Unlike most Python libraries, getting PySpark to start working properly is not as straightforward as pip install ... and import ... Most of us with Python-based data science and Jupyter/IPython background take this workflow as granted for all popular Python packages. We tend to just head over to our CMD or BASH shell, type the pip install command, launch a Jupyter notebook and import the library to start practicing.
But, PySpark+Jupyter combo needs a little bit more love :-)

python3 --version
sudo apt-get update
sudo apt install python3-pip
pip3 install jupyter
export PATH=$PATH:~/.local/bin
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get install oracle-java8-installer
sudo apt-get install oracle-java8-set-default
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export JRE_HOME=/usr/lib/jvm/java-8-oracle/jre
sudo apt-get install scala
pip3 install py4j
Download latest Apache Spark (with pre-built Hadoop) from Apache download server. Unpack Apache Spark after downloading
sudo tar -zxvf spark-2.3.1-bin-hadoop2.7.tgz
Set variables to launch PySpark with Python3 and enable it to be called from Jupyter notebook. Add all the following lines to the end of your .bashrc file
export SPARK_HOME='/home/tirtha/Spark/spark-2.3.1-bin-hadoop2.7'
export PYTHONPATH=$SPARK_HOME/python:$PYTHONPATH
export PYSPARK_DRIVER_PYTHON="jupyter"
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"
export PYSPARK_PYTHON=python3
export PATH=$SPARK_HOME:$PATH:~/.local/bin:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
source .bashrc
Resilient Distributed Datasets (RDD) is a fundamental data structure of Spark. It is an immutable distributed collection of objects. Each dataset in RDD is divided into logical partitions, which may be computed on different nodes of the cluster. RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes.
Spark makes use of the concept of RDD to achieve faster and efficient MapReduce operations.

Formally, an RDD is a read-only, partitioned collection of records. RDDs can be created through deterministic operations on either data on stable storage or other RDDs. RDD is a fault-tolerant collection of elements that can be operated on in parallel.
There are two ways to create RDDs,
- parallelizing an existing collection in your driver program,
- referencing a dataset in an external storage system, such as a shared file system, HDFS, HBase, or any data source offering a Hadoop Input Format.
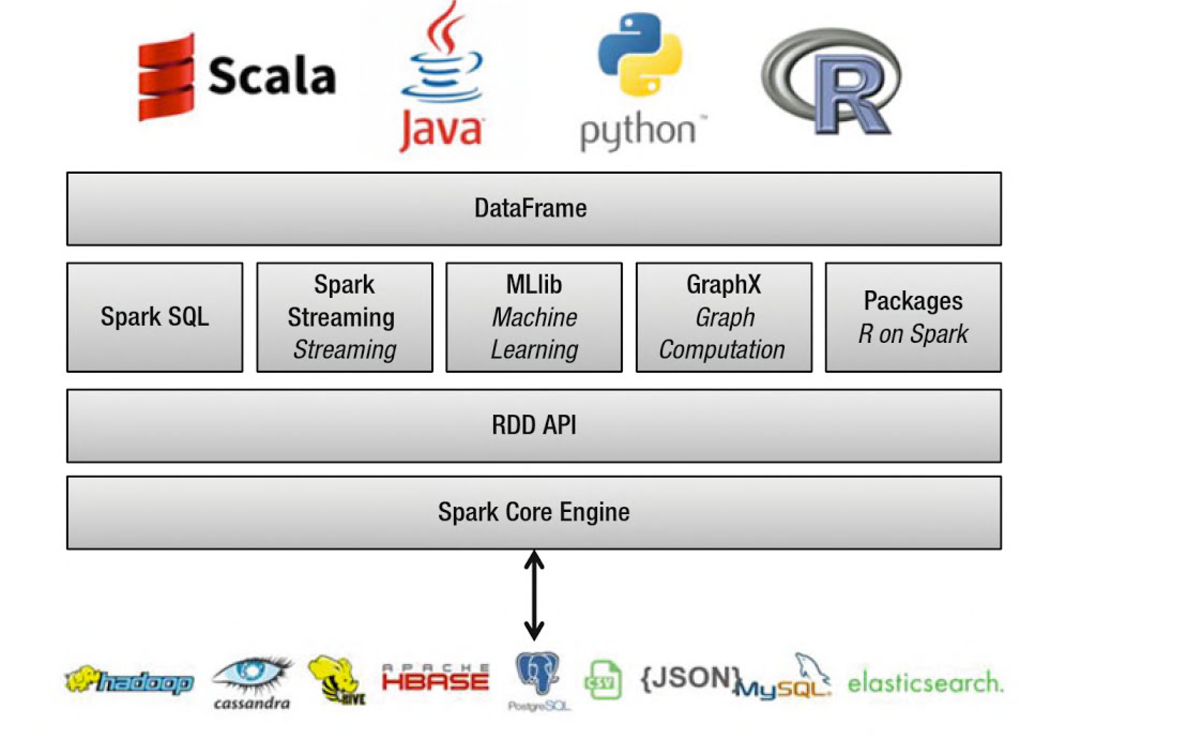
In Apache Spark, a DataFrame is a distributed collection of rows under named columns. It is conceptually equivalent to a table in a relational database, an Excel sheet with Column headers, or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs. It also shares some common characteristics with RDD:
- Immutable in nature : We can create DataFrame / RDD once but can’t change it. And we can transform a DataFrame / RDD after applying transformations.
- Lazy Evaluations: Which means that a task is not executed until an action is performed.
- Distributed: RDD and DataFrame both are distributed in nature.
- DataFrames are designed for processing large collection of structured or semi-structured data.
- Observations in Spark DataFrame are organised under named columns, which helps Apache Spark to understand the schema of a DataFrame. This helps Spark optimize execution plan on these queries.
- DataFrame in Apache Spark has the ability to handle petabytes of data.
- DataFrame has a support for wide range of data format and sources.
- It has API support for different languages like Python, R, Scala, Java.
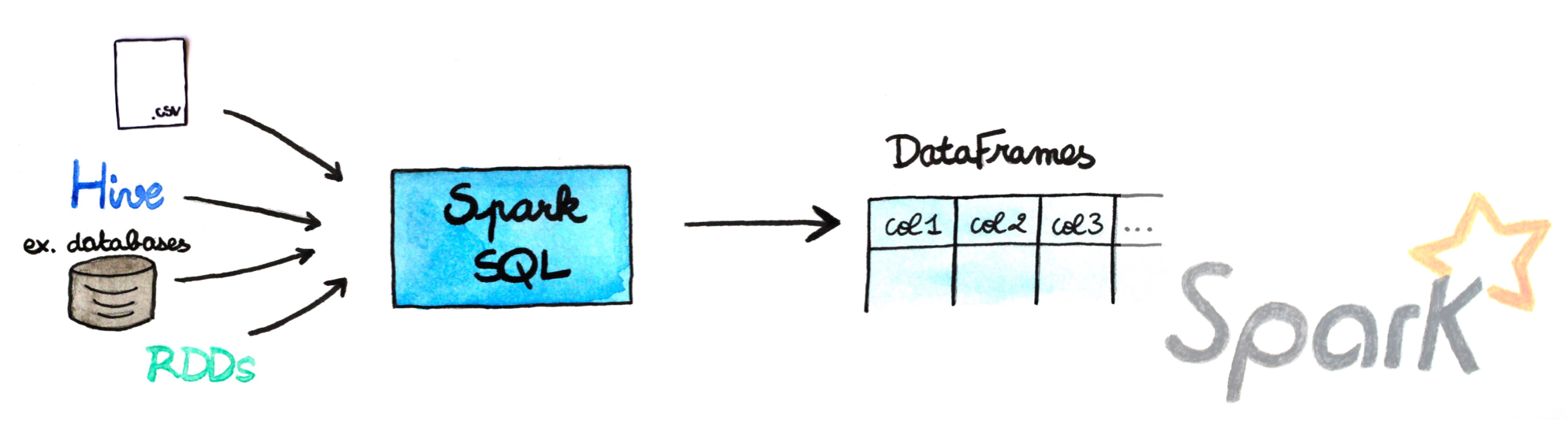
Spark SQL provides a DataFrame API that can perform relational operations on both external data sources and Spark's built-in distributed collections—at scale!
To support a wide variety of diverse data sources and algorithms in Big Data, Spark SQL introduces a novel extensible optimizer called Catalyst, which makes it easy to add data sources, optimization rules, and data types for advanced analytics such as machine learning. Essentially, Spark SQL leverages the power of Spark to perform distributed, robust, in-memory computations at massive scale on Big Data.
Spark SQL provides state-of-the-art SQL performance and also maintains compatibility with all existing structures and components supported by Apache Hive (a popular Big Data warehouse framework) including data formats, user-defined functions (UDFs), and the metastore. Besides this, it also helps in ingesting a wide variety of data formats from Big Data sources and enterprise data warehouses like JSON, Hive, Parquet, and so on, and performing a combination of relational and procedural operations for more complex, advanced analytics.
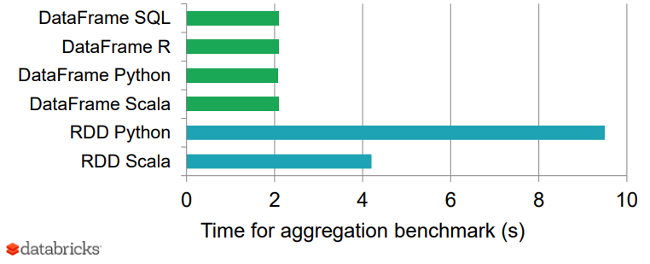
Spark SQL has been shown to be extremely fast, even comparable to C++ based engines such as Impala.

Following graph shows a nice benchmark result of DataFrames vs. RDDs in different languages, which gives an interesting perspective on how optimized DataFrames can be.
Why is Spark SQL so fast and optimized? The reason is because of a new extensible optimizer, Catalyst, based on functional programming constructs in Scala.
Catalyst's extensible design has two purposes.
- Makes it easy to add new optimization techniques and features to Spark SQL, especially to tackle diverse problems around Big Data, semi-structured data, and advanced analytics
- Ease of being able to extend the optimizer—for example, by adding data source-specific rules that can push filtering or aggregation into external storage systems or support for new data types