Analytics driven Customer Behavior Ranking for Retail Promotions using POS data Profile Customer based on their Buying behavior using POS (Point of Sale) data from a Retail stores. Normalised Behavior scores are computed based on their Shopping patterns and a Analytics Segmantation is run to identify Customers like Gold Class, Customers with Up Sell prospects or Customers at Risk and Dormant Customers. These Segments of Customers are then used for launching specific Promotions
Segmentation of Customer is a necessary first step in any Retail environment that needs to enhance their Customer experience. Customer Segmentation can be done using Point of Sale (PoS) data in Retail. Point of Sale data is captured at the counter in every Retail outlet either in FMCG or CPG
Below are some of the reasons that compel segmenting Customers for effective Promotions.
- Not all Customers behave similarly
- Customers of certain similarity show similar predictable behavior
- There cannot be one common Customer engagement strategy for approaching all Customers
The above pointers lead to the bigger question of:
- How to identify different Customer groups who exhibit similar behavior?
This Code pattern is a walkthrough of the steps involved in using PoS data to Segment Customers based on their buying behavior. Segmentation techniques are used to Rank Customers. The ranked Customer data is further used to generate Dashboards that delivers insights on the Customer buying Metrics
IBM cloud storage, Python notebooks in IBM Watson Studio, IBM Cognos will be used to implement the above Use case
All the intermediary steps are modularized and all code open sourced to enable developers to use / modify the modules / sub-modules as they see fit for their specific application
When you have completed this pattern, you will understand how to
- Read Retail Point of Sale (PoS) data stored in the IBM Object storage
- Compute Normalised Customer metrics from the CustomerPoS data
- Configure the features for Segmentation
- Run the Segmentation of Customers using Manual and Auto mode for Ranking the Customers A hybrid unsupervised k-means technique is applied on the Normalised Customer metrics is used in Auto mode Feature to allow configuration of Normalised ranges for the Customer metrics can be used in the Manual mode This is to ensure Developers who are new to these techniques can start experiments using Auto mode The initial results can be further fine tuned using Manual mode
- Run a Cognos dashboard to analyze the results of Customer segmentation and Buying insights of different Segments This step will enable visually analyze and present the Customer segmentation results

- User signs up for IBM Data Science experience
- User loads the sample IoT sensor Time series data to database
- A configuration file holds all the key parameters for running the IoT Time series prediction algorithm
- The prediction algorithm written in Python 2.0 Jupyter notebook uses the Configuration parameters and Sensor data from DB
- Python Notebook runs on Spark in IBM Watson Studio to ensure performance and scalability
- The outputs of the prediction algorithm is saved in Object storage for consumption
- IBM Cloud: IBM's innovative cloud computing platform or IBM Cloud in short (formerly Bluemix) combines platform as a service (PaaS) with infrastructure as a service (IaaS) and includes a rich catalog of cloud services that can be easily integrated with PaaS and IaaS to build business applications rapidly.
- IBM Watson Studio: Analyze data using Python, Jupyter Notebook and RStudio in a configured, collaborative environment that includes IBM value-adds, such as managed Spark.
- IBM Data Science Experience: Analyze data using Python, Jupyter Notebook and RStudio in a configured, collaborative environment that includes IBM value-adds, such as managed Spark.
- IBM Cloud Object Storage: An IBM Cloud service that provides an unstructured cloud data store to build and deliver cost effective apps and services with high reliability and fast speed to market.
- Analytics: Finding patterns in data to derive information.
- Data Science:Systems and scientific methods to analyze structured and unstructured data in order to extract knowledge and insights.
- IBM Cognos Live Embedded: The IBM Cognos Dashboard Embedded lets you, the developer, painlessly add end-to-end data visualization capabilities to your application so your users can easily drag and drop to quickly find valuable insight and create visualizations on their own. It is a new, API-based solution that lets developers easily add end-to-end data visualization capabilities to their applications so users can create visualizations that feel like part of the app. It offers developers the ability to define the user workflow and control the options available to users – from a guided exploration of the analysis through authored fixed dashboards to a free-form analytic exploration environment in which end-users choose their own visualizations – and virtually anything in between.
- Cognos DashBoard Embedded

Follow these steps to setup and run this IBM Code Pattern. The steps are described in detail below.
- Sign up for the Watson Studio
- Create IBM Cloud services
- Create the Jupyter notebook
- Add the data and configuraton file
- Run the notebook
- View the Segmentation results
- Run Cognos dashboard
- Analyze Customer bahaviorinsights
Sign up for IBM's Watson Studio. By signing up for Watson Studio, two services will be created - Spark and ObjectStore in your IBM Cloud account.

IBM Cloud -> Launch Catalog -> Watson -> Watson Studio

Download the sample data file, sample configuration file, python notebook from github and store it in your a local folder. This will be used to upload to database in the next steps.
Once you are familiar with the entire flow of this Pattern, you can use your own data for analysis. But ensure that your data format is exactly same as provided in the sample data file and configuration file.
First create a new project in Watson Studio. Follow the detailed steps provided in the IBM online documentation for Watson Studio Project creation, or watch a video on using Watson Studio to create a project.
In Watson Studio:
Use the menu on the top to select Projects and then Default Project.
Click on Add notebooks (upper right) to create a notebook.
-
Select the
From URLtab. -
Enter a name for the notebook.
-
Optionally, enter a description for the notebook.
-
Enter this Notebook URL: https://github.com/IBM/commerce_pos_analytics/blob/master/notebook/customer_segmentation_promo.ipynb
-
Select the free Anaconda runtime.
-
Click the
Createbutton. -
Upload the sample .json, .txt Watson Studio configuration file to Watson Studio Object storage from URL below: "https://github.com/IBM/commerce_pos_analytics/blob/master/data/Online%20Retail%20Sample.csv" https://github.com/IBM/commerce_pos_analytics/blob/master/configuration/PromoConfig.txt
To upload these files in Watson Studio object storage,
- Go to
My Projects->Your Project Name - Click on the
Find and add dataicon on top ribbon - Select the file and upload one by one
Now you must be able to see the uploaded files listed under
My Projects->Your Project Name->Assetstab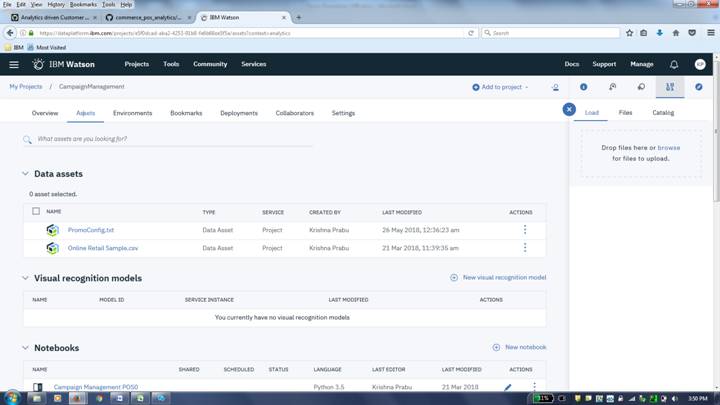
- Go to


Fix-up configuration parameter .json file name and values:
Go to the Notebook in Watson Studio by navigating to My Projects -> Your Project Name
Under Assets tab, under Notebooks section you will find the Notebook you just imported
Click on the Click to Edit and Lock icon to edit the notebook in Jupyter notebook in Watson Studio
For more details on Creating, Editing and sharing notebooks in IBM Watson Studio refer to Notebooks Watson Studio documentation
You can now update the variables that refer to the .txt configuration file name in the Python - Jupyter Notebook. This step is necessary only if you had changed the name of the sample .json configuration file you had uploaded earlier for any reason.

The default .txt configuration file, you uploaded earlier works without any changes with the Sample data supplied.
If you wanted to customise the Segmentation model to suit your requirements you can do so. Below are the steps to configure the .json configuration file to train the Predictive models using your custom data file.
- Download the .txt configuration file to your Computer local folder
- Open a local copy of the .txt file in text editor like notepad and edit the Watson Studio configuration .json file
-
- Update the
column valuesto suit your requirements and save the PromoConfig.txt file. Retain the rest of the format and composition of the .txt file
- Update the
- Delete the copy of
PromoConfig.txtin Watson Studio data store if one is already uploaded by you earlier. - Now upload your local edited copy of
PromoConfig.txtby following the steps in section 6.3 above.

The descriptions of the columns that can be configured are as below.
i. Customer Segment: Name of the Customer segement tobe assigned ii. Segment Auto Rank: Corresponding Ranking for the Customer segment. Used only if the Customer segmentation is run as AUTO iii. RFrom, RTo: Range of Recency value in dates. This is a numeric field with range from 0-100. Used only if the Customer segmentation mode is run as MANUAL iv. FFrom, FTo: Range of Frequency value in dates. This is a numeric field with range from 0-100. Used only if the Customer segmentation mode is run as MANUAL v.MFrom, MTo: Range of Shopping value. This is a numeric field with range from 0-100. Used only if the Customer segmentation mode is run as MANUAL
- The cell 3.1.2 of the Jupyter Notebook has a function definition which is shown for illustration purposes. These details that have user specific security details are striked out in the screenshots shown below. This function will need to be recreated with your user specific access credentials ang target data object. In order to do that first delete all pre existing code in cell 3.1.2 of the notebook.
Note: The .pynb file that you imported have code with dummy credentials for illustration purposes. This needs to be replaced by your user specific function with your own access credentials. The steps below explain that.
-
In section 3.1.2 of Jupyter Notebook (not this README file), Insert (replace) your own Object storage file credentials to read the
PromoConfig.txtconfiguration file
-
This step will auto generate a function that reads the data followed by a call to the function as below:

Refer to screen shot above for details. For more details, revisit the documentation help links provided in beginning of section 5.2.2
Use Find and Add Data (look for the 10/01 icon) and its Connections tab. You must be able to see your database connection created earlier. From there you can click Insert to Code under the Data connection list and add ibm DBR code with connection credentials to the flow.

Note: If you don't have your own data and configuration files, you can reuse our example in the Read IoT Sensor data from database section. Look in the /data/iot_sensor_dataset.csv directory for data file.

The Customer segmentation can be run in 2 modes
-
By setting the mode to “AUTO”
 In AUTO mode Customer segmentation algorithm will automatically do the segmentation and ranking based on Customer Buying behavior
In AUTO mode Customer segmentation algorithm will automatically do the segmentation and ranking based on Customer Buying behavior -
By setting the mode to “MANUAL”
 In MANUAL mode, the range of values mentioned for Customer metrics will be used for applying the segmentation.
In MANUAL mode, the range of values mentioned for Customer metrics will be used for applying the segmentation.


When a notebook is executed, what is actually happening is that each code cell in the notebook is executed, in order, from top to bottom.
Each code cell is selectable and is preceded by a tag in the left margin. The tag
format is In [x]:. Depending on the state of the notebook, the x can be:
- A blank, this indicates that the cell has never been executed.
- A number, this number represents the relative order this code step was executed.
- A
*, this indicates that the cell is currently executing.
There are several ways to execute the code cells in your notebook:
- One cell at a time.
- Select the cell, and then press the
Playbutton in the toolbar.
- Select the cell, and then press the
- Batch mode, in sequential order.
- From the
Cellmenu bar, there are several options available. For example, you canRun Allcells in your notebook, or you canRun All Below, that will start executing from the first cell under the currently selected cell, and then continue executing all cells that follow.
- From the
- At a scheduled time.
- Press the
Schedulebutton located in the top right section of your notebook panel. Here you can schedule your notebook to be executed once at some future time, or repeatedly at your specified interval.
- Press the
The notebook outputs the results in the Notebook which can be copied to clipboard Results for AUTO Customer segmentation

If you are satisfied with the Automatic segmentation results, you can proceed further for runningthe Cognos Dashboard and analyze the insights
If you wanted to further tweak and improve the results, you can update the config text file and run the Customer segmentation in manual mode
Results for MANUAL Customer segmentation

Understanding data effectively can be tricky. With too little data, any kind of analysis is unreliable. But too much data can make it difficult to understand exactly what you’re looking at. These days, very few people suffer from too little data, but too much data is a common problem in the age of big data. The Cognos Dashboard Embedded, a new service offered on IBM Cloud, lets developers easily add end-to-end data visualization capabilities to their applications so users can create visualizations that feel like part of the app.
As explained in the beginning of this Code Pattern you must have completed the below steps
- Watson Studio & Create the Service
- Watson Studio instance
- Craete a New Project in Watson Project
STEP 4: See for the output of the file loaded to datasets tab as part of the model execution process (see previous sections) If you don’t see the data file which is in csv format then, Add a csv file to the Project space which eventually will be added to the Datasets.

STEP 5: From the Dashboard tab add a new dashboard:

As you are creating the dashboard for the first time, you will need to create Cognos Dashboard service.

STEP 6: Add a source as the .csv file from the recently uploaded dataset:

See available csv files. Pick the ones which your model has uploaded to Cloud Storage space given to you. Click on the Segmented Customers csv file:

STEP 6: Now, you can drag and drop the required fields to the Dashboard area.

Also, you can create your own Calculations.


STEP 7: View Cognos dashboard:

STEP 8: Finally Share the output - Once you are done with building the simple and easy dashboard, you can share as an URL which you can plug into your any application.
