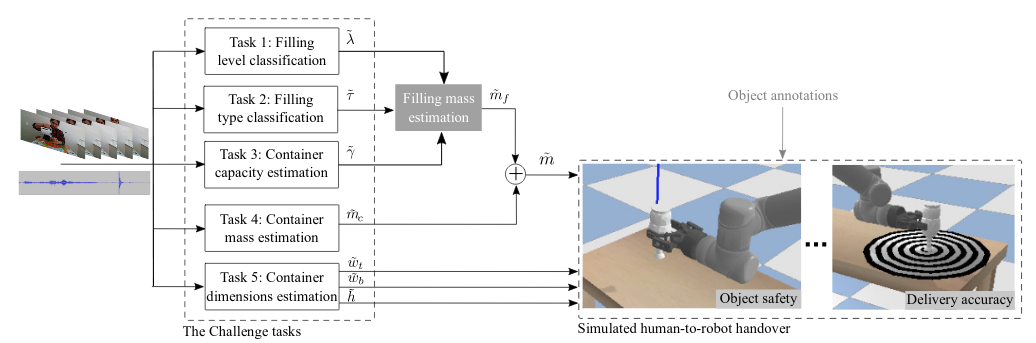
The CORSMAL challenge focuses on the estimation of the capacity, dimensions, and mass of containers, the type, mass, and filling (percentage of the container with content), and the overall mass of the container and filling. The specific containers and fillings are unknown to the robot: the only prior is a set of object categories (drinking glasses, cups, food boxes) and a set of filling types (water, pasta, rice). Click here
Update :
2022.2.12
The test score has been released, we find that our results contain some problems. We find the reason is that we perform the training on the sampled dataset using YOLOv5 and our training accuracy are obtained per Image, which introduces biases. We have tried our pre-trained model of task3 on whole training set and get the similar low score . We are currently working on re-evaluating our trained models on whole training set instead of per image on our YOLOv5 sampled version. The new pre-trained models will be coming soon...
-
Clone repository
git clone https://github.com/Noone65536/CORSMAL-Challenge-2022-Squids.git -
From a terminal or an Anaconda Prompt, go to project's root directory and run:
conda create --name corsmal-squids python=3.7conda activate corsmal-squidspip install -r requirements.txtThis will create a new conda environment and install all software dependencies. We also provide the .yaml file if you'd like to install packages using conda.
-
Install manually
If you could not insall packages using requiremens.txt through pip or using environments.yaml through conda, you can install packages manually using following instructions:
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch
you need torchvision>=0.8.pip install opencv-python
Do not use "conda" here as "conda" installs opencv3.4 which conflicts with torchvision>0.8- Other packages can be installed using:
conda install scipy tqdm pandas pyyaml requests seaborn matplotlib ipywidgets ipython

python test_task12.py --dataset datapath
Arguments:
-
--datapath: Absolute or relative path to dataset you would like to test. Notice that this is the path to the sub-dataset that directly contains the files to be tested, such ascrosmal_datset/trainorcrosmal_datset/test_pub -
--csv: (optional) Absolute or relative path to the csv file. Default output directory is this project's root directory. Please noted that the program reads the csv files and write testing results to the csv file directly. We hope that the indexes and columns of the csv file is the same as thepublic_test_set.csv
For example: python CORSMAL_test.py --dataset crosmal_datasets/test_pub --csv public_test_set.csv
Noted that this will generate some folders in the project's root directory:
- features : audio features (.npy)
- features_video_test : frames' features (.npy)
- features_frames_test: frames (.npy)
- results : results to be calculated as votes (.json)
python test_task1_audio.py --dataset datapath
Arguments:
-
--datapath: Absolute or relative path to dataset you would like to test. Notice that this is the path to the sub-dataset that directly contains the files to be tested, such ascrosmal_datset/trainorcrosmal_datset/test_pub -
--csv: (optional) Absolute or relative path to the csv file. Default output directory is this project's root directory. Please noted that the program reads the csv files and write testing results to the csv file directly. We hope that the indexes and columns of the csv file is the same as thetask1_audio.csv

python test_task345.py --dataset datapath or
python test_task345_4gpus.py --dataset datapath
Arguments: (The same as the Task1 and Task2)
--datapath: Absolute or relative path to dataset you would like to test. Notice that this is the path to the sub-dataset that directly contains the files to be tested, such ascorsmal_datset/trainorcorsmal_datset/test_pub--csv: (optional) Absolute or relative path to the csv file. Default output directory is this project's root directory.--bs_yolo: (optional) batch_size of the Yolov5 models. Default =64 for single GPU and 128 for 4 GPUs--bs_model: (optional) batch_size of the capacity,mass and dimensions estimation model. Deafult=32 for single GPU and 128 for 4 GPUs.
Please note that you may like to try following code for downloading the YOLOv5 weights
import torch
yolo = torch.hub.load('yolov5','custom', path='yolov5/yolov5s6.pt', source='local', force_reload=True)
On our GPU server(Tesla-V100), we use batch_size = 128 for both Yolov5 and our models. It occupied about 6.5G on GPU_0 and 4.5G on both GPU_1 and GPU_2 (zero in GPU_3 as we did not use it). It took about 1 hour to perdict all 228 videos in the CCM test_pub dataset.
When using single GPU with our deafult batch_size, it occupied about 3GB and took about 4 hours
You can enlarge the batchsize to obtain a higher detection speed.
Audio encoder: Params: 2,674,931 size: 10.7MB
RGB encoder: Params: 2,670,929 size: 10.7MB
LSTM: Params: 6,369,795 size: 24.8MB
Params: 2,674,931 size: 10.7MB
params: 2,671,217 size: 10.7MB
GPU: Tesla-V100 32G
Operating system: Linux and Colab