A toolkit for fine-tuning, inferencing, and evaluating GreenBitAI's low-bit LLMs.
This Python package uses the Bitorch Engine for efficient operations on GreenBitAI's Low-bit Language Models (LLMs). It enables high-performance inference on both cloud-based and consumer-level GPUs, and supports full-parameter fine-tuning directly using quantized LLMs. Additionally, you can use our provided evaluation tools to validate the model's performance on mainstream benchmark datasets.
- [2024/04]
- We have launched over 200 low-bit LLMs in GreenBitAI's Hugging Face Model Zoo. Our release includes highly precise 2.2/2.5/3-bit models across the LLM family, featuring LLaMA 2/3, 01-Yi, Qwen, Mistral, Phi-3, Gemma, and more.
- We released Bitorch Engine for low-bit quantized neural network operations. Our release support full parameter fine-tuning and parameter efficiency fine-tuning (PEFT), even under extremely constrained GPU resource conditions.
- We released gbx-lm python package which enables the efficient execution of GreenBitAI's low-bit models on Apple devices with MLX.
We have released over 200 highly precise 2.2/2.5/3/4-bit models across the modern LLM family, featuring LLaMA 2/3, 01-Yi, Qwen, Mistral, Phi-3, and more.
| Family | Bpw | Size | HF collection_id |
|---|---|---|---|
| Llama-3 | 4.0/3.0/2.5/2.2 |
8B/70B |
GreenBitAI Llama-3 |
| Llama-2 | 3.0/2.5/2.2 |
7B/13B/70B |
GreenBitAI Llama-2 |
| Qwen-1.5 | 4.0/3.0/2.5/2.2 |
0.5B/1.8B/4B/7B/14B/32B/110B |
GreenBitAI Qwen 1.5 |
| Phi-3 | 3.0/2.5/2.2 |
mini |
GreenBitAI Phi-3 |
| Mistral | 3.0/2.5/2.2 |
7B |
GreenBitAI Mistral |
| 01-Yi | 3.0/2.5/2.2 |
6B/34B |
GreenBitAI 01-Yi |
| Llama-3-instruct | 4.0/3.0/2.5/2.2 |
8B/70B |
GreenBitAI Llama-3 |
| Mistral-instruct | 3.0/2.5/2.2 |
7B |
GreenBitAI Mistral |
| Phi-3-instruct | 3.0/2.5/2.2 |
mini |
GreenBitAI Phi-3 |
| Qwen-1.5-Chat | 4.0/3.0/2.5/2.2 |
0.5B/1.8B/4B/7B/14B/32B/110B |
GreenBitAI Qwen 1.5 |
| 01-Yi-Chat | 3.0/2.5/2.2 |
6B/34B |
GreenBitAI 01-Yi |
In addition to our low-bit models, green-bit-llm is fully compatible with the AutoGPTQ series of 4-bit quantization and compression models.
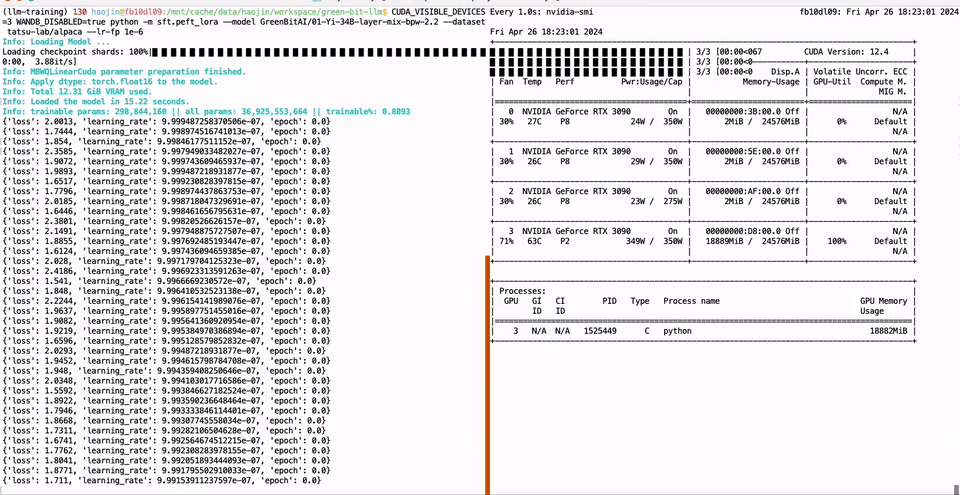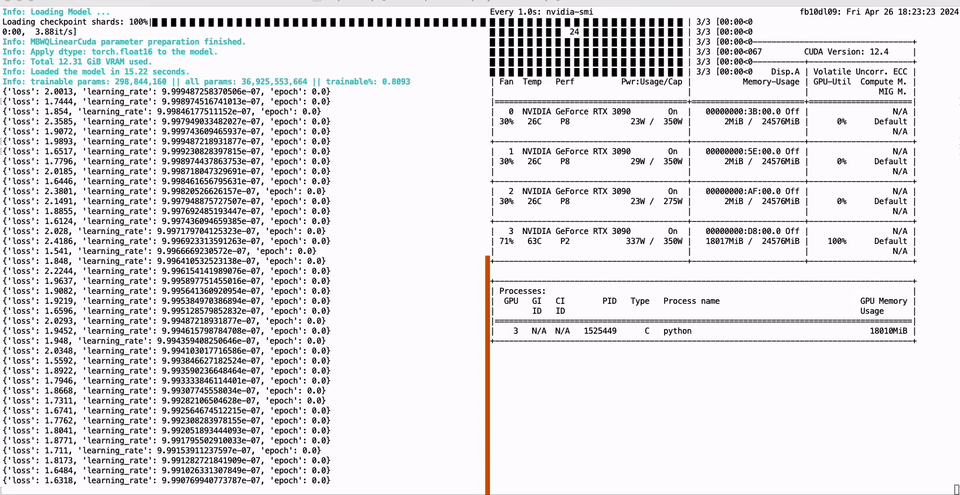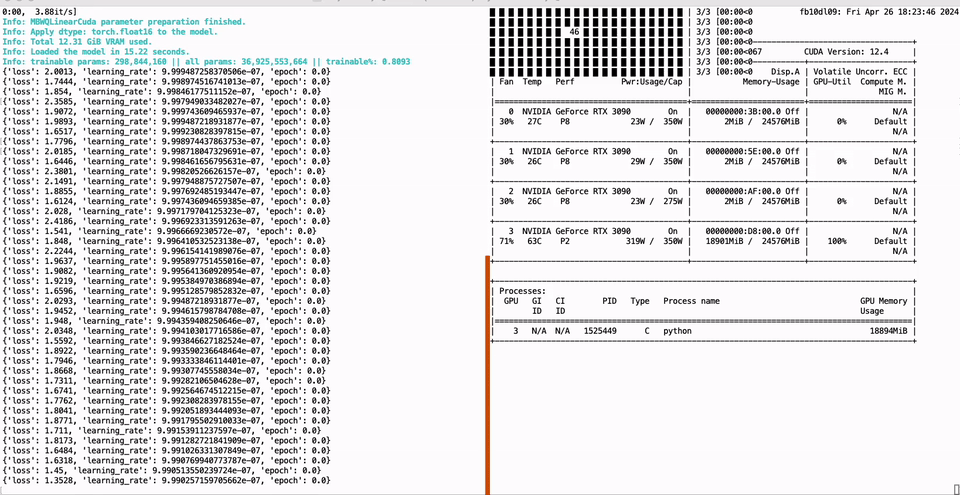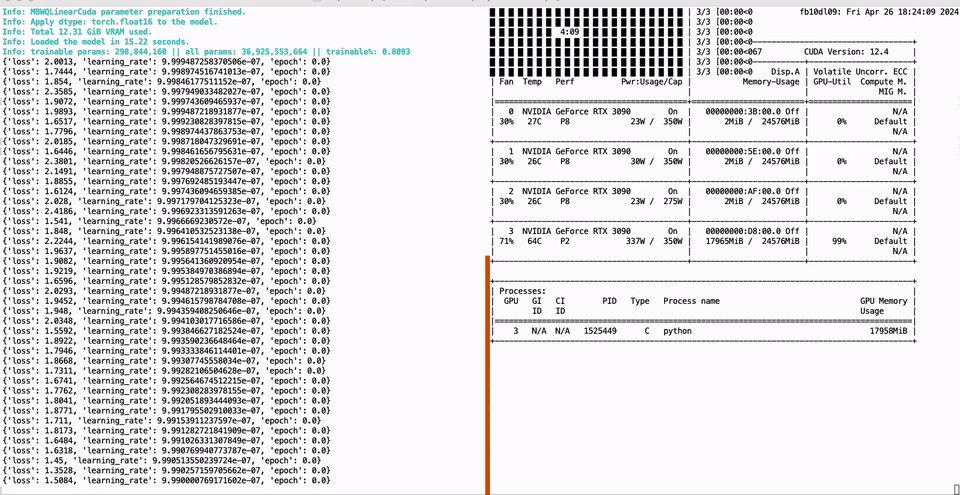
Full parameter fine-tuning of the LLaMA-3 8B model using a single GTX 3090 GPU with 24GB of graphics memory:
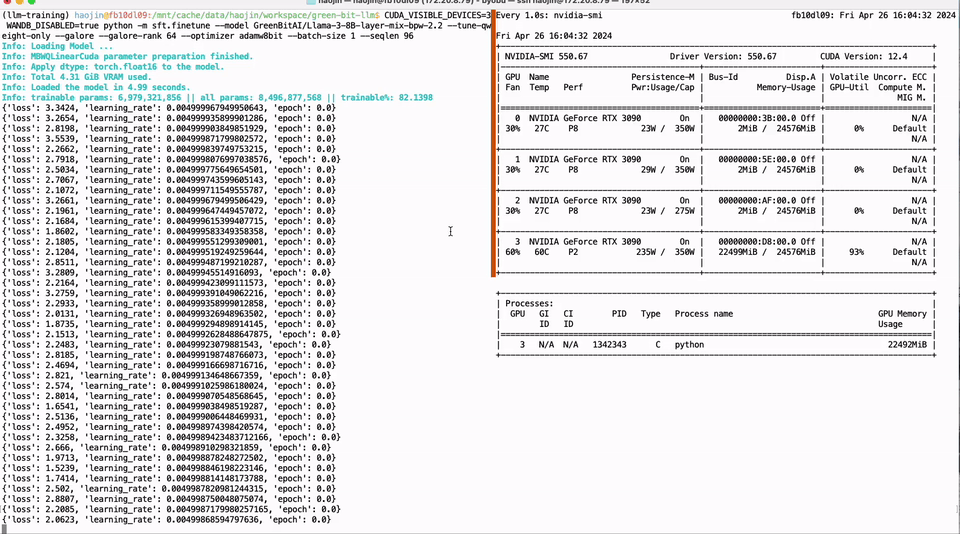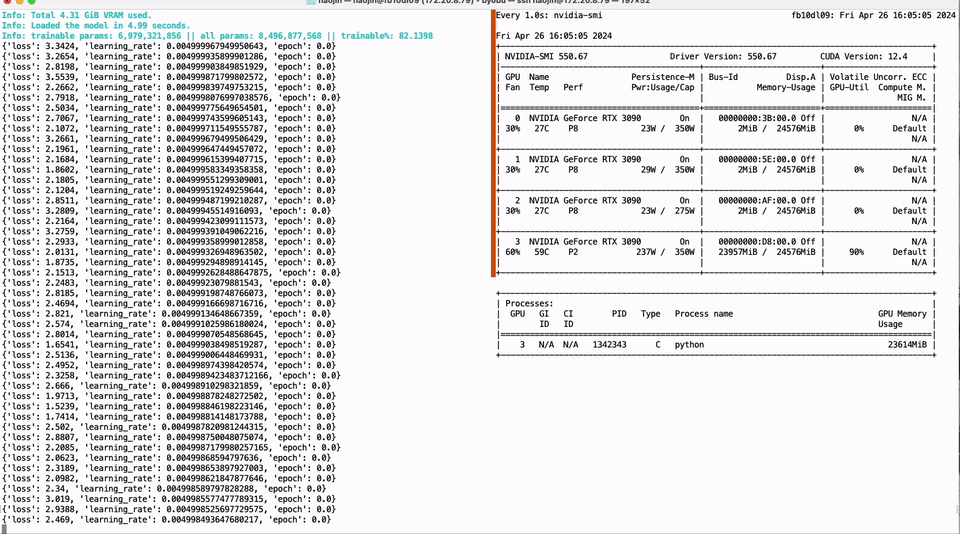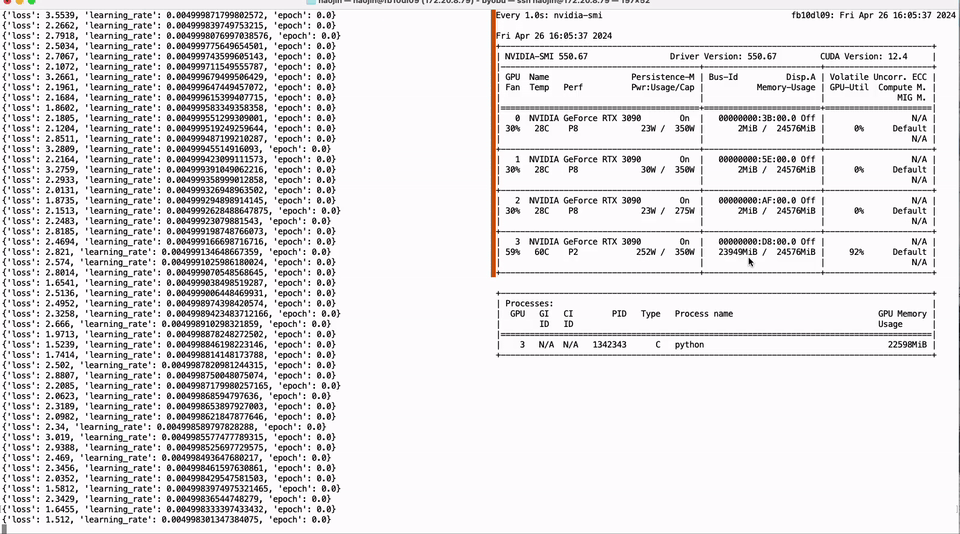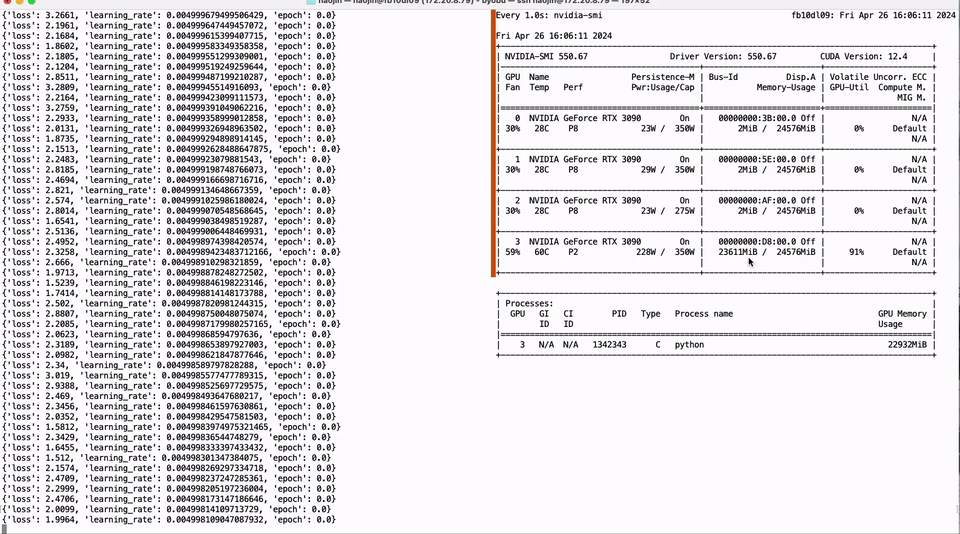
PEFT of the 01-Yi 34B model using a single GTX 3090 GPU with 24GB of graphics memory:
We support several ways to install this package. Except for the docker method, you should first install Bitorch Engine according to the official instructions.
Then choose how you want to install it:
pip install green-bit-llmClone the repository and install the required dependencies (for Python >= 3.9):
git clone https://github.com/GreenBitAI/green-bit-llm.git
pip install -r requirements.txtAfterward, install Flash Attention (flash-attn) according to their official instructions.
Alternatively, you can also use the prepared conda environment configuration:
conda env create -f environment.yml
conda activate gbai_cuda_lmAfterward, install Flash Attention (flash-attn) according to their official instructions.
Alternatively you can activate an existing conda environment and install the requirements with pip (as shown in the previous section).
To use docker, you can also use the provided Dockerfile which extends the bitorch-engine docker image.
Build the bitorch-engine image first, then run the following commands:
cd docker
cp -f ../requirements.txt .
docker build -t gbai/green-bit-llm .
docker run -it --rm --gpus all gbai/green-bit-llmCheck the docker readme for options and more details.
Please see the description of the Inference package for details.
Please see the description of the Evaluation package for details.
Please see the description of the sft package for details.
- Python 3.x
- Bitorch Engine
- See
requirements.txtorenvironment.ymlfor a complete list of dependencies
Run the simple generation script as follows:
CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.inference.sim_gen --model GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0 --max-tokens 100 --use-flash-attention-2 --ignore-chat-templateCUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.evaluation.evaluate --model GreenBitAI/Qwen-1.5-4B-layer-mix-bpw-3.0 --trust-remote-code --eval-ppl --ppl-tasks wikitext2,c4_new,ptbRun the script as follows to fine-tune the quantized weights of the model on the target dataset. The '--tune-qweight-only' parameter determines whether to fine-tune only the quantized weights or all weights, including non-quantized ones.
CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.finetune --model GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0 --dataset tatsu-lab/alpaca --optimizer DiodeMix --tune-qweight-only
# AutoGPTQ model Q-SFT
CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.finetune --model astronomer/Llama-3-8B-Instruct-GPTQ-4-Bit --dataset tatsu-lab/alpaca --tune-qweight-only --batch-size 1CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.peft_lora --model GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0 --dataset tatsu-lab/alpaca --lr-fp 1e-6
# AutoGPTQ model with Lora
CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.peft_lora --model astronomer/Llama-3-8B-Instruct-GPTQ-4-Bit --dataset tatsu-lab/alpaca --lr-fp 1e-6We release our codes under the Apache 2.0 License. Additionally, three packages are also partly based on third-party open-source codes. For detailed information, please refer to the description pages of the sub-projects.