
Tweets analysis from politics.





The project is online here !
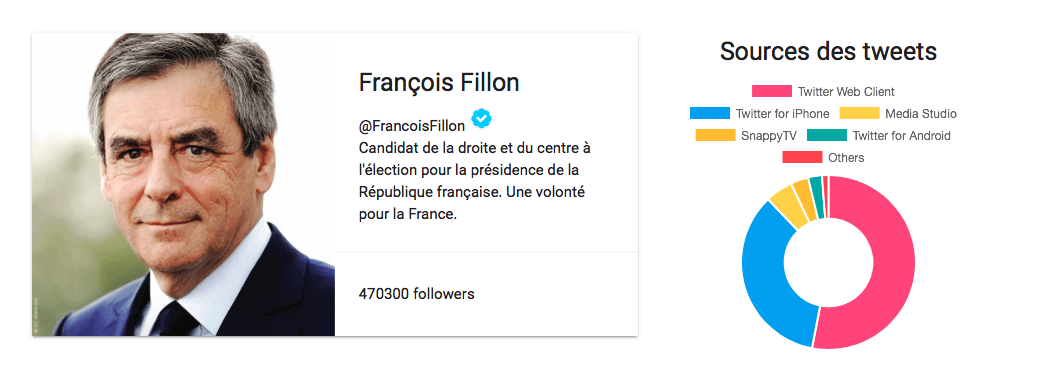
Semiotweet aims to better understand the tweets posted by politics. It shows what are the most commons words in those tweets, and what are the different semantic fields related to them.
Stack is subjects to know changes.
- Django as framework,
- PostGreSQL for the database,
- Twitter API as data provider,
- TreeTagger & gensim for tweets' analysis,
- chart.js for visualization
There's two apps called viewer and api.
urls.py directly redirects to this first app (viewer).
api is a classic REST API for the website.
The one from extraction.py catch the tweets, those in semanticAnalysis.py process the analysis.
The analysis is based on LDA (Latent Dirichlet allocation).
There are three models : Tweet, User and LdaModel :

Those models may change with new features.
Templates are directly put in viewer/templates/ and not as usual in viewer/templates/viewer as it can be the case in most of Django apps.
Clone it. Go to the folder and :
# For Python 3.6 or Python 3.x
$ virtualenv -p /usr/bin/python3 venv3
$ source venv3/bin/activate
# For Python 2.7
$ virtualenv venv
$ source venv/bin/activate
In the following, all the export lines can be put at the end of the file /venv3/bin/activate`. It is easier to define the env variables that way since those lines are executed when lauching the venv.
You have to set some variables in yout virtual env. First the "secret key" for the app (needed by Django). You can use this site to generate one.
$ export SECRET_KEY='someLongStringToImagine'
TreeTagger is one of the main library used for the project. You have to install it with the french parameter file in your home directory by refering to the official docummentation (see here)
You have to specify the folder in which you install TreeTagger with the LOCALTAGDIR variable :
$ export LOCALTAGDIR='/path/to/tree-tagger/'
Then the credentials (for user and consumer)for your app in order to use Twitter API. In order to have those string, you need to create a Twitter App (see here) ; then you can copy-paste them to set them in your virtual env.
$ export CONSUMER_KEY='someLongStringToImagine'
$ export CONSUMER_SECRET='someLongStringToImagine'
$ export KEY='someLongStringToImagine'
$ export SECRET='someLongStringToImagine'
Then install the requirements
$ pip install -r requirements.txt
If you have the error pg_config not found just install the libpq_dev package.
If you have the error could not run curl-config install the libcurl4-openssl-dev package.
Then re-install the requirements
You have to create a local_settings.py in the same folder as setting.py in order to extend this file (see the end of setting.py) ; this is useful for managing different
data base between local development and deployement :
$ touch local_settings.py
In this file are the settings set to use the local database (DEBUG is set to True for dev', false for production.) :
# Local settings : used for local development.
from __future__ import absolute_import
from .settings import PROJECT_ROOT, BASE_DIR
import os
DEBUG = True
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
}
Then you have to run this in order to set up the models and the database :
$ python manage.py makemigrations
$ python manage.py makemigrations viewer
$ python manage.py migrate
Finally, $ python manage.py runserver runs the server locally.
Once the server is running, you can extact the data concerning the users and their tweets using the api : http://127.0.0.1:8000/api/v1.0/getData/
| Things done | Things to do |
|---|---|
| Connection to Twitter API (100%) | Semantic fields (80%) |
| Basic architecture (100%) | JS libraries (90 %) |
| Defining models (100%) | README.md (60%) |
| Defining Env' Variables (100%) | |
| Extracting user info (100%) | |
| Extracting old tweets (100%) | |
| Extracting latest tweets (100%) | |
| Modular code for extraction (100%) | |
| Getting all the users at once (100%) | |
| Extract new tweet (100%) | |
| Deployement on Heroku (100%) |
- Logo from graphicdesignblg
- Twitter API documentation
- Map of a Twitter Status Object, Raffi Krikorian
- Marco Bonzanini, Mining Twitter Data with Python
- Migrating Your Django Project to Heroku
- TreeTagger for the tagging, tokenization and lemmatization of french documents
This project is under GNU General Public License (Version 3, 29 June 2007). Feel free to contact us and to fork or to patch this project.