📃 Paper • 🤗 Huatuo-Lite • 🤗 huatuo_encyclopedia_qa • 🤗 knowledge_graph_qa • 🤗 huatuo_consultation_qa
中文 | English
- Huatuo-26M is currently the largest Chinese medical question-and-answer dataset. This dataset contains over 26 million high-quality medical Q&A pairs, covering various aspects such as diseases, symptoms, treatment methods, and drug information.
- Huatuo-Lite is a refined and optimized dataset based on Huatuo-26M, having undergone multiple purifications and rewrites. It features more data dimensions and higher data quality.
The Huatuo-26M dataset is collected and integrated from multiple sources, including:
- Online Medical Encyclopedia huatuo_encyclopedia_qa
- Online Medical Knowledge Bases huatuo_knowledge_graph_qa
- Online Medical Consultation Records(answer in the form of URLs) huatuo_consultation_qa
- Streamlined version Huatuo-Lite
Each question-answer pair in the dataset contains the following fields:
- questions:Problem Description
- answers:Doctor/Expert Answers
- Huatuo-Lite dataset also includes Hospital Department and Related Diseases fields
The following is the huatuo test set we used in the paper, which consists of random sampling of data from multiple sources.
- Testdatasets:huatuo26M-testdatasets
The Huatuo-26M dataset can be used for a variety of AI research and applications in the medical field, such as:
- Natural Language Processing: Including but not limited to Q&A systems, text classification, sentiment analysis, etc.
- Machine Learning model training: Such as disease prediction, personalized treatment recommendation, etc.
- AI applications in the medical field: Such as intelligent diagnosis systems, medical consultation chatbots, etc.
To start using the Huatuo-26M dataset, you can follow the steps below:
import datasets
# part 1
knowledge_graph_dataset = datasets.load_dataset('FreedomIntelligence/huatuo_knowledge_graph_qa')
# part 2
encyclopedia_dataset = datasets.load_dataset('FreedomIntelligence/huatuo_encyclopedia_qa')
# part 3 (only url)
consultation_dataset = datasets.load_dataset('FreedomIntelligence/huatuo_consultation_qa')
# testdatasets (6k)
huatuo_testdatasets = datasets.load_dataset('FreedomIntelligence/huatuo26M-testdatasets')-
Retrieval Evaluation:
Click to expand
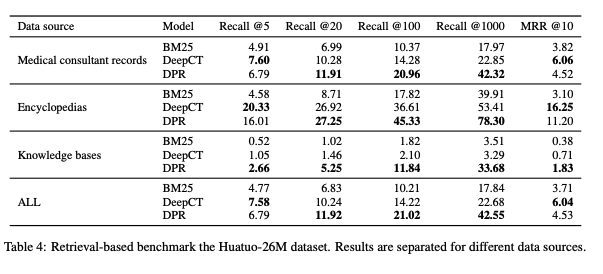
-
Answer Generation Evaluation:
Click to expand
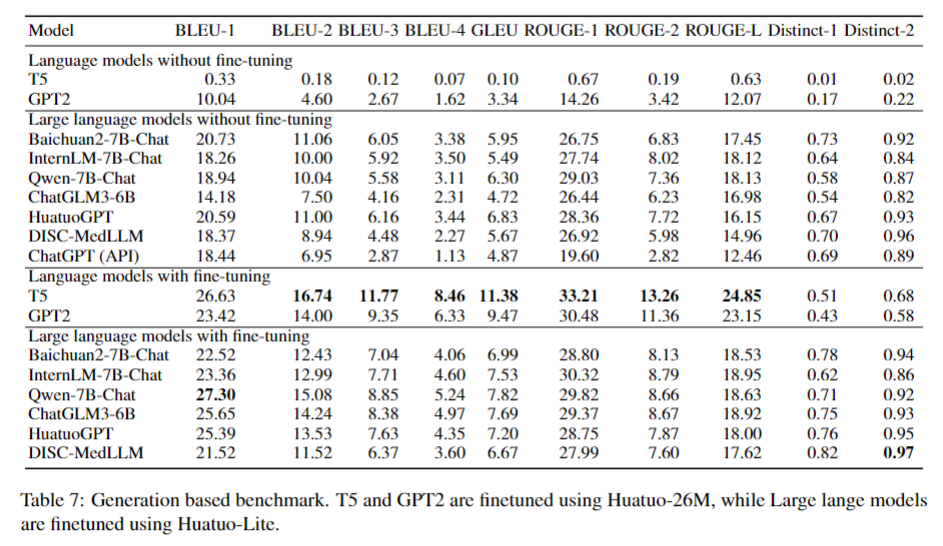


-
Zero-shot transfer to other QA datasets:
Click to expand
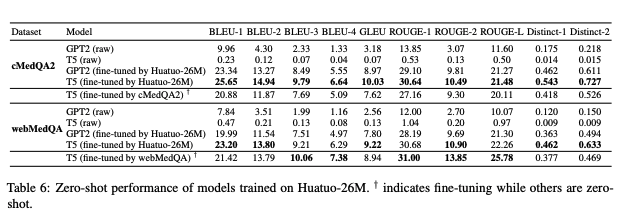
-
As external knowledge for RAG:
Click to expand
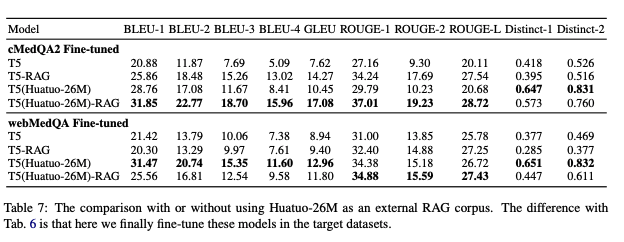
-
As pre-training data for language model (LM):
Click to expand
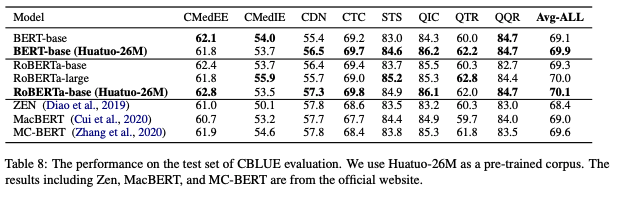
-
As fine-tuning data for Medical LLM:
Click to expand
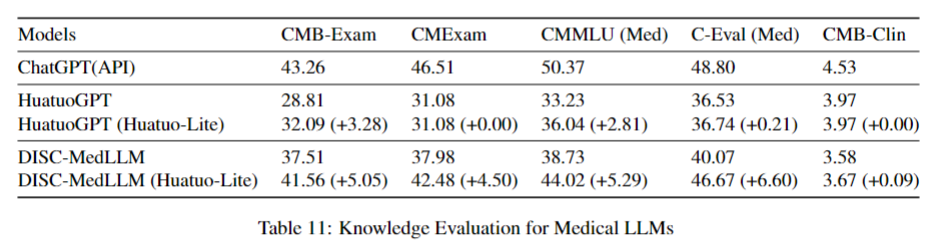




The Huatuo-26M dataset is licensed under Apache 2.0. Please make sure you have read and agreed to the license terms before using it.
If you have any questions or need help, please feel free to ask us via email (xidongw@163.com)or in the Issues section.
@misc{li2023huatuo26m,
title={Huatuo-26M, a Large-scale Chinese Medical QA Dataset},
author={Jianquan Li and Xidong Wang and Xiangbo Wu and Zhiyi Zhang and Xiaolong Xu and Jie Fu and Prayag Tiwari and Xiang Wan and Benyou Wang},
year={2023},
eprint={2305.01526},
archivePrefix={arXiv},
primaryClass={cs.CL}
}