This is an early preview
High-quality Neural Networks built with reusable blocks in PyTorch

Photo by Ryan Quintal on Unsplash
This library aims to create new components to make developing and writing neural networks faster and easier.
You can install using pip
pip install git+https://github.com/FrancescoSaverioZuppichini/torchlego%load_ext autoreload
%autoreload 2It follows a list of useful small components made to increase your code readability and development. Just like lego, when combined, they can become anything!
Most of the times you will use
from torchlego import conv3x3
conv3x3(32, 64)Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))

from torchlego import conv3x3_bn
conv3x3_bn(32, 64)Sequential( (0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1)) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) )

from torchlego import conv3x3_bn_act
conv3x3_bn_act(32, 64)Sequential( (0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1)) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU() )

Optionally, you can always pass your activation function
from torch.nn import SELU
conv3x3_bn_act(32, 64, act=SELU)Sequential( (0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1)) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): SELU() )
Also, we have conv1x1
from torchlego.blocks import conv1x1
conv1x1(32, 64)Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1))
Many times we need to pass an input to multiple modules and do something with the results. This is went InputForward comes in handy! aggr_func takes as input a list where each entry is the output from one of the modules
import torch
from torchlego.blocks import InputForward, Lambda
blocks = [Lambda(lambda x: x), Lambda(lambda x: x)]
InputForward(blocks, aggr_func=lambda x: torch.tensor(x).sum())(torch.tensor([1]))tensor(2)

An InputForward instance that concat the outputs
import torch
from torchlego.blocks import Cat, Lambda
blocks = [Lambda(lambda x: x), Lambda(lambda x: x)]
Cat(blocks)(torch.tensor([1]))tensor([1, 1])

Redisual connections are a big thing. They probably are most know from resnet paper (even if Schmidhuber did something very similar a long time ago). You can use torchlego to easily create any residual connection that you may need.
The main building block is the Residual class. It applies a function on the input and the output of a blocks.
import torch
from torchlego.blocks import Residual, Lambda
x = torch.tensor([1])
block = Lambda(lambda x: x)
res = Residual(block, res_func=lambda x, res: x + res)
res(x)tensor([2])
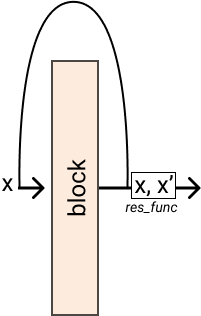
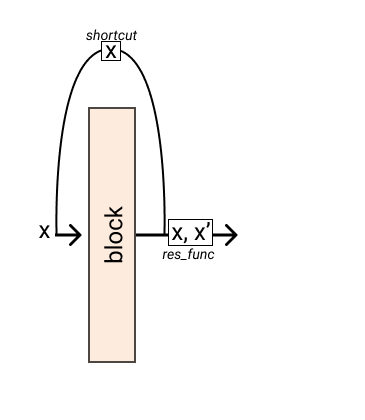
We can also apply a function on the residual, this operation is called shortcut.
res = Residual(block, res_func=lambda x, res: x + res, shortcut=lambda x: x * 2)
res(x)tensor([3])
You can also not pass the .res_func, in that case, the residual will be passed as the second parameter to the blocks.
If you pass an array of nn.ModuleList, we assume you want to pass residual through each respective layer. In the following example, all the A layers just compute input + 1 the input while the B layers add the residual with the current input. Notice that the B.forward function takes as second argument the residual.
import torch.nn as nn
<<<<<<< Updated upstream
class A(nn.Module):
def forward(self, x):
return x + 1
class B(nn.Module):
def forward(self, x, res):
return x + res
=======
class A(nn.ModuleList):
def forward(self, x):
return x + 1
class B(nn.ModuleList):
def forward(self, x, res):
return x + res
>>>>>>> Stashed changes
down = nn.ModuleList([A(), A()])
up = nn.ModuleList([B(), B()])
res = Residual([down, up])
res(x)tensor([8])

Be aware that only the first n residuals will be passed, where n is the len of the second blocks. I know, it sounds confusing, but let's see an example.
import torch.nn as nn
<<<<<<< Updated upstream
class B(nn.Module):
def forward(self, x, res = None):
x = x if res is None else x + res
return x
=======
class B(nn.ModuleList):
def forward(self, x, res = None):
x = x if res is None else x + res
return x
>>>>>>> Stashed changes
down = nn.ModuleList([A(), A()])
up = nn.ModuleList([B()])
res = Residual([down, up])
res(x)tensor([5])

torchlego comes with a useful ResidualAdd block that is just a Residual that performs automatically addition
import torch
from torchlego.blocks import ResidualAdd, Lambda
layer = ResidualAdd([Lambda(lambda x: x)])
layer(torch.tensor([1]))tensor([2])
A more complete example
import torch.nn as nn
from torchlego.blocks import ResidualAdd
x = torch.rand((1, 64, 8, 8))
block = nn.Sequential(conv3x3_bn_act(64, 64, padding=1))
layer = ResidualAdd([block])
x = layer(x)
You can pass multiple blocks
from torchlego.blocks import ResidualAdd, Lambda
blocks = [Lambda(lambda x: x), Lambda(lambda x: x)]
layer = ResidualAdd(blocks)
layer(torch.tensor(1))tensor(4)

Let's create a basic ResNet block
from torchlego.blocks import conv_bn
def resnet_basic_block(in_features, out_features):
shortbut = conv_bn(in_features, out_features, kernel_size=1, stride=2, bias=False) if in_features != out_features else nn.Identity()
stride = 2 if in_features != out_features else 1
return nn.Sequential(
ResidualAdd(nn.ModuleList([
nn.Sequential(
conv3x3_bn_act(in_features, out_features, stride=stride, padding=1, bias=False),
conv3x3_bn(out_features, out_features, padding=1, bias=False))]),
shortcut=shortbut),
nn.ReLU())
resnet_basic_block(32, 64)Sequential( (0): Residual( (blocks): ModuleList( (0): Sequential( (0): Sequential( (0): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU() ) (1): Sequential( (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) ) (shortcut): Sequential( (0): Conv2d(32, 64, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): ReLU() )

What about a full resnet? Easy peasy
def resnet(in_features, n_classes, sizes):
return nn.Sequential(
nn.Conv2d(in_features, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
nn.Sequential(*[resnet_basic_block(64, 64) for _ in range(sizes[0])]),
resnet_basic_block(64, 128),
nn.Sequential(*[resnet_basic_block(128, 128) for _ in range(sizes[1] - 1)]),
resnet_basic_block(128, 256),
nn.Sequential(*[resnet_basic_block(256, 256) for _ in range(sizes[2] - 1)]),
resnet_basic_block(256, 512),
nn.Sequential(*[resnet_basic_block(512, 512) for _ in range(sizes[3] - 1)]),
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(512, n_classes)
)
x = torch.rand((1,3,224,244))
resnet34 = resnet(3, 1000, [3, 4, 6, 3])
resnet34(x).shapetorch.Size([1, 1000])
What about Unet?
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchlego.blocks import ResidualCat2d, Lambda
from torchlego.blocks import Residual, conv3x3, conv3x3_bn_act, conv1x1
down = lambda in_features, out_features: nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2),
conv3x3_bn_act(in_features, out_features, padding=1),
conv3x3_bn_act(out_features, out_features, padding=1),
)
class up(nn.Module):
def __init__(self, in_features, out_features, should_up=True, *args, **kwargs):
super().__init__()
self.up = nn.ConvTranspose2d(in_features, out_features, kernel_size=2, stride=2)
self.should_up = should_up
self.blocks =nn.Sequential(
conv3x3(out_features * 2, out_features, padding=1),
conv3x3(out_features, out_features, padding=1),
)
def forward(self, x, res):
if self.should_up: x = self.up(x)
diffX = x.size()[2] - res.size()[2]
diffY = x.size()[3] - res.size()[3]
pad = (diffX // 2, int(diffX / 2), diffY // 2, int(diffY / 2))
res = F.pad(res, pad)
x = torch.cat([res, x], dim=1)
out = self.blocks(x)
return out
unet = nn.Sequential(
Residual([
nn.ModuleList([
nn.Sequential(
conv3x3_bn_act(3, 64),
conv3x3_bn_act(64, 64)),
down(64, 128),
down(128, 256),
down(256, 512),
down(512, 1024),
]),
nn.ModuleList([
up(512 * 2, 512),
up(256 * 2, 256),
up(128 * 2, 128),
up(64 * 2, 64),
])
]),
conv1x1(64, 2)
)
x = torch.rand((1,3,256,256))
unet(x)<<<<<<< Updated upstream tensor([[[[ 0.1703, 0.1333, 0.1065, ..., 0.0960, 0.0289, 0.2440], [ 0.0541, 0.1370, -0.0009, ..., -0.0234, 0.1766, 0.1227], [ 0.0071, 0.0103, -0.0728, ..., -0.0840, 0.0448, 0.0931], ..., [ 0.0387, 0.0116, 0.1317, ..., 0.0861, 0.0679, 0.1378], [ 0.0253, 0.0583, -0.0304, ..., -0.0590, -0.0112, 0.0985], [ 0.1501, 0.1165, 0.0767, ..., 0.0516, 0.0438, 0.0853]],
[[ 0.0734, 0.1631, -0.0388, ..., -0.0313, -0.0182, -0.0158],
[ 0.0150, -0.0157, -0.1313, ..., 0.0417, -0.0827, 0.0312],
[-0.0783, -0.1002, -0.0104, ..., -0.0625, 0.1027, -0.0133],
...,
[-0.0326, -0.0716, -0.0284, ..., -0.0891, -0.0317, -0.0103],
[ 0.1046, -0.0530, -0.0447, ..., 0.0813, -0.0651, 0.0246],
[-0.0351, 0.0342, -0.0398, ..., -0.0206, -0.0515, 0.0425]]]],
grad_fn=<ThnnConv2DBackward>)
======= tensor([[[[ 8.8137e-02, 3.6018e-02, 3.6493e-02, ..., -8.1409e-02, -1.0382e-01, -3.2821e-02], [-6.6964e-02, -2.5947e-02, 6.4162e-02, ..., 1.5033e-01, -7.9811e-02, -1.8225e-02], [ 1.4054e-01, -1.9263e-02, -7.7571e-02, ..., -7.0426e-03, -1.0605e-01, -1.3636e-01], ..., [ 7.7351e-02, -1.5599e-02, 1.2618e-01, ..., 2.8263e-02, 3.2247e-02, 2.6603e-02], [ 9.9938e-02, -1.0595e-01, -5.5370e-02, ..., 5.1364e-03, 1.1270e-01, -7.0449e-02], [ 1.1673e-01, 1.1466e-01, 9.6519e-02, ..., 2.0525e-01, -4.1448e-03, -1.7874e-04]],
[[-1.1501e-01, -7.1215e-02, -9.0835e-02, ..., 2.8257e-02, -9.3994e-02, -5.7923e-02], [-5.4163e-02, -9.5989e-02, 1.5962e-02, ..., -6.1023e-02, -1.2532e-01, -1.2940e-01], [ 9.8738e-02, -4.5944e-02, -9.7948e-02, ..., -6.3290e-02, -1.7416e-01, -7.3600e-02], ..., [-3.4967e-02, -4.3565e-02, -6.5006e-02, ..., -8.8919e-02, -1.3443e-01, -1.8066e-01], [-2.2645e-02, -7.6100e-02, -1.3066e-01, ..., -5.9316e-02, -1.9493e-01, -1.1370e-01], [-3.7421e-02, -7.6370e-02, -1.0176e-01, ..., -2.0086e-01, -1.5869e-01, -9.6589e-02]]]], grad_fn=)
Stashed changes