Deep learning library, implemented from scratch in numpy for fun.
- Tensor-based autograd
- Object-oriented PyTorch-like API
- Layers: multihead/rotary/grouped-query attention with KV caching, batch/layer/RMS norm, conv2d, max/avg pooling, dropout
- NLP: byte-pair encoding, SentencePiece enc/dec, LoRA fine-tuning, top-k/nucleus/beam search, speculative sampling, chat templates (Llama chat, ChatML), streaming chat UI
- Models: Mixtral, Mamba, Llama, GPT, ResNet
- Lightweight Tensorboard-like dashboarding
- Chat with Mixtral 8x7B 🌅 (notebook) (model)
(Mixtral 8x7B-instruct, video sped up 30x) - LoRA fine-tuning Llama on my Messenger chats (notebook)
- Chat with Mamba 🐍 (notebook) (model)
- Chat with Llama 🦙 (notebook) (model)
(Llama 13B-chat, video sped up 30x) - Chat with GPT2 (notebook) (model)
- Universal and Transferable Adversarial Attacks on Aligned Language Models (Zou et al. 2023) repro (notebook)
- Speculative sampling experiments (notebook)
- KV-caching speedup and memory (notebook)
- Beam search, top-p, top-k sampling quality (notebook)


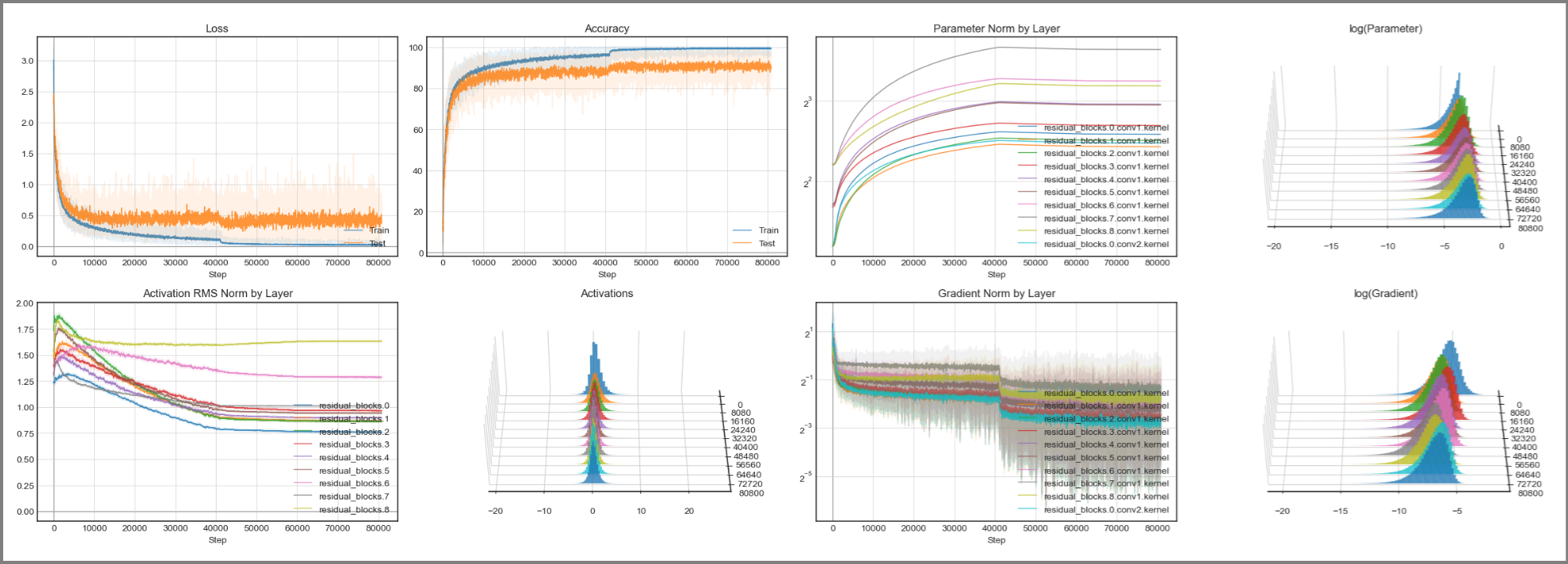
- Training ResNet20 on CIFAR10 (notebook)

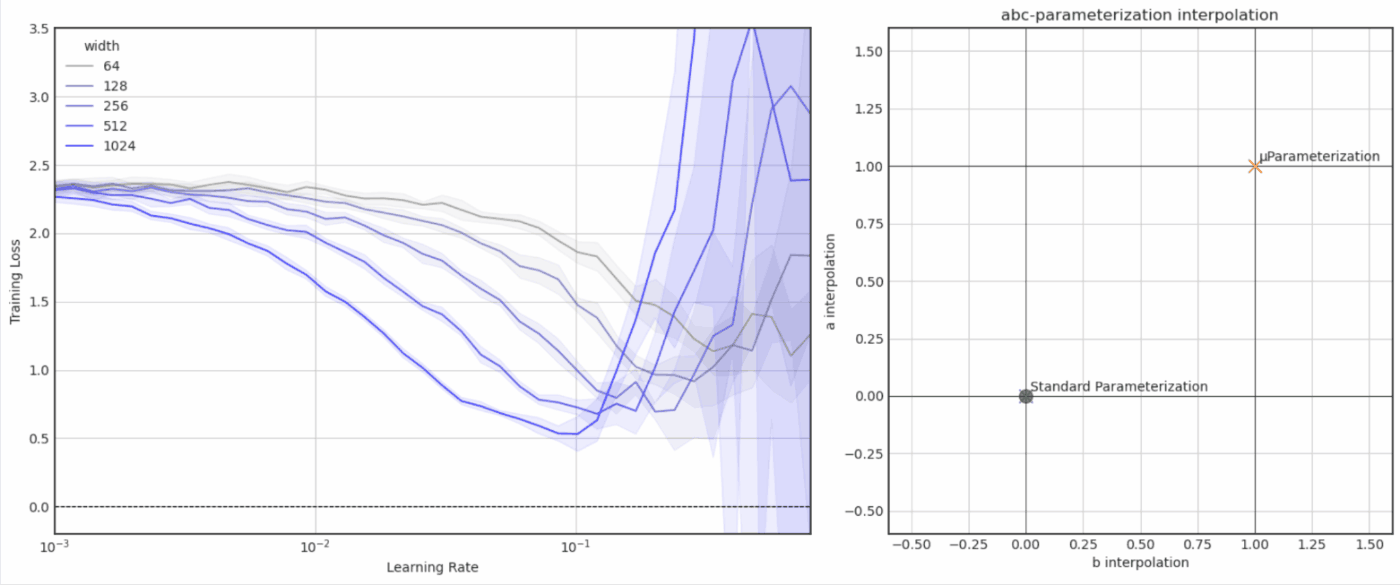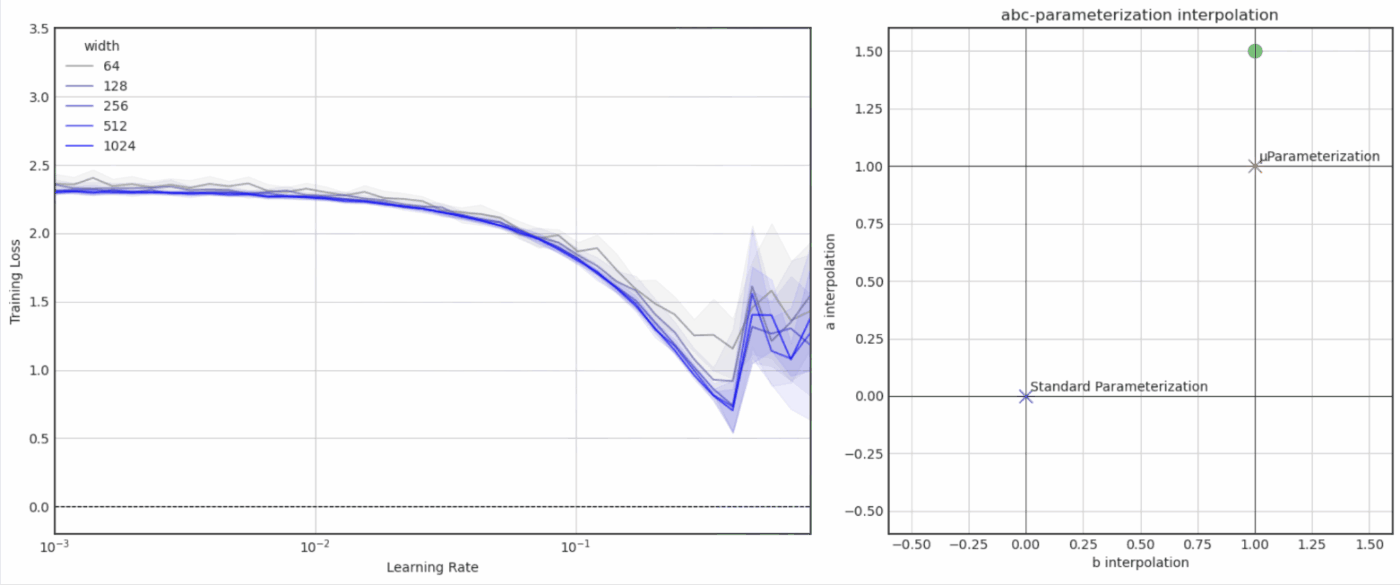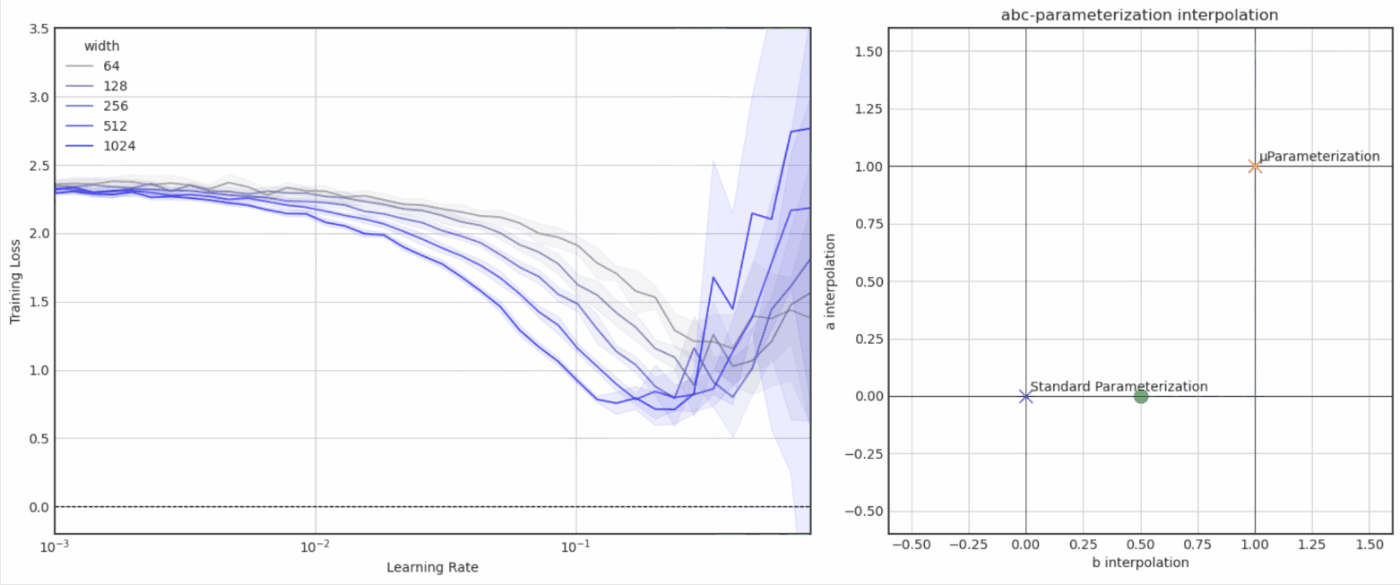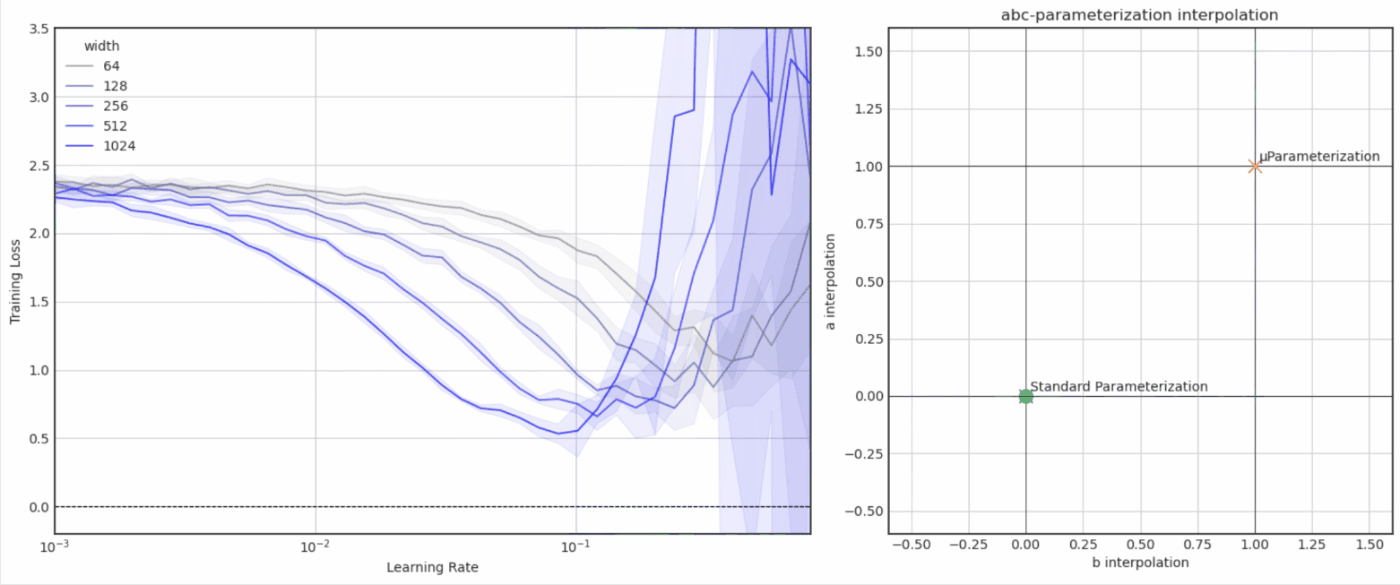
- Experiments with μParameterization / μTransfer (notebook)
- Experiments with Neural Tangent Kernels (notebook)
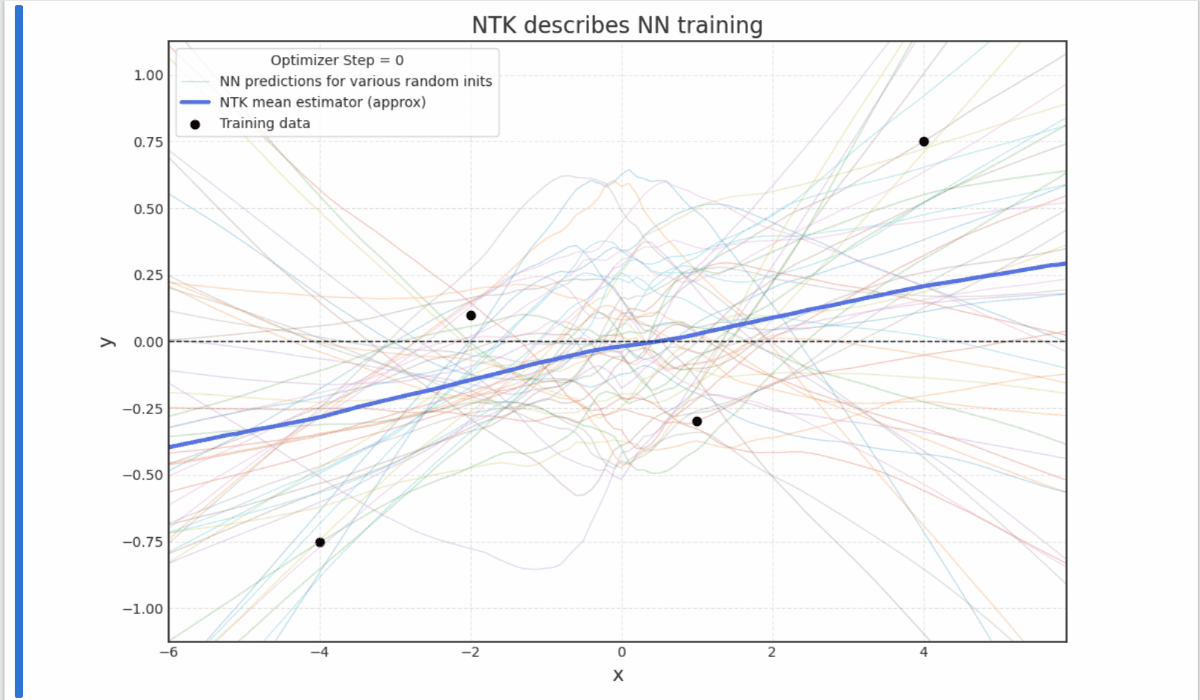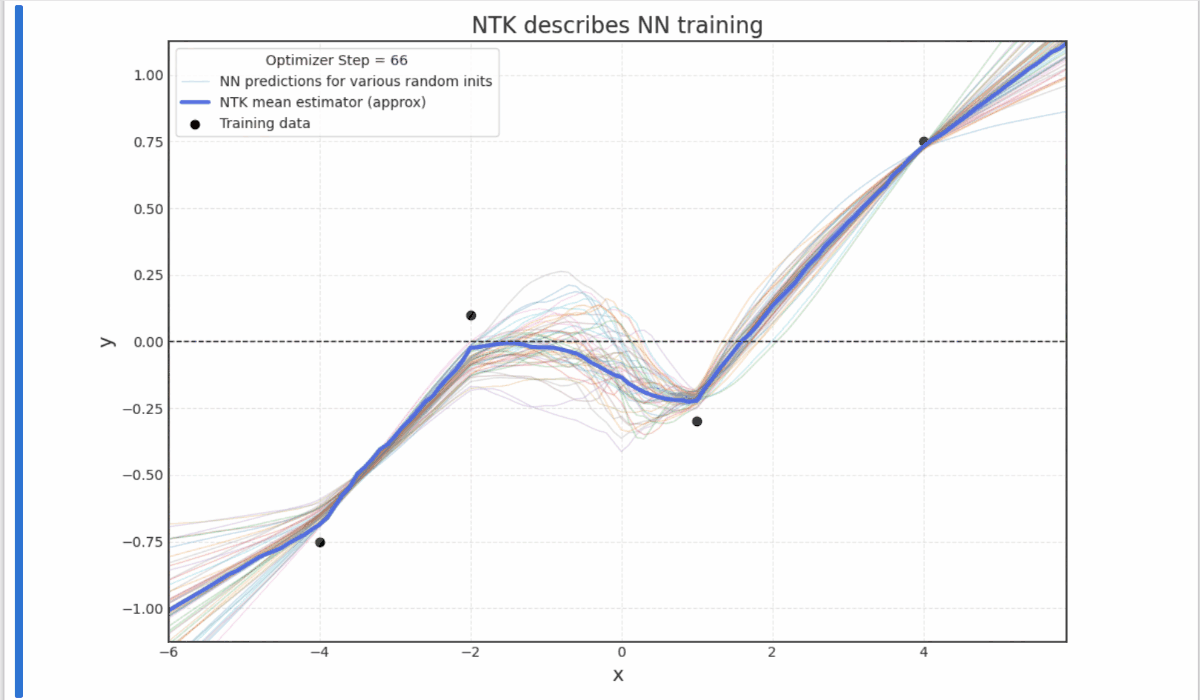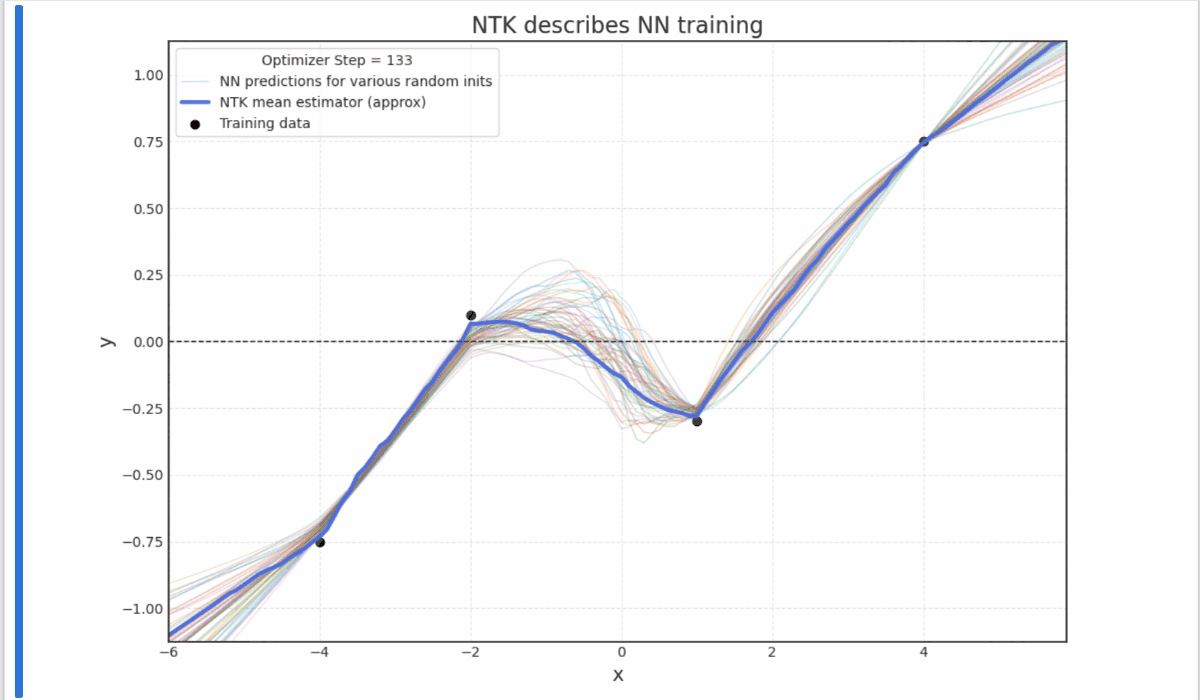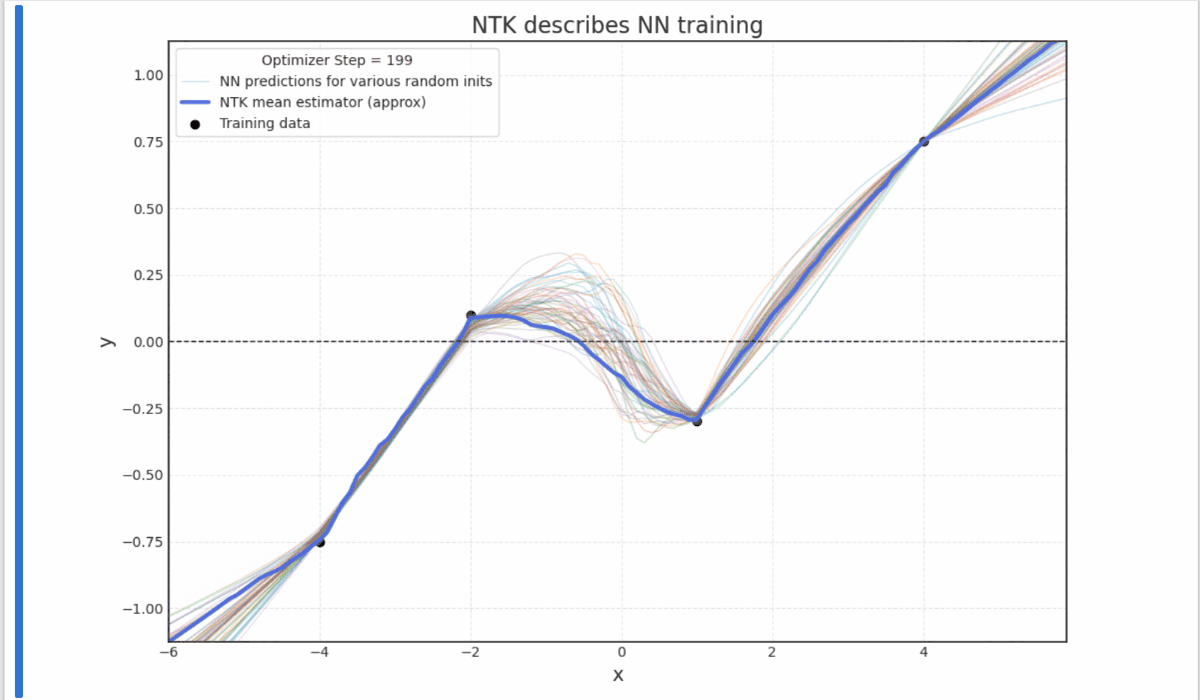


- Grokking: Generalization Beyond Overfitting (Power et al. 2016) reproduction (notebook)
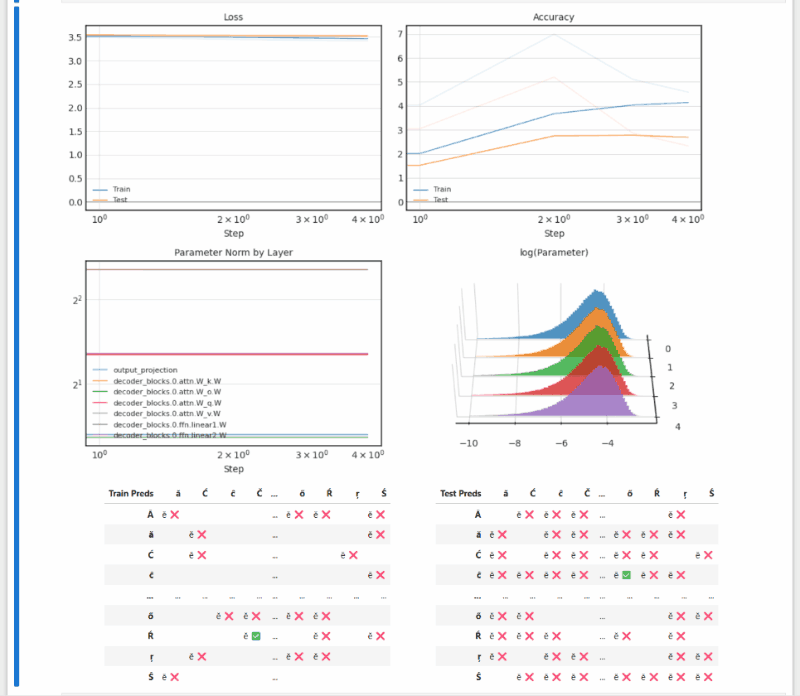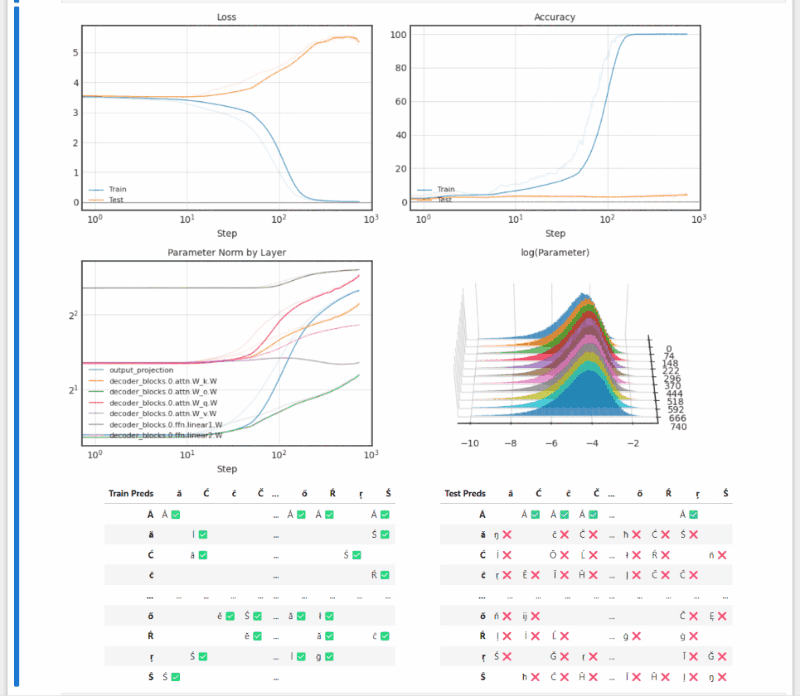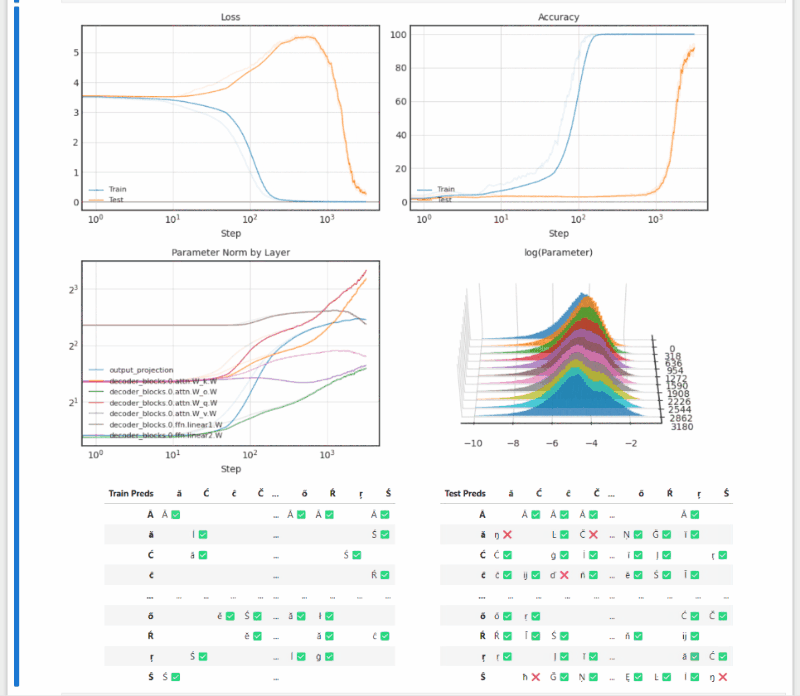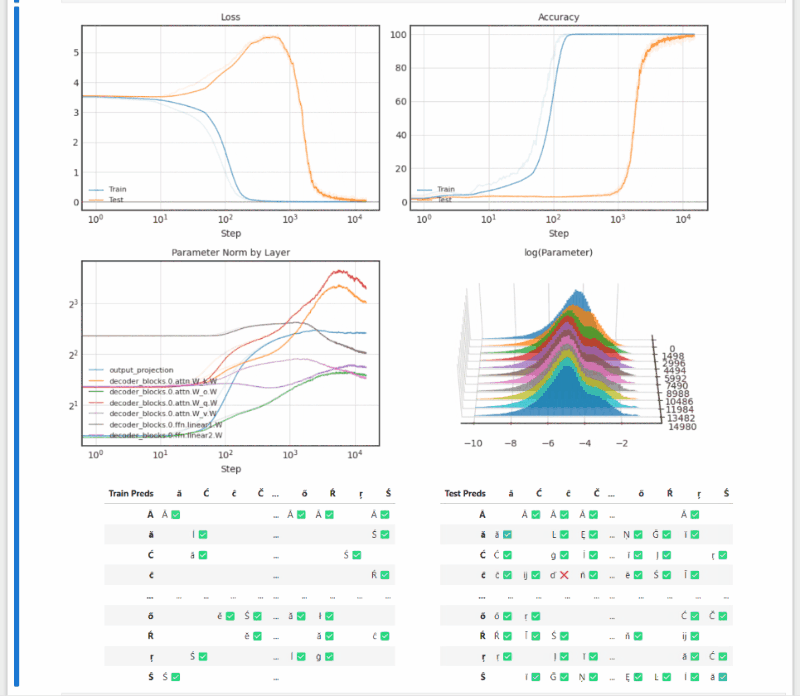
(long after overfitting, test accuracy suddenly begins increasing — a fun result that feels surprising at first)

import numpy as np
import candle
import candle.functions as F
from candle import Module, Tensor
class GPT(Module):
def __init__(self,
n_layers: int,
n_heads: int,
embed_dim: int,
vocab_size: int,
block_size: int,
dropout_p: float):
super().__init__()
self.n_layers = n_layers
self.embed_dim = embed_dim
self.block_size = block_size
self.dropout = candle.Dropout(dropout_p)
self.word_embeddings = candle.Embedding(vocab_size, embed_dim)
self.position_embeddings = candle.Embedding(block_size, embed_dim)
self.decoder_blocks = candle.ParameterList([DecoderBlock(embed_dim, n_heads, dropout_p)
for _ in range(n_layers)])
self.layer_norm = candle.LayerNorm(embed_dim)
# Tie output projection weights to word embeddings. See "Weight Tying" paper.
self.output_projection = self.word_embeddings.embeddings
def forward(self,
indices: Tensor,
use_kv_cache: bool = False):
offset = self.get_kv_cache_seqlen() if use_kv_cache else 0
position_indices = Tensor(np.arange(indices.shape[1]) + offset)
x = self.word_embeddings(indices) + self.position_embeddings(position_indices)
x = self.dropout(x) # shape (batch, seqlen, embed_dim)
for decoder_block in self.decoder_blocks:
x = decoder_block(x, use_kv_cache)
x = self.layer_norm(x)
return x @ self.output_projection.T
def get_kv_cache_seqlen(self):
"""Gets KV cache seqlen."""
return self.decoder_blocks[0].attn.get_kv_cache_seqlen()
class DecoderBlock(Module):
def __init__(self,
embed_dim: int,
n_heads: int,
dropout_p: float):
super().__init__()
self.dropout = candle.Dropout(dropout_p)
self.ln1 = candle.LayerNorm(embed_dim)
self.attn = candle.MultiheadAttention(embed_dim, n_heads, dropout_p, batch_first=True)
self.ln2 = candle.LayerNorm(embed_dim)
self.ffn = FeedForwardBlock(input_dim=embed_dim, hidden_dim=4 * embed_dim)
def forward(self,
x: Tensor,
use_kv_cache: bool):
# x: Tensor with shape (batch, seqlen, embed_dim)
x = x + self.dropout(self.self_attn(self.ln1(x), use_kv_cache))
x = x + self.dropout(self.ffn(self.ln2(x)))
return x
def self_attn(self,
x: Tensor,
use_kv_cache: bool):
"""Self-attention with causal mask."""
# causal_attn_mask[i, j] = 0 means that query[i] attends to key[j], and so
# causal_attn_mask[i, j] = 0 if i >= j and 1 otherwise.
causal_attn_mask = Tensor(1 - np.tri(x.shape[1]))
(attn_output, attn_scores) = self.attn(x, x, x,
attn_mask=causal_attn_mask,
use_kv_cache=use_kv_cache)
return attn_output
class FeedForwardBlock(Module):
def __init__(self,
input_dim: int,
hidden_dim: int):
super().__init__()
self.linear1 = candle.Linear(input_dim, hidden_dim)
self.linear2 = candle.Linear(hidden_dim, input_dim)
def forward(self, x):
x = self.linear1(x)
x = F.gelu(x)
x = self.linear2(x)
return xmodel = GPT(n_layers=12,
n_heads=12,
embed_dim=768,
vocab_size=50257,
block_size=1024,
dropout_p=0.1)
tokenizer = candle.models.gpt.GPT2BPETokenizer()
indices = candle.Tensor([tokenizer.encode(
'Once upon a time, there is a cat whose name is Maukoo. He loves eating and cuddling.'
)])
targets = indices[:, 1:]
logits = model(indices[:, :-1])
loss = F.cross_entropy_loss(logits, targets)
loss.backward()model = candle.models.gpt.GPT.from_pretrained('gpt2-large')
with candle.no_grad():
generator = candle.nlp.beam_search_decoder(model, indices[0],
n_tokens_to_generate=50,
beam_size=1,
top_p=0.90,
top_k=100,
use_kv_cache=True)
response_indices = np.concatenate(list(generator))
print(tokenizer.decode(response_indices))
# Output: A lot. He also loves drinking. (But it's an odd habit for a cat that loves eating
# and cuddling.) This little kitty is not the sort of kitty you would expect to be a