![]()
News 🔥
- [2024/1] Medusa technical report is now available on arXiv. We've added multiple new features, including Medusa-2 recipe for full-model training, self-distillation for adding Medusa to any fine-tuned LLM, etc. The new results show a 2.2-3.6x speedup over the original model on a range of LLMs.
Medusa is a simple framework that democratizes the acceleration techniques for LLM generation with multiple decoding heads.
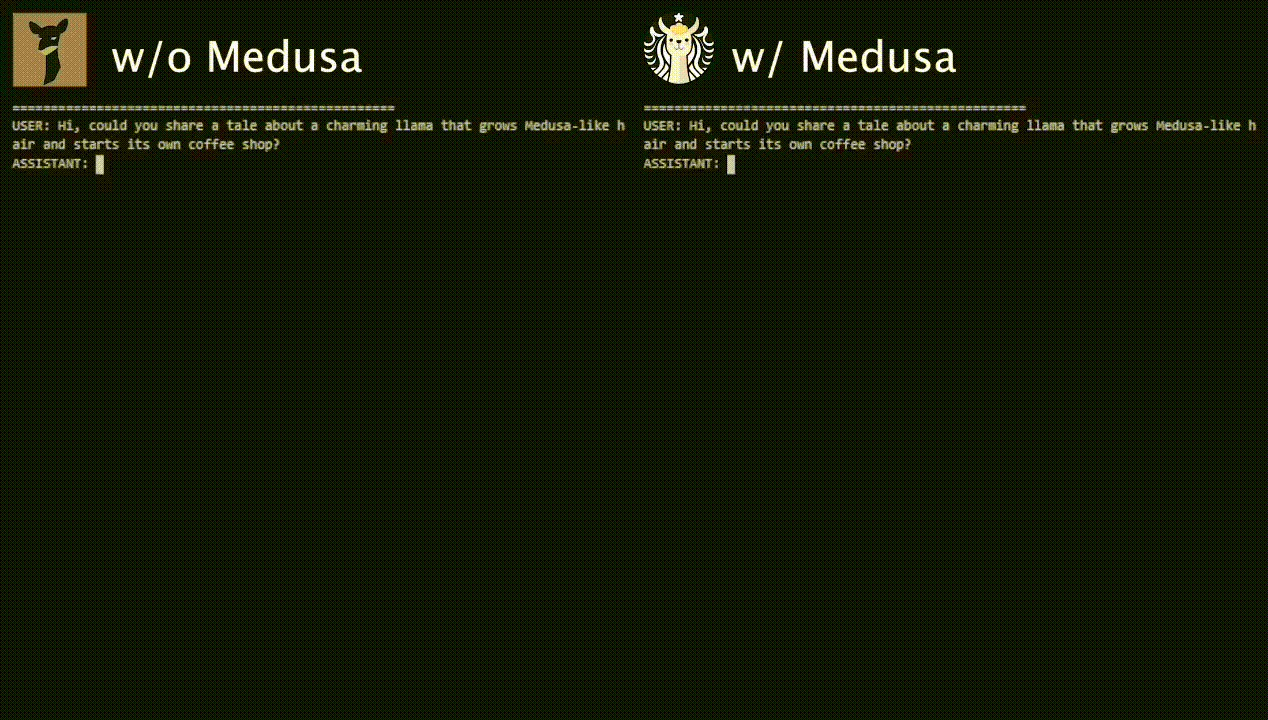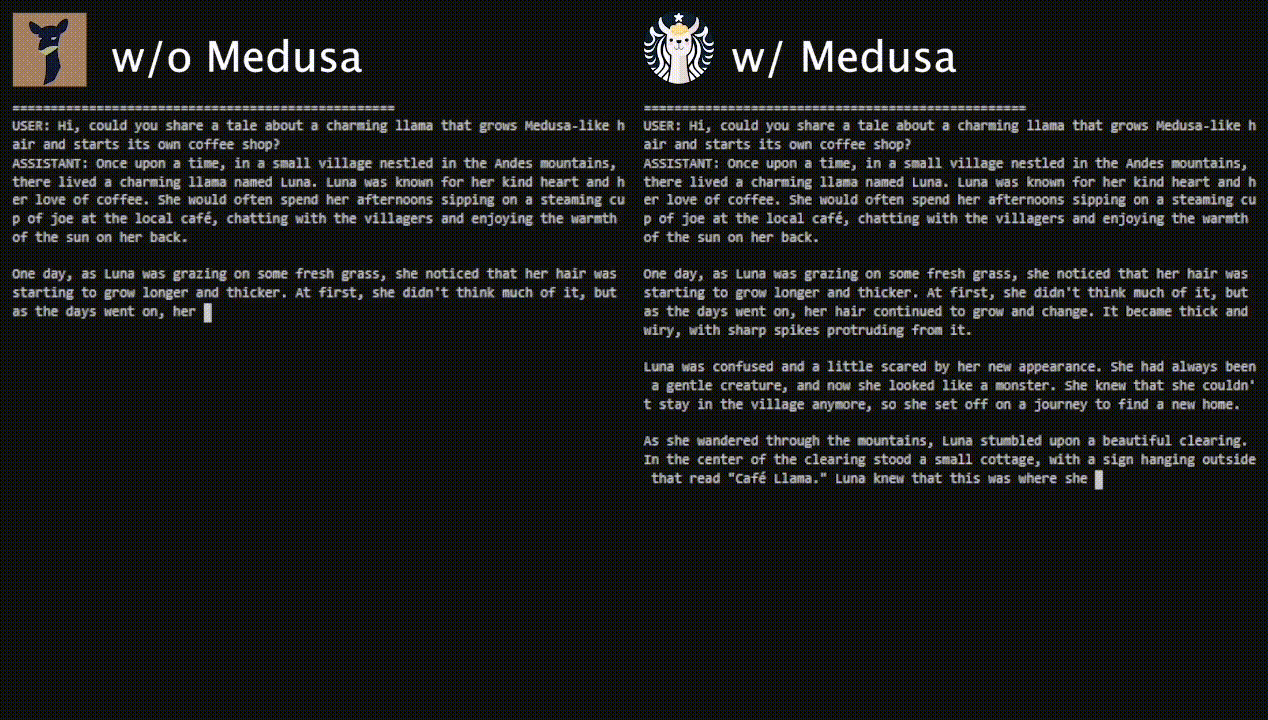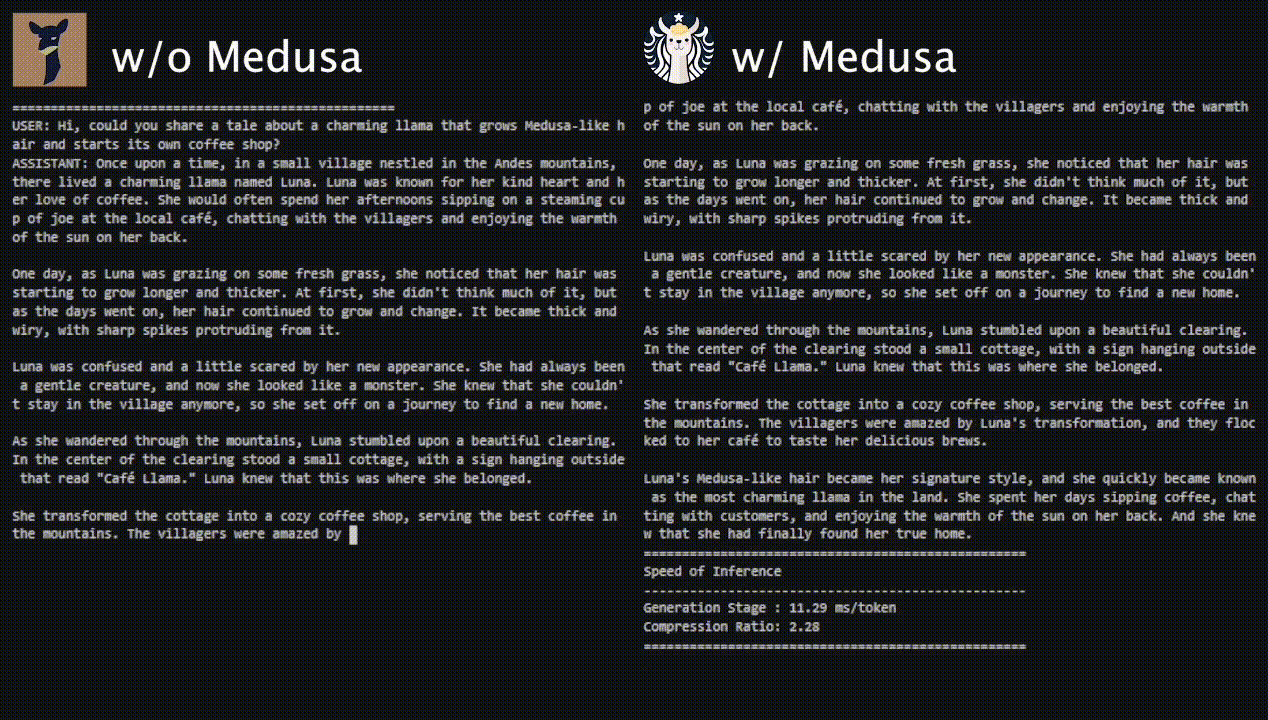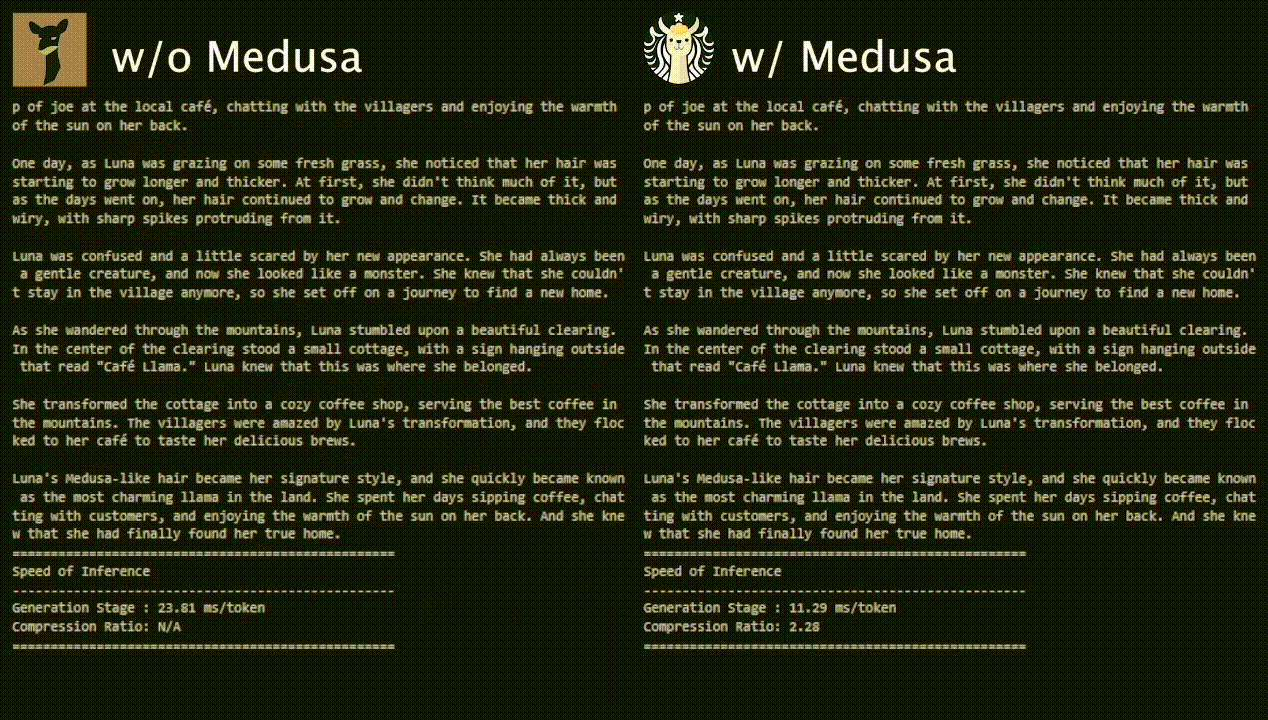
We aim to tackle the three pain points of popular acceleration techniques like speculative decoding:
- Requirement of a good draft model.
- System complexity.
- Inefficiency when using sampling-based generation.
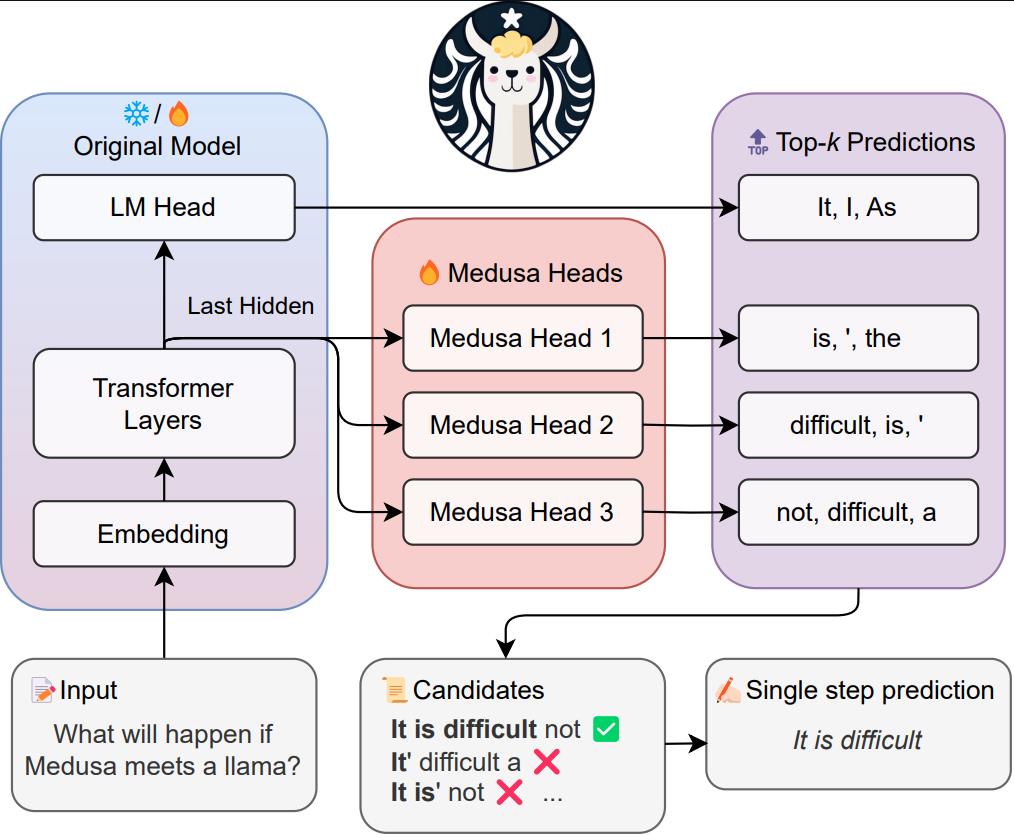
We aim to solve the challenges associated with speculative decoding by implementing the following ideas:
- Instead of introducing a new model, we train multiple decoding heads on the same model.
- The training is parameter-efficient so that even the "GPU-Poor" can do it. And since there is no additional model, there is no need to adjust the distributed computing setup.
- Relaxing the requirement of matching the distribution of the original model makes the non-greedy generation even faster than greedy decoding.
In the initial release, our primary focus is on optimizing Medusa for a batch size of 1—a setting commonly utilized for local model hosting. In this configuration, Medusa delivers approximately a 2x speed increase across a range of Vicuna models. We are actively working to extend Medusa's capabilities by integrating it into additional inference frameworks, with the aim of achieving even greater performance gains and extending Medusa to broader settings.
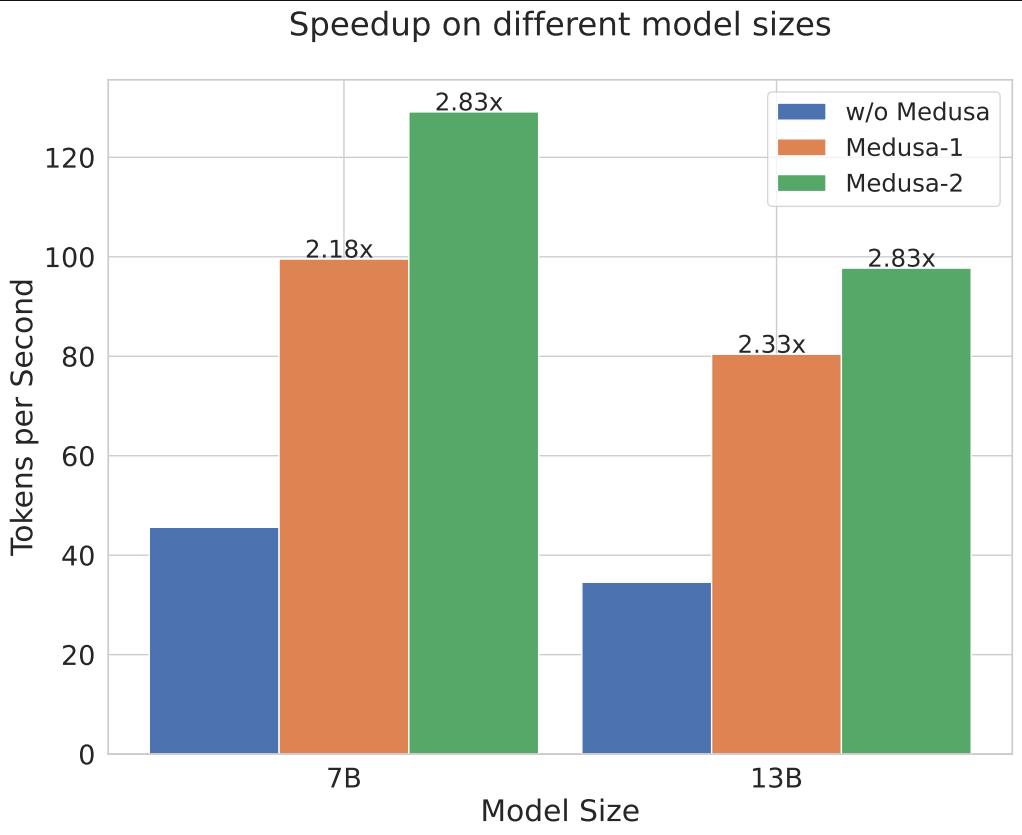
In the updated version, we add support for full-model training, called Medusa-2 (compared to Medusa-1, which only trains the new heads), which requires a special recipe that adds the speculative prediction ability while keeping the original model's performance.
We also add support for self-distillation, which allows us to add Medusa to any fine-tuned LLM without requiring the availability of the original training data.
- Introduction
- Contents
- Installation
- Citation
- Codebase Guide
- Community Adoption
- Contributing
- Acknowledgements
pip install medusa-llmgit clone https://github.com/FasterDecoding/Medusa.git
cd Medusa
pip install -e .| Size | Chat Command | Hugging Face Repo |
|---|---|---|
| 7B | python -m medusa.inference.cli --model FasterDecoding/medusa-vicuna-7b-v1.3 |
FasterDecoding/medusa-vicuna-7b-v1.3 |
| 13B | python -m medusa.inference.cli --model FasterDecoding/medusa-vicuna-13b-v1.3 |
FasterDecoding/medusa-vicuna-13b-v1.3 |
| 33B | python -m medusa.inference.cli --model FasterDecoding/medusa-vicuna-33b-v1.3 |
FasterDecoding/medusa-vicuna-33b-v1.3 |
| Size | Chat Command | Hugging Face Repo |
|---|---|---|
| Zephyr-7B-Beta | python -m medusa.inference.cli --model FasterDecoding/medusa-1.0-zephyr-7b-beta |
FasterDecoding/medusa-1.0-zephyr-7b-beta |
| Vicuna-7B-v1.5 | python -m medusa.inference.cli --model FasterDecoding/medusa-1.0-vicuna-7b-v1.5 |
FasterDecoding/medusa-1.0-vicuna-7b-v1.5 |
| Vicuna-13B-v1.5 | python -m medusa.inference.cli --model FasterDecoding/medusa-1.0-vicuna-13b-v1.5 |
FasterDecoding/medusa-1.0-vicuna-13b-v1.5 |
| Vicuna-33B-v1.5 | python -m medusa.inference.cli --model FasterDecoding/medusa-1.0-vicuna-33b-v1.5 |
FasterDecoding/medusa-1.0-vicuna-33b-v1.5 |
We currently support single-GPU inference with a batch size of 1, which is the most common setup for local model hosting. We are actively working to extend Medusa's capabilities by integrating it into other inference frameworks; please don't hesitate to reach out if you are interested in contributing to this effort.
You can use the following command to launch a CLI interface:
CUDA_VISIBLE_DEVICES=0 python -m medusa.inference.cli --model [path of medusa model]You can also pass --load-in-8bit or --load-in-4bit to load the base model in quantized format. If you download the base model elsewhere, you may override base model name or path with --base-model [path of base model].
In the updated version, we use the amazing axolotl library to manage the training process. Please refer to our fork for the training code. The major code modifications are in src/axolotl/utils/models.py. The training configs can be found in examples/medusa. A typical training command is as follows:
accelerate launch -m axolotl.cli.train examples/medusa/your_config.ymlThe data preparation code for self-distillation can be found in data_generation folder of the current repo. For other datasets, you can directly download the data from the corresponding Hugging Face dataset repo.
The following instructions are for the initial release of Medusa, it provides a minimal example of how to train a Medusa-1 model. For the updated version, please refer to the previous section.
For training, please install:
pip install -e ".[train]"We take a public version of the ShareGPT dataset, which is a subset of the Vicuna training data. For other models, you can use the corresponding training dataset.
git clone https://huggingface.co/datasets/Aeala/ShareGPT_Vicuna_unfilteredRemark: If you haven't installed git-lfs, please install it before cloning:
git lfs installStart by launch an inference server you like that will run the model you want to train on. Let's use mistralai/Mistral-7B-Instruct-v0.2 as an example.
For instance you can use text-generation-inference, which you can also use after you've trained the medusa heads.
model=mistralai/Mistral-7B-Instruct-v0.2
volume=$PWD/data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:latest --model-id $model --input-length 4000 --max-total-tokens 4096 --max-batch-prefill-tokens 4000
The sequences in shareGPT are relatively long for some, so make sure you can infer on those. If you do not have enough room, the script will simply ignore those long conversation. It shouldn't impact too much downstream performance, but more data is always better. You can use various tradeoffs to speed up inference but the defaults show be good enough in most cases.
python create_data.py --input-filename ShareGPT_Vicuna_unfiltered/ShareGPT_V4.3_unfiltered_cleaned_split.json --output-filename mistral.json
We follow the training setup from FastChat, but with a much larger learning rate because we freeze the original model and only train the new heads. Here is the training command for the Vicuna-7b model on 4 GPUs. Since we are only training the new heads, the training does not require a lot of memory, and only data parallelism is needed. You can modify the script to fit your own setup. For larger models, we use the same setup. You can also use --load_in_8bit or --load_in_4bit to load the base model in quantized format.
torchrun --nproc_per_node=4 medusa/train/train_legacy.py --model_name_or_path mistralai/Mistral-7B-Instruct-v0.2 \
--data_path mistral.json \
--bf16 True \
--output_dir test \
--num_train_epochs 2 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--gradient_accumulation_steps 4 \
--evaluation_strategy "no" \
--save_strategy "no" \
--learning_rate 1e-3 \
--weight_decay 0.0 \
--warmup_ratio 0.1 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--tf32 True \
--model_max_length 2048 \
--lazy_preprocess True \
--medusa_num_heads 3 \
--medusa_num_layers 1 \
--deepspeed deepspeed.jsonYou can use the following command to push your model to the Hugging Face Hub:
python -m medusa.hf_utils --folder [path of the model folder] --repo [name of the repo]@article{cai2024medusa,
title = {Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads},
author = {Tianle Cai and Yuhong Li and Zhengyang Geng and Hongwu Peng and Jason D. Lee and Deming Chen and Tri Dao},
year = {2024},
journal = {arXiv preprint arXiv: 2401.10774}
}medusa/model/medusa_model.py is the key file for Medusa. It contains the MedusaModel class, which is a wrapper of the original model and the new heads. This class also has an implementation of a streaming generation method. If you want to dive into the details of Medusa, this is the place to start.
We also provide some illustrative notebooks in notebooks/ to help you understand the codebase.
We are super excited to see that Medusa has been adopted by many open-source projects. Here is an (incomplete) list:
We are grateful to the authors for their contributions to the community and sincerely hope that Medusa can help accelerate the development of LLMs. If you are using Medusa in your project, please let us know, and we will add your project to the list.
We welcome community contributions to Medusa. If you have an idea for how to improve it, please open an issue to discuss it with us. When submitting a pull request, please ensure that your changes are well-tested. Please split each major change into a separate pull request. We also have a Roadmap summarizing our future plans for Medusa. Don't hesitate to reach out if you are interested in contributing to any of the items on the roadmap.
This codebase is influenced by remarkable projects from the LLM community, including FastChat, TinyChat, vllm, axolotl.
This project is supported by Together AI, MyShell AI, Chai AI.