import jiagu
import jieba#jiagu.init() # 可手动初始化,也可以动态初始化text = '苏州的天气不错'
words = jiagu.seg(text) # 分词
print('jiagu:',words)
print('jieba:',jieba.lcut(text))
words = jiagu.cut(text) # 分词
print(words)Building prefix dict from the default dictionary ...
jiagu: ['苏州', '的', '天气', '不错']
Dumping model to file cache C:\Users\86185\AppData\Local\Temp\jieba.cache
Loading model cost 1.324 seconds.
Prefix dict has been built succesfully.
jieb: ['苏州', '的', '天气', '不错']
['苏州', '的', '天气', '不错']
# 字典模式分词
text = '思知机器人挺好用的'
words = jiagu.seg(text)
print(words)
# jiagu.load_userdict('dict/user.dict') # 加载自定义字典,支持字典路径、字典列表形式。
jiagu.load_userdict(['思知机器人'])
words = jiagu.seg(text)
print(words)pos = jiagu.pos(words) # 词性标注
print(pos)['ns', 'u', 'n', 'a']
ner = jiagu.ner(words) # 命名实体识别
print(ner)
jiagu.ner['B-LOC', 'O', 'O', 'O']
<bound method Analyze.ner of <jiagu.analyze.Analyze object at 0x000001174FC2F3C8>>
any_0 = jiagu.any
any_0
any_0.__dict__
ner_model = any_0.__dict__['ner_model']
ner_model.__dict__
ner_averagedPerceptron = ner_model.model
ner_averagedPerceptron.__dict__.keys() #dict_keys(['weights', 'classes', '_totals', '_tstamps', 'i'])
ner_averagedPerceptrontext = """
**空调系统由一个或多个冷热源系统和多个空气调节系统组成,该系统不同于传统冷剂式空调,(如单体机,VRV) 集中处理空气以达到舒适要求。采用液体气化制冷的原理为空气调节系统提供所需冷量,用以抵消室内环境的热负荷;制热系统为空气调节系统提供所需热量,用以抵消室内环境冷暖负荷。
制冷系统是**空调系统至关重要的部分,其采用种类、运行方式、结构形式等直接影响了**空调系统在运行中的经济性、高效性、合理性。
"""
keywords = jiagu.keywords(text, 5) # 关键词抽取
print(keywords)['系统', '冷', '空气', '运行', '性']
text = '''
该研究主持者之一、波士顿大学地球与环境科学系博士陈池(音)表示,“尽管**和印度国土面积仅占全球陆地的9%,但两国为这一绿化过程贡献超过三分之一。考虑到人口过多的国家一般存在对土地过度利用的问题,这个发现令人吃惊。”
NASA埃姆斯研究中心的科学家拉玛·内曼尼(Rama Nemani)说,“这一长期数据能让我们深入分析地表绿化背后的影响因素。我们一开始以为,植被增加是由于更多二氧化碳排放,导致气候更加温暖、潮湿,适宜生长。”
“MODIS的数据让我们能在非常小的尺度上理解这一现象,我们发现人类活动也作出了贡献。”
NASA文章介绍,在**为全球绿化进程做出的贡献中,有42%来源于植树造林工程,对于减少土壤侵蚀、空气污染与气候变化发挥了作用。
据观察者网过往报道,2017年我国全国共完成造林736.2万公顷、森林抚育830.2万公顷。其中,天然林资源保护工程完成造林26万公顷,退耕还林工程完成造林91.2万公顷。京津风沙源治理工程完成造林18.5万公顷。三北及长江流域等重点防护林体系工程完成造林99.1万公顷。完成国家储备林建设任务68万公顷。
'''
summarize = jiagu.summarize(text, 3) # 文本摘要
print(summarize)['”NASA文章介绍,在**为全球绿化进程做出的贡献中,有42%来源于植树造林工程,对于减少土壤侵蚀、空气污染与气候变化发挥了作用。', '该研究主持者之一、波士顿大学地球与环境科学系博士陈池(音)表示,“尽管**和印度国土面积仅占全球陆地的9%,但两国为这一绿化过程贡献超过三分之一。', '其中,天然林资源保护工程完成造林26万公顷,退耕还林工程完成造林91.2万公顷。']
# jiagu.findword('input.txt', 'output.txt') # 根据大规模语料,利用信息熵做新词发现。# 知识图谱关系抽取
text = '姚明1980年9月12日出生于上海市徐汇区,祖籍江苏省苏州市吴江区震泽镇,前**职业篮球运动员,司职中锋,现任中职联公司董事长兼总经理。'
knowledge = jiagu.knowledge(text)
print(knowledge)[['姚明', '出生日期', '1980年9月12日'], ['姚明', '出生地', '上海市徐汇区'], ['姚明', '祖籍', '江苏省苏州市吴江区震泽镇']]
# 情感分析
text = '很讨厌还是个懒鬼'
sentiment = jiagu.sentiment(text)
print(sentiment)('negative', 0.9957030885091285)
# 文本聚类(需要调参)
docs = [
"百度深度学习中文情感分析工具Senta试用及在线测试",
"情感分析是自然语言处理里面一个热门话题",
"AI Challenger 2018 文本挖掘类竞赛相关解决方案及代码汇总",
"深度学习实践:从零开始做电影评论文本情感分析",
"BERT相关论文、文章和代码资源汇总",
"将不同长度的句子用BERT预训练模型编码,映射到一个固定长度的向量上",
"自然语言处理工具包spaCy介绍",
"现在可以快速测试一下spaCy的相关功能,我们以英文数据为例,spaCy目前主要支持英文和德文"
]
cluster = jiagu.text_cluster(docs)
print(cluster){0: ['将不同长度的句子用BERT预训练模型编码,映射到一个固定长度的向量上', '现在可以快速测试一下spaCy的相关功能,我们以英文数据为例,spaCy目前主要支持英文和德文', '自然语言处理工具包spaCy介绍', 'BERT相关论文、文章和代码资源汇总', '情感分析是自然语言处理里面一个热门话题', '百度深度学习中文情感分析工具Senta试用及在线测试'], 1: ['AI Challenger 2018 文本挖掘类竞赛相关解决方案及代码汇总'], 2: ['深度学习实践:从零开始做电影评论文本情感分析']}
参考:https://www.jianshu.com/p/caef1926adf7 https://blog.csdn.net/qll125596718/article/details/8243404/ https://zhuanlan.zhihu.com/p/88747614
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集成为一个“簇”。通过这样的划分,每个簇可能对应于一些潜在的概念(也就是类别),如“浅色瓜” “深色瓜”,“有籽瓜” “无籽瓜”,甚至“本地瓜” “外地瓜”等;需说明的是,这些概念对聚类算法而言事先是未知的,聚类过程仅能自动形成簇结构,簇对应的概念语义由使用者来把握和命名
聚类是无监督的学习算法,分类是有监督的学习算法。所谓有监督就是有已知标签的训练集(也就是说提前知道训练集里的数据属于哪个类别),机器学习算法在训练集上学习到相应的参数,构建模型,然后应用到测试集上。而聚类算法是没有标签的,聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到一起。
聚类的目的是把相似的样本聚到一起,而将不相似的样本分开,类似于“物以类聚”,很直观的想法是同一个簇中的相似度要尽可能高,而簇与簇之间的相似度要尽可能的低。
性能度量大概可分为两类: 一是外部指标, 二是内部指标 。
外部指标:将聚类结果和某个“参考模型”进行比较。
内部指标:不利用任何参考模型,直接考察聚类结果。
对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大
给定样本集D,
选择K个点作为初始质心
repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心
until 簇不发生变化或达到最大迭代次数
时间复杂度:O(tKmn),其中,t为迭代次数,K为簇的数目,m为记录数,n为维数
空间复杂度:O((m+K)n),其中,K为簇的数目,m为记录数,n为维数
kmenas算法首先选择K个初始质心,其中K是用户指定的参数,即所期望的簇的个数。这样做的前提是我们已经知道数据集中包含多少个簇,但很多情况下,我们并不知道数据的分布情况,实际上聚类就是我们发现数据分布的一种手段,这就陷入了鸡和蛋的矛盾。如何有效的确定K值,这里大致提供几种方法。
经常会产生较好的聚类结果的一个有趣策略是,首先采用层次凝聚算法决定结果粗的数目,并找到一个初始聚类,然后用迭代重定位来改进该聚类。
稳定性方法对一个数据集进行2次重采样产生2个数据子集,再用相同的聚类算法对2个数据子集进行聚类,产生2个具有k个聚类的聚类结果,计算2个聚类结果的相似度的分布情况。2个聚类结果具有高的相似度说明k个聚类反映了稳定的聚类结构,其相似度可以用来估计聚类个数。采用次方法试探多个k,找到合适的k值。
系统演化方法将一个数据集视为伪热力学系统,当数据集被划分为K个聚类时称系统处于状态K。系统由初始状态K=1出发,经过分裂过程和合并过程,系统将演化到它的稳定平衡状态Ki,其所对应的聚类结构决定了最优类数Ki。系统演化方法能提供关于所有聚类之间的相对边界距离或可分程度,它适用于明显分离的聚类结构和轻微重叠的聚类结构。
选择适当的初始质心是基本kmeans算法的关键步骤。常见方法是随机法:随机选取初始质心,但是这样簇的质量常常很差。
第一种:多次运行,每次使用一组不同的随机初始质心,然后选取具有最小SSE(误差平方和)的簇集。这种策略简单,但是效果可能不好,这取决于数据集和寻找的簇的个数。
第二种:取一个样本,并使用层次聚类技术对它聚类。从层次聚类中提取K个簇,并用这些簇的质心作为初始质心。该方法通常很有效,但仅对下列情况有效:(1)样本相对较小,例如数百到数千(层次聚类开销较大);(2)K相对于样本大小较小
第三种:随机地选择第一个点,获取所有点的质心作为第一个点。然后,对于每个后继初始质心,选择离已经选取过的初始质心最远的点。使用这种方法,确保了选择的初始质心不仅是随机的,而且是散开的。但是,这种方法可能选中离群点。此外,求离当前初始质心集最远的点开销也非常大。为了克服这个问题,通常该方法用于点样本。由于离群点很少(多了就不是离群点了),它们多半不会在随机样本中出现。计算量也大幅减少。
第四种:上面提到的canopy算法。
常用的距离度量方法包括:欧几里得距离和余弦相似度。两者都是评定个体间差异的大小的。
欧几里得距离度量会受指标不同单位刻度的影响,所以一般需要先进行标准化,同时距离越大,个体间差异越大;
空间向量余弦夹角的相似度度量不会受指标刻度的影响,余弦值落于区间[-1,1],值越大,差异越小。
但是针对具体应用,什么情况下使用欧氏距离,什么情况下使用余弦相似度?
从几何意义上来说,n维向量空间的一条线段作为底边和原点组成的三角形,其顶角大小是不确定的。也就是说对于两条空间向量,即使两点距离一定,他们的夹角余弦值也可以随意变化。
感性的认识,当两用户评分趋势一致时,但是评分值差距很大,余弦相似度倾向给出更优解。举个极端的例子,两用户只对两件商品评分,向量分别为(3,3)和(5,5),这两位用户的认知其实是一样的,但是欧式距离给出的解显然没有余弦值合理。[6]
采用欧式距离和采用余弦相似度,簇的质心都是其均值,即向量各维取平均即可。
一般是目标函数达到最优或者达到最大的迭代次数即可终止。对于不同的距离度量,目标函数往往不同。
当采用欧式距离时,目标函数一般为最小化对象到其簇质心的距离的平方和,如下:

当采用余弦相似度时,目标函数一般为最大化对象到其簇质心的余弦相似度和,如下:

如果所有的点在指派步骤都未分配到某个簇,就会得到空簇。如果这种情况发生,则需要某种策略来选择一个替补质心,否则的话,平方误差将会偏大。
一种方法是选择一个距离当前任何质心最远的点。这将消除当前对总平方误差影响最大的点。
另一种方法是从具有最大SSE的簇中选择一个替补的质心。这将分裂簇并降低聚类的总SSE。如果有多个空簇,则该过程重复多次。
另外,编程实现时,要注意空簇可能导致的程序bug。
Kmenas算法试图找到使平凡误差准则函数最小的簇。当潜在的簇形状是凸面的,簇与簇之间区别较明显,且簇大小相近时,其聚类结果较理想。
该算法时间复杂度为O(tKmn),与样本数量线性相关,所以,对于处理大数据集合,该算法非常高效,且伸缩性较好。
但该算法除了要事先确定簇数K和对初始聚类中心敏感外,经常以局部最优结束,同时对“噪声”和孤立点敏感,并且该方法不适于发现非凸面形状的簇或大小差别很大的簇。
基于密度的聚类算法,英文全称Density-Based Spatial Clustering of Applications with Noise——一种基于密度,对噪声鲁棒的空间聚类算法。
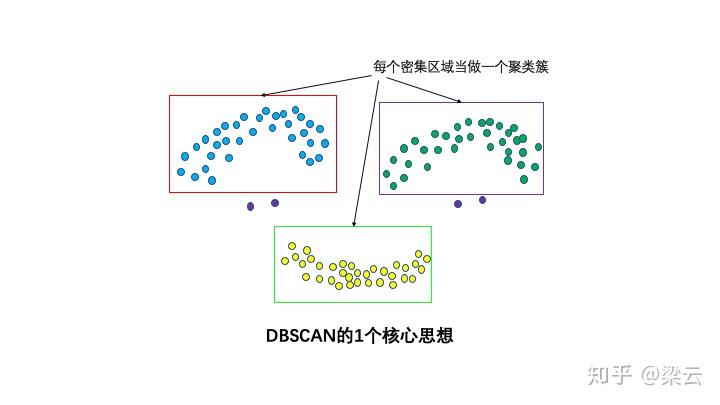
直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。
DBSCAN算法具有以下特点:
基于密度,对远离密度核心的噪声点鲁棒
无需知道聚类簇的数量
可以发现任意形状的聚类簇
DBSCAN通常适合于对较低维度数据进行聚类分析。
DBSCAN的基本概念可以用1,2,3,4来总结。
直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。
这两个算法参数实际可以刻画什么叫密集——当邻域半径R内的点的个数大于最少点数目minpoints时,就是密集。
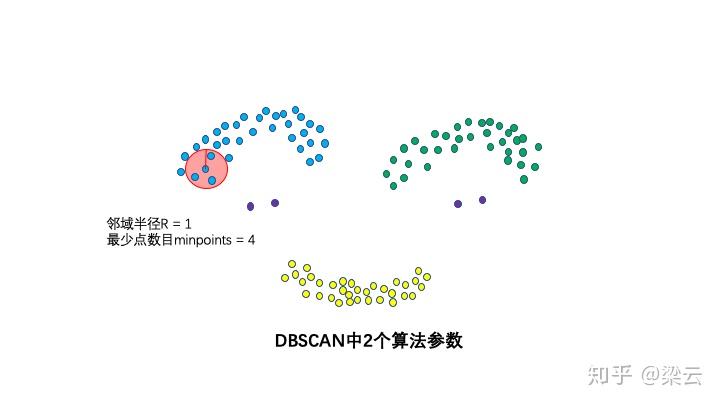
邻域半径R内样本点的数量大于等于minpoints的点叫做核心点。不属于核心点但在某个核心点的邻域内的点叫做边界点。既不是核心点也不是边界点的是噪声点。

如果P为核心点,Q在P的R邻域内,那么称P到Q密度直达。任何核心点到其自身密度直达,密度直达不具有对称性,如果P到Q密度直达,那么Q到P不一定密度直达。
如果存在核心点P2,P3,……,Pn,且P1到P2密度直达,P2到P3密度直达,……,P(n-1)到Pn密度直达,Pn到Q密度直达,则P1到Q密度可达。密度可达也不具有对称性。
如果存在核心点S,使得S到P和Q都密度可达,则P和Q密度相连。密度相连具有对称性,如果P和Q密度相连,那么Q和P也一定密度相连。密度相连的两个点属于同一个聚类簇。
如果两个点不属于密度相连关系,则两个点非密度相连。非密度相连的两个点属于不同的聚类簇,或者其中存在噪声点。

DBSCAN的算法步骤分成两步。
扫描全部样本点,如果某个样本点R半径范围内点数目>=MinPoints,则将其纳入核心点列表,并将其密度直达的点形成对应的临时聚类簇。
对于每一个临时聚类簇,检查其中的点是否为核心点,如果是,将该点对应的临时聚类簇和当前临时聚类簇合并,得到新的临时聚类簇。
重复此操作,直到当前临时聚类簇中的每一个点要么不在核心点列表,要么其密度直达的点都已经在该临时聚类簇,该临时聚类簇升级成为聚类簇。
继续对剩余的临时聚类簇进行相同的合并操作,直到全部临时聚类簇被处理。

def text_cluster(self, docs, features_method='tfidf', method="k-means", k=3, max_iter=100, eps=0.5, min_pts=2):
return cluster(docs, features_method, method, k, max_iter, eps, min_pts, self.seg)
k值默认设置为3
def text_cluster(docs, features_method='tfidf', method="dbscan",
k=3, max_iter=100, eps=0.5, min_pts=2, tokenizer=list):
"""文本聚类,目前支持 K-Means 和 DBSCAN 两种方法
:param features_method: str
提取文本特征的方法,目前支持 tfidf 和 count 两种。
:param docs: list of str
输入的文本列表,如 ['k-means', 'dbscan']
:param method: str
指定使用的方法,默认为 k-means,可选 'k-means', 'dbscan'
:param k: int
k-means 参数,类簇数量
:param max_iter: int
k-means 参数,最大迭代次数,确保模型不收敛的情况下可以退出循环
:param eps: float
dbscan 参数,邻域距离
:param min_pts:
dbscan 参数,核心对象中的最少样本数量
:return: dict
聚类结果
"""
#提取文本特征
if features_method == 'tfidf':
features, names = tfidf_features(docs, tokenizer)
elif features_method == 'count':
features, names = count_features(docs, tokenizer)
else:
raise ValueError('features_method error')
# feature to doc
f2d = {k: v for k, v in zip(docs, features)}
if method == 'k-means':
km = KMeans(k=k, max_iter=max_iter)
clusters = km.train(features) #传入特征用于训练
elif method == 'dbscan':
ds = DBSCAN(eps=eps, min_pts=min_pts)
clusters = ds.train(features) #传入特征用于训练
else:
raise ValueError("method invalid, please use 'k-means' or 'dbscan'")
clusters_out = {}
for label, examples in clusters.items():
c_docs = []
for example in examples:
doc = [d for d, f in f2d.items() if list(example) == f]
c_docs.extend(doc)
clusters_out[label] = list(set(c_docs))
return clusters_out
class KMeans(object):
def __init__(self, k, max_iter=100):
"""
:param k: int
类簇数量,如 k=5
:param max_iter: int
最大迭代次数,避免不收敛的情况出现导致无法退出循环,默认值为 max_iter=100
"""
self.k = k
self.max_iter = max_iter
self.centroids = None # list
self.clusters = None # OrderedDict
def _update_clusters(self, dataset):
"""
对dataset中的每个点item, 计算item与centroids中k个中心的距离
根据最小距离将item加入相应的簇中并返回簇类结果cluster
"""
clusters = OrderedDict()
centroids = self.centroids
k = len(centroids)
for item in dataset:
a = item
flag = -1
min_dist = float("inf")
for i in range(k): #比较点和k个中心的距离;取最近的k为该点中心
b = centroids[i]
dist = elu_distance(a, b)
if dist < min_dist:
min_dist = dist
flag = i
if flag not in clusters.keys():
clusters[flag] = []
clusters[flag].append(item)
self.clusters = clusters # clusters == {'k1':[item1,,,,],,,}
def _mean(self, features):
res = []
for i in range(len(features[0])):
col = [x[i] for x in features]
res.append(sum(col) / len(col))
return res
def _update_centroids(self):
"""根据簇类结果重新计算每个簇的中心,更新 centroids"""
centroids = []
for key in self.clusters.keys():
centroid = self._mean(self.clusters[key]) # 重新选取中心
centroids.append(centroid)
self.centroids = centroids
def _quadratic_sum(self):
"""计算簇内样本与各自中心的距离,累计求和。
sum_dist刻画簇内样本相似度, sum_dist越小则簇内样本相似度越高
计算均方误差,该均方误差刻画了簇内样本相似度
将簇类中各个点与质心的距离累计求和
"""
centroids = self.centroids
clusters = self.clusters
sum_dist = 0.0
for key in clusters.keys():
a = centroids[key]
dist = 0.0
for item in clusters[key]:
b = item
dist += elu_distance(a, b)
sum_dist += dist
return sum_dist
def train(self, X):
"""输入数据,完成 KMeans 聚类
:param X: list of list
输入数据特征,[n_samples, n_features],如:[[0.36, 0.37], [0.483, 0.312]]
:return: OrderedDict
"""
# 随机选择 k 个 example 作为初始类簇均值向量
self.centroids = random.sample(X, self.k)
self._update_clusters(X) #k个簇聚集
current_dist = self._quadratic_sum() #汇总距离,用于判定是否收敛
old_dist = 0
iter_i = 0
while abs(current_dist - old_dist) >= 0.00001:
self._update_centroids() #更新中心
self._update_clusters(X) #k个簇据集
old_dist = current_dist
current_dist = self._quadratic_sum() #汇总距离
iter_i += 1
if iter_i > self.max_iter:
break
return self.clusters
class DBSCAN(object):
def __init__(self, eps, min_pts):
self.eps = eps
self.min_pts = min_pts
def _find_cores(self, X):
"""遍历样本集找出所有核心对象"""
cores = set()
for di in X:
if len([dj for dj in X if elu_distance(di, dj) <= self.eps]) >= self.min_pts:
cores.add(di)
return cores
def train(self, X):
"""输入数据,完成 DBSCAN 聚类
:param X: list of tuple
输入数据特征,[n_samples, n_features],如:[[0.36, 0.37], [0.483, 0.312]]
:return: OrderedDict
"""
# 确定数据集中的全部核心对象集合
X = [tuple(x) for x in X]
cores = self._find_cores(X) #找核心:set()
not_visit = set(X)
k = 0
clusters = OrderedDict()
while len(cores):
not_visit_old = not_visit
# 随机选取一个核心对象
core = list(cores)[random.randint(0, len(cores) - 1)]
not_visit = not_visit - set(core)
# 查找所有密度可达的样本
core_deque = [core]
while len(core_deque):
coreq = core_deque[0]
coreq_neighborhood = [di for di in X if elu_distance(di, coreq) <= self.eps]
# 若coreq为核心对象,则通过求交集方式将其邻域内未被访问过的样本找出
if len(coreq_neighborhood) >= self.min_pts:
intersection = not_visit & set(coreq_neighborhood)
core_deque += list(intersection)
not_visit = not_visit - intersection
core_deque.remove(coreq)
cluster_k = not_visit_old - not_visit
cores = cores - cluster_k
clusters[k] = list(cluster_k)
k += 1
return clusters
# 文本聚类(需要调参)
docs = [
"百度深度学习中文情感分析工具Senta试用及在线测试",
"中文情感分析工具Senta试用及在线测试",
"百度深度学习中文情感分析工具Senta",
"试用及在线测试",
"中文情感分析工具Senta",
"情感分析是自然语言处理里面一个热门话题",
"AI Challenger 2018 文本挖掘类竞赛相关解决方案及代码汇总",
"深度学习实践:从零开始做电影评论文本情感分析",
"BERT相关论文、文章和代码资源汇总",
"将不同长度的句子用BERT预训练模型编码,映射到一个固定长度的向量上",
"自然语言处理工具包spaCy介绍",
"现在可以快速测试一下spaCy的相关功能,我们以英文数据为例,spaCy目前主要支持英文和德文"
]
#cluster = jiagu.text_cluster(docs)
#print(cluster)from jiagu.cluster.base import count_features, tfidf_features
from jiagu.cluster.dbscan import DBSCAN
from jiagu.cluster.kmeans import KMeans
import jiagufeatures, names = tfidf_features(docs, tokenizer=list)
features, names([[0.011064695094299264,
0.015594811850314015,
................
0.03812254189846925,
0.03812254189846925]],
['文',
'a',
'度',
.....,
'持',
'德'])
cluster = jiagu.text_cluster(docs, method="k-means")
print(cluster){0: ['深度学习实践:从零开始做电影评论文本情感分析', '百度深度学习中文情感分析工具Senta试用及在线测试'], 1: ['将不同长度的句子用BERT预训练模型编码,映射到一个固定长度的向量上', '现在可以快速测试一下spaCy的相关功能,我们以英文数据为例,spaCy目前主要支持英文和德文', '自然语言处理工具包spaCy介绍', '情感分析是自然语言处理里面一个热门话题', 'AI Challenger 2018 文本挖掘类竞赛相关解决方案及代码汇总'], 2: ['BERT相关论文、文章和代码资源汇总']}
k, max_iter = 3, 100
km = KMeans(k=k, max_iter=max_iter)
clusters = km.train(features)import jiagu
cluster = jiagu.text_cluster(docs, method="dbscan")
print(cluster){0: ['将不同长度的句子用BERT预训练模型编码,映射到一个固定长度的向量上', '现在可以快速测试一下spaCy的相关功能,我们以英文数据为例,spaCy目前主要支持英文和德文', '深度学习实践:从零开始做电影评论文本情感分析', 'BERT相关论文、文章和代码资源汇总', '自然语言处理工具包spaCy介绍', '情感分析是自然语言处理里面一个热门话题', 'AI Challenger 2018 文本挖掘类竞赛相关解决方案及代码汇总', '百度深度学习中文情感分析工具Senta试用及在线测试']}
import random
from collections import OrderedDict
from jiagu.cluster.base import elu_distance
eps, min_pts = 0.5, 2
ds = DBSCAN(eps=eps, min_pts=min_pts)
#def train(self, X):
# """输入数据,完成 KMeans 聚类
# :param X: list of tuple
# 输入数据特征,[n_samples, n_features],如:[[0.36, 0.37], [0.483, 0.312]]
# :return: OrderedDict
# """
# 确定数据集中的全部核心对象集合
X = [tuple(x) for x in features]
cores = ds._find_cores(X)
not_visit = set(X)
k = 0
clusters = OrderedDict()
while len(cores):
not_visit_old = not_visit
# 随机选取一个核心对象
core = list(cores)[random.randint(0, len(cores) - 1)]
not_visit = not_visit - set(core)
print('core:',core)
# 查找所有密度可达的样本
core_deque = [core]
while len(core_deque):
coreq = core_deque[0]
coreq_neighborhood = [di for di in X if elu_distance(di, coreq) <= ds.eps]
# 若coreq为核心对象,则通过求交集方式将其邻域内未被访问过的样本找出
if len(coreq_neighborhood) >= ds.min_pts:
intersection = not_visit & set(coreq_neighborhood)
core_deque += list(intersection)
not_visit = not_visit - intersection
core_deque.remove(coreq)
cluster_k = not_visit_old - not_visit
cores = cores - cluster_k
clusters[k] = list(cluster_k)
k += 1core: (0.018362685475645586, 0.017253834387581463, 0.0, 0.018626994411785103, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.018626994411785103, 0.018626994411785103, 0.04674945909225999, 0.0, 0.0, 0.0, 0.0, 0.023374729546129996, 0.0, 0.023374729546129996, 0.023374729546129996, 0.0, 0.029495624704678522, 0.058991249409357044, 0.058991249409357044, 0.058991249409357044, 0.058991249409357044, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.029495624704678522, 0.0, 0.0762450837969385, 0.0762450837969385, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925, 0.03812254189846925)