
This repository contains examples of popular machine learning algorithms implemented in Python with mathematics behind them being explained.
- For Octave/MatLab version of Machine Learning algorithms please check Machine Learning Course in Octave / MatLab repository.
- For Deep Learning algorithms please check Deep Learning repository.
- For Natural Language Processing (NLU = NLP + NLG) please check Natural Language Processing repository.
- For Computer Vision please check Computer Vision repository.
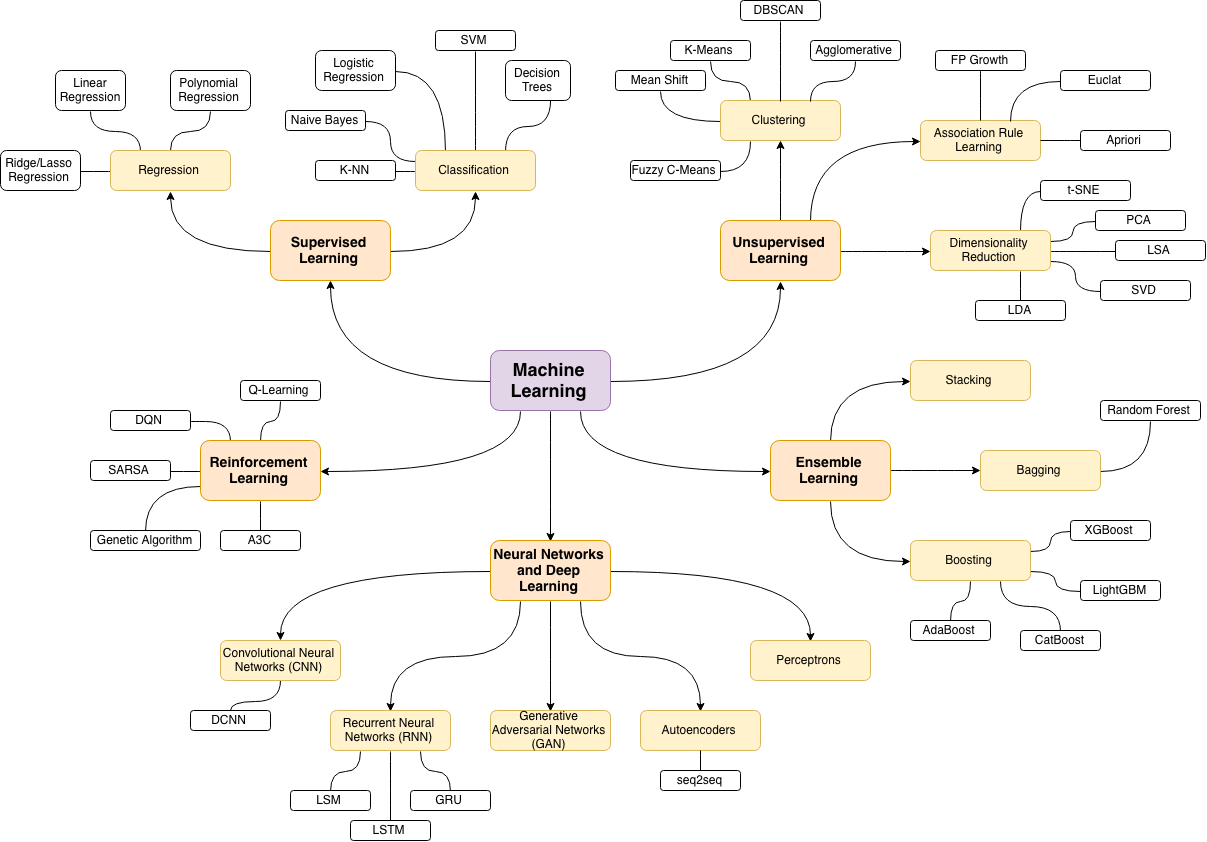
- Machine Learning Map
- Courses
- Online Courses (Coursera, Udacity, Edx, DataCamp, etc.)
- YouTube Videos
- Books
- Conferences
- Websites
- GitHub Repositories

- Awesome List
- Other
- Big Data
- Neural Networks
- Reinforcement Learning
- Books
- Classes
- Task / Tutorials
- GitHub Repositories
- Mathematics for AI, ML, DL, CV
- Algorithms
- Machine Learning System Design
- Python, IPython, Scikit-learn etc.
- Code editors
- JavaScript-libraries for visualizing
- R
- LaTeX
- Open Datasets list
- Social Networks (chanels, chats, groups, etc.)
- Implementation
- Supervised Learning
- Classification
- Regression
- Weak Supervision
- Active Learning
- Unsupervised Learning
- Clustering
- Neural Networks
- Supervised Learning
- What's is the difference between train, validation and test set, in neural networks?
- Projects
- Spam Detection
- Text Generator
- Quora Insincere Questions Classification
- Question Answering System using BiDAF Model on SQuAD
- MIT OpenCourseWare
- MIT OpenCourseWare on YouTube
- Top 50 FREE Artificial Intelligence, Computer Science, Engineering and Programming Courses from the Ivy League Universities
- This is The Entire Computer Science Curriculum in 1000 YouTube Videos
- Курс Машинное обучение. Воронцов
- Курс "Машинное обучение" на ФКН ВШЭ, Евгений Соколов
- Data Mining
- Deep Learning LUN Cources
- Тонна разнообразных курсов по программированию, алгоритмам, в том числе 14 курсов по ML
- Machine Learning Foundations
Machine Learning Foundations: Linear Algebra, Calculus, Statistics & Computer Science
- [ ]
🔹 Introductory Lectures:
These are great courses to get started in machine learning and AI. No prior experience in ML and AI is needed. You should have some knowledge of linear algebra, introductory calculus and probability. Some programming experience is also recommended.
- Machine Learning (Stanford CS229)
- Course website
- This modern classic of machine learning courses is a great starting point to understand the concepts and techniques of machine learning. The course covers many widely used techniques, The lecture notes are detailed and review necessary mathematical concepts.
- CS 329S: Machine Learning Systems Design by Stanford, Winter 2021
- This course aims to provide an iterative framework for designing real-world machine learning systems. The goal of this framework is to build a system that is deployable, reliable, and scalable.
- Machine Learning Interviews
- Convolutional Neural Networks for Visual Recognition (Stanford CS231n)
- Course website
- ( repo on github) — отличный десятинедельный курс по нейросетям и компьютерному зрению.
- A great way to start with deep learning. The course focuses on convolutional neural networks and computer vision, but also gives an overview on recurrent networks and reinforcement learning.
- Introduction to Artificial Intelligence (UC Berkeley CS188)
- Course website
- Covers the whole field of AI. From search methods, game trees and machine learning to Bayesian networks and reinforcement learning.
- Applied Machine Learning 2020 (Columbia)
- Alternative to Stanford CS229. As the name implies, this course takes a more applied perspective than Andrew Ng's machine learning lecture at Stanford. You will see more code than mathematics. Concepts and algorithms are using the popular Python libraries scikit-learn and Keras.
- Introduction to Reinforcement learning with David Silver (DeepMind)
- UCL Course on Reinforcement Learning by David Silver
- Course website
- Introduction to reinforcement learning by one of the leading researchers behind AlphaGo and AlphaZero.
- Introduction to Deep Learning (MIT 6.S191 )
- MIT's official introductory course on deep learning methods with applications in medicine, and more!
- Natural Language Processing with Deep Learning (Stanford CS224N)
- Course website
- Modern NLP techniques from recurrent neural networks and word embeddings to transformers and self-attention. Covers applied topics like questions answering and text generation.
- Machine Learning at MIPT
- This course aims to introduce students to modern state of Machine Learning and Artificial Intelligence. It is designed to take one year (two terms at MIPT) - approximately 2 * 15 lectures and seminars.
- [ ]
🔸 Advanced Lectures:
Advanced courses that require prior knowledge in machine learning and AI.
- Deep Unsupervised Learning (UC Berkeley CS294)
- Frontiers of Deep Learning (Simons Institute)
- New Deep Learning Techniques
- Geometry of Deep Learning (Microsoft Research)
- Deep Multi-Task and Meta Learning (Stanford CS330)
- Mathematics of Machine Learning Summer School 2019 (University of Washington)
- Probabilistic Graphical Models (Carneggie Mellon University)
- Probabilistic and Statistical Machine Learning 2020 (University of Tübingen)
- Statistical Machine Learning 2020 (University of Tübingen)
- Mobile Sensing and Robotics 2019 (Bonn University)
- Sensors and State Estimation Course 2020 (Bonn University)
- Photogrammetry 2015 (Bonn University)
- Advanced Deep Learning & Reinforcement Learning 2020 (DeepMind / UCL)
- Data-Driven Dynamical Systems with Machine Learning
- Data-Driven Control with Machine Learning
- ECE AI Seminar Series 2020 (NYU)
- CS287 Advanced Robotics at UC Berkeley Fall 2019
- CSEP 546 - Machine Learning (AU 2019) (U of Washington)
- Deep Reinforcment Learning, Decision Making and Control (UC Berkeley CS285)
- Stanford Convex Optimization
- Stanford CS224U: Natural Language Understanding, Spring 2019
- Full Stack Deep Learning 2019
- Emerging Challenges in Deep Learning
- Deep Bayes 2019 Summer School
- CMU Neural Nets for NLP 2020
- New Directions in Reinforcement Learning and Control (Institure for Advanced Study)
- Workshop on Theory of Deep Learning: Where next (Institure for Advanced Study)
- Deep Learning: Alchemy or Science? (Institure for Advanced Study)
- Theoretical Machine Learning Lecture Series (Institure for Advanced Study)
-
Free courses:
-
Перечень лучших курсов по практически любым областям математики
-
Coursera:
- DeepLearning.AI
- Top 40 COMPLETELY FREE Coursera Artificial Intelligence and Computer Science Courses
- Бесплатные курсы для изучения навыков в области облачных технологий
- Бесплатные курсы для студентов
- Coursera Together: Free online learning during COVID-19
- Get Started with Data Science Foundations
- Spesialization: Advanced Machine Learning
- Machine Learning от Andrew Ng (Stanford University) – самый популярный курс по машинному обучению (осторожно, вместо стандартных Питона или R – Matlab/Octave)
- Специализация Машинное обучение от МФТИ и Яндекса. По этой специализации есть аккуратный репозиторий
- Machine Learning Foundations: A Case Study Approach — очень доходчивый курс, подходит в качестве самого первого курса по ML
- Practical Predictive Analytics: Models and Methods
- Calculus: Single Variable Part 1 от University of Pennsylvania;
- Calculus One от The Ohio State University
- Современная комбинаторика от МФТИ, ведёт Райгородский А.М.
- Теория вероятностей для начинающих, а также на OpenEdu — курс от МФТИ, ведёт Райгородский А.М.
- Линейная алгебра от ВШЭ. Курс линейной алгебры для нематематических факультетов, подходит «для быстрого старта»
- Эконометрика (Econometrics) — 10-недельный курс от ВШЭ
- Customer Analytics – курс о практическом применении статистики и анализа данных. Для людей, разочаровавшихся в DS и не понимающих, на кой это всё
- Social Network Analysis от University of Michigan
- Social and Economic Networks: Models and Analysis от Stanford University
- Introduction to Recommender Systems – восьминедельный курс по рекомендательным системам от университета Миннесоты
- Специализация Machine Learning от Washington University.
-
Udacity:
- Machine Learning Engineer Nanodegree
- Data Analyst Nanodegree
- Intro to Machine Learning — this will teach you the end-to-end process of investigating data through a machine learning lens
- Intro to Descriptive Statistics – подробный курс для новичков
-
Edx:
-
- Intro to Python for Data Science – основы Python и немного про NumPy
-
- Курс по статистике на stepic.org — качественное введение в статистику, целиком на русском языке
-
Hyperskill from JetBrains Academy:
-
Google:
- Machine Learning Crash Course with TensorFlow APIs - Google's fast-paced, practical introduction to machine learning
- Google Cloud Training
- Google Developers Training
- Technical Writing Courses
- Qwiklabs
- Grow.Google
- LearnDigital.WithGoogle
-
Learning from Data – введение в машинное обучение (основная теория, алгоритмы и области практического применения)
-
Data Science and Machine Learning Essentials от Microsoft
-
-
A complete guide to start and improve in machine learning (ML), artificial intelligence (AI) in 2021 without ANY background in the field and stay up-to-date with the latest news and state-of-the-art techniques!
-
- TensorFlow: Coding TensorFlow playlist
- Google Cloud Platform: AI Adventures
- 3Blue1Brown channel
- Grammarly AI-NLP Club playlist
- Lviv Data Science Summer School 2020 lectures
- Samsung AI Innovation Campus - Russia
- Machine Learning University, at GitHub
- Dive into Deep Learning
- Interactive deep learning book with code, math, and discussions
- Implemented with NumPy/MXNet, PyTorch, and TensorFlow
- Neural Networks and Deep Learning a free online book
- 100+ Free Data Science Books – более 100 бесплатных книг по Data Science
- 16 Free Machine Learning Books — ещё 16 бесплатных книг по ML
- An Introduction to Statistical Learning
- Tensor Calculus
- The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition (Springer Series in Statistics)
- Pattern Recognition and Machine Learning, Bishop
- Deep Learning by Ian Goodfellow, Yoshua Bengio, Aaron Courville
- Applied Predictive Modeling – M. Kuhn, K. Johnson (2013)
- Bayesian Reasoning and Machine Learning - D.Barber (2015)
- Core Concepts in Data Analysis: Summarization, Correlation and Visualization - Boris Mirkin
- A Course in Machine Learning - Hal Daumé III (another link)
- Data Mining: Concepts and Techniques - Jiawei Han et. al.
- Data Mining and Analysis. Fundamental Concepts and Algorithms - M.J.Zaki, W.Meira Jr (2014)
- Data Science For Dummies – Lillian Pierson (2015)
- Doing Data Science
- Frequent Pattern Mining - Charu C Aggarwal, Jiawei Han (eds.)
- Gaussian Processes for Machine Learning - Carl E. Rasmussen, Christopher K. I. Williams
- Inductive Logic Programming: Techniques and Applications - Nada Lavrac, Saso Dzeroski
- Information Theory, Inference and Learning Algorithms – David MacKay
- Introduction To Machine Learning - Nils J Nilsson (1997)
- The LION Way Machine Learning plus Intelligent Optimization (pdf)
- Machine Learning - Tom Mitchell
- Machine Learning – Andrew Ng
- Machine Learning, Neural and Statistical Classification - D. Michie, D. J. Spiegelhalter
- Machine Learning. The Art of Science of Algorithms that Make Sense of Data - P. Flach (2012)
- Pattern Recognition and Machine Learning - C.M.Bishop (2006)
- Machine Learning in Action - Peter Harrington
- R in Action
- Reinforcement Learning: An Introduction - Richard S. Sutton, Andrew G. Barto
- Understanding Machine Learning: From Theory to Algorithms
- Анализ больших наборов данных - перевод Mining Massive Datasets - Jure Leskovec, Anand Rajaraman, Jeff Ullman
- Машинное обучение — Петер Флах
- Построение систем машинного обучения — Л. П. Коэльо, В. Ричарт (2016)
- Подборка научпоп-книг
- Hands-On Machine Learning with Scikit-Learn and TensorFlow
- Machine Learning Notebooks
-
A series of Jupyter notebooks that walk you through the fundamentals of Machine Learning and Deep Learning in python using Scikit-Learn and TensorFlow.
-
- Machine Learning Notebooks
- [ ]
- AAAI, Association for the Advancement of Artificial Intelligence
- AAMAS, International Conference on Autonomous Agents and Multi-Agent Systems
- CVPR, IEEE Conference on Computer Vision and Pattern Recognition
- ICML, International Conference on Machine Learning
- ICCBR, International Conference on Case-Based Reasoning
- ICCV, International Computer Vision Conference
- IEEE, International Conference on Data Mining
- IJCAI, International Joint Conferences on Artificial Intelligence
- NIPS, NeurIPS, Conference on Neural Information Processing Systems
- SIAM, Society for Industrial and Applied Mathematics
- SIGKDD, Conference on Knowledge Discovery and Data Mining
- O'Reilly AI Conference - O'Reilly Artificial Intelligence Conference
- ACL, Association for Computational Linguistics
- Open Data Science Conference
- The Data Science Conference
- Strata Data & AI Conference
- useR!
- Deep Learning Summit
-
Computer Vision:
-
Nalural Language Processing:
- ECML, European Conference on Machine Learning
- ECCV, European Conference on Computer Vision
- EACL, European Chapter of the Association for Computational Linguistics
- Talking Machines
- Made with ML - Join 20K+ developers in learning how to responsibly deliver value with applied ML.
- Laconic Machine Learning
- Towards AI
- Tutorials
-
AI-related tutorials.
-
- Tutorials
- [ ]
| Title | Description, Information |
|---|---|
| Top-down learning path: Machine Learning for Software Engineers | |
| 100-Days-Of-ML-Code | |
| ml-course-msu | Репозиторий с конспектами, кодом и прочими материалами к семинарам по машинному обучению ВМК МГУ |
| 100-best-github-machine-learning | |
| awesome-machine-learning | |
| trekhleb, homemade-machine-learning | Python examples of popular machine learning algorithms with interactive Jupyter demos and math being explained |
| trekhleb, machine-learning-experiments | Interactive Machine Learning experiments: models training + models demo |
| trekhleb, machine-learning-octave | MatLab/Octave examples of popular machine learning algorithms with code examples and mathematics being explained |
| Machine Learning Notebooks | A collection of Machine Learning fundamentals and useful python notebooks by Diego Inácio |
| Open Source Society University's Data Science course | This is a solid path for those of you who want to complete a Data Science course on your own time, for free, with courses from the best universities in the World |
| data-science-blogs | |
| Dive into Machine Learning | ( |
| Рекомендации от преподавателей курса «Математика и Python» и специализации | |
| Литература для поступления в ШАД | |
| Machine learning cheat sheet | - soulmachine (2015) |
| Probabilistic Programming and Bayesian Methods for Hackers | (free) |
| ml-surveys | Survey papers summarizing advances in deep learning, NLP, CV, graphs, reinforcement learning, recommendations, graphs, etc. |
| Machine_Learning_and_Deep_Learning | Getting started with Machine Learning and Deep Learning |
| MachineLearning_DeepLearning | Share about Machine Learning and Deep Learning |
| Machine Learning Guide | A guide covering Machine Learning including the applications, libraries and tools that will make you better and more efficient with Machine Learning development. |
- Awesome Adversarial Machine Learning - A curated list of awesome adversarial machine learning resources
- Awesome AI Booksmarks - Curated list of reads, implementations and core concepts of Artificial Intelligence, Deep Learning, Machine Learning by best folk in the world
- Awesome AI on Kubernetes - awesome tools and libs for AI, Deep Learning, Machine Learning, Computer Vision, Data Science, Data Analytics and Cognitive Computing that are baked in the oven to be Native on Kubernetes and Docker with Python, R, Scala, Java, C#, Go, Julia, C++ etc
- Awesome Awesomeness - A curated list of awesome awesomeness
- Awesome Big Data - A curated list of awesome big data frameworks, ressources and other awesomeness
- Awesome Business Machine Learning - A curated list of practical business machine learning (BML) and business data science (BDS) applications for Accounting, Customer, Employee, Legal, Management and Operations
- Awesome CS Courses - List of awesome university courses for learning Computer Science
- Awesome ML Courses - Awesome free machine learning and AI courses with video lectures
- Awesome Causality
- Awesome Community Detection
- Awesome CSV
- Awesome Data Science with Ruby
- Awesome Dash
- Awesome Decision Trees
- Awesome Deep Learning - A curated list of awesome Deep Learning tutorials, projects and communities
- Awesome Deep Learning Papers - The most cited deep learning papers
- Awesome Deep Learning for Natural Language Processing (NLP) - A curated list of awesome Deep Learning for Natural Language Processing resources
- Awesome Deep Reinforcement Learning - A curated list of awesome Deep Reinforcement Learning resources
- Awesome ETL
- Awesome Financial Machine Learning
- Awesome Fraud Detection
- Awesome GAN Applications
- Awesome GNN Papers - Papers on Graph neural network (GNN)
- Awesome Graph Classification
- Awesome Gradient Boosting
- Awesome Machine Learning
- Awesome Machine Learning Interpretability
- Awesome Machine Learning Operations
- Awesome Monte Carlo Tree Search
- Awesome Online Machine Learning
- Awesome Python
- Awesome Python Books - Directory of Python books
- Awesome Python Data Science - Probably the best curated list of data science software in Python
- Awesome Python Data Science
- Awesome Python Data Science - Curated list of Python resources for data science
- Awesome Python Data Science
- Awesome Pytorch
- Awesome Public Datasets – an awesome list of high-quality open datasets in public domains (on-going)
- Awesome RNN – awesome recurrent neural networks
- Awesome Recommender Systems
- Awesome Semantic Segmentation
- Awesome Sentence Embedding
- Awesome Time Series
- Awesome Time Series Anomaly Detection
- Cheat Sheets:
- Tucker Decomposition, Article
- Katakoda
- A Step by Step Backpropagation Example
- Машинное обучение: вводная лекция – К. В. Воронцов
- Математические методы обучения по прецедентам (теория обучения машин) – К. В. Воронцов
- Пост на reddit: Machine Learning Books
- Доска по data science в Trello — проверенные материалы, организованные по темам (expertise tracks, языки программирования, различные инструменты)
- People tweeting about ML and AI — на кого подписаться в Твиттере
- Machine Learning Resource Guide
- 17 ресурсов по машинному обучению от Типичного Программиста
- 51 идея для тренировочных задачек (toy data problem) в Data Science
- Data Science Interview Questions — огромный список вопросов для подготовки к интервью на позицию data scientist'а
- Много книг по NLP (Natural Language Processing)
- Список открытых источников данных, на которых можно найти бесплатные датасеты
- Для фанатов reddit.com — полезные и весёлые сабреддиты по машинному обучению и смежным темам
- Очень подробный ответ на вопрос What should I learn in data science in 100 hours?
- Books:
- Big Data Fundamentals: Concepts, Drivers & Techniques by Thomas Erl, Wajid Khattak
- Big Data: Principles and best practices of scalable realtime data systems by Nathan Marz, James Warren
- Courses:
- Coursera:
- Data Engineer VS Data Scientist:
- Лекции по искусственным нейронным сетям — К. В. Воронцов
- Нейронные сети на stepic — теоретические и практические основы искусственных нейронных сетей от Института Биоинформатики
- Искусственный интеллект и машинное обучение — приятные и качественные лекции по широкому набору тем. Один из немногих из источников на русском языке
- Neural Networks for Machine Learning. Цитата: «Я уже использовал фразу "живая легенда" и теперь испытываю сложности, поскольку как-то иначе охарактеризовать Джеффри Хинтона (человека, стоящего у истоков современных подходов к обучению нейросетей с помощью алгоритма обратного распространения ошибки) сложно. Курс у него получился отличный»
- Neural Networks and Deep Learning – бесплатная онлайн-книга по нейросетям и глубинному обучению ( repo on github)
- CS231n: Convolutional Neural Networks for Visual Recognition ( repo on github). During the 10-week course, students will learn to implement, train and debug their own neural networks and gain a detailed understanding of cutting-edge research in computer vision
- Tensorflow — Neural Network Playground – игрушечные нейросети в браузере ( исходный код)
- awesome-rnn – awesome recurrent neural networks
- nmn2 – dynamically predicted neural network structures for multi-domain question answering;
- Nervana's Deep Learning Course.
- Books:
- Classes:
- David Silver's Reinforcement Learning Course (UCL, 2015)
- Introduction to Reinforcement learning with David Silver (DeepMind)
- Course website
- Introduction to reinforcement learning by one of the leading researchers behind AlphaGo and AlphaZero.
- CS294 - Deep Reinforcement Learning (Berkeley, Fall 2015)
- CS 8803 - Reinforcement Learning (Georgia Tech)
- CS885 - Reinforcement Learning (UWaterloo), Spring 2018
- CS294-112 - Deep Reinforcement Learning (UC Berkeley)
- David Silver's Reinforcement Learning Course (UCL, 2015)
- Task / Tutorials:
- Introduction to Reinforcement Learning (Joelle Pineau @ Deep Learning Summer School 2016)
- Deep Reinforcement Learning (Pieter Abbeel @ Deep Learning Summer School 2016)
- Deep Reinforcement Learning ICML 2016 Tutorial (David Silver)
- Tutorial: Introduction to Reinforcement Learning with Function Approximation
- John Schulman - Deep Reinforcement Learning (4 Lectures)
- Deep Reinforcement Learning Slides @ NIPS 2016
- OpenAI Spinning Up
- Advanced Deep Learning & Reinforcement Learning (UCL 2018, DeepMind) -Deep RL Bootcamp
- GitHub Repositories:
- dennybritz/reinforcement-learning, Implementation of Reinforcement Learning Algorithms. Python, OpenAI Gym, Tensorflow. Exercises and Solutions to accompany Sutton's Book and David Silver's course.
- Deep Reinforcment Learning, Decision Making and Control (UC Berkeley CS285)
- New Directions in Reinforcement Learning and Control (Institure for Advanced Study)
- Sheldon Axler "Linear algebra done right"
- Курс по линейной алгебре на stepic
- https://www.coursera.org/course/linalg
- Принстон
- http://dshinin.ru/Upload_Books2/Books/2008-07-15/200807152203201.PDF
- Бойд
- https://www.youtube.com/playlist?list=PLbMVogVj5nJQ2vsW_hmyvVfO4GYWaaPp7
- immersive linear algebra – online linear algebra book with fully interactive figures
- Линейная алгебра от ВШЭ. Курс линейной алгебры для нематематических факультетов, подходит «для быстрого старта»
- MIT 18.06 Linear Algebra – by Professor Gilbert Strang
- The Elements of Statistical Learning: Data Mining, Inference, and Prediction - T. Hastie, R. Tibshirani, J. Friedman
- Openintro Statistics 3 (free)
- Теория вероятностей – Чернова Н.И. (СибГУТИ, 2009)
- Теория вероятностей – Чернова Н.И. (НГУ, 2007)
- Математическая статистика – Чернова Н.И. (НГУ, 2014)
- Математическая статистика – Чернова Н.И. (СибГУТИ, 2009)
- Прикладная математическая статистика – Кобзарь А.
- Современная комбинаторика от МФТИ, ведёт Райгородский А.М.
- Теория вероятностей для начинающих (также на OpenEdu) — курс от МФТИ, ведёт Райгородский А.М.
- Basic Statistics – хорошие лекции и квизы, идеально для новичков. Минус — недоработанные практические задания (Labs) на DataCamp, которые не помогают закрепить выученный материал, а, скорее, отвлекают от изучения статистики
- Introduction to Probability and Data от Duke University
- Probability and Statistics на KhanAcademy
- Основы статистики на stepic.org — качественное введение в статистику, на русском языке
- Основы статистики: часть 2 — курс продолжает знакомить слушателей с основными понятиями и методами статистики. Курс затронет такие темы как анализ номинативных данных, непараметрические критерии и методы понижения размерности
- MITx: 6.041x Introduction to Probability - The Science of Uncertainty
- Intro to Statistics — covers visualization, probability, regression and other topics that will help you learn the basic methods of understanding data with statistics
- Intro to Descriptive Statistics – подробный курс для новичков. This course will teach you the basic terms and concepts in statistics as well as guide you through introductory probability
- Intro to Inferential Statistics – курс знакомит с базовыми понятиями индуктивной статистики (t-test, ANOVA, корреляция, регрессия и др.)
- Introduction to Probability – Joseph K. Blitzstein (2014)
- Causal Inference in Statistics: A Primer – Pearl J., Glymour M.
- An Introduction to Statistical learning – Gareth James, D. Witten et. al
- Machine Learning: A Probabilistic Perspective
- Statistics 110: Probability – Гарвардский курс от Joseph K. Blitzstein
- Statistics for Hackers — презентация о том, как можно использовать coding skills to "hack statistics"
- Mathematical Statistics
- Think Stats 2e
- Files from lecture:
Bayesian statistics and related books:
- C.P. Robert: The Bayesian choice (advanced)
- Gelman, Carlin, Stern, Rubin: Bayesian data analysis (nice easy older book)
- Congdon: Applied Bayesian modelling; Bayesian statistical modelling (relatively nice books for references)
- Casella, Robert: Introducing Monte Carlo methods with R (nice book about MCMC)
- Robert, Casella: Monte Carlo Statistical Methods
- some parts of Bishop: Pattern recognition and machine learning (very nice book for engineers)
- Puppy book from Kruschke
Correlation does not imply causation
More online lectures, courses, papers, books, etc. on Causality:
-
Coursera:
-
Powerful Concepts in Social Science playlists, Duke
-
4 lectures on causality by J.Peters (8 h), MIT Statistics and Data Science Center, 2017
-
Causality tutorial by D.Janzing and S.Weichwald (4 h), Conference on Cognitive Computational Neuroscience 2019
-
Course on causality by S.Bauer and B.Schölkopf (3 h), Machine Learning Summer School 2020
-
Course on causality by D.Janzing and B.Schölkopf (3 h), Machine Learning Summer School 2013
-
Causal Structure Learning,Christina Heinze-Deml, Marloes H. Maathuis, Nicolai Meinshausen, 2017
-
JUDEA PEARL, MADELYN GLYMOUR, NICHOLAS P. JEWELL CAUSAL INFERENCE IN STATISTICS: A PRIMER
-
Causality in cognitive neuroscience: concepts, challenges, and distributional robustness
-
Investigating Causal Relations by Econometric Models and Cross-spectral Methods, 1969
-
Fast Greedy Equivalence Search (FGES) Algorithm for Continuous Variables
-
Greedy Fast Causal Inference (GFCI) Algorithm for Continuous Variables
Casual Machine Learning (Papers):
- Causal Decision Trees, Jiuyong Li, Saisai Ma, Thuc Duy Le, Lin Liu and Jixue Liu, 2015
- Discovery of Causal Rules Using Partial Association, 2012
- Causal Inference in Data Science From Prediction to Causation, 2016
Experimental designs for casual learning:
- Matching
- Incident user design
- Active comparator
- Instrumental variables estimation
- Difference-in-differences
- Regression discontinuity design
- Modeling
- Data Structures and Algorithms – специализация на Coursera
- MIT 6.046J Introduction to Algorithms – teaches techniques for the design and analysis of efficient algorithms, emphasizing methods useful in practice
- Visualizing Algorithms;
- Реализации алгоритмов
- API:
- Dive into Machine Learning ( repo on github) with Python Jupyter notebook and scikit-learn
- Заметка по IPython Notebook
- WinPython – дистрибутив питона и научных библиотек (+Jupyter, +Spyder) для Windows 7/8/10 ( репозиторий на гитхабе)
- awesome-python-books - Directory of Python books
- Статья Data Munging in Python (using Pandas) — в помощь тем, кто в первый раз столкнулся с Python и/или Pandas
- Intermediate Python — (переведённое на русский!) краткое онлайн-руководство по нюансам языка, мимо которых часто проходят новички (автор — Yasoob Khalid);
- Effective Python — книга от разработчика из Google
- Введение в Sklearn — подробный IPython-notebook на русском языке
- Туториал по Matplotlib
- Таблица названий цветов (png) в Python
- Анализ данных при помощи Python – большая статья про графики в pandas и matplotlib
- Scipy lecture notes — tutorials on the scientific Python ecosystem: a quick introduction to central tools and techniques
- Очень большой список интересных питоновских ноутбуков (от туториалов на три минуты, до целых книг (!) в таком формате)
- Data Science IPython Notebooks on Deep learning (TensorFlow, Theano, Caffe), scikit-learn, Kaggle, big data (Spark, Hadoop MapReduce, HDFS), matplotlib, pandas, NumPy, SciPy, Python essentials, AWS, and various command lines.
- 100 Numpy exercises. The goal is both to offer a quick reference for new and old users and to provide also a set of exercices for those who teach
- Intro to Python for Data Science – основы Python и немного про NumPy
- Курс по основам Python, алгоритмам и структурам данных. Курс представлен в виде тетрадок IPython
- @py_digest – канал в telegram, уведомляющий о последних новостях из мира Python
- Python – группа в telegram с общением и обсуждением языка программирования Python
- Pythonpedia – энциклопедия ресурсов по программированию на Python
- 10 библиотек для визуализации данных на Python
- tpot – A Python tool that automatically creates and optimizes machine learning pipelines using genetic programming
- Data Analysis Tutorials – Python Programming tutorials from beginner to advanced on a massive variety of topics. All video and text tutorials are free
- The python-machine-learning-book code repository and info resource
- introduction to ML with python – Notebooks and code for the book "Introduction to Machine Learning with Python"
-
PyCharm от JetBrains - серьезная IDE для больших проектов
-
Spyder – the Scientific PYthon Development EnviRonment. Spyder входит в Анаконду (просто введите
spyderв командной строке) -
Canopy — scientific and analytic Python deployment with integrated analysis environment (рекомендуют в курсе MITx)
-
Rodeo — a data science IDE for Python
-
Jupyter – open source, interactive data science and scientific computing across over 40 programming languages. The Jupyter Notebook is a web application that allows you to create and share documents that contain live code, equations, visualizations and explanatory text
-
nbviewer – renders notebooks available on other websites
-
Sublime Text 3 - VIM XXI века*;, отлично подходит для python, если использовать вместе с плагинами:
- Package Control - для быстрой и удобной работы с дополнениями
- Git - для работы с git
- Jedi - делает автодополнения для Python более умными и глубокими
- SublimeREPL - запускает
Read-eval-print loopв соседней вкладке, удобно для пошаговой отладки кода - Auto-PEP8 - приводит код в соответствие с каноном стиля pep8
- Python Checker - проверка кода
-
PyCharm vs Sublime Text – a blog post comparing these two popular development tools and text editors.
-
PEP 0008 -- Style Guide for Python Code.
- d3.js
- JS Charts – a JavaScript based chart generator that requires little or no coding. With JS Charts drawing charts is a simple and easy task, since you only have to use client-side scripting
- LT Diagram Builder
- Flot – a pure JavaScript plotting library for jQuery, with a focus on simple usage, attractive looks and interactive features
- Canvas 3D Graph
- JQuery Visualize Plugin
- PlotKit
- http://www.ajaxline.com/10-best-free-javascript-charts-solutions
- http://webtecker.com/2008/06/12/10-free-chart-scripts/
- raphaeljs.com
- www.deensoft.com/lab/protochart/
- http://teethgrinder.co.uk/open-flash-chart-2
- R in Action
- Basic Statistics – в этом курсе практические задания на R;
- Анализ данных на R в примерах и задачах — видеолекции от Computer Science Center;
- Advanced R by Hadley Wickham – онлайн-книга для тех, кто хочет повысить свой навык программирования на R и лучше понять этот язык (в т.ч. для программистов на других языках);
- A detailed list of online courses on R;
- Machine Learning in R ( github repo) — Interface to a large number of classification and regression techniques, including machine-readable parameter descriptions;
- Лучшие пакеты для машинного обучения в R – статья на Хабрахабре.
- Не очень краткое введение в LateX (PDF),
- IDE:
- Курс по LateX на Coursera от Высшей Школы Экономики*,
- https://vk.com/hse.latex – группа курса vk (много полезного и разного).
- Kaggle
- Google’s Public Data Sets
- /r/datasets
- UCI Machine Learning Repository
- awesome-public-datasets – an awesome list of high-quality open datasets in public domains (on-going)
The initial list was provided by Kevyn Collins-Thomson from the University of Michigan School of Information.
-
Long general-purpose list of datasets:
-
This website has dozens of public datasets - some fun, some a bit, well.. quirky. external link:
-
The Academic Torrents site has a growing number of datasets, including a few text collections that might be of interest (Wikipedia, email, twitter, academic, etc.) for current or future projects.
-
Google Books n-gram corpus
- External link: http://books.google.com/ngrams
- Dataset: external link: http://aws.amazon.com/datasets/8172056142375670
-
Common Crawl: • Currently 6 billion Web documents (81 Tb) • Amazon S3 Public Data Set
-
Business/commercial data Yelp external link:
- http://www.yelp.com/developers/documentation/v2/search_api
- Upcoming Deprecation of Yelp API v2 on June 30, 2018 (Posted by Yelp Jun 28, 2017)
-
Internet Archive (huge, ever-growing archive of the Web going back to 1990s) external link:
-
WikiData:
-
World Food Facts
-
Data USA - a variety of census data
-
U.S. Government open data - datasets from 75 agencies and subagencies
-
NASA data portal - space and earth science
- /r/datacleaning
- /r/dataisbeautiful
- /r/dataisugly
- /r/datasets
- /r/MachineLearning
- /r/probabilitytheory
- /r/statistics
- /r/pystats
- /r/learnpython
- Deep Learning Russia — Канал сообщества vk.com/deeplearning_ru
- ModelOverfit — Канал сообщества modeloverfit
- Data Science — Первый новостной канал про data science
- Big Data & Machine Learning — Чат по большим данным, обработке и машинному обучению
- Data Science Chat — Чат по теме Data Science
Training Set: this data set is used to adjust the weights on the neural network.
Validation Set: this data set is used to minimize overfitting. You're not adjusting the weights of the network with this data set, you're just verifying that any increase in accuracy over the training data set actually yields an increase in accuracy over a data set that has not been shown to the network before, or at least the network hasn't trained on it (i.e. validation data set). If the accuracy over the training data set increases, but the accuracy over the validation data set stays the same or decreases, then you're overfitting your neural network and you should stop training.
The validation data set is a set of data for the function you want to learn, which you are not directly using to train the network. You are training the network with a set of data which you call the training data set. If you are using gradient based algorithm to train the network then the error surface and the gradient at some point will completely depend on the training data set thus the training data set is being directly used to adjust the weights. To make sure you don't overfit the network you need to input the validation dataset to the network and check if the error is within some range. Because the validation set is not being using directly to adjust the weights of the network, therefore a good error for the validation and also the test set indicates that the network predicts well for the train set examples, also it is expected to perform well when new example are presented to the network which was not used in the training process.
Testing Set: this data set is used only for testing the final solution in order to confirm the actual predictive power of the network.
Also, in the case you do not have enough data for a validation set, you can use cross-validation to tune the parameters as well as estimate the test error.
Cross-validation set is used for model selection, for example, select the polynomial model with the least amount of errors for a given parameter set. The test set is then used to report the generalization error on the selected model.
Early stopping is a way to stop training. There are different variations available, the main outline is, both the train and the validation set errors are monitored, the train error decreases at each iteration (backpropagation and brothers) and at first the validation error decreases. The training is stopped at the moment the validation error starts to rise. The weight configuration at this point indicates a model, which predicts the training data well, as well as the data which is not seen by the network . But because the validation data actually affects the weight configuration indirectly to select the weight configuration. This is where the Test set comes in. This set of data is never used in the training process. Once a model is selected based on the validation set, the test set data is applied on the network model and the error for this set is found. This error is a representative of the error which we can expect from absolutely new data for the same problem.
-
- Fully connected neural network that recognizes handwriting numbers from MNIST database (Modified National Institute of Standards and Technology database)
- MNIST Database
- Code
-
- Understanding GRU Networks, Towards Data Science
-
⚙️ Methods:
- Naive Bayes spam filtering
- K-Nearest Neighbors algorithm
- Decision Tree learning
- Support Vector Machine (SVM)
- Random Forest
-
💻 Code
-
Neural Network for generating text based on training txt file using Google Colab. As a base text were used Alice in Wonderland by Lewis Carroll.
-
Implemented a Bidirectional Attention Flow neural network as a baseline on SQuAD, improving Chris Chute's model implementation, adding word-character inputs as described in the original paper and improving GauthierDmns' code.