The goals / steps of this project are the following:
- Use the simulator to collect data of good driving behavior
- Build, a convolution neural network in Keras that predicts steering angles from images
- Train and validate the model with a training and validation set
- Test that the model successfully drives around track one without leaving the road
- Summarize the results with a written report
This repository contains starting files for the Behavioral Cloning Project.
model.pymodel.h5video.mp4README.mddrive.py
The model consists of a convolution neural network with 3x3 and 5x5 filter sizes and depths between 24 and 64 (model.py lines 91-117) The model includes RELU layers to introduce nonlinearity and the data is normalized in the model using a Keras lambda layer.
def get_model():
"""Get Keras Model
:return model: keras model
"""
model = Sequential()
model.add(Lambda(lambda x: x / 255.0 - 0.5, input_shape=(160, 320, 3)))
model.add(Cropping2D(cropping=((70,25), (0,0)), input_shape=(160,320,3)))
model.add(Conv2D(filters=24, kernel_size=5, strides=(2, 2), activation='relu'))
model.add(Conv2D(filters=36, kernel_size=5, strides=(2, 2), activation='relu'))
model.add(Conv2D(filters=48, kernel_size=5, strides=(2, 2), activation='relu'))
model.add(Conv2D(filters=64, kernel_size=3, strides=(1, 1), activation='relu'))
model.add(Conv2D(filters=64, kernel_size=3, strides=(1, 1), activation='relu'))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(100, activation='relu'))
model.add(Dense(50, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1))
model.compile(optimizer=Adam(learning_rate=0.0001), loss='mse')
return modelTo prevent overfitting, several data augmentation techniques like flipping images horizontally as well as using left and right images to help the model generalize were used. The model was trained and validated on different data sets to ensure that the model was not overfitting. The model was tested by running it through the simulator and ensuring that the vehicle could stay on the track.
Another technique to reduce overfitting was to introduce dropout in the network, with a dropout probability of 0.5.
The model used an Adam optimizer, and various learning rates (LR) were iterated over to arrive at the final LR.
batch_size = 32
number_of_epochs = 5
learning_rate = 0.0001Udacity sample data was used for training.
To gauge how well the model was working, I split my image and steering angle data into a training (80%) and validation (20%) set. A validation loss was calculated as the mean absolute error between the true and predicted steering angles for the validation set and this was used to monitor progress of training.
The overall strategy for deriving a good model was to use the Nvidia architecture since it has been proven to be very successful in self-driving car tasks. A lot of other students have also reported that it was successful. The architecture was also recommended in the lessons and it's adapted for this use case.
In order to gauge how well the model was working, I split my image and steering angle data into a training and validation set. Since I was using data augmentation techniques, the mean squared error was low both on the training and validation steps.
I first tried training the model with the network described in the lessons but could not get the model to drive correctly. The next step was to add more convolutions and layer activations, which still did not get the model to do what was expected. After many attempts, the nvidia architecture was adapted for this project and this worked. The architecture worked in creating a model that could drive around the track.
The final model architecture code is shown above. Here is a visualization of the architecture:
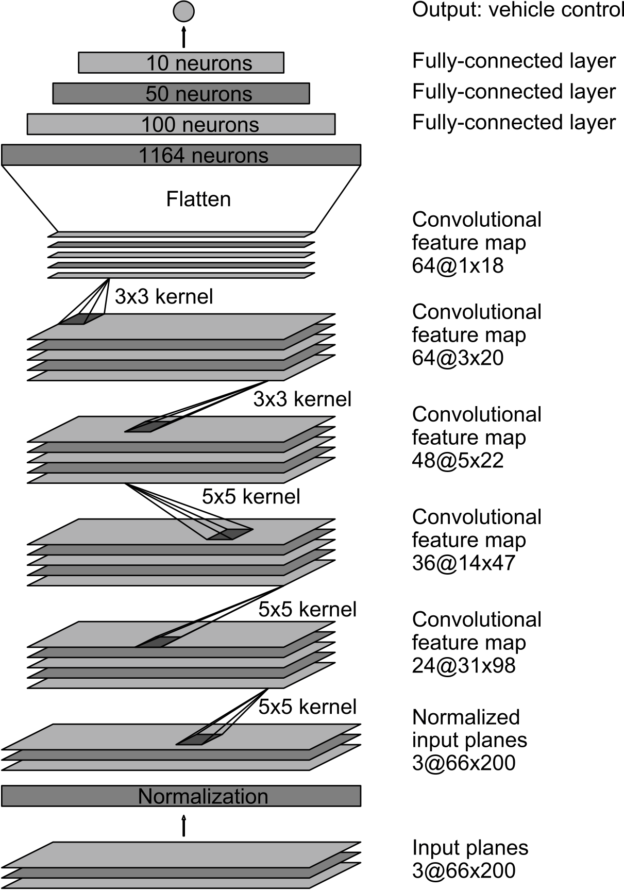
To create the training data, I used the Udacity sample data as a base. For each image, normalization would be applied before the image was fed into the network. The training sample consisted of three images:
- Center camera image
- Left camera image
- Right camera image
I found that this was sufficient to meet the project requirements for the first track. To make the car run on the same track, additional data augmenation techniques like adding random brightness, shearing and horizontal shifting could be applied.
Instead of storing the preprocessed data in memory all at once, using a generator function, pieces of the data were pulled and processed on the fly as and when needed, which was found to be more memory-efficient.
The network was then trained for 5 epochs.
The model was tested on the first track to ensure that it was performing as expected.
The following challenges were faced and overcome during this project: Network predicting constant steering angles: During the initial phase of training, the network would produce a constant prediction for steering angle regardless of the input. This was found out to be due to an unbalanced dataset with more entries for zero steering angle than others.
The current code can steer the car such that it can drive autonomously over the track. However, there are several improvements that can be made:
- Traning the model using the second track.
- Teaching the vehicle to steer and accelerate/brake autonomously. Since there are no obstacles/traffic on this test track, it can be used to investigate how the throttle may also be autonomously controlled.
- Usage of more data augumentation techniques to increase the accuracy.
The code in this project was adapted from the lessons on Behavioral Cloning, which are part of the Nanodegree program.